




 文章介绍了Logstash中的mutate过滤器,用于日志事件字段的修改、删除和添加。通过示例展示了如何配合grok过滤器解析日志,然后使用mutate过滤掉无用字段,以实现日志数据的标准化,便于后续分析和存储。
文章介绍了Logstash中的mutate过滤器,用于日志事件字段的修改、删除和添加。通过示例展示了如何配合grok过滤器解析日志,然后使用mutate过滤掉无用字段,以实现日志数据的标准化,便于后续分析和存储。
1.前言
mutate 过滤器是Logstash中的一个常用过滤器,用于对事件中的字段进行修改、重命名、删除和添加操作。它提供了多种操作选项,如替换字段值、添加新字段、删除字段、重命名字段等。mutate 过滤器可以在事件流水线的任何阶段使用,且不需要匹配特定的模式,通常情况下,你可能需要先使用 grok 过滤器解析日志行并提取字段,然后使用 mutate 过滤器对提取的字段进行进一步处理或添加额外的字段。这样可以对日志数据进行解析、转换和标准化,以便后续的存储、分析和可视化操作
2.使用
先展示一下日志使用gork结构化后的情况

这是未设置mutate过滤之前logstash输出的日志
tail -f /opt/logstash/logstash/logstash.log
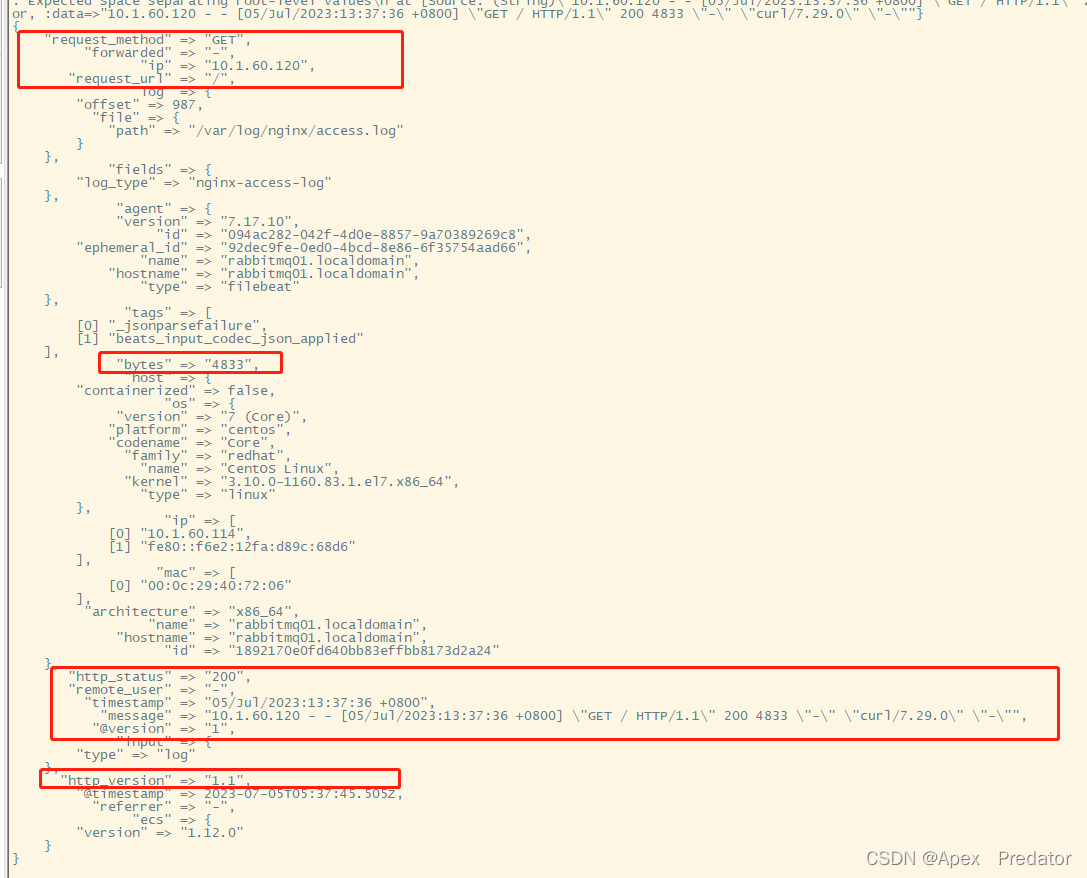
我们在通过mutate过滤掉不需要的字段,编辑logstash配置文件
vi /opt/logstash/logstash/config/logstash.conf
input {
beats { #配置为beats,供filebeat调用
port => 5044 #配置监听端口,用于接收filebeat传输过来的日志
codec => "json" #如果传输过来的是json格式日志则需要此项配置,否则就删掉此项配置
}
}
filter {
if [fields][topic] == "nginx-access-log" {
grok {
match => {
"message" => "%{IP:ip} - (%{USERNAME:remote_user}|-) \[%{HTTPDATE:timestamp}\] \"%{WORD:request_method} %{URIPATHPARAM:request_url} HTTP/%{NUMBER:http_version}\" %{NUMBER:http_status} %{NUMBER:bytes} \"(%{DATA:referrer}|-)\" \"%{DATA:http_agent}\" \"(%{DATA:forwarded}|-)\""
}
}
mutate {
remove_field => ["message","timestamp","http_status","ip"] #过滤掉日志中的message、timestamp、http_status、ip字段
}
}
else if [fields][topic] == "nginx-error-log" {
grok {
match => {
"message" => "%{DATA:timestamp} \[%{WORD:severity}\] %{NUMBER:pid}#%{NUMBER:tid}: %{GREEDYDATA:prompt}"
}
}
mutate {
remove_field => ["message","timestamp"] #过滤掉日志中的message和timestamp字段
}
}
}
output {
stdout{
codec => rubydebug #将数据输出到日志中,用于测试
}
# elasticsearch {
# hosts => ["http://10.1.60.114:9200","http://10.1.60.115:9200","http://10.1.60.118:9200"]
# index => "%{[@metadata][kafka][topic]}-%{+YYYY.MM.dd}"
# }
}
查看一下日志
tail -f /opt/logstash/logstash/logstash.log

对比上图未过滤前输出的日志可以发现,message、http_status、ip、timestamp这些字段已经被过滤掉了,并没有被logstash输出
对于mutate过滤还有其它的用法,这里就不展示案例了,只在以下展示一些如何配置
vi /opt/logstash/logstash/config/logstash.conf
input {
file {
path => "/path/to/your/logfile.log"
start_position => "beginning"
}
}
filter {
grok {
match => { "message" => "\[%{TIMESTAMP_ISO8601:timestamp}\] %{LOGLEVEL:loglevel}: User '%{USERNAME:username}' %{WORD:status} successfully." }
}
mutate {
remove_field => ["message"] # 删除原始日志行字段
convert => {
"timestamp" => "string" # 将 timestamp 字段转换为字符串类型
}
gsub => [
"username", "\.", "_" # 将用户名中的点号替换为下划线
]
}
}
output {
stdout {
codec => rubydebug
}
}
以下是日志例子
[2023-07-01 10:30:15] INFO: User 'john.doe' logged in successfully.


















 1164
1164

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









