




 本文探讨了Java中的BufferedInputStream和BufferedOutputStream如何提高输入输出效率。BufferedInputStream通过内部缓冲区实现数据批量处理,支持标记功能,提供skip和available等方法。BufferedOutputStream同样利用缓冲区提升写入效率,数据会在缓冲区满或调用flush、close方法时写入磁盘。
本文探讨了Java中的BufferedInputStream和BufferedOutputStream如何提高输入输出效率。BufferedInputStream通过内部缓冲区实现数据批量处理,支持标记功能,提供skip和available等方法。BufferedOutputStream同样利用缓冲区提升写入效率,数据会在缓冲区满或调用flush、close方法时写入磁盘。
BufferedInputStream是对InputStream的一种包装,属于设计模式中的装饰器模式。同样的,BufferedOutputStream是对OutputStream的一种包装。
关联现实世界,相当于:
假如使用FileInputStream,就像是一个快递员从仓库取出一件包裹给客户送去,再取第二件包裹给客户送去,如此往复。
而BufferedInputStream干了件什么事呢?它先从仓库里把包裹一件一件拿出来以后,先不给客户送过去,只是先用个容器给装起来,等容器装满了或者调用了flush方法或者调用了close方法,才会给客户送过去。这样的话,就提高了效率。
BufferedOutputStream也是同样的道理!
先聊聊BufferedInputStream类吧!
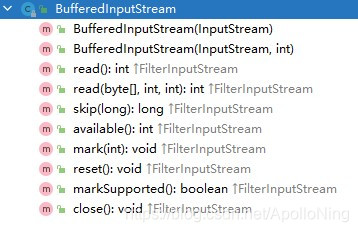
它和FileInputStream的API差不多,但是也是有区别的,比如:
boolean markSupported()
void reset()
void mark(int readlimit)
我们知道,在FileInputStream中,markSupported()返回的是false!是不支持标记功能的。但是在BufferedInputStream类中是支持的。
public boolean markSupported() {
return true;
}
那我们就试一试!
public class BufferedInputStreamTestClient {
public static void main(String[] args) {
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("ThreeKind"))) {
System.out.println("markSupported = " + bufferedInputStream.markSupported());
System.out.println(bufferedInputStream.read());
System.out.println(bufferedInputStream.read());
bufferedInputStream.mark(3);//第三个位置做上标记
System.out.println(bufferedInputStream.read());
System.out.println(bufferedInputStream.read());
bufferedInputStream.reset();//回到标记的位置(第三个位置)
System.out.println(bufferedInputStream.read());
System.out.println(bufferedInputStream.read());
} catch (Exception exception) {
}
}
}
ThreeKind文件的内容是:ABCDEFG。运行结果是:
markSupported = true
65
66
67
68
67
68
可以看出,先输出了对mark功能是支持的,返回true。先输出的2个字节分别是 65 66 即 A B。此时我们在C即第三个字节做了标记,继续输出2个字节,分别是C D即 67 68。紧接着,我们reset()一下,就回到了标记处,再次输出2个字节,又是 67 68 即C D。这就是mark的功能。
好,继续看下其他的API:
- int available()
功能类似,获取剩余的字节数。
public class BufferedInputStreamTestClient {
public static void main(String[] args) {
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("ThreeKind"))) {
int available = bufferedInputStream.available();
System.out.println("available = " + available);
} catch (Exception exception) {
}
}
}
available = 7
- long skip(long n)
功能类似,跳过指定的字节数,返回值是实际跳过的字节数。
public class BufferedInputStreamTestClient {
public static void main(String[] args) {
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("ThreeKind"))) {
long skip = bufferedInputStream.skip(1);
System.out.println("skip = " + skip);
int data = bufferedInputStream.read();
System.out.println("data = " + (char) data);
} catch (Exception exception) {
}
}
}
skip = 1
data = B
跳过了一个字节,本来应该是输出A的,被跳过去了。
接下来就是读的API了,由于和FileInputStream的API很类似,所以就贴下代码,不做解释了。
public class BufferedInputStreamTestClient {
public static void main(String[] args) {
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("ThreeKind"))) {
int data;
while ((data = bufferedInputStream.read()) != -1) {
System.out.print((char) data);
}
} catch (Exception exception) {
}
}
}
public class BufferedInputStreamTestClient {
public static void main(String[] args) {
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("ThreeKind"))) {
int len;//读取字节数
byte[] bytes = new byte[4];
while ((len = bufferedInputStream.read(bytes)) != -1) {
System.out.println("len = " + len + "bytes = " + Arrays.toString(bytes));
}
} catch (Exception exception) {
}
}
}
public class BufferedInputStreamTestClient {
public static void main(String[] args) {
try (BufferedInputStream bufferedInputStream = new BufferedInputStream(new FileInputStream("ThreeKind"))) {
int len;//读取字节数
byte[] bytes = new byte[4];
while ((len = bufferedInputStream.read(bytes, 1/*起始位置,从0开始*/, 2/*存放字节数组长度*/)) != -1) {
System.out.println("len = " + len + "bytes = " + Arrays.toString(bytes));
}
} catch (Exception exception) {
}
}
}
最后,说一下BufferedInputStream的构造方法吧!很简单就2种!
public BufferedInputStream(InputStream in) {
this(in, DEFAULT_BUFFER_SIZE);
}
public BufferedInputStream(InputStream in, int size) {
super(in);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
第一个构造方法是调用第二个构造方法的。int size参数给的是DEFAULT_BUFFER_SIZE。DEFAULT_BUFFER_SIZE是一个固定值:private static int DEFAULT_BUFFER_SIZE = 8192;
所以,可以看出,默认的缓冲大小是8192字节,就是8kb。日常来说是够用了,当然可以用第②种构造方法来修改。
好,接下来聊一下,BufferedOutputStream,看看它的用法。
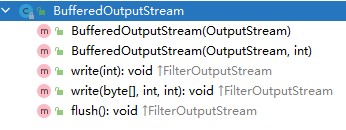
BufferedOutputStream并不是一个字节一个字节的往硬盘上写的,而是有个桶,就是缓冲区,先把要写的数据装进缓冲区里,然后一次性把桶里的数据写出去。
public BufferedOutputStream(OutputStream out) {
this(out, 8192);
}
public BufferedOutputStream(OutputStream out, int size) {
super(out);
if (size <= 0) {
throw new IllegalArgumentException("Buffer size <= 0");
}
buf = new byte[size];
}
看到,this(out, 8192);了吗?这就是调用了第二个构造方法!默认的size就是8192,就是缓冲区,大小是8kb。
那么,什么时候会往磁盘中写数据呢?
第①种:缓存区满了,写出去!
第②种:void flush()方法被调用,写出去!
第③种:void close()方法被调用,写出去!因为,close()方法被调用的时候,会先调用flush()方法。
public class BufferedOutputStreamTestClient {
public static void main(String[] args) {
try (BufferedOutputStream bufferedOutputStream = new BufferedOutputStream(new FileOutputStream("ThreeKind"), 4)) {
bufferedOutputStream.write(65);
bufferedOutputStream.flush();//调用flush()方法会将缓冲区的数据刷入到磁盘中
bufferedOutputStream.write(66);//flush()方法将缓冲区清空,此语句执行完,缓冲区只有一个字节的数据
bufferedOutputStream.write(67);
bufferedOutputStream.write(68);
bufferedOutputStream.write(69);//此条语句执行完缓冲区刚刚满,但是还未将数据刷入到磁盘中
bufferedOutputStream.write(70);//缓冲区已经满了先将数据刷入到磁盘中,清空缓冲区,再存入一个字节
bufferedOutputStream.write(71);
} catch (Exception exception) {
}
}
}
通过调试模式,一步一步调试,进行测试:
由于,构造函数第二个参数是4,所以默认的8192被覆盖了,缓冲区的大小变成了4字节。
当write(65)时,文件中没有数据,因为,此时65被写入了缓冲区,还没到磁盘;
当flush()方法被调用时,文件中有了A字母。此时的缓冲区被清空了。
接下来的数据都被写入的缓冲区,直到write(70)时,发现缓冲区满了,此时将缓冲区的数据写入磁盘中,并将缓冲区清空,将70写入缓冲区。
当write(71)时,文件中只有ABCDE,即65 66 67 68 69,此时的 70 和 71 还未写入到文件中。
直到,准备跳出try代码块,程序会自动调用close方法,为什么?原因在FileInputStream一文的开始就说了,在这里就不罗嗦了。close方法又会调用flush方法,所以,此时,FG才会写入文件中。
以上就是关于BufferedInputStream和BufferedOutputStream的全部内容!不知客官欣赏的是否尽兴,评论区聊聊?

















 1491
1491




 到【灌水乐园】发言
到【灌水乐园】发言







