







SQL
def:
structured query language.(A language for database)
parts

DBMS(database management system)
components | |||
|
functions
data models
| |||




基本元素
注释
单行注释 -- (两个破折号加一个空格)
多行注释 /*
……
*/
数据类型data types
整型:
int/integer/smallint/bigint
小整数:tinyint
有符号范围:int/tinyint

无符号范围:int unsigned/tinyint unsigned
小数:
decimal[ ( M [ , D] ) ]/numeraic[ ( M [ , D] ) ]
M:总位数(包含整数部分和小数部分)
D:小数位数
浮点数:
float(p)
字符串:
varchar(M)/char[(M)]
string要用‘’引起来
因此'用''或者\'表示
区别:
char占用内存量固定,读取写入速度更快,M(字符数)不填则默认为1
varchar根据提供的字符串改变内存占用量,读取写入速度更慢,M必填
日期时间:
DATE/DATETIME/TIMESTAMP(TIMESTAMP储存当前时区的时间,若更换时区则时间随之变化)
要用‘’引起来

date小的指日期更早的
元素
schema
(keyword:USE)
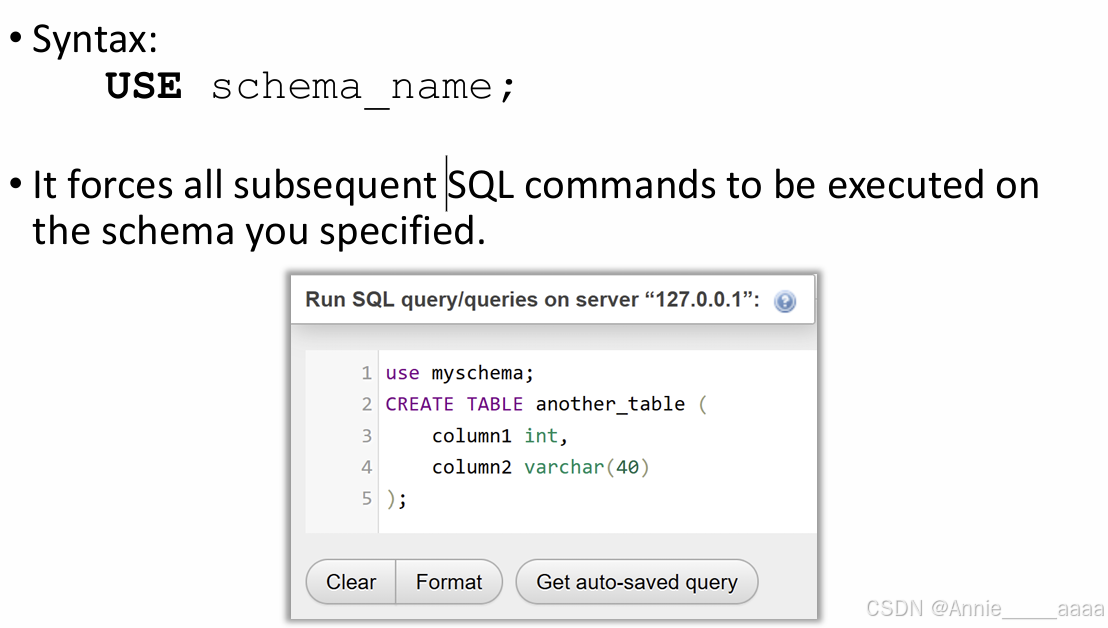
表:table/relation/file/entity
字段(列):field/column/attribute
记录(行):record/row/tuple
数据库:database
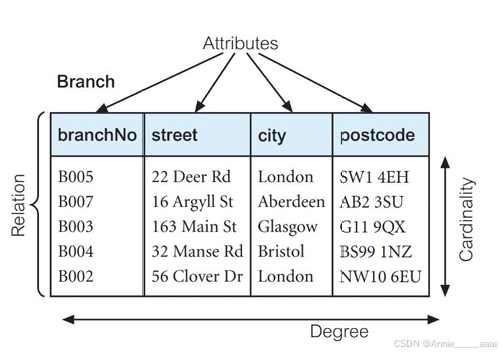

Properties of Relations
- Relation’s name is unique in the relational database schema.
- Each cell contains exactly one atomic value.
- Each attribute of a relation must have a distinct name.
- The values of an attribute are from the same domain.
- The order of attributes has no significance.
- The order of tuples has no significance.
- No duplicate tuples.
applications
Server application:

Client application:
Clients designed for managing DBMS: DBeaver, MySQL workbench, PhpMyAdmin
some format:
若含有空格,table和column需用``引起来
字符串用‘’
mysql中keywords不区分大小写,但table_name和column_name区分大小写
用二进制和ASCII码来计算
布尔值
Null
不同情况下 NULL 的处理和返回值的总结:
1、条件查询:NULL 在条件中评估为 Unknown,通常不会返回结果。但如果条件中包含 TRUE 或 FALSE,则 Unknown 会根据逻辑运算符的结果进行处理。
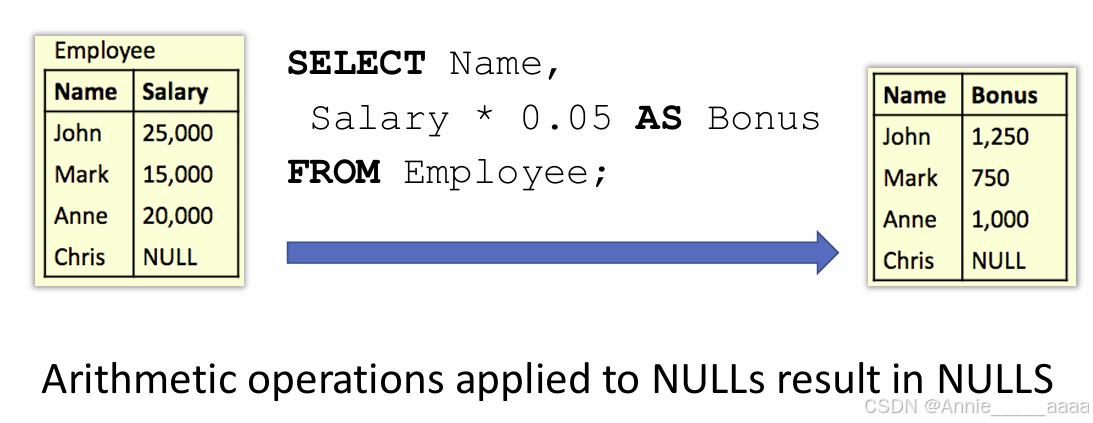
2、算术运算:任何算术运算中涉及 NULL 的结果都是 NULL。
3、聚合函数:NULL 值在大多数聚合函数中被忽略,但可以通过 COUNT(*) 包含在内。
4、GROUP BY:NULL 值被视为等价,并被分组在一起。
5、ORDER BY:NULL 值默认排在最前面,可以通过 NULLS LAST 调整顺序。


True:表示为1,
但是所有非0数字都返回true
False:0
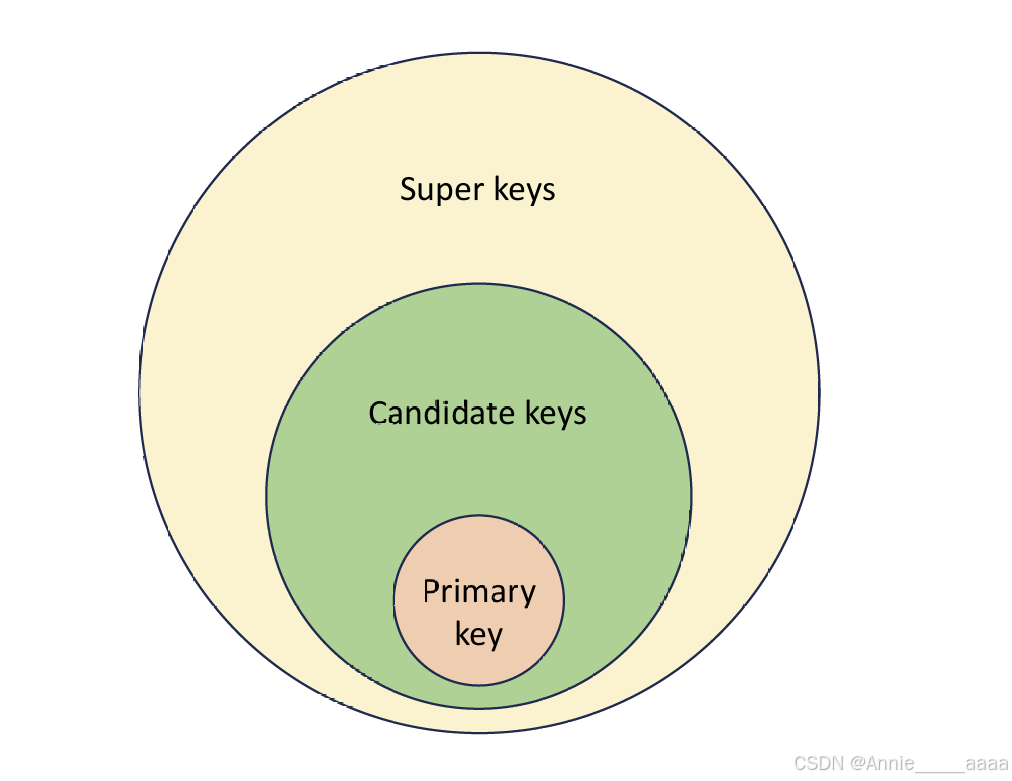
KEY类型
唯一键(Unique Key):确保唯一性,允许 NULL。
外键(Foreign Key):确保引用完整性(确保一个表中的值在另一个表中存在),通常不能为 NULL。
候选键(Candidate Key):唯一标识,最小性(候选键不能包含任何冗余列,即不能去掉任何一列仍然保持唯一性),不能包含 NULL 值。
主键(Primary Key):唯一标识,非空性,不能包含 NULL ,最常用。
超键(Super Key):唯一标识,包含性(超键可以包含冗余列,即去掉某些列后可能仍然保持唯一性),通常不能包含 NULL 值(尽管定义上不确定,但实际应用中通常限制)。
超键与候选键、主键的关系
主键(Primary Key):主键是从候选键中选出的一个,用于唯一标识表中的每一行。主键是候选键的一个特例。
候选键(Candidate Key):候选键是指所有满足唯一性和非空性要求的键。一个表可以有多个候选键,但只能有一个主键。
超键(Super Key):超键是指所有能够唯一标识表中每一行记录的字段或字段组合。超键可以包含候选键,也可以包含其他非必要的字段。
Index

CREATE
syntax
Create table_name(
column_name datatype [column_options]
);

Column options
Auto-increment:
自动增加,可设置每次增加值
Must be applied to a key column (primary key, unique key)


DEFULT
如果没有插入指定值,结果就是default默认值
e.g.1

e.g.2

NOT NULL
UNIQUE, PRIMATY KEY, FOREIGN KEY
BINARY
CONSTRAINT
Types:
Primary key:
不允许重复
不能是NULL
只能有一行primary key
Primary key auto_increment:,insert其他列时,主键那列不用指定insert新value也能自动加1
![]()
![]()
Non-insensitive(不区分大小写)
如果想区分大小写:

ASCII 的全称是 American Standard Code for Information Interchange
Not null:
该列不能为空
Unique key:
不允许重复
允许 NULL
![]()
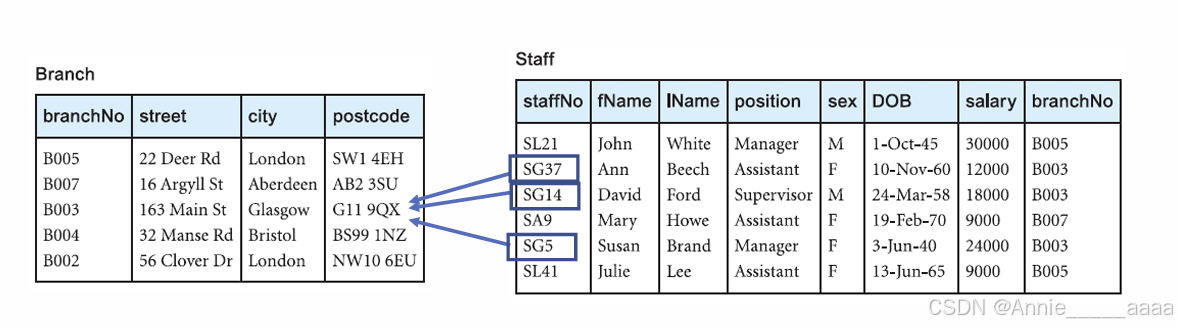
Foreign key:
确保引用完整性(确保一个表中的值在另一个表中存在):values of referencing columns must be existing values from affected columns
Referencing columns are allowed to have NULLs
Referenced column must be primary key or unique key
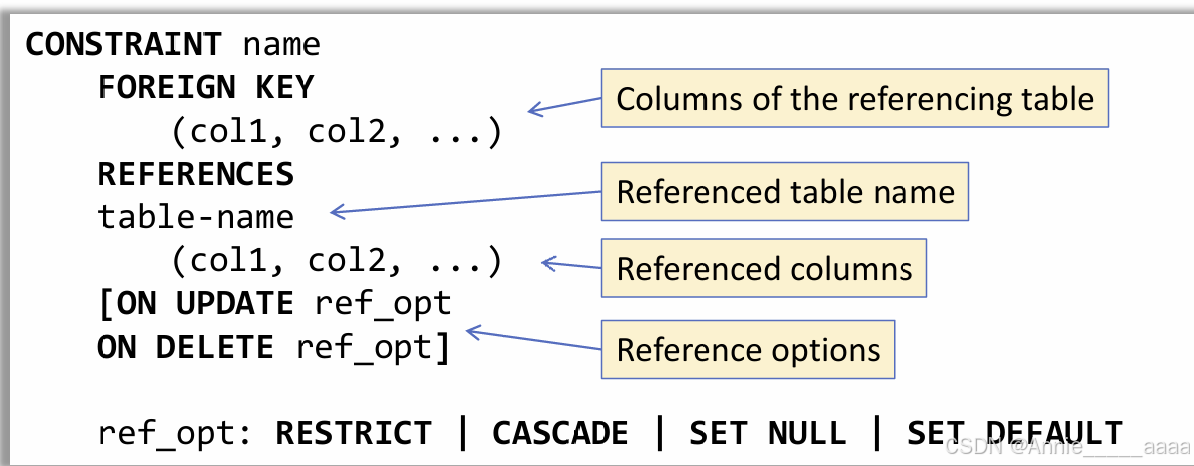
Reference options:
Restrict(default option)
禁止删除 ON DELETE RESTRICT
禁止更新 ON UPDATE RESTRICT
Cascade
级联删除 ON DELETE CASCADE
级联更新 ON UPDATE CASCAD
SET NULL
SET DEFAULT(is not available in MySQL)
CHECK
表达式:>,<,=

符号格式
1、Table_name,column_name 内不含空格,若需要空格则用` `将名称括起来
2、最后一行定义完后不用逗号(,),用分号(;)
增删改
增INSERT
插入全列:
Insert into table_name values (…,….,….),(…,….,….);
插入指定几列:
Insert into table_name (…,….) values (…,….),(…,….);
插入多行:用分号”;“隔开多个insert
用一条insert插入多行:1.()内需插入所有列的value
2.table_name的括号规定column名,values的括号用逗号”,“隔开
删DELETE
rows:

If no condition, all rows will be deleted

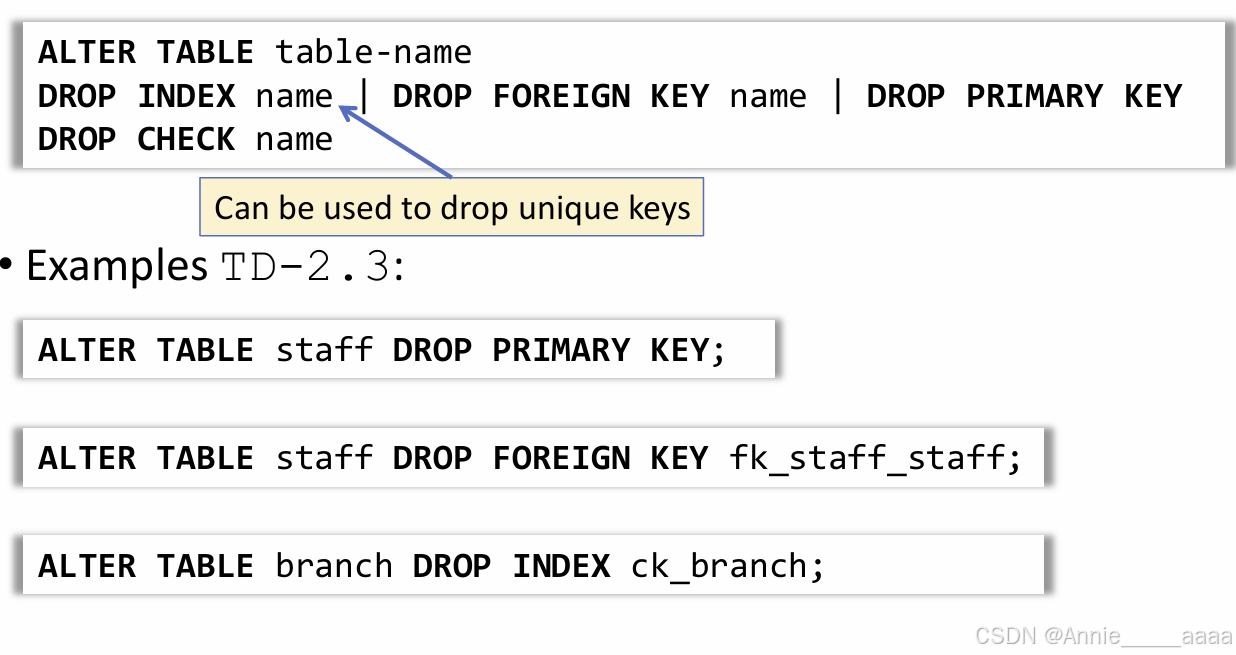
删DROP
一、删Table:

二、与alter一起用
1)删column
![]()
2)删constraints
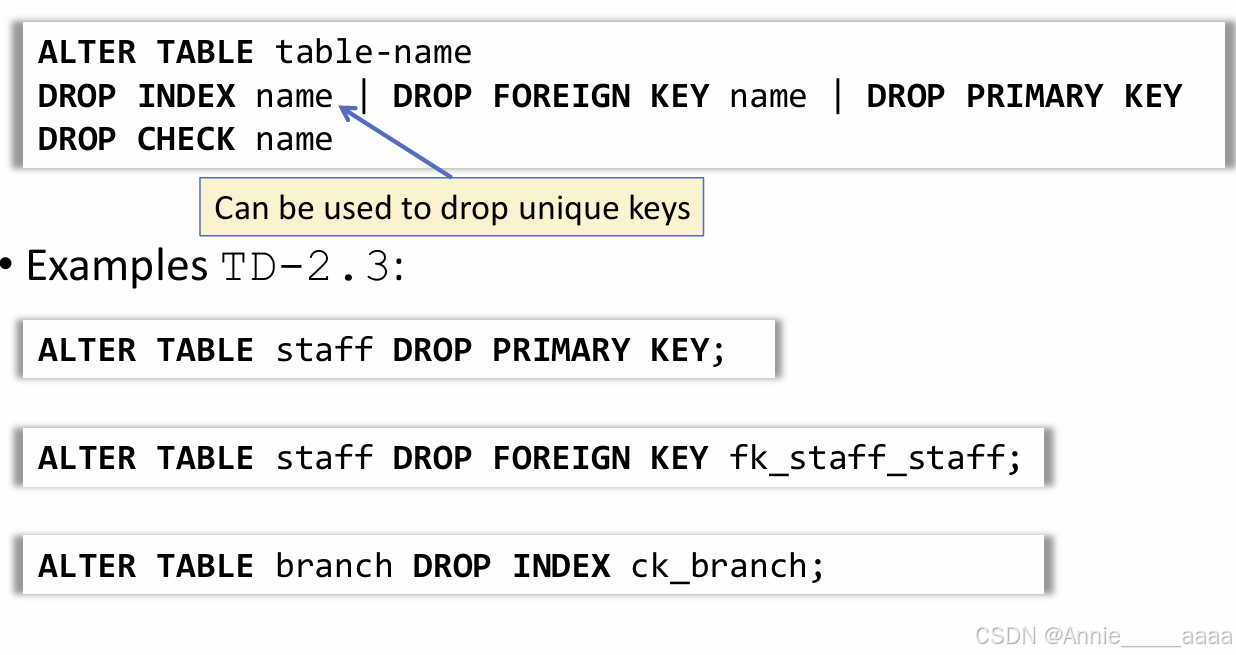
改UPDATE
用途:
更新数据。UPDATE 用于修改表中现有的数据。它可以更新一个或多个列的值,通常需要指定条件来限制更新的范围。
If no condition, all rows will be updated


改ALTER
用途:
修改表结构:ALTER 用于修改数据库表的结构,例如添加、删除或修改列、约束、索引等。
Column:
Add
●添加列
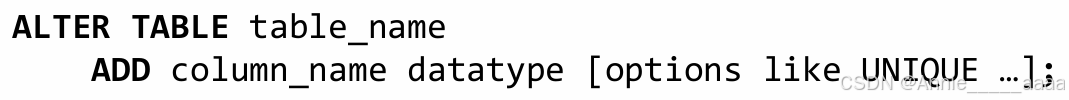

Drop
![]()
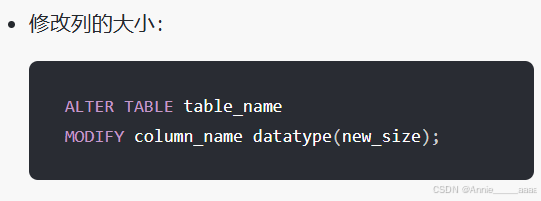
Modify
(与 ALTER 结合使用):用于修改表中现有列的定义,如数据类型、大小等。
●

CHANGE
(与 ALTER 结合使用):用于重命名表中的现有列,并且可以同时修改列的定义。


Constraints
Add
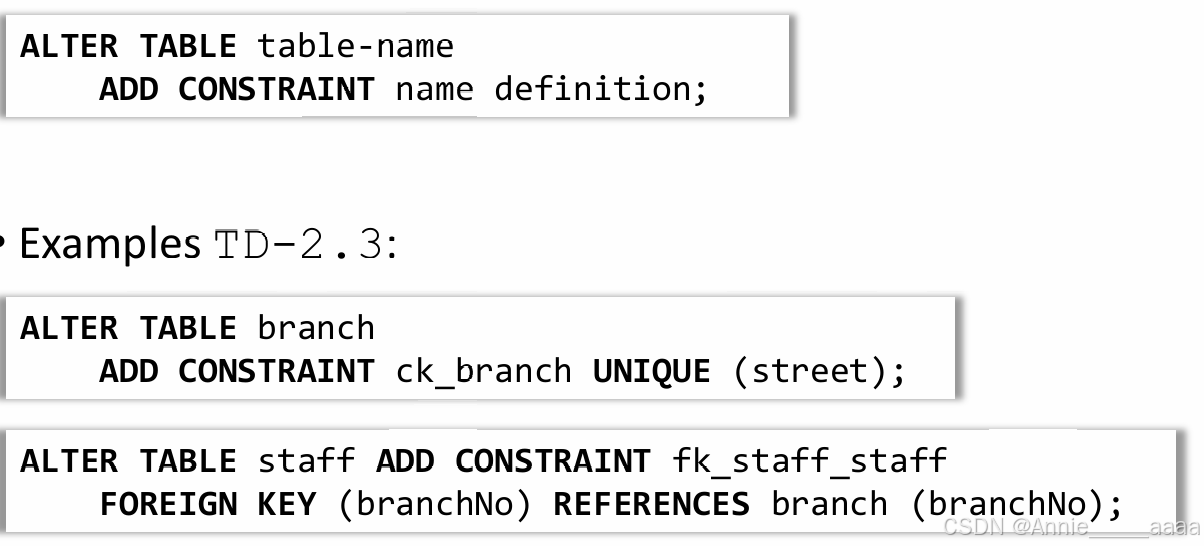
Drop
SELECT查
操作符operators
Arithmetic
符号:+, -, *, /, >, =, <=, != (same as <>)
String comparison:case-insensitive by default(不区分大小写)
Values of date and datetime can be compared against each other using operators like >, <>
e.g.

Logical
AND
OR
NOT
LIKE
%:指其他字符串的位置


_:represents exactly one character


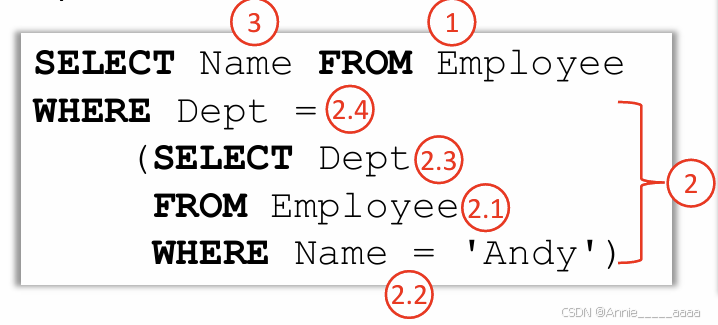
子查询subqueries
In FROM
- Must use alias to rename the results of subqueries. because that the result of a subquery does not have a table name
e.g.
SELECT * FROM (SELECT * FROM table) as t
In WHERE
e.g.

Options for handling sets:
• IN: checks to see if a value is in a set

• EXISTS: checks to see if a set is empty

• ALL/ANY: checks to see if a relationship holds for every/one member of a set



• NOT: can be used with any of the above 4

e.g.红圈表示电脑执行顺序
化名alias
AS

×:

Self-joins
e.g.

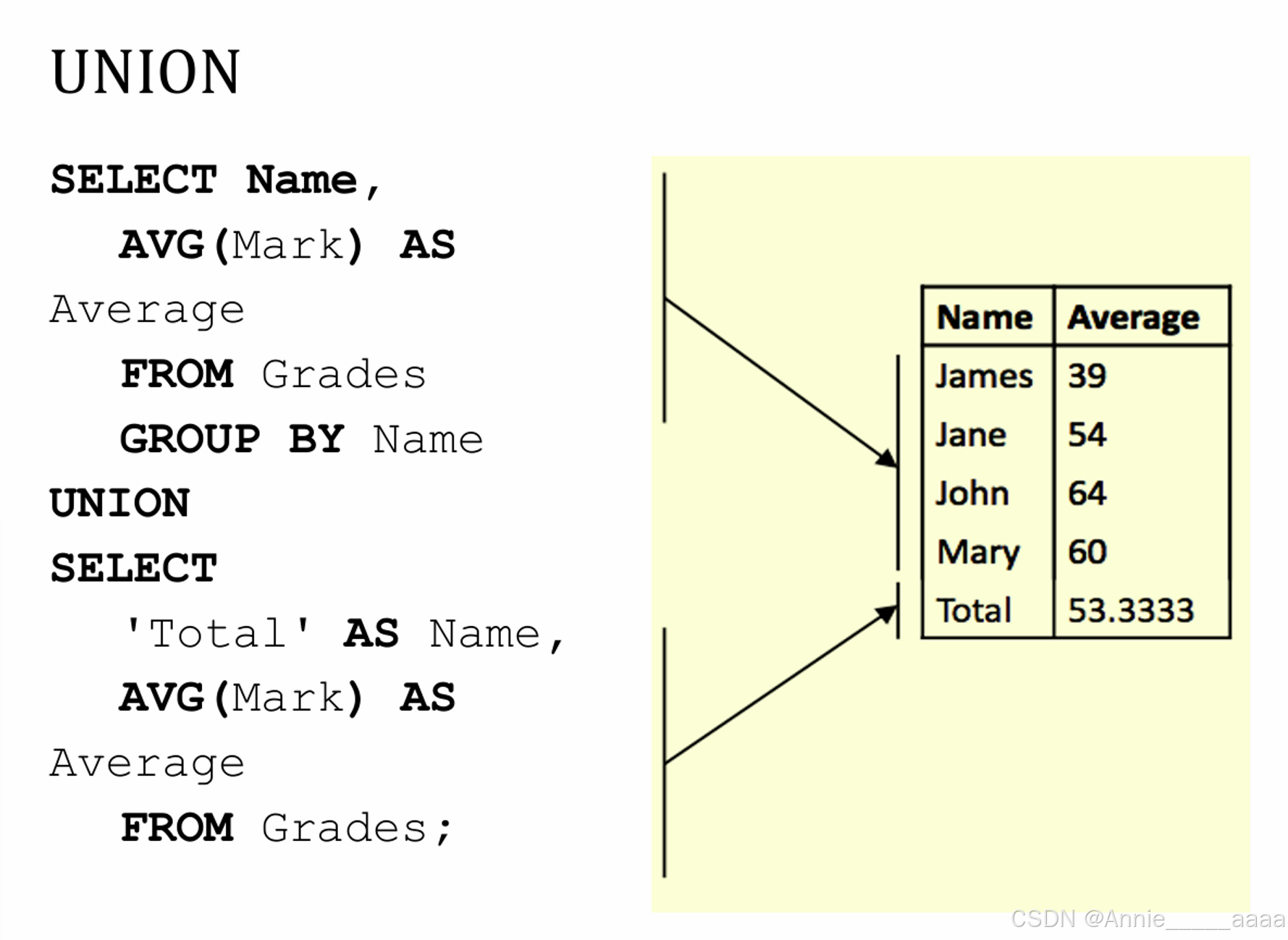
UNION
合并两个SELECT语句
ORDER BY

字母的increment代表从a到z
执行顺序sequence of execution
SELECT查
Syntax
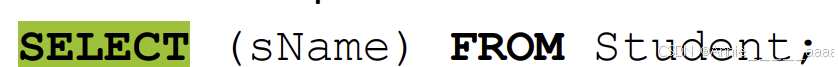
Select * from c:查询表c所有列
Select column3,column1 from c:查询表c column3和column1的列

Distinct:将选出来的重复项移除
You cannot apply DISTINCT to a single column when multiple columns exist in SELECT part.
All:the default of distinct
*
- The symbol * selects all columns
- "SELECT *, 1 FROM" addes a column full of value 1 to the final result
Aggregate Functions

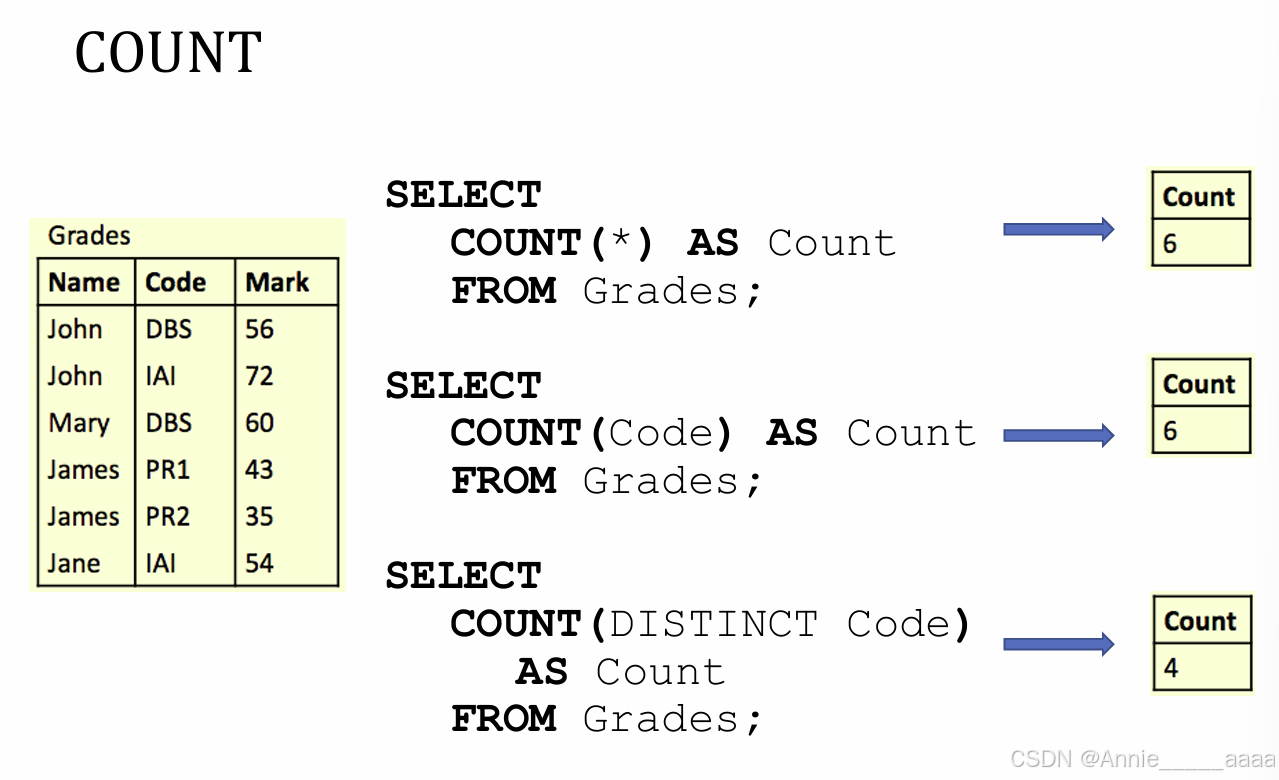
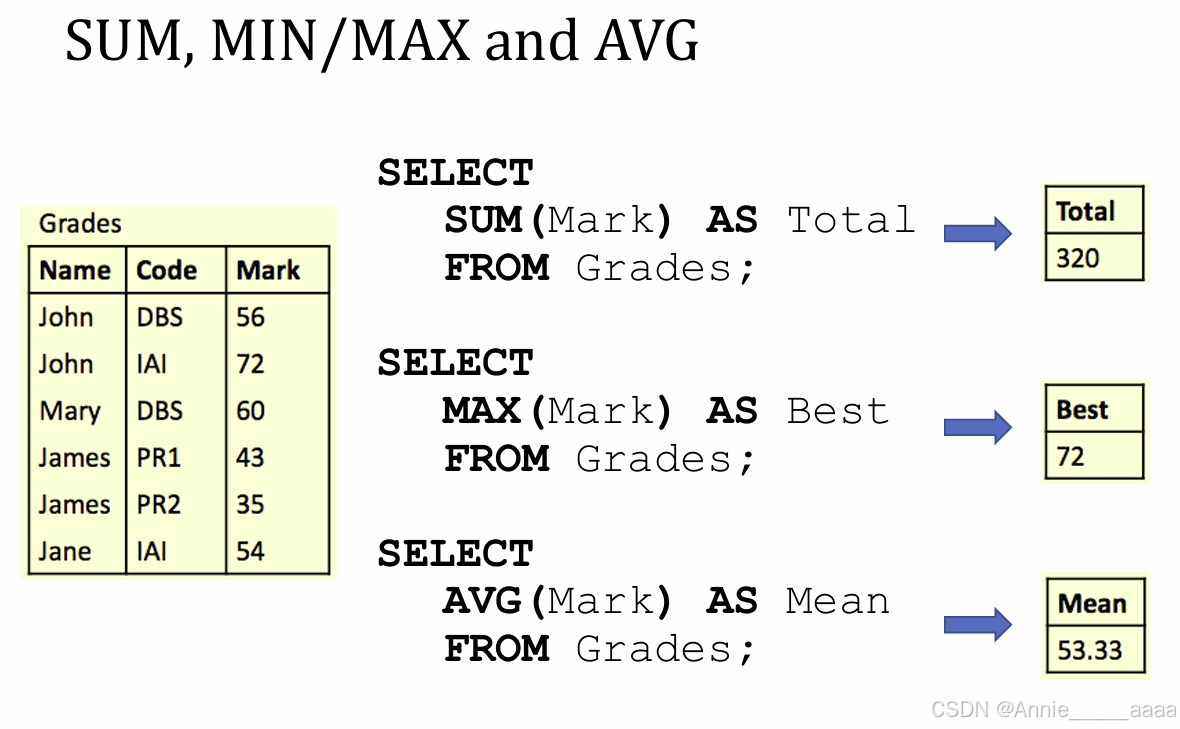

●不能直接在WHERE里用,但是可以在WHERE的subqueries里用

Also can use in HAVING clause

JOIN
JION:


会展示A和B的列的所有组合

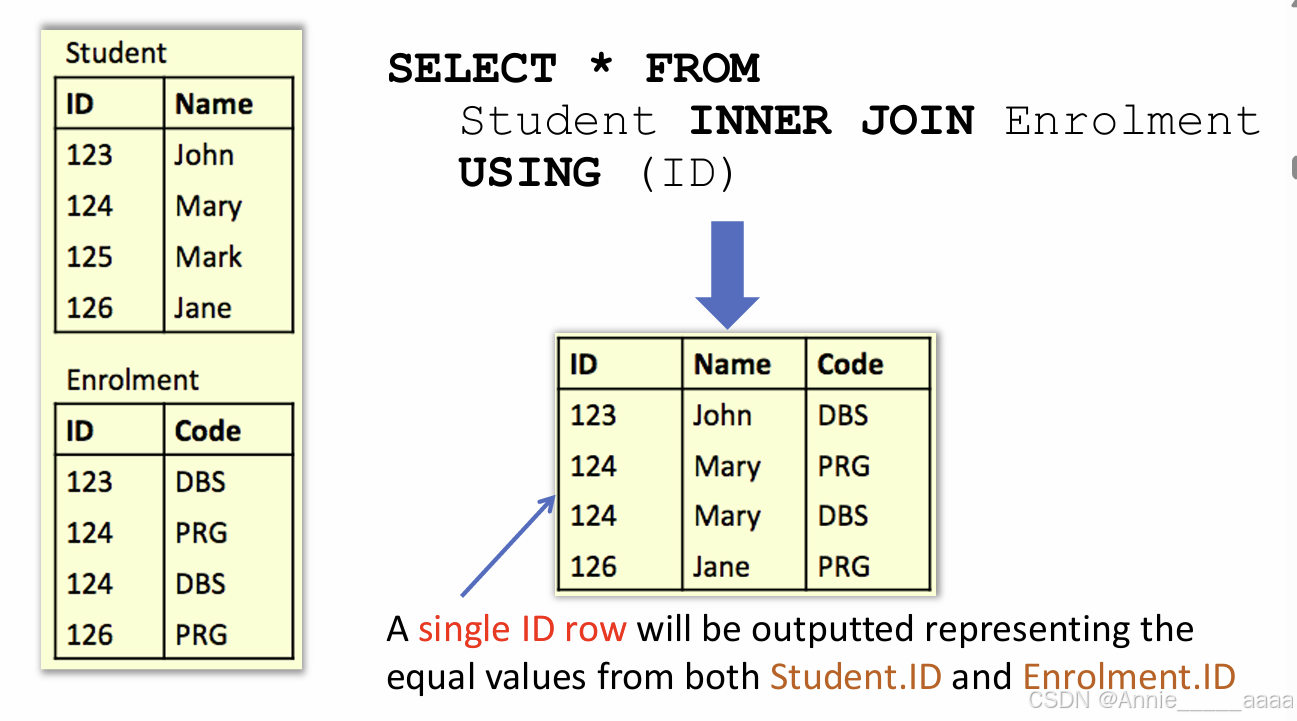

A NATURAL JOINis effectively a special case of an INNER JOINwhere the USING clause has specified all identically named columns .(natual join 会自己找到相同名称的列,不用特意用using指明列)


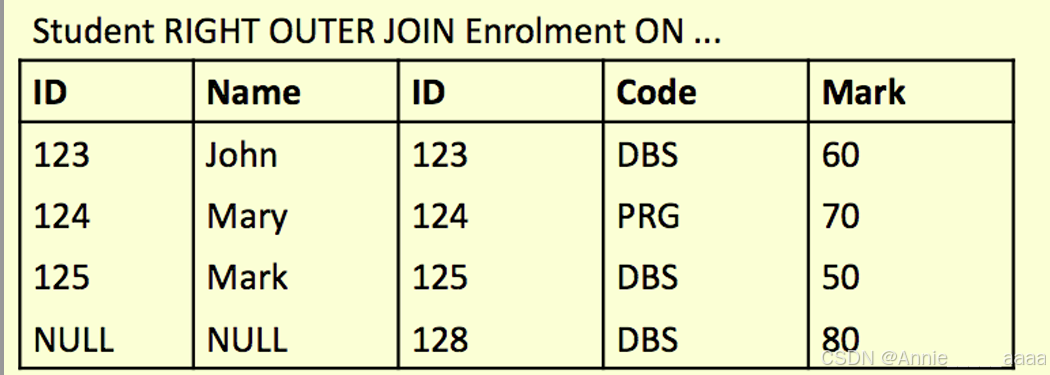

Since FULL OUTER JOIN is not supported in MySQL, so FULL OUTER JOIN can be replaced by using UNION LEFT OUTER JOIN and RIGHT OUTER JOIN

on后加布尔表达式 e.g.s.x = e.y
USING只能用于inner join和natural join
syntax:后跟随一个或多个列名
ON VS USING:
- ON 用于指定连接条件,适用于任何类型的连接,特别是在列名不同或需要复杂连接条件时。
- USING 用于简化连接条件,特别是当两个表之间有相同列名时,适用于内连接或自然连接。
WHERE
Take parameters and return true or false
WHERErefers to the rows of tables, so cannot make use of aggregate functions
True:kept row

False:delete row

Three-valued logic
NULL,true,false的运算
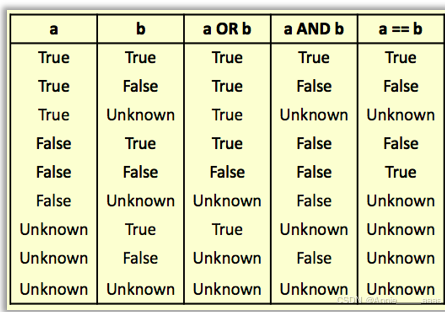
Null
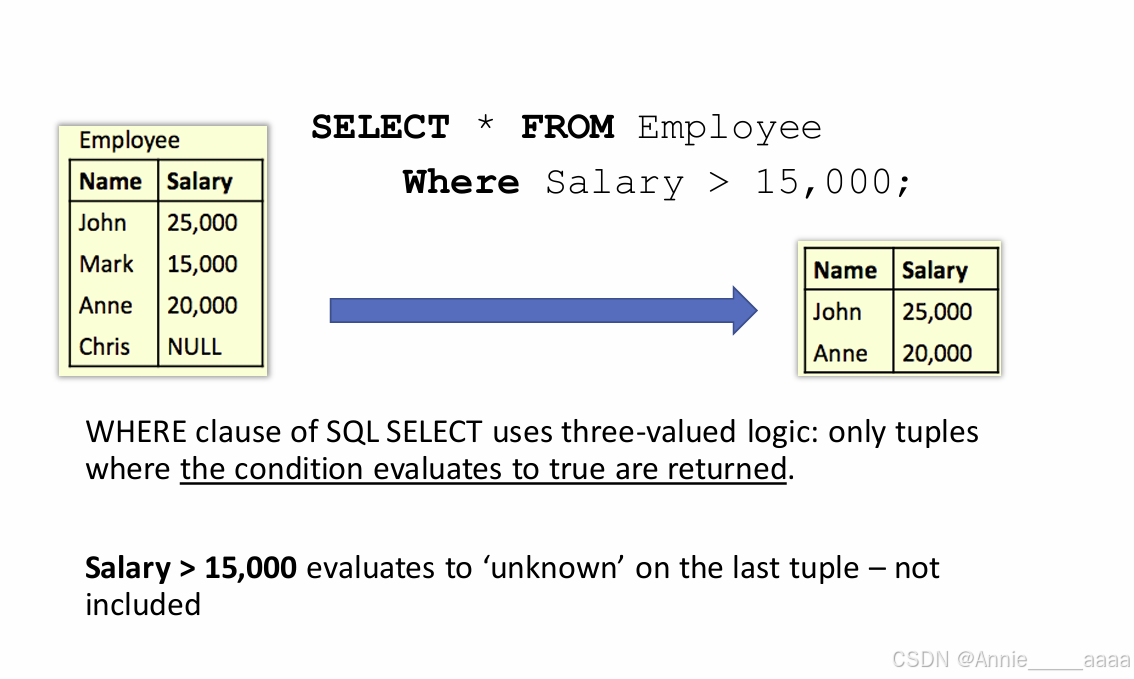
in conditions
1、数值的><=:
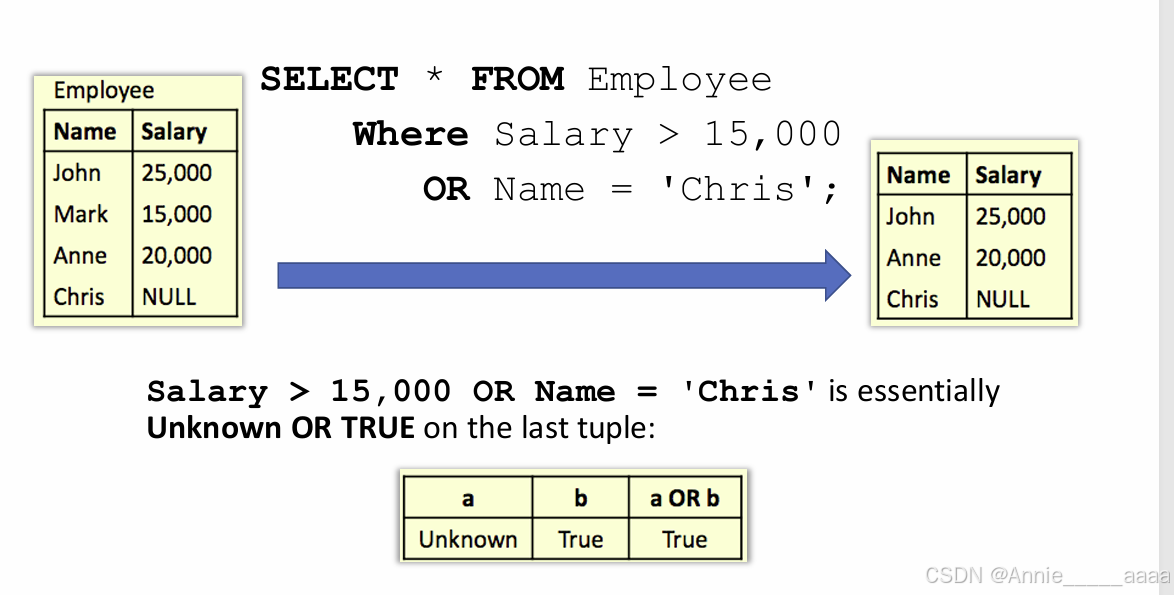
2、字符串=:
In arithmetic
In aggregation

In GROUP BY

In ORDER BY

GROUP BY

Use aggregate functions e.g.

HAVING
- Similar to WHERE,but happens after GROUP BY
- refers to the groups of rows, and so cannot use columns or aggregate functions that does not exist after the step of column selection.
e.g.

HAVING VS WHERE
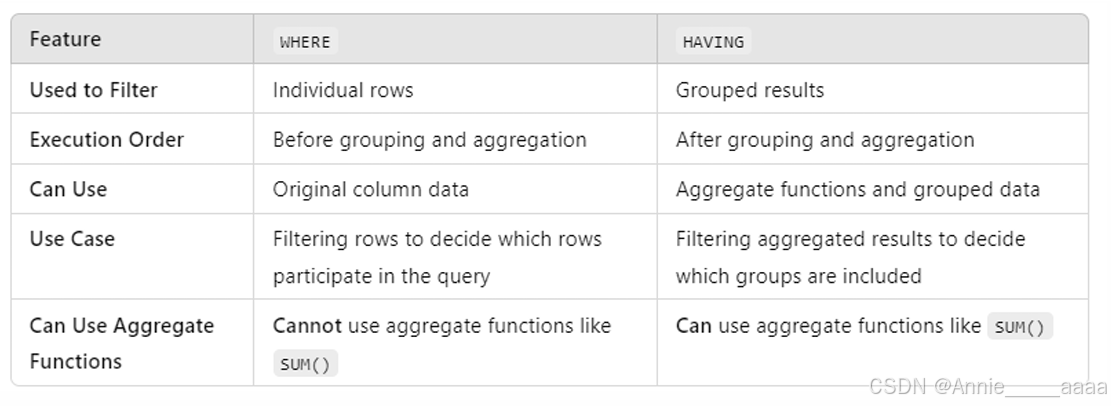
ER modeling(Entity-Relationship Modelling)
Components
1、Entities: objects or items of interest. (e.g.题目中名字,作为一个表)
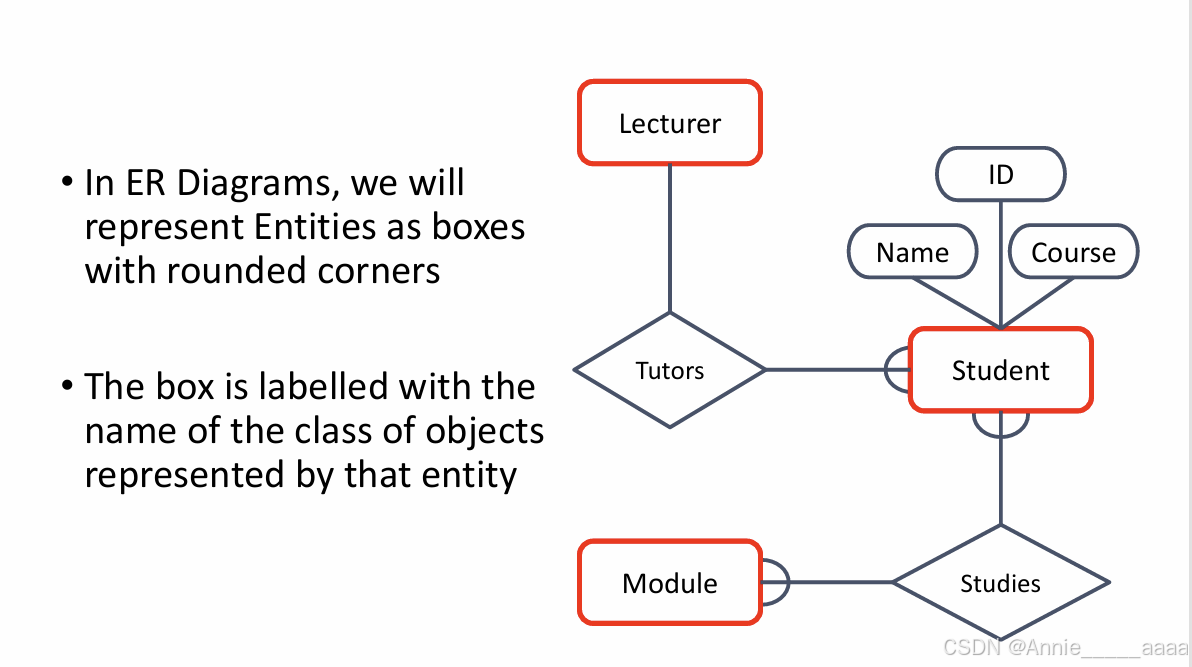
2、 Attributes: properties of an entity.(用椭圆表示,下面那个图的形状
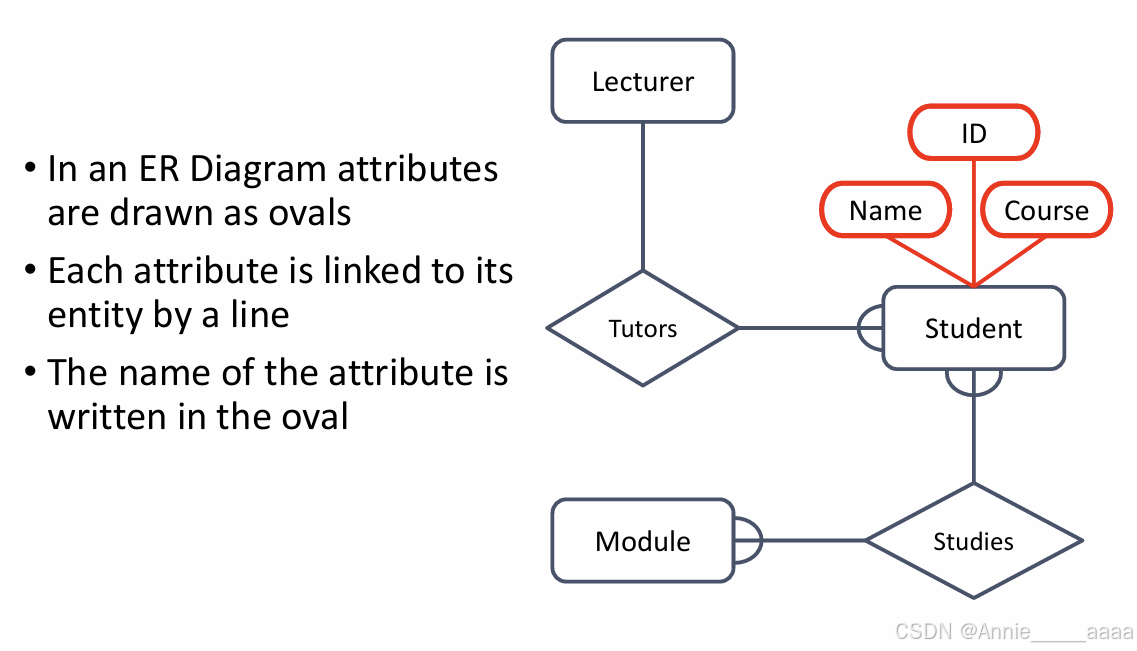
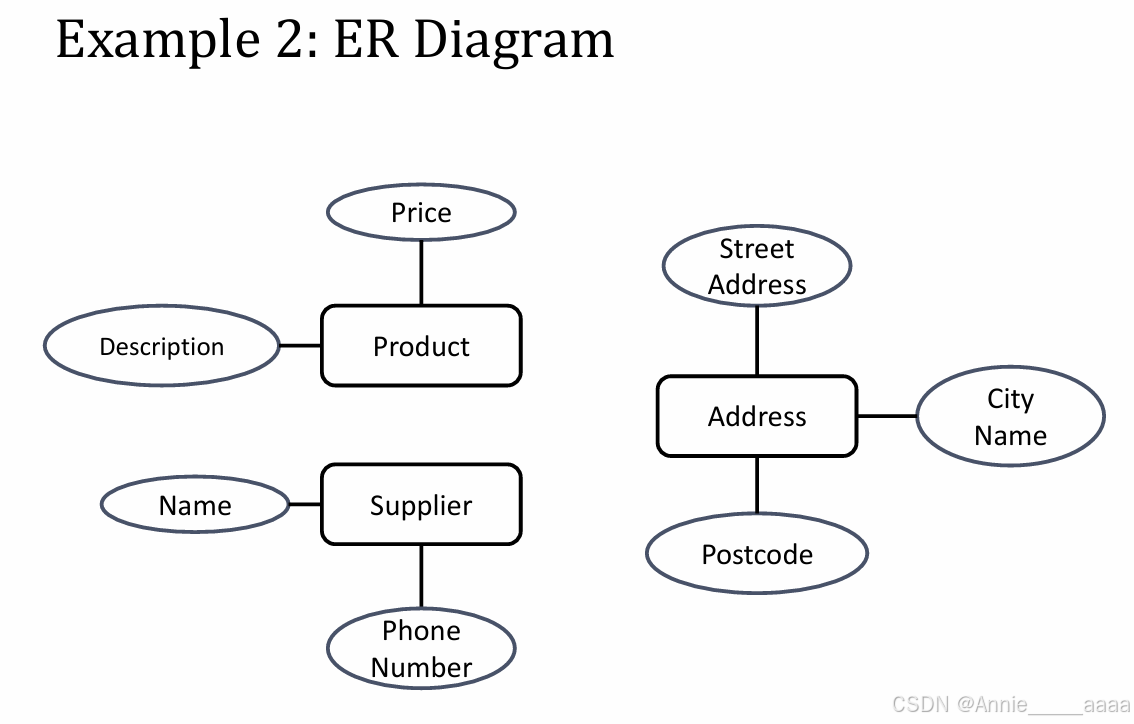
3、Relationships: links between entities.(e.g.题目中动词)

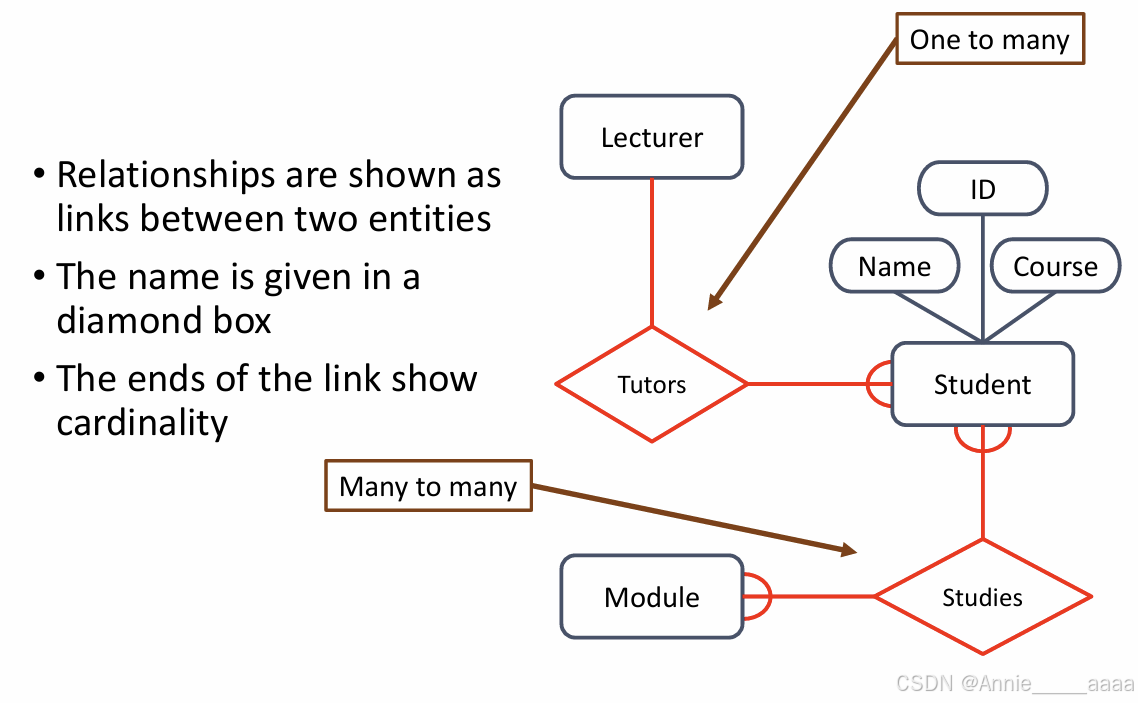
How is this relationship(one to many)reflected in database tables?:
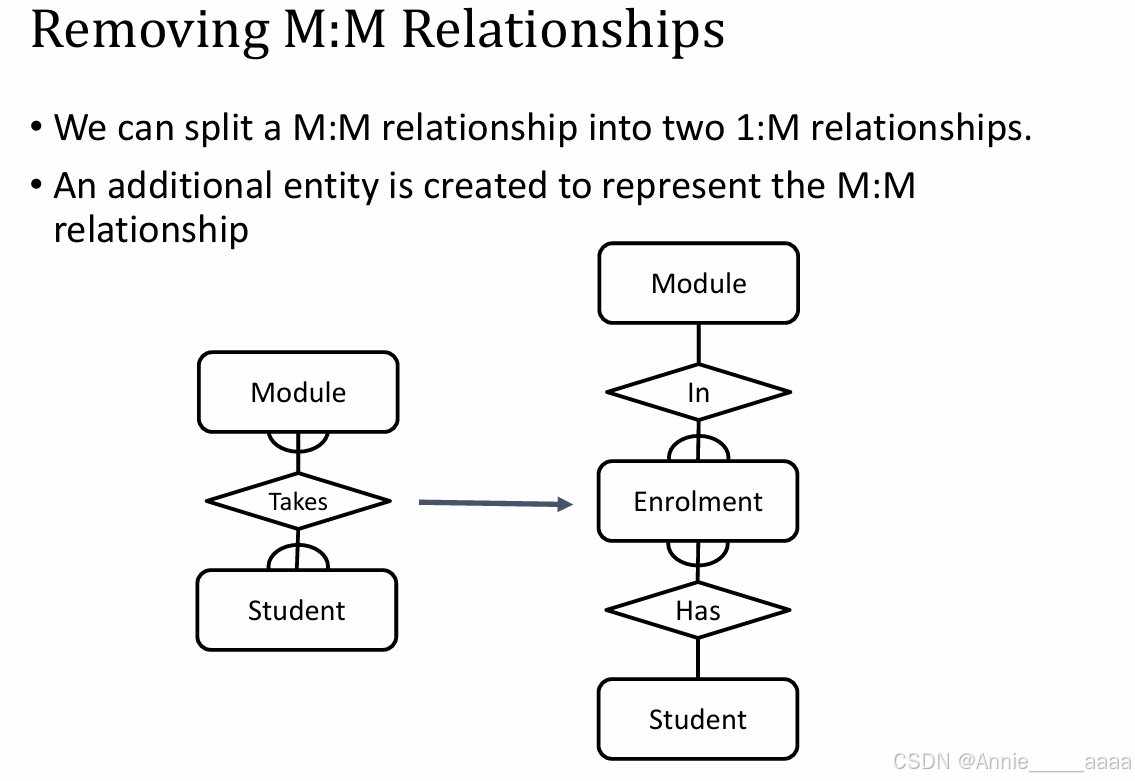
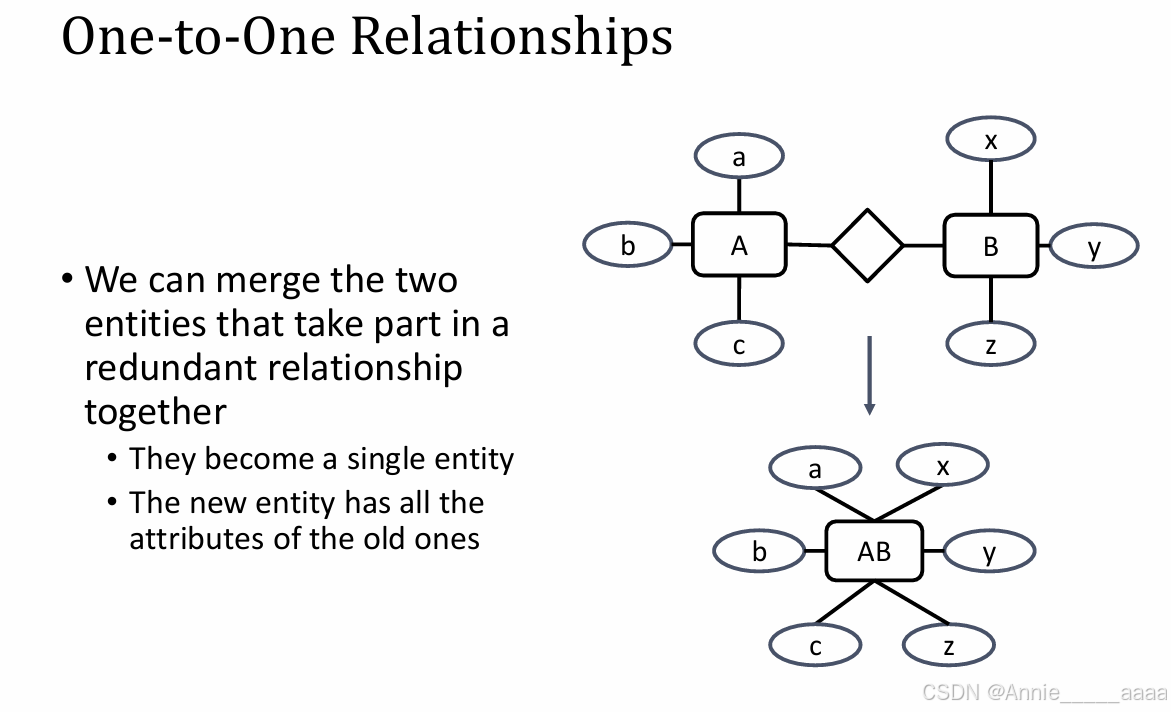
M:M 和 One-to-One relationships 要根据实际情况决定是否拆分或合并
entities vs attributes
to sql tables

normalisation
Functional Dependencies
Def: If A and B are attribute sets of relation R, B is functionally dependent on A (denoted A → B), if each value of A in R is associated with exactly one value of B in R
Full functional dependency(完全函数依赖):B 依赖于 A 的所有属性,不能移除 A 中的任何一个属性而不破坏依赖关系。
Partial FDs(部分函数依赖):B 依赖于 A 的部分属性,可以移除 A 中的某些属性而依赖关系仍然成立。
Determinant
Determinants in full functional dependencies: Will become candidate keys if we split the table
Determinants in partial functional dependencies: Will become super keys.
1:1,M:1, M:M
Transitive Dependency
Transitive dependency describes a condition where A, B, and C are attributes of a relation such that if A → B and B → C, then C is transitively dependent on A via B ( provided that A is not functionally dependent on B or C )
Normal Forms
第一范式(1NF):确保每个列的值是原子性的,不可再分。Need to update and delete manually
第二范式(2NF):消除非主键列对主键的部分依赖,确保非主键列完全依赖于整个主键。做法:将partial dependency的组合拆分出去,把剩下的元素和所有primary key放在一起。
第三范式(3NF):消除非主键列之间的传递依赖,确保 非主键列之间不存在传递依赖。做法:将transitive dependency安装箭头拆分,其余不变。
拆分一个表的简便做法
法1、

法2、

Good DB design

Normalisation is a technique of re-organising data into multiple related tables, so that data redundancy is minimised
(Reduce redundancies减少冗余)



















 53万+
53万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









