



一、What:RAG到底是什么?大白话解释
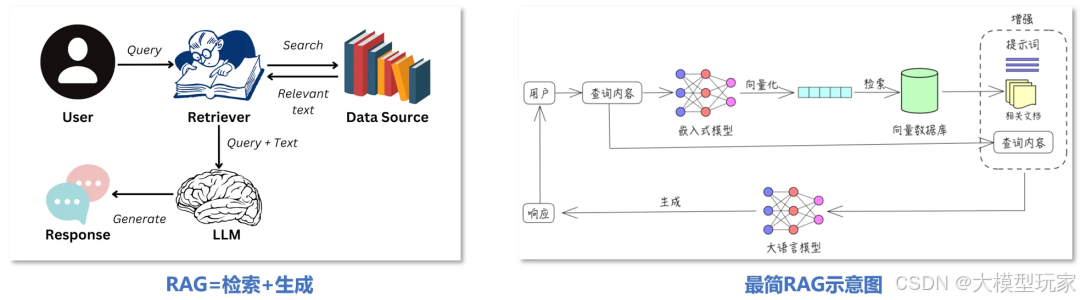
想象一下,你正在参加一场重要考试。传统的学习方法是死记硬背教科书的内容,传统方式是死记硬背教材,答题全靠记忆;但如果允许你带资料进考场,遇到不确定的问题,就可以翻阅相关内容,给出更准确的回答。
RAG技术正是这样工作的:
-
传统 AI:仅依赖训练时“记住”的知识,如同闭卷考试;
-
RAG增强的AI:先搜索相关资料,再基于搜索结果回答问题(就像开卷考试)
RAG
(Retrieval-Augmented Generation,检索增强生成)本质上是一种让大模型“边查资料边回答”的技术。它的核心理念很简单:不靠死记硬背,而是现查现答。
正如 IBM 和 Google 所指出的,RAG 通过连接外部知识库,使 AI 的回答更准确、及时、可溯源——而这恰恰是通用大模型最欠缺的三大能力。
既然 RAG 能补足大模型的短板,那它到底解决了哪些实际问题?为什么越来越多的团队开始拥抱这项技术?
二、Why:为什么需要RAG?
尽管大模型在许多任务上表现卓越,但仍存在明显短板,而 RAG 正好能有效弥补这些不足。
- 知识时效性有限:模型训练完成后,知识就“冻结”了。例如,ChatGPT 无法回答 2023 年 10 月之后发生的“东方甄选小作文”事件。RAG 通过接入实时知识库,轻松突破这一限制。

-
无法访问私有数据:企业内部文档、个人笔记等私域信息无法被通用模型学习。本地部署 RAG 系统,就能安全地利用这些专属知识。
-
可解析性:RAG检索结果提供事实依据,减少猜测性回答。同时生成答案可标注来源文档,增强可信度。
-
缺乏可解释性:传统大模型常“一本正经地胡说八道”。RAG 的答案基于真实文档,还能标注来源,显著提升可信度。
-
成本更优:相比为私有知识微调模型所需的大量标注数据和算力,RAG 以极低代价实现了知识的动态注入。

综合来看,RAG 不仅缓解了大模型的幻觉问题,还支持按需定制专业回答,在效果与成本之间找到了理想平衡点。
看到这里,你可能会想:RAG 听起来很强大,但它是大公司的专利吗?普通人能用得上吗?

三、Who:个人和团队也能玩转RAG!
虽然企业级 RAG 系统开发复杂,但对个人或小团队而言,搭建一个轻量级 RAG 知识库完全可行——尤其当你资源有限、目标明确时。
- 需求明确,规模可控:你可能只需从几份笔记、文档或网页中提取信息,根本不需要处理复杂的多源数据集成问题。
- 工具成熟,上手门槛低: LangChain、LlamaIndex、FAISS 等开源框架已高度封装,即使没有深厚技术背景,也能快速入门。
- 成本低,灵活性强:利用现有电脑或免费云资源即可开发测试,功能也可随需求逐步扩展
- 边做边学,加深理解:亲手搭建过程能让你深入掌握 RAG 的数据流、检索逻辑与优化技巧。
当然,也要注意几点:
- 数据质量:确保数据的准确性和完整性,避免“垃圾进,垃圾出”。
- 模型选择:选择合适的预训练模型,避免不必要的复杂度。
- 持续优化:定期评估系统的性能,优化和调整系统。
- 隐私与安全:处理敏感数据时,要注意加密和访问控制,避免信息泄露。
四、When:什么时候用RAG?什么时候用微调?
选择 RAG 还是微调,关键看三点:
1、看数据
- 数据更新频繁(如新闻、商品信息)→ 选 RAG
- 任务高度专业化且有标注数据(如法律文书分类)→ 选微调
2、看预算与资源
- 预算有限,用RAG更划算,搭建RAG系统的成本可能只有微调的1/5。
- 预算充足,可以尝试混合方案。先用RAG处理日常问题,再用微调优化复杂任务,成本降低,效率提升。
3、看应用场景
- 需要实时响应(如电商客服)→ RAG 更合适,有案例显示响应时间从 30 秒缩短至 1 秒;
- 需要深度专业输出(如学术综述)→ 微调更可靠,某高校医学院微调模型生成的内容被评价为“接近研究生水平”。
- 最佳实践是互补而非二选一:用 RAG 保证事实准确性,用微调提升表达质量。未来趋势正是“RAG + 微调”的组合拳
五、Where:RAG真实行业案例
RAG 尤其适用于对准确性高、内容更新快的场景。以下是几个典型应用:
- 智能客服:客户咨询退换货政策时,系统实时检索最新文档,确保回答精准无误。
- 企业知识管理:摩根士丹利为 16,000 多名顾问部署 GPT-4 助手,支持搜索 10 万份内部文档,大幅提升新人培训效率。
- 金融合规:摩根大通利用 RAG 自动分析 KYC 文件,处理效率提升 90%,用更少人力完成更多任务,同时降低合规风险。
- 医疗辅助:某大型医院构建医学知识库,医生输入症状后,系统自动匹配最新指南与文献,辅助诊断并减少误判。
- 教育培训:在线平台通过 RAG 为学生提供精准答疑,根据学习水平动态调整解释深度,显著提升参与度与满意度。
这些成功案例背后,RAG 系统究竟是如何一步步搭建起来的?如果你也想动手试试,接下来我们就拆解它的完整构建流程。
六、How:如何构建RAG系统?
RAG 的工作流程可分为两个阶段、五个关键步骤:
准备阶段(提问前)
1️⃣ 文档分片(Document Chunking)
目的:将长文档切分成易于处理的小片段
就像整理一本厚厚的百科全书,我们需要把它按章节、段落或页面分成小部分:
- 按字数分:比如每1000字一个片段
- 按段落分:一个段落一个片段
- 按章节分:一个章节一个片段
- 按主题分:相关内容归为一个片段
2️⃣ 向量索引(Vector Indexing)
目的:将文本转换为计算机能理解的”数字指纹”
这个过程包含三个核心概念:
向量(Vector)
- 简单理解:每个文本片段的”数字指纹”
- 技术表示:一串数字,如[1.0, 2.3, 5.76, -3.6]
- 重要特性:含义相近的文本,其向量在数学空间中距离很近
嵌入(Embedding)
- 定义:把文本转换为向量的过程
- 举例: - “马克喜欢吃水果” → [1, 2] - “马克爱吃水果” → [1, 1](距离很近) - “天气真好” → [-3, -1](距离较远)
向量数据库(Vector Database)
- 作用:专门存储这些”数字指纹”的仓库
- 内容:文本内容 + 对应的向量
- 优势:可以快速找到相似的内容
回答阶段(提问后)
3️⃣ 语义检索(Semantic Retrieval)
目的:从海量信息中找到最相关的内容
当用户提出问题时:
- 问题转向量:将用户问题转换为向量
- 相似度计算:计算问题向量与所有文档向量的相似度
- 初步筛选:选出最相关的Top-10个片段
相似度计算方法:
- 余弦相似度:计算向量夹角,夹角越小越相似
- 欧氏距离:计算直线距离,距离越小越相似
- 点积:代数计算方法,结果越大越相似
4️⃣ 结果重排(Re-ranking)
目的:从初选结果中精挑细选最佳答案
这就像招聘过程:
- 检索阶段:简历筛选(快速、低成本、准确率一般)
- 重排阶段:面试评估(慢速、高成本、准确率高)
通过Cross-encoder模型对Top-10结果进行精确评估,选出最相关的3-5个片段。
5️⃣ 答案生成(Answer Generation)
目的:基于精选的参考材料生成最终答案
将用户问题 + 精选的文档片段一起发送给大语言模型(如GPT-4o),生成准确、有依据的最终答案。
逐步构建RAG系统
(一)设置环境
构建RAG系统需要使用多个Python库,包括langchain、langchain-core、langchain-community、langchain-experimental、pymupdf、langchain-text-splitters、faiss-cpu、langchain-ollama、langchain-openai等。这些库各自承担着不同的功能:
-
LangChain提供了构建大语言模型应用的整体框架和组件,简化了开发流程。
-
PyMuPDF能够从PDF文档中提取文本,支持多种PDF特性的处理。
-
FAISS为向量数据库提供高效的相似性搜索能力。
-
Ollama和OpenAI集成允许使用不同的语言模型,为用户提供了更多选择。
可以使用pip命令安装这些库:
pip install langchain langchain-core langchain-community langchain-experimental pymupdf langchain-text-splitters faiss-cpu langchain-ollama langchai
(二)组件1:PDF加载器
from langchain_community.document_loaders import PyMuPDFLoader
class PdfLoader:
def __init__(self):
pass
def read_file(self, file_path):
loader = PyMuPDFLoader(file_path)
docs = loader.load()
return docs
上述代码定义了一个PdfLoader类,其read_file方法使用PyMuPDFLoader从指定的PDF文件路径中加载文档。PyMuPDFLoader基于PyMuPDF库(也称为fitz),能够高效地处理各种PDF特性,包括文本、表格,甚至通过OCR处理一些图像。load()方法返回一个Document对象列表,每个对象代表PDF文件中的一页,包含提取的文本内容(page_content)和元数据(metadata),如源文件路径和页码。在实际应用中,可扩展该类以处理其他文档类型。
(三)组件2:文本分块
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.documents import Document
class Chunker:
def __init__(self, chunk_size=1000, chunk_overlap=100):
self.text_splitter = RecursiveCharacterTextSplitter(
separators=["\n\n", "\n", " ", ".", ",", "\u200b", "\uff0c", "\u3001", "\uff0e", "\u3002", ""],
chunk_size=chunk_size,
chunk_overlap=chunk_overlap,
length_function=len,
is_separator_regex=False
)
def chunk_docs(self, docs):
list_of_docs = []
for doc in docs:
tmp = self.text_splitter.split_text(doc.page_content)
for chunk in tmp:
list_of_docs.append(
Document(
page_content=chunk,
metadata=doc.metadata
)
)
return list_of_docs
Chunker类负责将加载的文档分割成较小的文本块。在初始化时,通过设置chunk_size(默认1000个字符)和chunk_overlap(默认100个字符)来控制分块的大小和重叠程度。RecursiveCharacterTextSplitter使用一系列分隔符(包括段落分隔符、换行符、空格、标点符号等)来分割文本,优先在自然边界处分割。chunk_docs方法对输入的文档列表进行处理,为每个文本块创建新的Document对象,并保留原始文档的元数据。
(四)组件3:向量存储
import faiss
from langchain_community.docstore.in_memory import InMemoryDocstore
from langchain_community.vectorstores import FAISS
from langchain_ollama import OllamaEmbeddings
from uuid import uuid4
class VectorStore:
def __init__(self):
self.embeddings = OllamaEmbeddings(model="llama3.2:3b")
self.index = faiss.IndexFlatL2(len(self.embeddings.embed_query("hello world")))
self.vector_store = FAISS(
embedding_function=self.embeddings,
index=self.index,
docstore=InMemoryDocstore(),
index_to_docstore_id={}
)
def add_docs(self, list_of_docs):
uuids = [str(uuid4()) for _ in range(len(list_of_docs))]
self.vector_store.add_documents(documents=list_of_docs, ids=uuids)
def search_docs(self, query, k=5):
results = self.vector_store.similarity_search(
query,
k=k
)
return results
VectorStore类是检索系统的核心。在初始化时,创建一个OllamaEmbeddings嵌入模型(这里使用llama3.2:3b模型),并基于FAISS创建一个用于L2距离计算的索引,同时初始化一个包含嵌入函数、索引和文档存储的向量存储。add_docs方法为每个文档生成唯一ID,并将文档添加到向量存储中,向量存储会计算文档内容的嵌入并进行索引。search_docs方法将输入的查询转换为嵌入,在向量存储中执行相似性搜索,并返回最相似的k个文档。在实际生产中,可考虑使用持久化向量存储、添加元数据过滤功能或实现混合搜索。
(五)组件4:RAG系统
from langchain_core.prompts import PromptTemplate
from langchain_openai import OpenAI
from langchain_ollama import OllamaLLM
from pdf_loader import PdfLoader
from vector_store import VectorStore
from chunk_text import Chunker
class RAG:
def __init__(self):
self.instructor_prompt = """Instruction: You're an expert problem solver you answer questions from context given below. You strictly adhere to the context and never move away from it. You're honest and if you do not find the answer to the question in the context you politely say "I Don't know!"
So help me answer the user question mentioned below with the help of the context provided
User Question: {user_query}
Answer Context: {answer_context}
"""
self.prompt = PromptTemplate.from_template(self.instructor_prompt)
self.llm = OllamaLLM(model="llama3.2:3b") # OpenAI()
self.vectorStore = VectorStore()
self.pdfloader = PdfLoader()
self.chunker = Chunker()
def run(self, filePath, query):
docs = self.pdfloader.read_file(filePath)
list_of_docs = self.chunker.chunk_docs(docs)
self.vectorStore.add_docs(list_of_docs)
results = self.vectorStore.search_docs(query)
answer_context = "\n\n"
for res in results:
answer_context = answer_context + "\n\n" + res.page_content
chain = self.prompt | self.llm
response = chain.invoke(
{
"user_query": query,
"answer_context": answer_context
}
)
return response
if __name__ == "__main__":
rag = RAG()
filePath = "investment.pdf"
query = "How to invest?"
response = rag.run(filePath, query)
print(response)
RAG类将前面构建的各个组件整合在一起,形成一个完整的RAG系统。在初始化时,定义一个指导语言模型的提示模板,创建PromptTemplate对象,并初始化语言模型、向量存储、PDF加载器和文本分块器。run方法实现了完整的RAG工作流程:加载PDF文档,分块处理,添加到向量存储,根据用户查询搜索相关文本块,组合检索到的文本块形成上下文,将提示模板与语言模型结合生成回答。在主程序中,创建RAG实例,指定PDF文件路径和查询,运行系统并打印结果。
七、总结
RAG技术作为AI领域的重要突破,为解决传统大语言模型的核心局限性提供了优雅的解决方案。通过“检索-增强-生成”的工作模式,RAG让AI系统能够:
✅ 获取最新信息:突破训练数据的时间限制
✅ 提供准确答案:基于真实数据减少幻觉
✅ 降低使用成本:优化计算资源利用效率
✅ 增强可信度:提供可追溯的信息来源
从学术研究到产业应用,从金融服务到医疗教育,RAG技术正在各个领域展现出巨大的价值。随着技术的不断完善和生态的日趋成熟,我们有理由相信,RAG将成为构建下一代智能系统的核心技术之一。
对于普通用户而言,RAG技术意味着我们将拥有更智能、更可靠、更有用的AI助手。对于企业而言,RAG技术为数字化转型和智能化升级提供了强有力的技术支撑。
记住:RAG 不是终点,而是 AI 走向‘可信、可用、可控’的关键一步。而你,已经站在了这场变革的起点。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









