




“我是做后端的,能不能转大模型?”
“我在看一些课程,不知道该学哪些才有用?”
“我试着搭了个模型,发现全是坑,是不是我不适合?”
大模型怎么转?适合哪些人?哪些方向对新手友好?又有哪些坑你必须避开?
文章有点长,如果你真的想搞懂大模型、入场不踩坑,建议认真读完,或先收藏慢慢看。
一、 入行大模型的4大方向
大模型相关岗位基本可以分为这四类:
| 类型 | 岗位关键词 | 适合人群 |
|---|---|---|
| 1. 数据方向 | 数据构建、预处理、标注、数据质量评估 | 适合零基础/转行者,入门门槛低,上手快 |
| 2. 平台方向 | 分布式训练、资源调度、模型流水线 | 适合工程背景(后端/DevOps/大数据) |
| 3. 应用方向 | LLM算法、RAG、AIGC、对话系统 | 适合有转行 |
| 4. 部署方向 | 模型压缩、推理加速、端侧部署 | 系统能力强、做过底层开发的人更有优势 |
为什么要先讲这个?
因为太多人一上来就“我要搞算法”、“我想调模型”,结果发现自己根本没有训练数据、搞不清pipeline、代码跑不起来,最后就放弃了。
这不是你不行,而是选错了切入角度。
二、新人最容易犯的3个典型误区
误区1:只想搞模型,根本没想清要解决什么问题
很多新手“理想中的工作”是:
- 在大厂模型组里调ChatGPT
- 每天改超参、训练、测试效果
但真实情况是:
- 真正“调模型”的人不到团队的5%
- 大部分新人做的都是“链路搭建 + 数据清洗 + demo验证”
建议你:把目标从“调模型”转成“做出能跑起来的模型服务”,哪怕是个对话demo,也比纸上谈兵有用得多。
误区2:盲目学习所有热门词,却没搞懂底层逻辑
LoRA、SFT、RLHF、vLLM、QLoRA……
很多人听到这些名词眼睛一亮,像打卡一样都想学一遍,但最后变成“啥都看过,啥都不会”。
其实大模型的学习应该是“问题驱动”,你要围绕业务问题,反推需要哪些技术。
举个例子:你要做一个知识问答机器人,那你至少得搞懂:
- 向量检索(RAG)
- 数据清洗和知识构建
- 模型部署(推理延迟控制)
而不是“我会LoRA,我也会SFT,但不知道该用在哪里”。
误区3:忽略工程能力,以为搞AI就不用写脚本了
不好意思,很多大模型工作,本质就是——工程活。
你要写爬虫拿数据,要用Python跑数据处理链路,要部署模型到服务器,还得调各种依赖和环境。
所以,不会写代码,只想看论文,是做不好大模型相关工作的。
你是做业务的,那就要能把AI工具接到真实系统;你是做平台的,那就要搞定分布式系统配置;你是做数据的,那就要能用脚本快速生成训练数据集。
三、哪个方向适合你入门?
① 数据方向:新人最容易上手的黄金入口
别小看“做数据”,它其实是目前大模型里面最容易切入、最容易出成绩、最容易落地的方向。
你要学的内容包括:
- 数据清洗、过滤、格式统一
- 有毒数据识别(脏话、敏感内容)
- prompt-响应对构建
- 评测集设计(准确率、覆盖率等)
推荐工具链:
Python / Pandas / LangChain / label studio / 数据增强脚本 / Excel也能用
适合人群:
- 完全转行的小白
- 没有模型背景但逻辑好、细节控的人
注意事项:
- 千万不要小看数据清洗,它决定了你训练出来的模型质量
- 很多大公司现在就是因为数据链路做不好,效果再强的模型也不稳定
一句话总结:数据不是脏活累活,而是最容易打出成果的一块阵地。
② 平台方向:工程师转行首选,高价值低风险
如果你之前有写后端、搞大数据、做K8s、玩过分布式系统的经验,那这个方向太适合你了。
平台岗主要负责什么?
- 构建训练pipeline:数据加载、预处理、模型训练、评估
- GPU资源调度:混部、监控、资源管理
- 自动化训练/推理系统搭建
核心能力:
- Python + Shell 脚本能力
- 熟悉 Docker / Kubernetes
- 熟悉 DeepSpeed / FSDP / NCCL 等训练优化框架
项目思路:
- 搭建一个LoRA训练平台,接收数据即可训练
- 设计一个多GPU并行推理的小平台
风险点:
- 工程偏多,适合愿意写代码、搞部署的人
- 如果抗拒写脚本调系统,那就别碰了
③ 应用方向:最卷也最诱人的一块
这块是大模型最“显眼”的岗位,比如你看到的对话系统、AIGC生成工具、搜索问答、智能客服……都属于这个方向。
主要内容:
- Prompt工程:设计提示词结构,提高响应质量
- 多模态交互:文本+图像+语音的整合
- 应用系统接入:接第三方API、加上业务逻辑、部署上线
推荐学习路径:
- 掌握LangChain / LlamaIndex 等中间件
- 学会RAG基本实现(检索+生成)
- 理解如何评估一个大模型输出质量
注意:
- 想进这个方向,业务sense很关键。你得知道你解决的是什么问题。
- 对于简历来说,最好有真实场景demo,比如“帮某企业搭建了法务问答机器人”。
建议新手:先从数据方向做几轮项目,等理解了底层,再切入应用,胜率更高。
④ 部署方向:高门槛、高回报,但不是新手切入点
部署工程师是被严重低估的工种。为什么?
因为你一旦把推理效率提升了2倍,就是实实在在地给公司省钱了。
岗位常做的事:
- 推理加速:TensorRT、ONNX、vLLM、量化、裁剪
- 小模型构建:蒸馏、低秩分解、KV缓存复用
- 多卡部署:多租户并发服务、模型冷热加载优化
建议先别直接跳:
- 如果你没有系统开发背景 / 没有玩过CUDA / 没调过C++框架,就别硬上
- 更合理的做法:从平台转部署,从实战中积累经验
四、你该怎么开始准备?(AI大模型系统学习路线)
学习新技能,方向至关重要。 正确的学习路线图可以为你节省时间,少走弯路;方向不对,努力白费。
这里,我们为新手小白和想要进一步提升的专业人士准备了一份详细的学习成长路线图和规划。可以说是最科学最系统的大模型学习成长路线。
2025最新AI大模型系统学习路线,有需要的小伙伴可以微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】

第一阶段 大模型基础入门【10天】
这一阶段了解大语言模型的基础知识,以及大模型在各个行业的应用和分析;学习理解大模型的核心原理,关键技术,以及大模型应用场景;掌握Prompt提示工程。
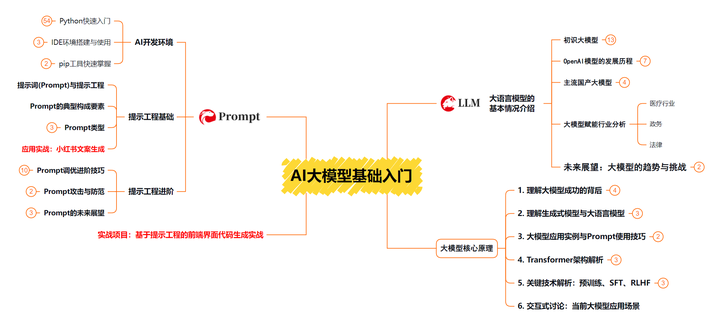
配套学习资源

第二阶段 大模型进阶提升【40天】
这一阶段学习AI大模型RAG应用开发工程和大模型Agent应用架构进阶实现。
- AI大模型RAG应用开发工程:包括RAG检索增强生成、Naive RAG、Advanced-RAG以及RAG性能评估,还有GraphRAG在内的多个RAG热门项目的分析。
- 大模型Agent应用架构进阶实现:学习LangChain、 LIamaIndex框架,也会学习到AutoGPT、 MetaGPT等多Agent系统,打造我们自己的Agent智能体;同时还可以学习到包括Coze、Dify在内的可视化工具的使用。
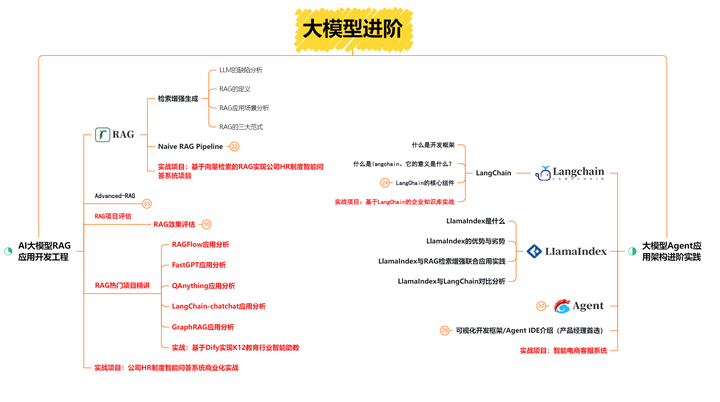
配套学习资源

第三阶段 大模型项目实战【40天】
这一阶段学习大模型的微调和私有化部署,我们会更加深入的探讨Transformer架构,学习大模型的微调技术,利用DeepSpeed、Lamam Factory等工具快速进行模型微调;并通过Ollama、vLLM等推理部署框架,实现模型的快速部署。
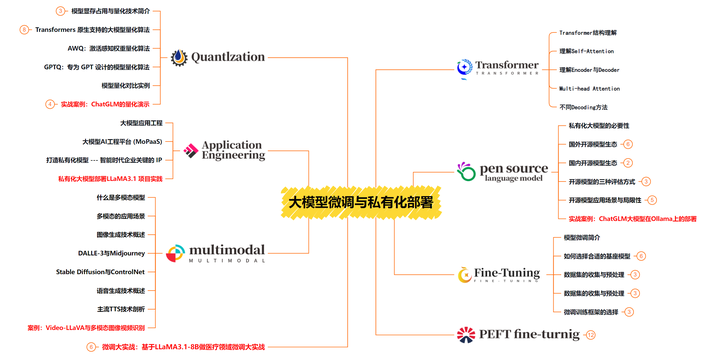
配套学习资源

第四阶段 面试
面试,不仅是技术的较量,更需要充分的准备。当你已经掌握了以上的大模型技术之后,就需要开始准备面试,我们还精心整理了大模型面试题库,涵盖当前面试中可能遇到的各种技术问题,让你在面试中游刃有余。

机会总是留给有准备的人。 如果你需要学习大模型,那么请不要犹豫,立刻行动起来!
全套的AI大模型学习资源已经整理打包,有需要的小伙伴可以微信扫描下方优快云官方认证二维码,免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









