








题目:FCMNet: Frequency-aware cross-modality attention networks for RGB-D salient object detection
论文地址:
https://www.sciencedirect.com/science/article/abs/pii/S0925231222003848
创新点
-
频域跨模态注意力模块 (FACMA):作者提出了一种频率感知的跨模态注意力模块,以增强和选择 RGB 和深度图的互补特征。该模块设计了一个空间频率通道注意力(SFCA)子模块,能够在空间和频率域中提取互补信息。这一模块从频域角度出发,不同于传统的仅基于空间和通道的注意力机制,能够更好地保留不同模态之间的特征互补性。
-
加权跨模态融合模块 (WCMF):为了提高融合效果,作者提出了一个加权跨模态融合模块,通过学习内容相关的权重图来自适应地融合不同模态的特征,弱化低质量深度图的影响。此外,该模块还通过非线性特征增强(NFE)单元提高了融合过程中网络的非线性表示能力。
-
性能对比与效果验证:论文在八个基准数据集上进行了实验,并与17种最新的 RGB-D 显著性检测方法进行对比,在四种评价指标(如 S-measure、F-measure、MAE 和 E-measure)上均取得了最佳或接近最佳的结果,这展示了所提出模型的有效性和鲁棒性。
方法
整体结构
该论文提出的模型(FCMNet)采用双流编解码结构,由RGB和深度两个对称的VGG-16网络构成。通过频域跨模态注意力模块(FACMA)从RGB和深度模态中提取和增强互补特征,再利用加权跨模态融合模块(WCMF)进行内容自适应的融合,确保低质量深度图的干扰最小化。解码器使用膨胀空间金字塔池化模块逐步整合多尺度特征,同时加入边缘监督以提升显著性目标的边缘细节,从而实现高精度的RGB-D显著性检测。
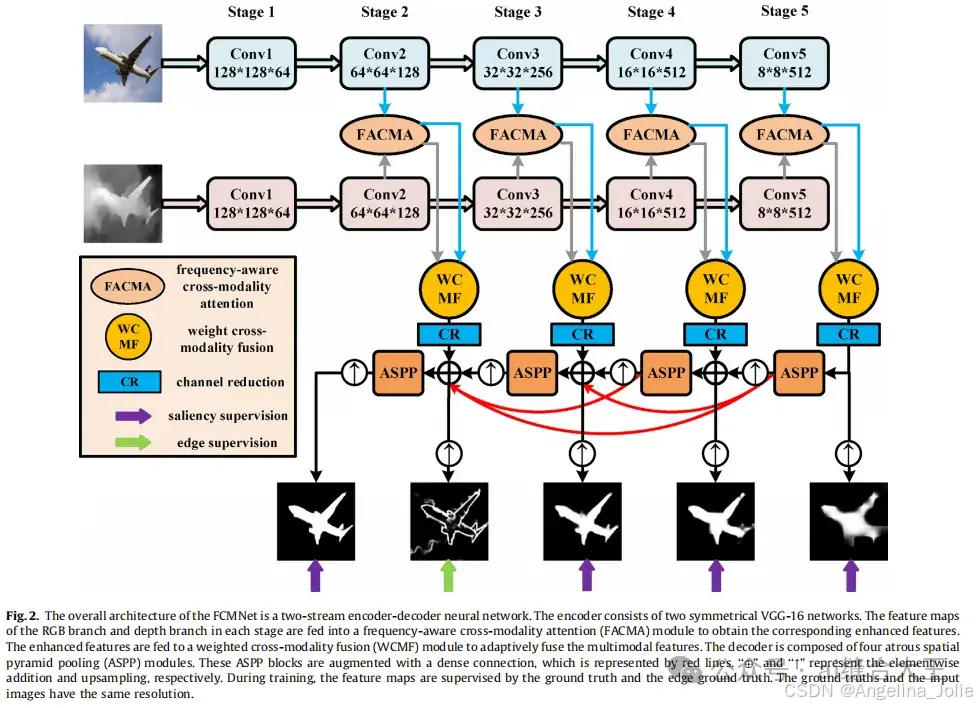
-
输入与编码器:模型输入为RGB图像和深度图像。为了匹配维度,深度图像被复制成三个通道。编码器由两个对称的VGG-16网络组成,分别提取RGB和深度的特征,每一层的输出特征被定义为FRGBiF^i_{RGB}和FDiF^i_D。
-
频域跨模态注意力模块 (FACMA):编码器输出的特征首先进入FACMA模块,该模块通过空间频率通道注意力(SFCA)模块从RGB和深度两个模态中提取互补特征。在此过程中,RGB特征和深度特征在空间和频率域内进行相互作用,以确保模型能够捕获两种模态的独特信息。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 890
890

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









