




 文章描述了一个k8s集群中Master组件出现错误,特别是controller和scheduler组件显示异常的情况。尽管尝试删除pod,但它们未能自动重启。解决方法是修改kube-scheduler和kube-controller-manager的yaml文件,调整livenessProbe的超时时间,从而触发组件pod的重启。
文章描述了一个k8s集群中Master组件出现错误,特别是controller和scheduler组件显示异常的情况。尽管尝试删除pod,但它们未能自动重启。解决方法是修改kube-scheduler和kube-controller-manager的yaml文件,调整livenessProbe的超时时间,从而触发组件pod的重启。
1.案例
k8s的master组件出错,删掉pod重新拉起也无法正常启动
kubectl get pod -n kube-system
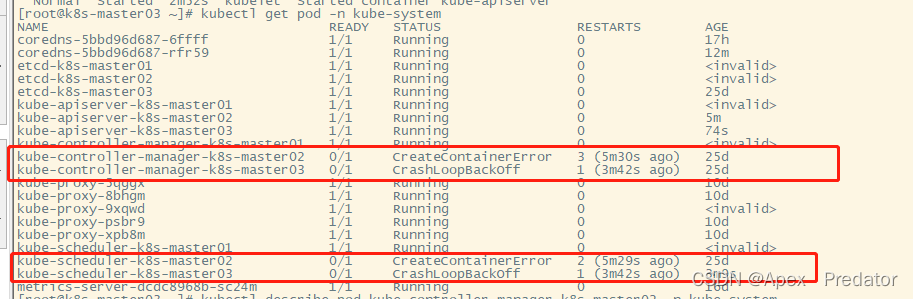
可以看到controller和scheduler组件都显示异常
kubectl describe pod kube-apiserver-k8s-master03 -n kube-system
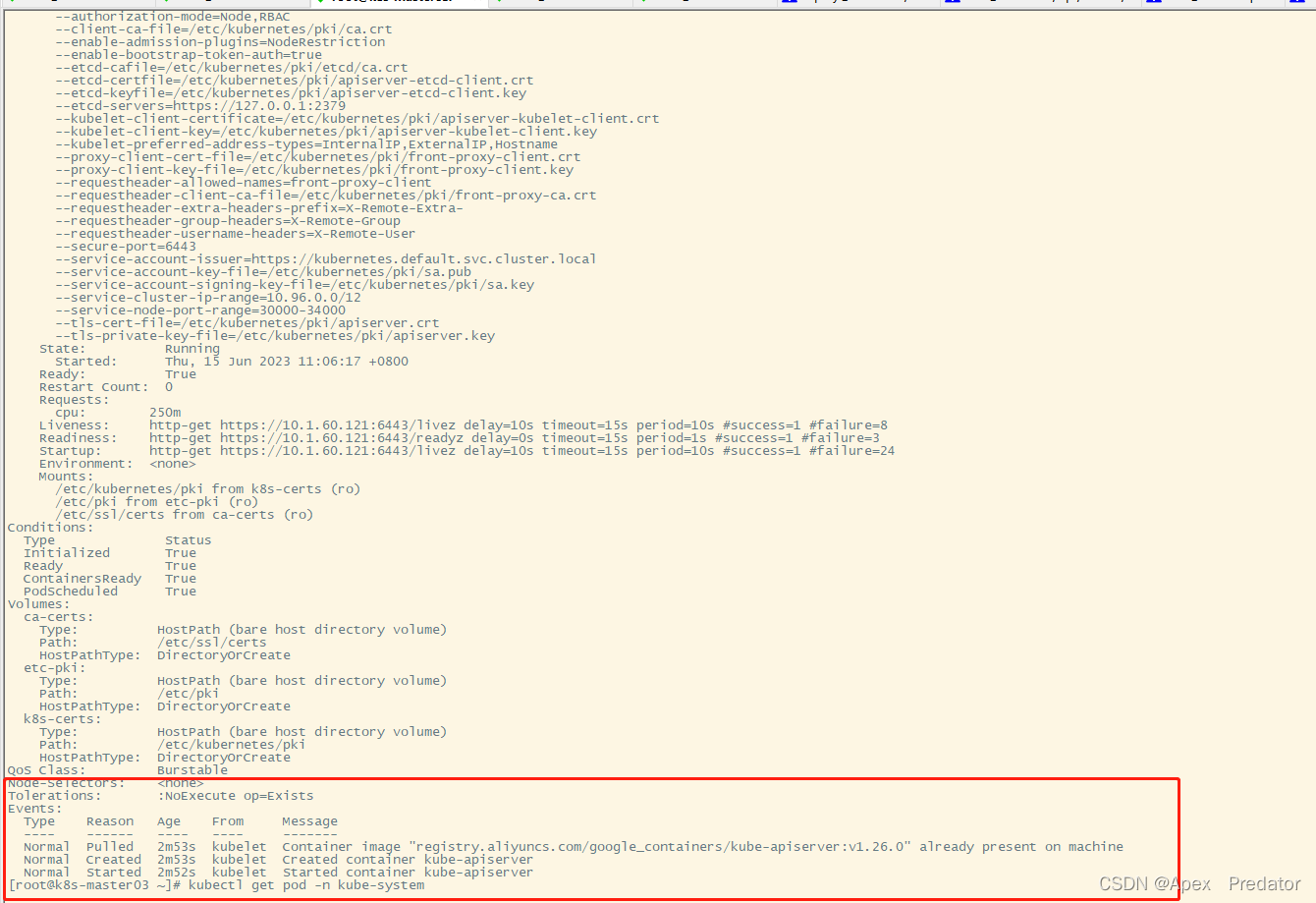
通过describe查看组件容器的详细信息也并没有报错输出
kubectl delete pod kube-controller-manager-k8s-master02 -n kube-system
kubectl get pod -n kube-system
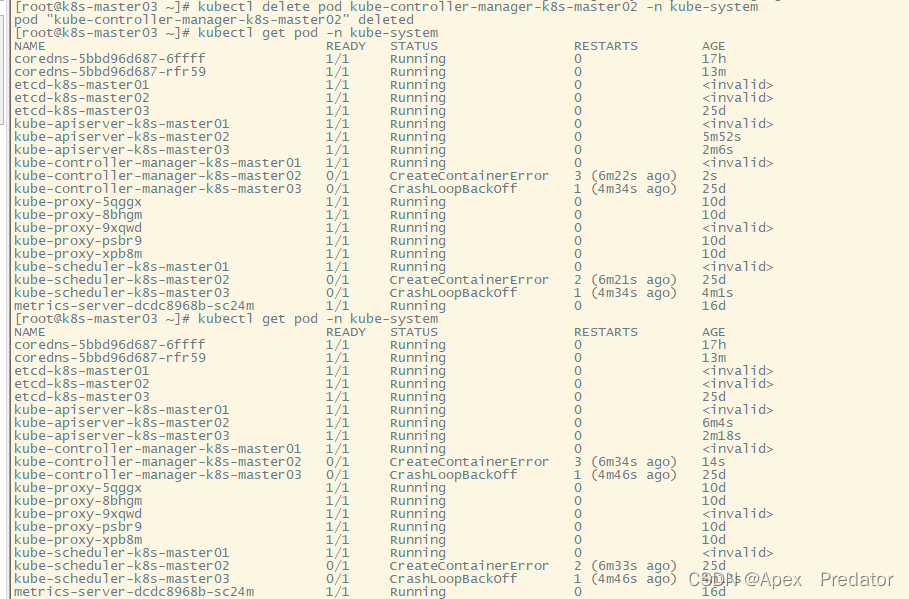
可以看到即使删除了pod,pod也没重新拉起,依然是老的pod显示报错
2.解决方法
修改一下组件的yaml文件中无关紧要的参数,使组件的pod自动重启
vi /etc/kubernetes/manifests/kube-scheduler.yaml
vi /etc/kubernetes/manifests/kube-controller-manager.yaml
更改两个yaml文件中的livenessProbe的超时时间
timeoutSeconds: 16 #将15秒改成16秒,保存退出即可
kubectl get pod -n kube-system
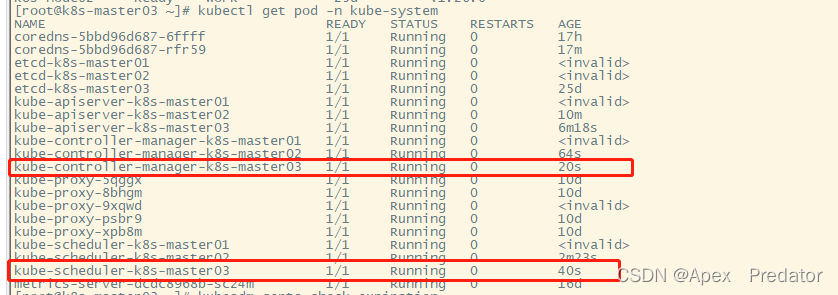
就可以看到重新拉起了一个新的组件pod


















 4155
4155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









