




 本文介绍了Android Transform插件的进阶使用,包括如何实现增量编译以提高编译速度,以及在自动化埋点过程中参数的传递。通过抽象Transform流程,作者展示了如何优化编译时间和ASM操作,并分享了使用ClassNode进行复杂类修改的技巧。
本文介绍了Android Transform插件的进阶使用,包括如何实现增量编译以提高编译速度,以及在自动化埋点过程中参数的传递。通过抽象Transform流程,作者展示了如何优化编译时间和ASM操作,并分享了使用ClassNode进行复杂类修改的技巧。
前言
还是我那个90后的老安卓,这算是一篇自吹自擂的自嗨爽文。首先我写这个AndroidAutoTrack Demo的原因很简单,我就单纯觉得很好玩,然后同时其实对于自己的技术水平是会有成长的。我最近下班在优化以前写的自动化埋点。我看过很多文章介绍这个,但是我觉得都是一些入门相关的,很难有一些更深入一点的文章。
Plugin插件或者说Transform,我个人觉得说难其实也不难,但对于新入门的人来说,这个东西非常的不友善,gralde 官方资料都是英文的,然后Gralde Plugin的编写调试又比较繁琐,如果中间碰到了什么问题,如果没人带你一把,你也走进死胡同了。
所以并不是各位看下文章就能完全搞懂这个的,我个人觉得如果没有人带你的情况下,你基本很难学会这个东西。
开始我的表演
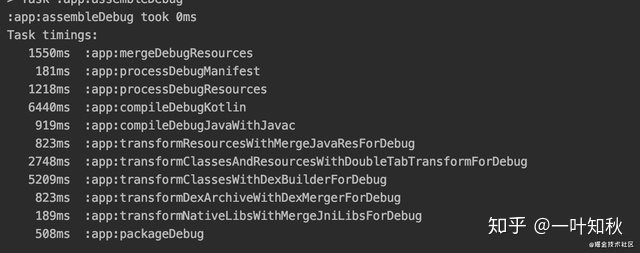
一个合格的Transform插件是需要增量编译的功能的,我拿我找到的文章数据给大家做个比较好了。
全量编译的情况下
二次增量编译情况下
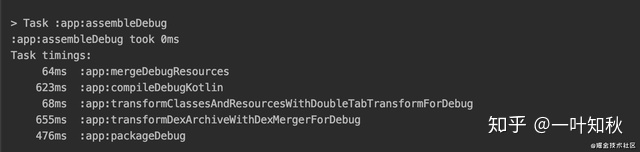
我们抛开别的Task,同样一个Transform全量编译的耗时是2784ms,而代码变更增量编译的情况下只有68ms。其中的差距之大也值得各位去把增量编译给写出来了。
当项目后期代码持续不断地增加之后,不可避免的Transform变多了,只要有任意的一个Transform不是增量的,就会导致整个编译Transform过程都变成全量。这个以前我也介绍过,其实有很多系统的Transform任务,比如Shrink和Dex合并等等。
你们想一想哦,一个人优化了1分半的编译时间的话,那么如果团队人员一多,那么岂不就是Kpi美滋滋。
如何去实现一个增编
首先我将Transform流程进行了一次抽象,主要是因为我比较懒,同样代码和功能如果要让我复制黏贴好两遍其实我都不乐意。所以我先对这部分代码进行了梳理,整理出来两个部分,第一就是文件的复制拷贝,第二就是文件的ASM操作。其中我觉第一部分的代码是可以进行整合的,然后就是下面的逻辑了。
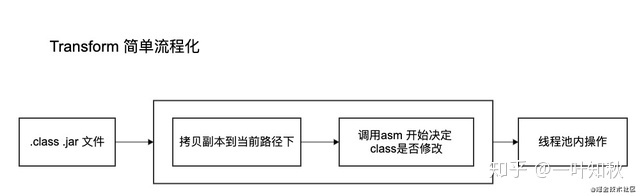
先从Transform开始吧,简单的说Transform就是一个输入文件集合Collection<TransformInput>一个输出文件集合TransformOutputProvider的过程。我们先读取原始的class jar,然后我们自己对其进行加工之后生成好另外一部分class jar,最后把这个Transform的输出产物当作下一个Transform的输入产物。当class+jar输入的时候,我会先把整个流数据进行一次copy操作,然后对这个temp文件进行加工,如果asm操作完了,我们就将文件进行覆盖操作。
而在增量编译的情况下,输入流就会发生轻微的变更,TransformInput会告诉我们其中变更的类是什么,其中变更被定义为三种,无论是Jar还是Class都是一样的。
- NOTCHANGED 当前文件不需要处理跳过就行了。
- ADDED、CHANGED 因为我们都是先用temp然后覆盖当前文件,所以采用同样的处理方式。
- REMOVED 删除当前文件夹下的该历史文件。
所以当增编被调用的情况下,我们只是对于上述这四种不同的操作符号进行不同的处理就好了,只要几个if else就能搞定了。
而一般我们在使用asm的时候,我们都只会操作Class文件,然后根据class的文件名+路径对其进行一次简单的判断,当前类是不是我们需要做插桩或者扫描操作的,然后我们会读取这个文件byte数组,之后在完成asm操作之后返回一个byte数组,之后覆盖掉原始文件。那么其实我在这里就对其进行了第一次的抽象,asm操作被我定义成了一个接口。
package com.kronos.plugin.base
interface TransformCallBack {
fun process(className: String, classBytes: ByteArray?): ByteArray?
}这个接口只负责接受一个文件名和一个byte数组,然后方法结束返回一个byte数组就行了。如果byte数组非空的情况下,代表当前类被进行了字节码修改操作,然后我们只要把这个文件进行一次覆盖操作就可以了。进行了这个抽象,我们就可以把上面的文件操作和ASM操作进行一次整合,sdk使用者只需要对这个接口负责就好了。
那么剩下来我们需要做的就是对这部分文件的写入进行封装了。我是怎么做的呢?我参考了另外一个大佬的多线程优化transform的思路,大佬的项目地址Leaking / Hunter
- 所有的输入文件先进行第一次文件拷贝操作
- forecah 遍历将每一个文件操作压入线程池中执行
- 获取文件名以及byte数组 调用我们定义的抽象接口
- 根据interface 返回的byte生成temp文件,然后进行文件覆盖操作
- 线程池等待所有任务执行完成之后结束transform
DoubleTap的编译速度优化
原来的DoubleTap plugin是整个项目的代码进行扫描的,虽然完成了增量编译功能,同时我也过滤了很多无效扫描的逻辑,但是其实还是会拖慢整个编译速度的。一直到我前一阵子学习了另外一个大佬的一个StringFog项目的时候,发现大佬的常量加密的Transform,可以直接对Module生效。
public class DoubleTapPlugin implements Plugin<Project> {
private static final String EXT_NAME = "doubleTab";
@Override
public void apply(Project project) {
boolean isApp = project.getPlugins().hasPlugin(AppPlugin.class);
project.getExtensions().create(EXT_NAME, DoubleTabConfig.class);
project.afterEvaluate(project1 -> {
DoubleTabConfig config = (DoubleTabConfig) project1.getExtensions().findByName(EXT_NAME);
if (config == null) {
config = new DoubleTabConfig();
}
config.transform();
});
if (isApp) {
AppExtension appExtension = project.getExtensions().getByType(AppExtension.class);
appExtension.registerTransform(new DoubleTapAppTransform());
return;
}
if (project.getPlugins().hasPlugin("com.android.library")) {
LibraryExtension libraryExtension = project.getExtensions().getByType(LibraryExtension.class);
libraryExtension.registerTransform(new DoubleTapLibraryTransform());
}
}
}以前我在写的时候一般只会给AppExtension注册一个Transform,而在LibraryExtension同样也可以注册一个Transform。在LibraryExtension上注册的会让这部分字节码操作被使用在使用了这个Plugin的Module上。
小贴士: 这个Transform同样会对Aar生效哦,不仅仅是本地产物。
而这个Transform的代码上最大的差别就是,其中的输入产物和类型有差别以外,其实别的代码全是一样的。
class DoubleTapLibraryTransform : DoubleTapTransform() {
override fun getScopes(): MutableSet<in QualifiedContent.Scope> {
return ImmutableSet.of(
QualifiedContent.Scope.PROJECT
)
}
override fun getInputTypes(): Set<QualifiedContent.ContentType>? {
return TransformManager.CONTENT_CLASS
}
}这边有个Scope作用域,InputTypes这几个参数大家可以参考下别人的文章 深入理解Transform
我个人的一个小看法哦,如果只是一个需要针对模块内修改的话,那么你完全不需要写一个全局操作的Transform,只需要对每个Module进行操作就好了。这样有几个好处,扫描速度会变得更快,因为我们不需要操作无关的Jar。另外如果Module没有变更的情况下就不会参与编译,可以变得更快。
自动化埋点的参数传递
我在写自动化埋点Demo的时候,一直没有特别好的解决关于参数的问题。以前留了个小坑,只能使用匿名内部类内定义的属性,而如果是外部类的话,因为asm中的ClassVisitor写起来,其实我感觉很不舒服,其原理都是基于事件的。当一个方法被触发之后你要记录下相关值,然后在另外一个函数内进行插入操作。
之前在做ThreadPoolHook的时候了解到滴滴的Booster内的asm用的都是ClassNode,这里我先简单的说下ClassNode好了。
ClassNode简介
如果你仔细读了关于字节码的文章后,你应该会知道Java中当一个方法被调用时会产生一个栈帧(Stack Frame),可以理解为那个方法被包含在了这个栈帧里,栈帧包括3个部分,局部变量区,操作数栈区和帧数据区.接下来我们主要要用到的是局部变量区和操作数栈区.
一般一句简单的java代码,被翻译成字节码的情况下复杂度都会翻好几倍,其中特别是Java字节码的栈帧。给一个方法传递参数,就是压栈的操作,所以当用ClassVisitor直接操作的时候,我想要修改一行代码,其实难度都非常大。
ClassNode是ClassVisitor的一个实现类,相比较于ClassVisitor,ClassNode已经存储记录了所有的ClassVisitor信息,构建好了语法树,包括方法内的代码以及行号,还有当前的类属性,类信息等等。其核心就是牺牲了内存,但是由于记录了所有类信息,所以对于复杂的多类联动的操作,会更加方便实用。
不过TreeAPI比CoreAPI慢30%左右,内存占用也高。
修改Class,我们只需使用ClassTransformer,然后在transform方法中修改对应的ClassNode即可。使用TreeAPI比CoreAPI更耗时,内存占用也多,但是对于某些复杂的修改也相对简单。 treeAPI被设计用于那些使用coreAPI一遍解析无法完成,需要解析多次的场景。
ClassNode传入参数
好了 show me the code 吧
class AutoTrackHelper : AsmHelper {
private val classNodeMap = hashMapOf<String, ClassNode>()
@Throws(IOException::class)
override fun modifyClass(srcClass: ByteArray): ByteArray {
val classNode = ClassNode(ASM5)
val classReader = ClassReader(srcClass)
//1 将读入的字节转为classNode
classReader.accept(classNode, 0)
classNodeMap[classNode.name] = classNode
// 判断当前类是否实现了OnClickListener接口
classNode.interfaces?.forEach {
if (it == "android/view/View\$OnClickListener") {
val field = classNode.getField()
classNode.methods?.forEach { method ->
// 找到onClick 方法
insertTrack(classNode, method, field)
}
}
}
//调用Fragment的onHiddenChange方法
visitFragment(classNode)
val classWriter = ClassWriter(0)
//3 将classNode转为字节数组
classNode.accept(classWriter)
return classWriter.toByteArray()
}
private fun insertTrack(node: ClassNode, method: MethodNode, field: FieldNode?) {
// 判断方法名和方法描述
if (method.name == "onClick" && method.desc == "(Landroid/view/View;)V") {
val className = node.outerClass
val parentNode = classNodeMap[className]
// 根据outClassName 获取到外部类的Node
val parentField = field ?: parentNode?.getField()
val instructions = method.instructions
instructions?.iterator()?.forEach {
// 判断是不是代码的截止点
if ((it.opcode >= Opcodes.IRETURN && it.opcode <= Opcodes.RETURN) || it.opcode == Opcodes.ATHROW) {
instructions.insertBefore(it, VarInsnNode(Opcodes.ALOAD, 1))
instructions.insertBefore(it, VarInsnNode(Opcodes.ALOAD, 1))
// 获取到数据参数
if (parentField != null) {
parentField.apply {
instructions.insertBefore(it, VarInsnNode(Opcodes.ALOAD, 0))
instructions.insertBefore(
it, FieldInsnNode(Opcodes.GETFIELD, node.name, parentField.name, parentField.desc)
)
}
} else {
instructions.insertBefore(it, LdcInsnNode("1234"))
}
instructions.insertBefore(
it, MethodInsnNode(
Opcodes.INVOKESTATIC,
"com/wallstreetcn/sample/ToastHelper",
"toast",
"(Ljava/lang/Object;Landroid/view/View;Ljava/lang/Object;)V",
false
)
)
}
}
}
}
// 判断Field是否包含注解
private fun ClassNode.getField(): FieldNode? {
return fields?.firstOrNull { field ->
var hasAnnotation = false
field?.visibleAnnotations?.forEach { annotation ->
if (annotation.desc == "Lcom/wallstreetcn/sample/adapter/Test;") {
hasAnnotation = true
}
}
hasAnnotation
}
}
}
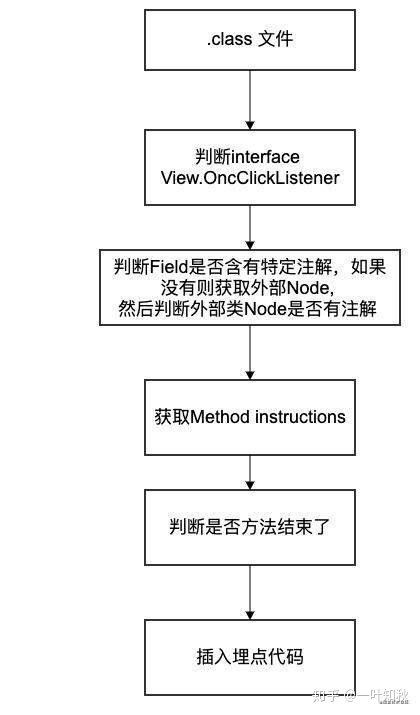
这次我顺便给大家画了一个这部分逻辑的流程图,方便大家可以搞懂这部分代码。这里顺便给大家展开下我之前用ClassVisitor的痛苦吧,这个地方可能是我的操作方式有问题哦。asm操作的是.class文件,每一个内部类其实都是.class文件,这部分扫描都是单独的,如果你要用内部类去访问一些外部类的Field,我是完全没办法的。因为两个类的实例都不同,然后我整个人都感觉有点裂开了。
这次使用ClassNode,我用HashMap保存了大部分类的ClassNode,然后通过outClassName,去获取到ClassNode实例,然后就可以对其进行修改了。
上面基本上就是我所有的插桩的代码了,其实基本上都是字符串匹配之类的,只是因为bytecode上的和java的不一样,而且bytecode的可读性比较差了点,之前也安利过大家asm bytecode viewer。还是很香的。
最后
在这里我也分享一份由几位大佬一起收录整理的 Flutter进阶资料以及Android学习PDF+架构视频+面试文档+源码笔记 ,并且还有 高级架构技术进阶脑图、Android开发面试专题资料,高级进阶架构资料……
这些都是我闲暇时还会反复翻阅的精品资料。可以有效的帮助大家掌握知识、理解原理。当然你也可以拿去查漏补缺,提升自身的竞争力。
如果你有需要的话,可以前往 GitHub 自行查阅。
相信一定可以帮助到大家


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









