 Elasticsearch集群搭建
Elasticsearch集群搭建





 本文详细介绍了如何在共享模式下搭建Elasticsearch集群,包括创建用户、上传与解压Elasticsearch包、配置防脑裂参数及安装可视化插件等步骤。
本文详细介绍了如何在共享模式下搭建Elasticsearch集群,包括创建用户、上传与解压Elasticsearch包、配置防脑裂参数及安装可视化插件等步骤。
目的:先让集群跑起来然后再细细研究
搭建步骤:
(前提:都配置了Java环境)
1.共享模式下给node01 node02 node03节点做如下四步:
[root@node01 ~]# useradd xc
[root@node01 ~]# echo hadoop | passwd --stdin xc
[root@node01 ~]# mkdir -p /opt/software/es
[root@node01 software]# chown xc:xc es
解释:
(1)useradd xc 创建xc用户,因为elasticsearch只允许普通用户操作,不允许root用户操作。
(2)echo hadoop | passwd --stdin xc 是给xc用户增加密码
(3)root 用户创建 /opt/sxt/es(普通用户无法创建) 创建存放es文件的目录:
mkdir -p /opt/software/es (注意:此时的目录权限属于root)
(4)chown xc:xc es 是把es目录的权限修改为xc用户
2. 上传es包并解压,记住创建一个文件夹比如software,然后把elasticsearch包放进去,
为什么呢?主要是为了让xc用户可以访问,如果在根目录,xc用户是无法访问的

因为是zip包不能用tar命令,所以需要安装一个zip解压工具

需要把elasticsearch解压到es目录,所以把管理员切换为xc,哪个用户解压,权限就属于哪个用户
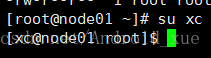
解压:

可以看到这个文件的权限为xc用户

进入es/config, 修改elastic配置文件:
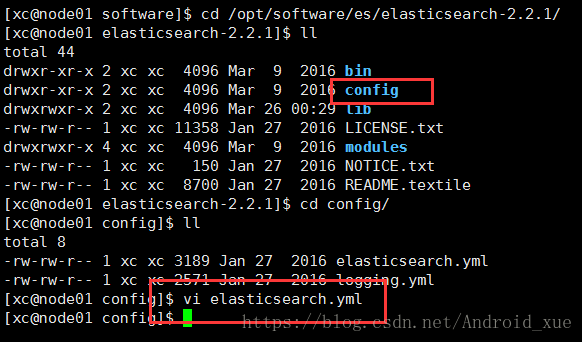
做如下修改:



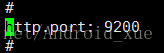
末尾增加防脑裂:
discovery.zen.ping.multicast.enabled: false
discovery.zen.ping.unicast.hosts: ["192.168.47.11","192.168.47.12", "192.168.47.13"]
discovery.zen.ping_timeout: 120s
client.transport.ping_timeout: 60s

3. 增加图形可视化插件(head):
先下载可视化插件(https://github.com/mobz/elasticsearch-head),然后把plugins目录上传到elasticsearch目录下:
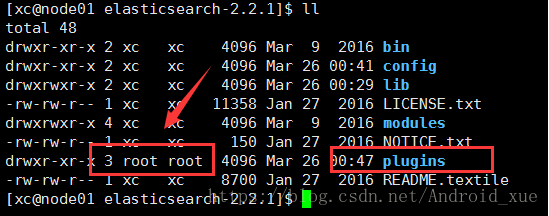
但是发现权限属于root,所以需要更改为xc用户
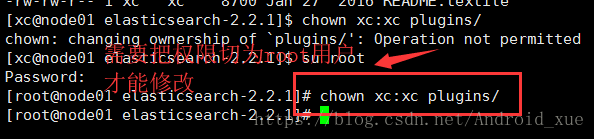
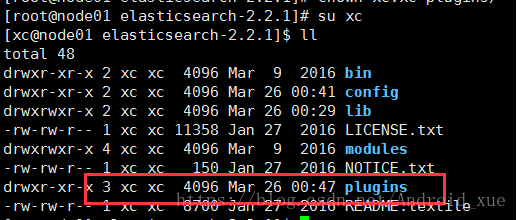
4. 分发文件到集群中的其他节点,也就是node02、node03


然后我们可以看到node02和node03中,已经有了该文件,并且权限属于xc用户

5. 修改node02、node03节点的配置文件(类似node01节点)
6. 进入bin目录,启动脚本:
启动集群前同步所有集群的时间是个好习惯



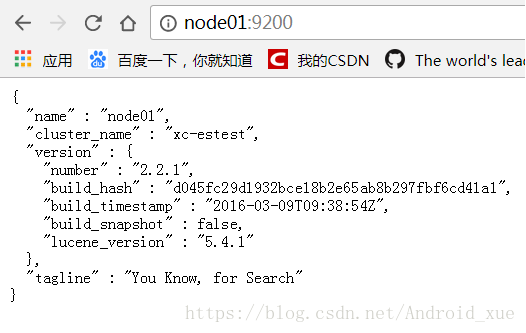
7. web浏览器访问node01:9200
再分别访问node01:9200/_plugin/head/
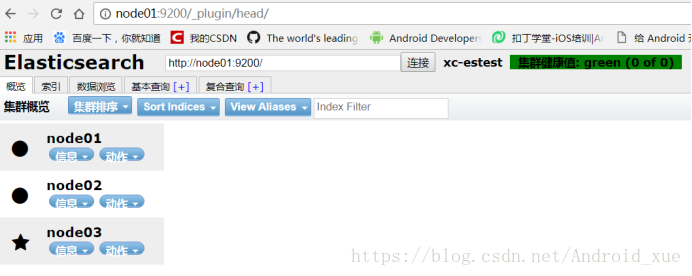
其他两个节点可做类似的访问。
接下来就可以使用linux 的CURL命令来操作elasticsearch了:
#创建索引库:
curl -XPUT http://192.168.47.11:9200/estest/

在看浏览器,发现每个节点都变为如下所示:
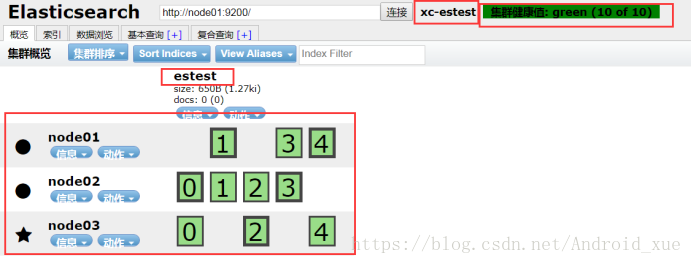
可以看到上面的10个块中,有五个边框比较宽(0-4),这个五个是主,剩下的五个是备。主备的比例是一比一,而且主和备不在一个节点,这样是为了避免一个节点出现故障数据全部丢失。总共有三个节点但Lucene却分了五个切片,主要是为了之后做迁移做准备。
接下来把node01关闭,看一下发生什么:
首先node01:9200:

然后看node02和node03
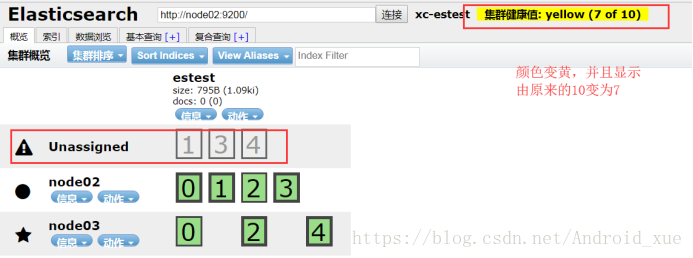
可以看到此时1、3、4没有备,Lucene会重新分配。

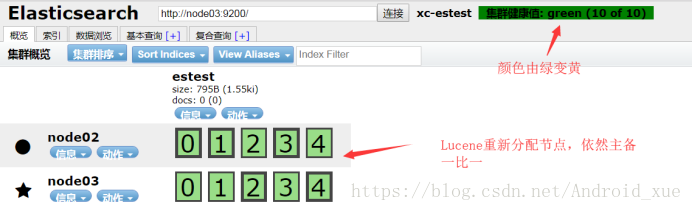
当然如果重新启动node01,依然会恢复到之前的状态。


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











