







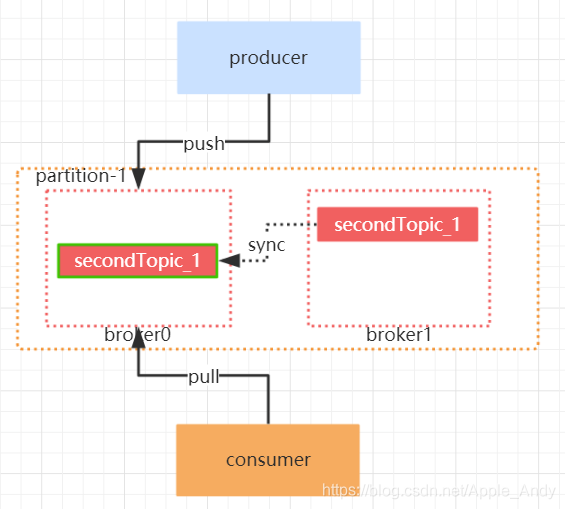
一.分区的副本机制
我们已经知道Kafka的每个topic都可以分为多个Partition,并且多个partition会均匀分布在集群的各个
节点下。虽然这种方式能够有效的对数据进行分片,但是对于每个partition来说,都是单点的,当其中
一个partition不可用的时候,那么这部分消息就没办法消费。所以kafka为了提高partition的可靠性而
提供了副本的概念(Replica),通过副本机制来实现冗余备份。
每个分区可以有多个副本,并且在副本集合中会存在一个leader的副本,所有的读写请求都是由leader
副本来进行处理。剩余的其他副本都做为follower副本,follower副本会从leader副本同步消息日志。
这个有点类似zookeeper中leader和follower的概念,但是具体的时间方式还是有比较大的差异。所以
我们可以认为,副本集会存在一主多从的关系。
一般情况下,同一个分区的多个副本会被均匀分配到集群中的不同broker上,当leader副本所在的
broker出现故障后,可以重新选举新的leader副本继续对外提供服务。通过这样的副本机制来提高
kafka集群的可用性。
二.副本的leader选举
Kafka提供了数据复制算法保证,如果leader副本所在的broker节点宕机或者出现故障,或者分区的
leader节点发生故障,这个时候怎么处理呢?
那么,kafka必须要保证从follower副本中选择一个新的leader副本。那么kafka是如何实现选举的呢?
要了解leader选举,我们需要了解几个概念:
leader副本:响应clients端读写请求的副本
follower副本:被动的备份leader副本中的数据,不能响应clients端读写的请求
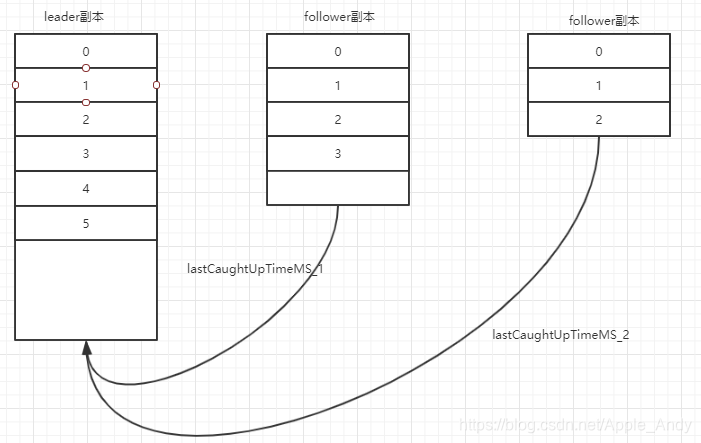
ISR副本::包含了leader副本和所有与leader副本保持同步的follower副本——如何判定是否与leader同
步后面会提到每个Kafka副本对象都有两个重要的属性:LEO和HW。注意是所有的副本,而不只是leader副本。
LEO:即日志末端位移(log end offset),记录了该副本底层日志(log)中下一条消息的位移值。注意是下一条消息!也就是说,如果LEO=10,那么表示该副本保存了10条消息,位移值范围是[0, 9]。
HW:即上面提到的水位值。对于同一个副本对象而言,其HW值不会大于LEO值。小于等于HW值的所有消息都被认为是“已备份”的(replicated)。同理,leader副本和follower副本的HW更新是有区别的.
从生产者发出的 一 条消息首先会被写入分区的leader 副本,不过还需要等待ISR集合中的所有follower副本都同步完之后才能被认为已经提交,之后才会更新分区的HW, 进而消费者可以消费到这条消息。
三.副本协同机制
刚刚提到了,消息的读写操作都只会由leader节点来接收和处理。follower副本只负责同步数据以及当leader副本所在的broker挂了以后,会从follower副本中选取新的leader。写请求首先由Leader副本处理,之后follower副本会从leader上拉取写入的消息,这个过程会有一定的延迟,导致follower副本中保存的消息略少于leader副本,但是只要没有超出阈值都可以容忍。但是如果一个follower副本出现异常,比如宕机、网络断开等原因长时间没有同步到消息,那这个时候,leader就会把它踢出去。kafka通过ISR集合来维护一个分区副本信息
一个新leader被选举并被接受客户端的消息成功写入。Kafka确保从同步副本列表中选举一个副本为leader;leader负责维护和跟踪ISR(in-Sync replicas , 副本同步队列)中所有follower滞后的状态。当producer发送一条消息到broker后,leader写入消息并复制到所有follower。消息提交之后才被成功复制到所有的同步副本
ISR
ISR表示目前“可用且消息量与leader相差不多的副本集合,这是整个副本集合的一个子集”。怎么去理解可用和相差不多这两个词呢?具体来说,ISR集合中的副本必须满足两个条件:
- 副本所在节点必须维持着与zookeeper的连接
- 副本最后一条消息的offset与leader副本的最后一条消息的offset之间的差值不能超过指定的阈值(replica.lag.time.max.ms) replica.lag.time.max.ms:如果该follower在此时间间隔内一直没有追上过leader的所有消息,则该follower就会被剔除isr列表
- ISR数据保存在Zookeeper的 /brokers/topics//partitions//state节点中


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









