



继续看技术,看RAG问题,看看它纹眉用于处理高分辨率HR图像问题,我的理解是,很硬的一个图像压缩方法,本质上是利用RAG来增强MLLM的长上下文能力。
实际上,理解高分辨率图像对多模态大模型而言并不好做。
现在,有几个思路。
裁剪法(如LLaVA-v1.6、LLaVA-ov):将图像分割为多个块独立编码,但需对HR图像下采样,导致细粒度细节大量丢失。
HR视觉编码器法(如Deepseek-VL、LLaVA-HR):通过SAM、ConvNeXt提升HR理解,但仍受限于视觉token序列长度,无法处理8K等超HR图像。
搜索法(如DC²、ZoomEye):自上而下树搜索提取相关区域,但初始阶段难以感知小目标,易产生错误搜索路径。
所以,可以使用RAG来做个优化,如:
通过检索与查询相关的图像块,替代原始HR图像输入MLLM,在降低输入分辨率的同时保留关键视觉信息,解决MLLMs处理HR图像的局限。
因此,看两个思路。
多总结,多归纳,多从底层实现分析逻辑,会有收获。
一、多模态RAG用于高分辨率图像感知任务
看一个工作《Retrieval-augmented perception: High-resolution image perception meets visual rag》(https://arxiv.org/pdf/2503.01222,https://github.com/DreamMr/RAP),其核心思路在于通过 VisRAG 检索与查询相关的图像块,并利用Spatial-Awareness Layout保留图像块的相对空间关系,同时借助Retrieved-Exploration Search(RE-Search),基于模型置信度和检索分数动态选择最优图像块数量。
看具体实现:
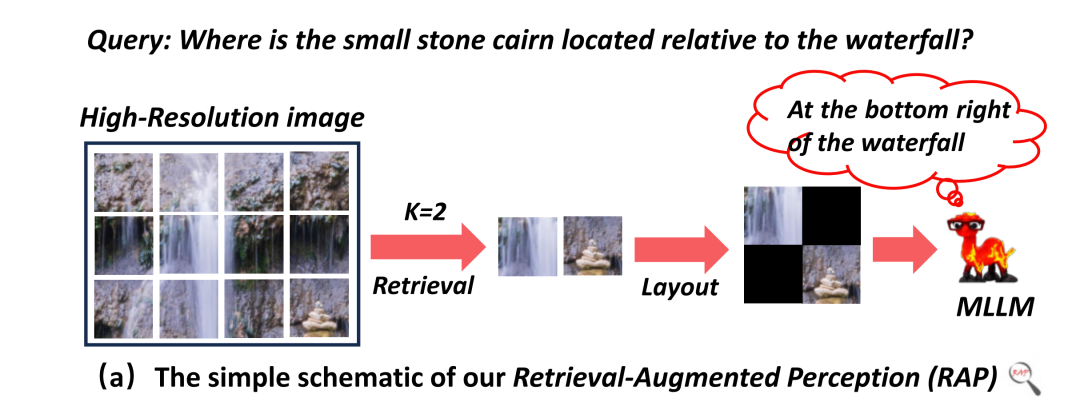
1、先看思路
思路很简单,流程如下:
【图像分块】将HR图像按检索器(VisRAG)的偏好分辨率分割为图像块集合;->【相似度计算】用VisRAG分别编码查询与图像块,通过余弦相似度计算;->【最优K选择】通过RE-Search搜索RE-Tree,确定最优K值及对应的top-K图像块;->【图像合成】用Spatial-AwarenessLayout合成新图像->【MLLM推理】将新图像输入MLLM,生成查询答案。
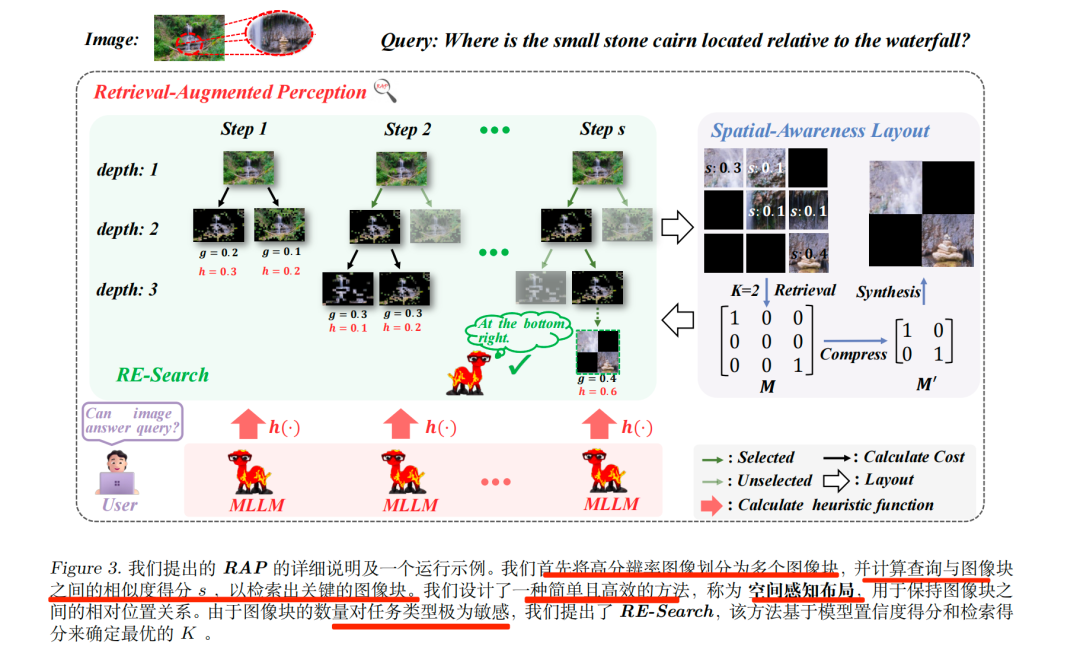
具体展开来看,核心思路是:
首先,VisRAG首先用于计算每个图像裁剪区域与查询之间的相似度得分。
其次,保留相似度得分最高的前K个裁剪区域,通过空间感知布局确保它们之间的相对空间关系得以保留。
这个布局方式有三种布局策略,如按检索分数升序排列;按图像块原始出现顺序排列;保留图像块的相对空间关系,也就是Spatial-Awareness Layout,核心思路是:通过二进制矩阵标记需保留的图像块,压缩矩阵以保留含有效图像块的行/列,再通过空间映射函数将压缩矩阵的坐标对应回原始图像位置,最终合成保留相对空间关系的新图像。
最后,选择的topk个图像,为了确定最优的K,构建了一个RE-Tree,其中每个结点代表通过保留不同比例的图像裁剪区域而合成的新图像。
具体的,也是得分计算,以“图像块与查询的相似度(g(t))”和“模型对图像信息充足性的置信度(h(t))”为成本,通过动态调整权重w(随树深度变化)计算总成本f(t),自适应搜索最优K值。
2、再看结论
检索与查询相关的图像块是提升MLLMHR感知性能的关键,随机保留图像块效果远差,保留图像块的相对空间关系对FCP等依赖空间推理的任务不可或缺。
二、MRD多分辨率检索方案
前面的方案算是给了一个基础,其通过最相关的图像块以定位目标对象并抑制无关信息,但这种基于图像块的处理方式可能导致完整物体被分割到多个图像块中,从而破坏语义相似度的计算。不同大小的物体在不同分辨率下处理效果不一样。
总结看,有多个问题。
一个是目标分割:图像切块导致完整目标分散,破坏语义相似性计算,部分无关切块获异常高相似度。
一个是单分辨率超参难调:块尺寸过大引入冗余背景,过小加剧目标分割,分辨率对性能影响显著(实验显示 112 分辨率整体最优,但部分样本需其他分辨率)。
一个是背景干扰:高分辨率图像背景复杂时,背景区域易被误判为目标,导致误检。
所以,做个小优化,通过“多分辨率语义修正+全局目标检测”,提升高分辨率图像理解精度。
看工作:《MRD: Multi-resolution Retrieval-Detection Fusion for High-Resolution Image Understanding》,https://arxiv.org/pdf/2512.02906,思路是通过多分辨率语义融合整合不同分辨率下的语义相似性图,修正单分辨率分割带来的语义偏差并保留目标完整性,同时引入开放词汇目标检测(OVD)模型(基于滑动窗口遍历全图)生成检测置信图;最终将两种图线性融合。
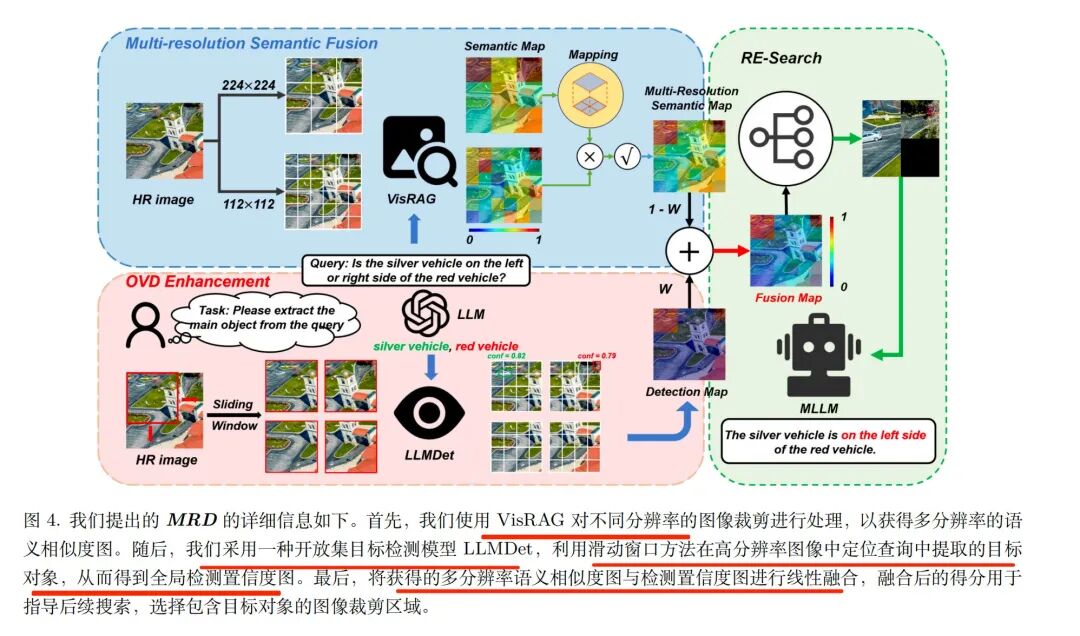
1、step1-多尺寸切图+融合
首先,分辨率设置,采用高、低两种比例分辨率,高分辨率块对应4个低分辨率块。
其次,语义映射?基于VisRAG模型计算两种分辨率下的语义相似性得分后,将高分辨率得分映射到对应的低分辨率块位置,建立不同分辨率的语义关联;
最后,一致性融合。对低分辨率块的“原始语义得分”与“映射后的高分辨率语义得分”做几何平均,修正单分辨率下因目标分割导致的部分块语义得分偏低问题。
这里的逻辑在于:既然一个尺寸切图有问题,就用两个不同尺寸(比如“粗切”和“细切”)分别分析,再把两个尺寸的分析结果结合起来,这样不管是大目标还是小目标,都尽量保持完整,不会被切得乱七八糟;
2、step2-加个“目标定位器”
引入OVD开放目标检测模块(LLMDet模型),做高分辨率图像的全局目标直接定位,生成检测置信图,与语义相似性图融合后抑制背景干扰、强化目标区域响应,解决精准定位大目标及背景误检的问题。
实现逻辑是按网格分割高分辨率图像(如VBench分块数n=H×W),用滑动窗口(VBench窗口尺寸1232、步长896)遍历全图,检测每个窗口内目标并生成边界框与置信度,过滤低置信检测(阈值τ),为每个块分配最大置信度,越大的地方越可能是目标;
3、step3-结合两个结果
把“多尺寸分析结果”和“置信图”合并。
从结论上看,多分辨率检索-检测,可以提升大模型对高分辨率图像的理解能力。
采用多分辨率语义相似度来修正单分辨率相似度图,确保目标物体的完整性。
此外,为更准确、直接地定位目标物体,引入OVD模型,通过滑动窗口方法识别物体区域,也是有效的方案。
那么,如何系统的去学习大模型LLM?
作为一名深耕行业的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
所以我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需要全套 《2025全新制作的大模型全套资料》,扫码获取~

👉大模型学习指南+路线汇总👈
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。


👉①.基础篇👈
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt使用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。

👉②.进阶篇👈
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高开发效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。

👉③.实战篇👈
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。

👉④.福利篇👈
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

















 24万+
24万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









