




不少AI语音合成软件的生成作品都缺乏“人味”,而流畅自然的语音交互体验却逐渐被更多AI应用场景所需要。今天要介绍的就是Fish Audio出品的一款文本转语音(TTS)解决方案——FishSpeech,其在中文语音生成场景下的出色表现如同一骑绝尘,几乎能够达到接近人类自然语音的效果。
下面就让我们一起来看看吧~
FishSpeech的优势在哪?
- 高保真音质:能够生成接近真人的语音,提供自然流畅的听觉体验。
- 智能调整:能够智能分析输入文本的情感色彩和语境,自动调整语调和节奏,使输出语音更加贴合原文意图。
- 简洁友好:用户界面非常简单,操作简便,生成速度也很快。
- 三语切换:中、日、英三种语言全面支持,能听出异域风情。
FishSpeech适合哪些场景?
- 教育培训:用最小的人力和成本投入,实现大量教育素材的输出,并可用于教学视频、PPT演示文稿和有声书的配音。
- 媒体娱乐:为播客、动画、游戏等角色提供配音服务,增强沉浸感和表现力,丰富节目内容。
- 智能客服:提供语音交互功能,提升用户体验;发送语音通知和提醒,如订单确认、快递到达等。
在哪里玩FishSpeech?
FishSpeech现已上线东方超算AI应用商店(访问网址appmall.ai),您可以查看《手把手教你玩转AppMall》,全流程了解如何安装开启站内应用。
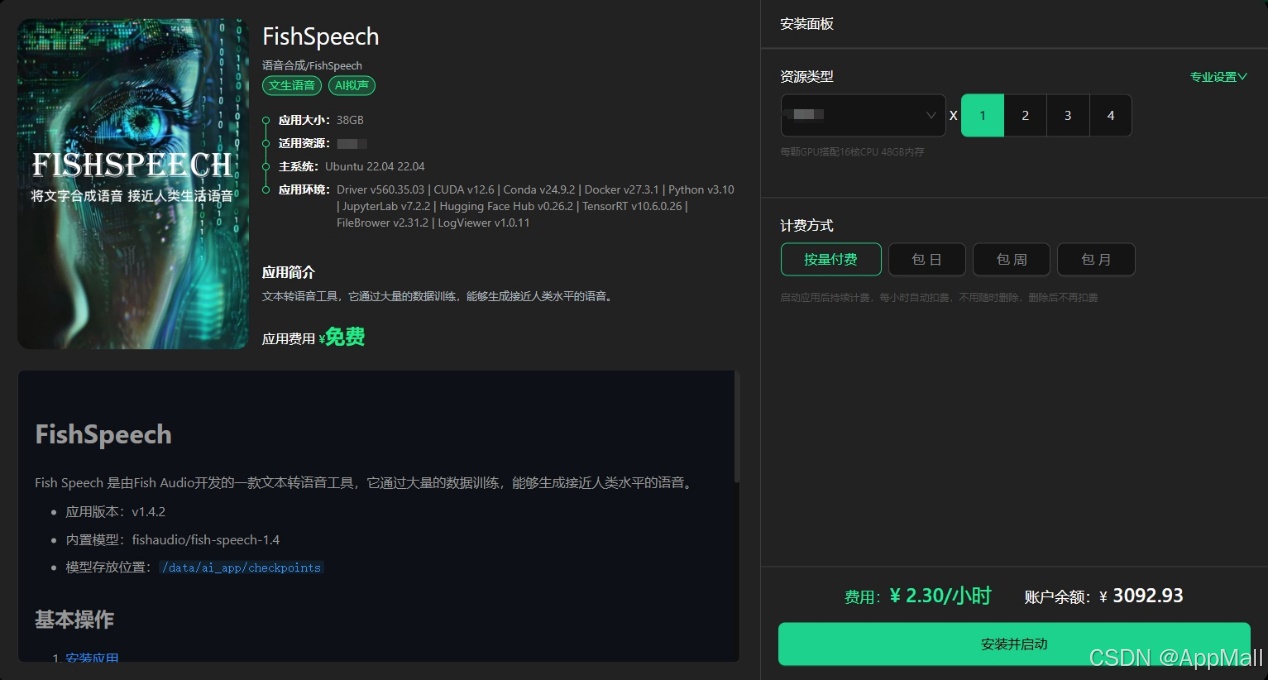
FishSpeech怎么用?
界面非常简单,只需要输入文本原文,按Generate键进行生成即可。在实测中,差不多长度的中文文本的生成速度最快>英文文本>日文文本。
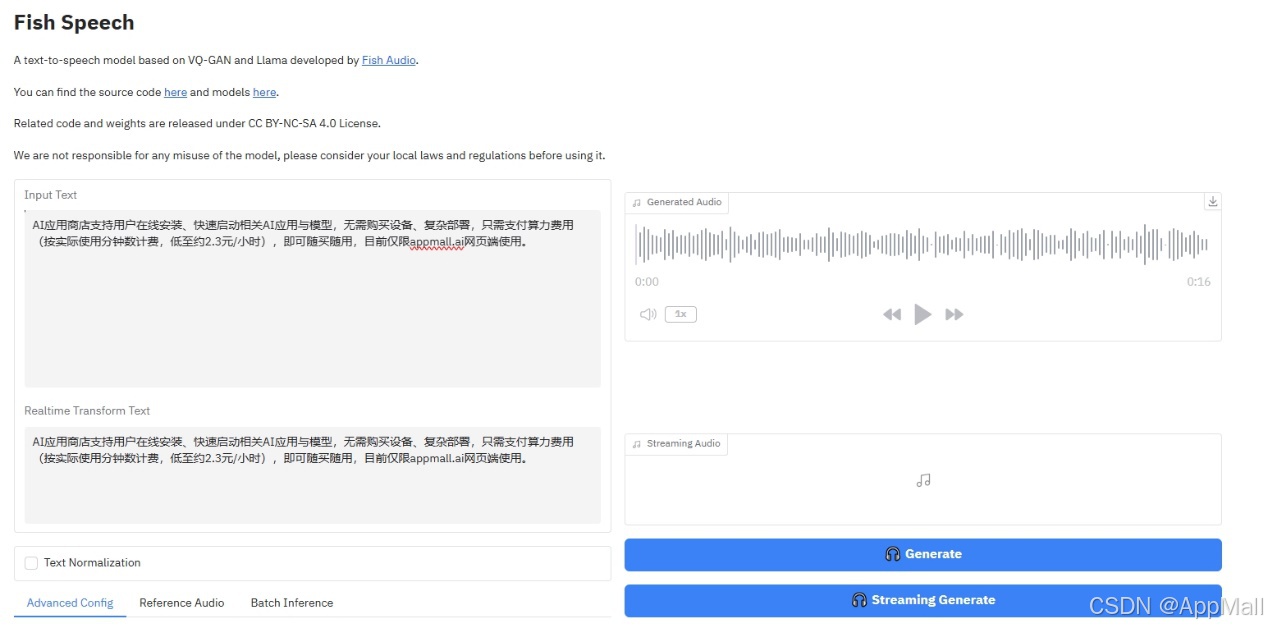
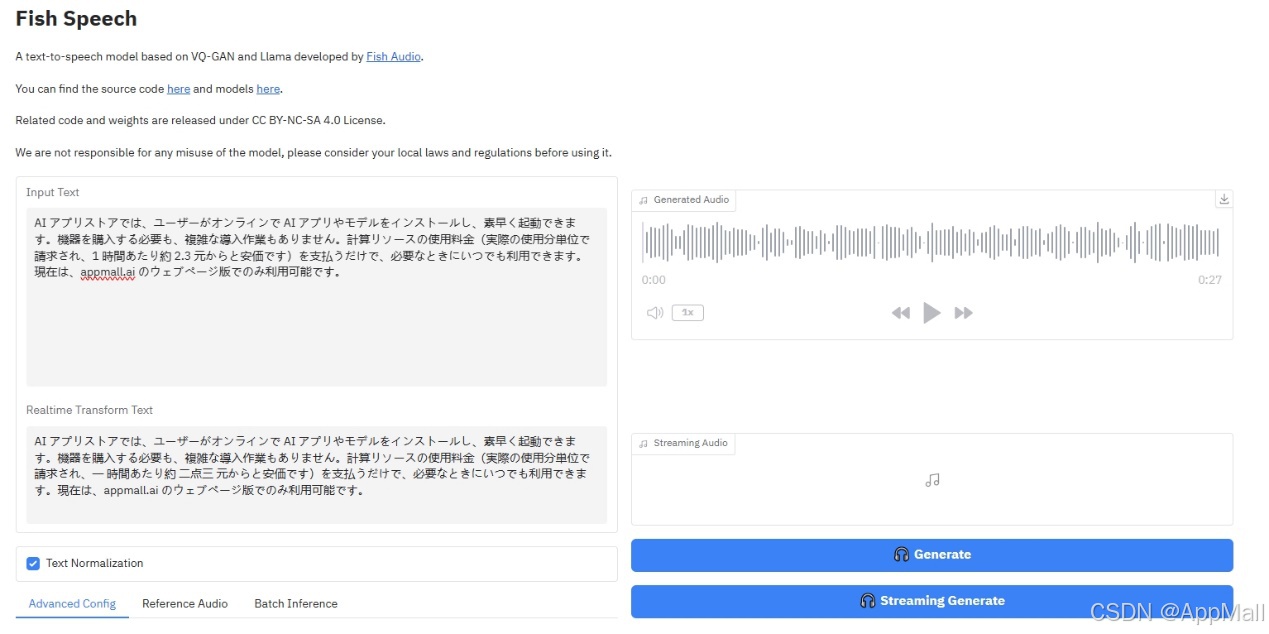
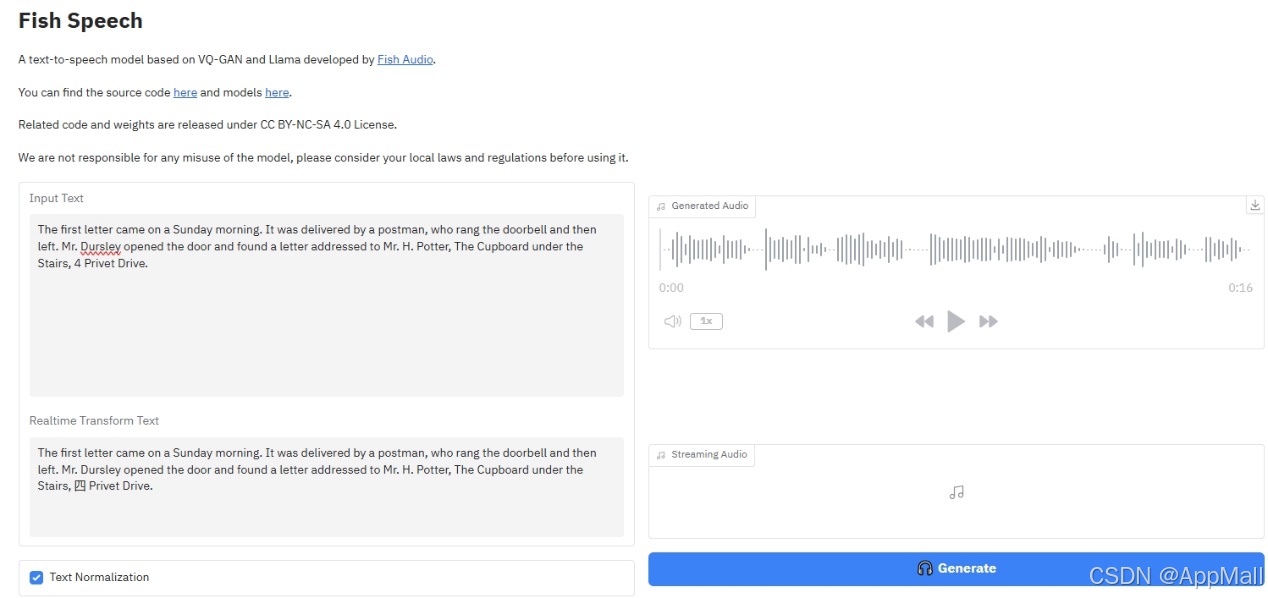
但是从语音文件本身来说,有起承转合,准确率也接近100%,而且语速和语调都比较自然,高度还原native speaker。
大部分情况下,直接使用默认参数,即可短平快完成一次文本-语音生成,如果需要高级参数调试,那么就需要注意下面这些参数了:
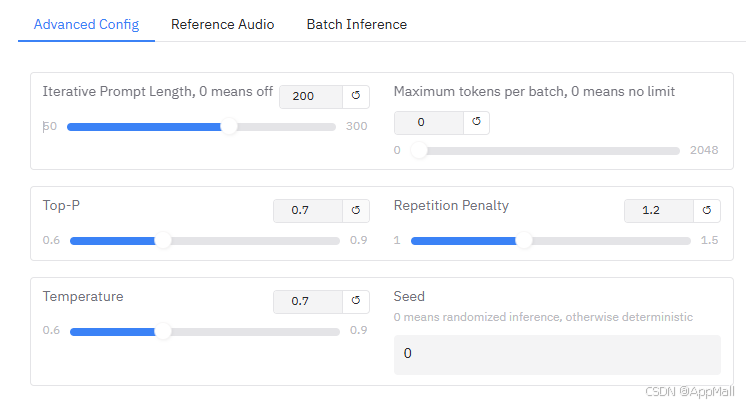
- Iterative Prompt Length:迭代提示长度,指在生成语音时,模型会考虑前文内容的长度,数值为 0 表示关闭此功能。比如设置为 200,模型就会参考前面 200 个相关单位(如字符、词等)的内容来生成当前语音 ,合适的设置能让语音更连贯、符合语境。
- Maximum tokens per batch:批次最大标记数,用于限定每个批次中模型可以生成的最大标记(token)数量,0 表示没有限制。token 是模型处理文本时的基本单位,限制这个数量可以控制每批处理量,避免内存等资源过度占用。
- Top-P:核采样,是一种文本生成策略。模型在生成每一个新词时,只考虑累积概率大于 P 的最小集合的词。比如设置为 0.7,就是从累积概率达到 0.7 的最小词集合中选择下一个词,该参数能控制生成内容的随机性和多样性。
- Repetition Penalty:重复惩罚,用于减少生成语音文本中的重复内容。比如设置为 1.2 ,模型在生成过程中遇到重复内容时,会给予一定惩罚,降低重复出现的概率,让生成的语音更自然。
- Temperature:温度,用于控制生成语音文本的随机性。数值越低,生成结果越确定、保守;数值越高,随机性越强,结果可能更加多样但也可能更偏离预期。比如设置为 0.7 ,处于适中水平,能平衡多样性和稳定性。
- Seed:随机种子,当设置为 0 时表示随机推理,每次运行结果可能不同;设置为非 0 数值时,推理过程是确定性的,即使用相同的随机种子和输入,每次得到的结果相同 ,方便复现特定的语音生成效果。


















 1145
1145

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









