




 本文详细介绍了如何搭建Hadoop HA高可用集群,包括免密钥SSH配置、环境变量统一配置、Zookeeper安装启动及JournalNode启动等关键步骤。
本文详细介绍了如何搭建Hadoop HA高可用集群,包括免密钥SSH配置、环境变量统一配置、Zookeeper安装启动及JournalNode启动等关键步骤。
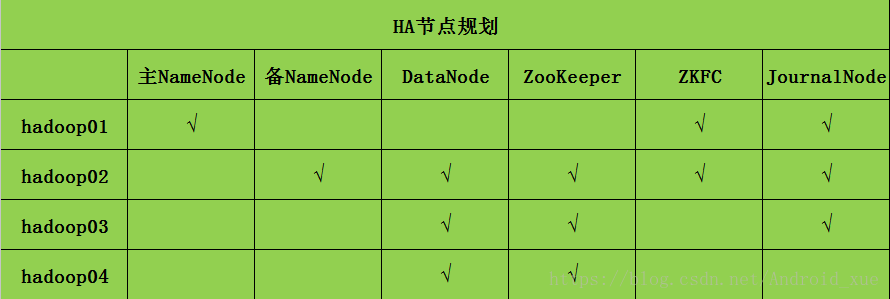
节点规划表:
新项目开始前先把原来的进行备份
搭建步骤:
1. (Hadoop01和Hadoop02相互免秘钥)
Setup passphraseless ssh
Now check that you can ssh to the localhost without a passphrase:
$ ssh localhost
If you cannot ssh to localhost without a passphrase, execute the following commands:
$ ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa $ cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
要想对别人免秘钥,上面三步是前提,必须要做



做完后就可以把公钥给hadoop01分发

在hadoop01中追加

验证免秘钥是否成功
2.这个时候统一配置hadoop02 hadoop03 hadoop04的环境变量:
(1)配置hdfs-site.xml
<!--指定hdfs的nameservice为mycluster,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- mycluster下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- nn1的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop01:8020</value>
</property>
<!-- nn2的RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop02:8020</value>
</property>
<!-- nn1的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop01:50070</value>
</property>
<!-- nn2的http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop02:50070</value>
</property>
<!-- 指定NameNode的edits元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop01:8485;hadoop02:8485;hadoop03:8485/mycluster</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/var/hadoop/ha/jn</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_dsa</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
(2)配置core-site.xml
<configuration>
<!-- 指定hdfs的nameservice为mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/var/hadoop/zk</value>
</property>
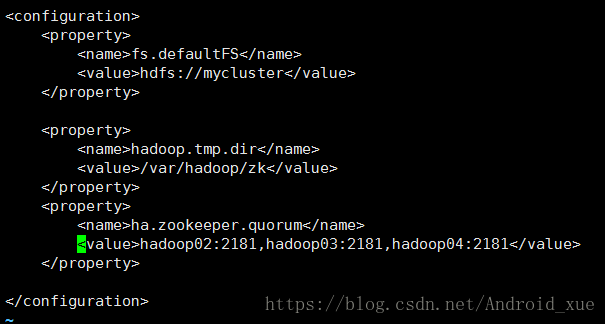
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop02:2181,hadoop03:2181,hadoop04:2181</value>
</property>
</configuration>
(3)修改完这两个文件然后分发给hadoop02-04
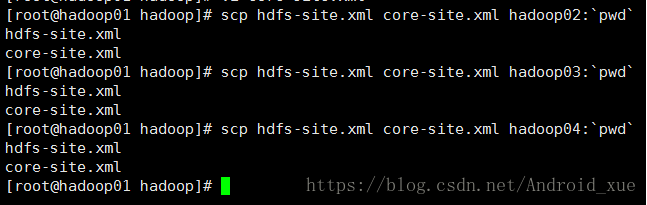
3.hadoop02-04安装并启动zookeeper

(1)将解压后的文件移动

(2)配置环境变量:

(3)配置好后,需要修改zoo_sample.cfg文件,先备份。
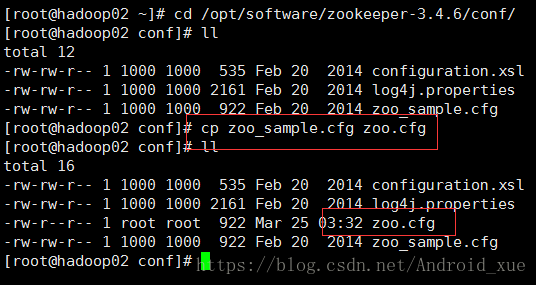
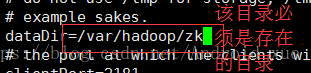
(4)配置zoo.cfg文件:
默认的保存目录不安全所以修改:
配置三台zookeeper节点
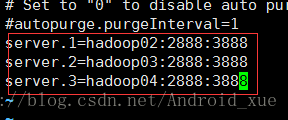
(5)给zookeeper的myid设置不同的数值

(6)把部署好的zookeeper进行对hadoop03-04两个zookeeper节点分发


(7)对hadoop03-04设置myid


(8)hadoop03-hadoop04环境变量配置
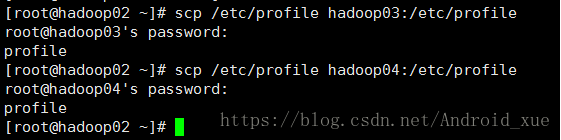
重新加载

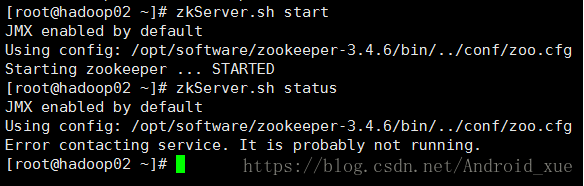
(9)启动hadoop02zookeeper
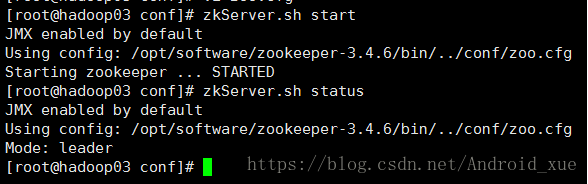
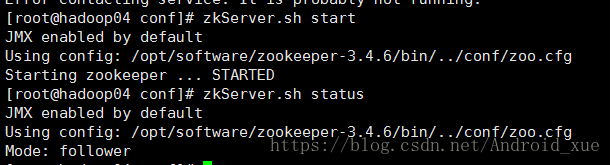
(10)再启动hadoop03和hadoop04,发现hadoop03是leader而hadoop02-04是follower
4.启动JN(hadoop01-03)

使用jps命令查看
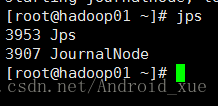
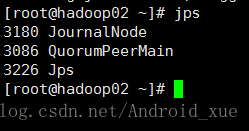
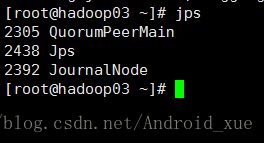
可以看到JournalNode进程已启动
5.第一台NN:
hdfs namenode –format
hadoop-daemon.sh start namenode
另一台NN:
hdfs namenode -bootstrapStandby
hadoop01:


hadoop02:

6.格式化ZK
hdfs zkfc -formatZK

7.启动集群
hadoop01:
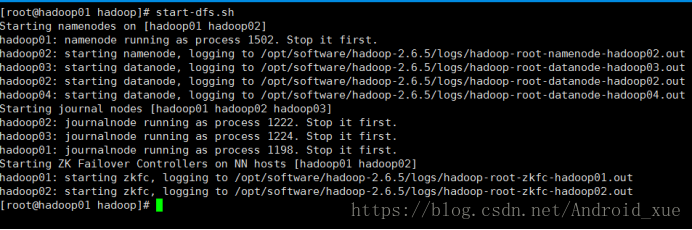
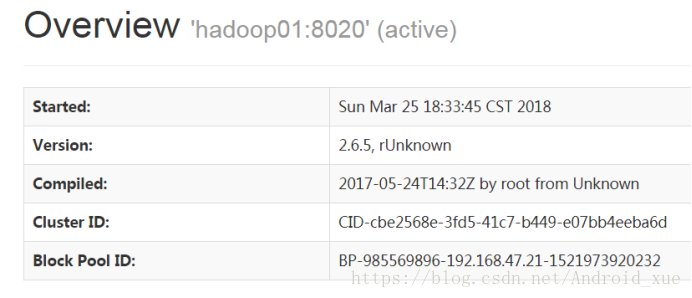
8.浏览器验证 hadoop01:50070


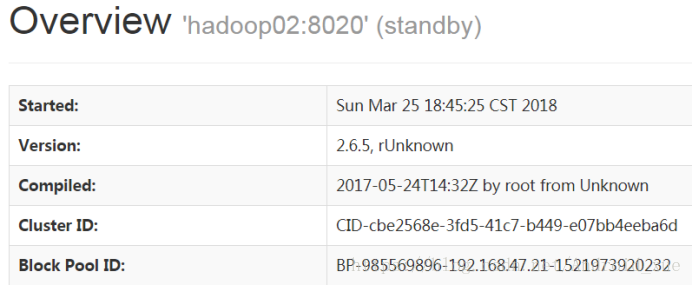
hadoop02:50070

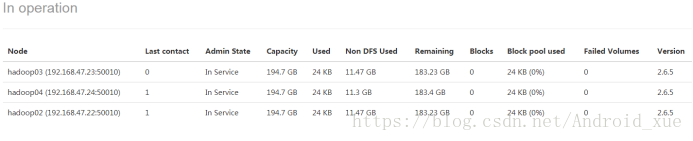
在hadoop01节点创建目录/user/root目录


上传文件,并自定义block块为1MB


9.验证高可用
(1)杀死主NameNode
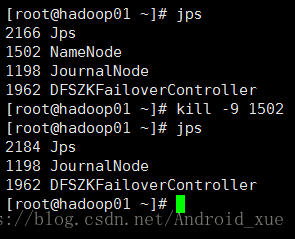
一刷新hadoop01:50070:
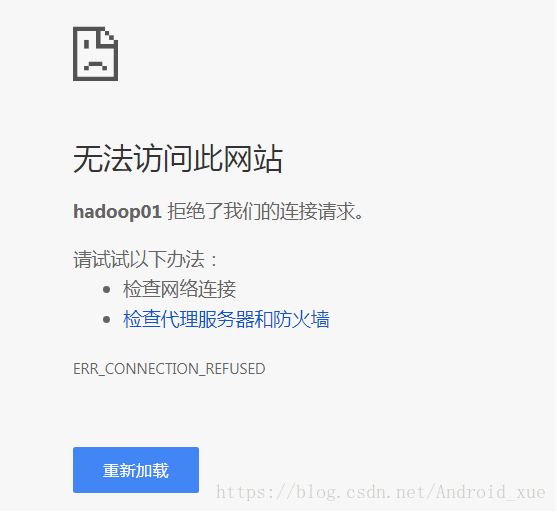
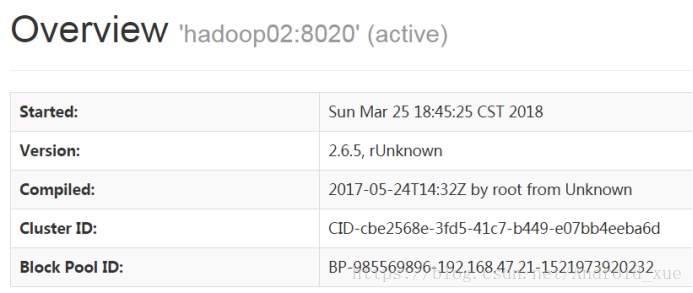
再刷新hadoop02:50070:


















 4243
4243

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











