




理解检索与结构化(RAS)范式,以实现精确推理和领域专业知识,并附带实施示例
大型语言模型(LLM)在文本生成和复杂推理方面展现出卓越的能力。但我们都知道它们并非完美无缺。
当 LLM 部署到现实世界中时,这些应用程序会遇到一些挑战。有时它们会产生幻觉。有时,它们会给出过时的响应。
检索增强生成(RAG) 应运而生,旨在解决这些缺陷。RAG 首先通过从外部文档中检索相关信息来增强 LLM,从而使模型的响应有据可依。这大大减少了幻觉。
这是一个好的解决方案,对吗?不完全是。
传统的 RAG 方法遇到了瓶颈,因为它们通常将外部信息作为原始的、非结构化的文本段落进行处理。这些混乱的文本通常包含令人困惑或非原子信息,可能会误导 LLM。当尝试回答需要多步推理的复杂查询时,系统也会遇到困难。
为了克服这些限制,检索与结构化(RAS)范式应运而生。RAS 通过增加一个额外的知识结构化步骤来扩展 RAG。
在这篇博客中,我将引导您了解 RAS 框架、以及框架中的不同阶段和步骤,并附带实施示例。
为什么我们需要为 RAG 结构化数据?
结构化通过将检索到的非结构化文本转换为有组织的、可操作的知识,解决了传统 RAG 中的一些关键限制。
让我们了解为什么在 RAG 中结构化数据很重要。
1. 克服传统 RAG 的局限性
传统的 RAG 将 LLM 连接到外部信息,以缓解幻觉和过时知识等问题。然而,即使是 RAG 也面临局限性,因为它将文档作为非结构化文本段落进行处理。
非结构化文本通常包含不相关的细节,这可能会使模型偏离方向并导致误导性答案。
常规 RAG 在处理复杂问题时会遇到困难,尤其是当这些问题需要多步推理或有组织的、领域特定的知识时。
2. 增强 LLM 生成和推理能力
将外部知识结构化为知识图谱等表示形式是提高 LLM 输出和推理能力的关键。
当答案从结构化知识构建时,模型产生幻觉的可能性较小。例如,KG-RAG 使用知识图谱来指导模型,因此响应更准确、更可靠。
结构化数据让模型能够看到事实之间的联系。这有助于它解决需要更深入推理的更复杂问题。
RAS 与闭源模型和开源模型的性能比较显示了 RAS 可以为 AI 应用程序带来的改进。
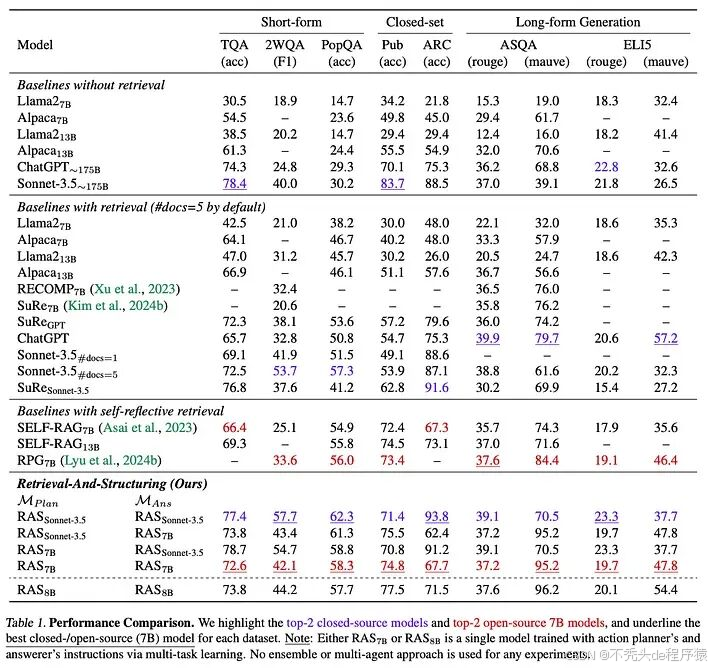
RAS 的性能——与闭源模型和开源模型——来源

什么是 RAS?
检索与结构化(RAS)范式通过结合知识结构化技术(例如分类法和知识图谱)来扩展传统 RAG,这些技术将非结构化文本转换为有组织的知识,以增强推理和验证。
RAS 范式将三个关键组件统一到一个框架中:信息检索、结构化知识表示(如知识图谱)和大型语言模型。
让我给出一个简单易懂的 RAS 版本。
传统 LLM 仅依赖于它们从大量训练中记住的内容(这可能已过时或不完整)。它们可能会猜测或“幻觉”答案。
RAG(检索增强生成) 旨在解决幻觉和过时/专有数据问题。RAG 框架使 LLM 能够查找相关书籍(检索非结构化文本段落)。问题是,它们可能会得到一大堆混乱的文本,这些文本令人困惑或包含非原子、误导性信息。
RAS(检索与结构化) 已发展成为一种强大的策略,可以消除混乱的数据问题。
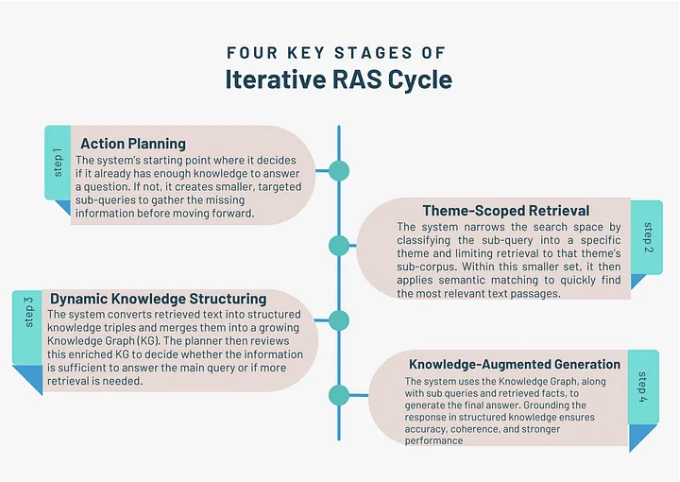
步骤 1:检索 — LLM 搜索所有相关文档。
步骤 2:结构化 — 当 LLM 访问的是有组织的(知识图谱或分类法),而不是提取原始文本时,这就消除了混乱,并隔离了事实和关系。
步骤 3:生成 — 最后,LLM 使用这个有组织的知识图谱来构建一个事实性、准确且易于验证的答案。
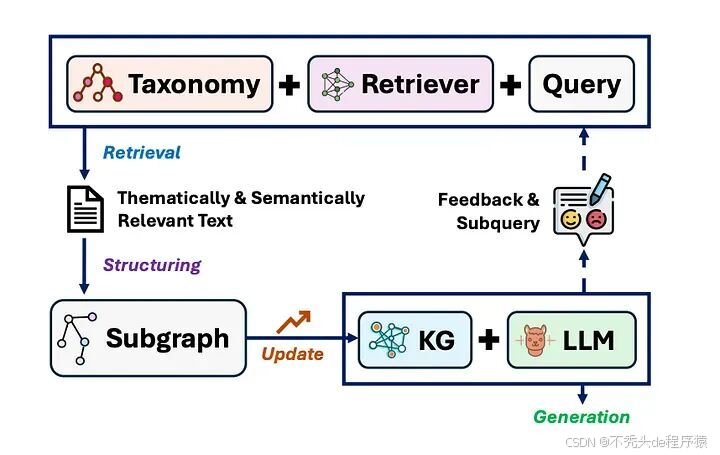
RAS 范式的抽象示例 来源
本质上,RAS 教导 LLM 不仅要查找信息,还要如何正确组织和推理信息。
RAS 范式的基本原则
RAS 框架增强了 LLM 执行知识密集型任务的能力,并实现了更有效的知识发现。RAS 的核心是有效利用结构化数据来改进检索过程和 LLM 的输出质量:
1. 结构增强检索(更智能地查找知识)
结构化技术有助于检索系统准确找到 LLM 所需的内容,特别是对于复杂或领域特定的问题。有 3 种基本方法可以增强检索。
基于分类法的方法: RAS 不仅仅进行一般搜索,而是使用特定于领域的专题分类法。这意味着搜索由对主题有意义的结构引导,因此不需要大量的标记训练数据。
基于知识图谱(KG)的方法: 在这里,知识图谱有助于提高检索质量。例如,KG-RAG 等方法允许 LLM 通过其推理能力逐步遍历图谱。这种方法通常能找到更准确的信息,因为它着眼于关系和连接,而不仅仅是关键词。
迭代循环: 这种方法使用迭代循环,其中分类法增强的检索器找到相关文档,然后立即将其结构化为子图以更新特定于查询的 KG。LLM 使用这个结构化 KG 来回答查询,如果需要,它会生成一个集中的子查询来启动一个新的、精炼的检索循环。
2. 结构增强 LLM 生成(更智能地使用知识)
一旦检索到的知识被结构化,挑战就转移到如何利用这种结构来增强 LLM 的响应。结构增强的 LLM 生成将模型响应基于明确的知识结构,这显著减少了幻觉并提高了事实一致性。
ToG(图上思考)使 LLM 能够通过引导式、提示驱动的探索直接与 KG 进行推理,逐步构建明确的推理链。
GoT(思维图)将 LLM 的推理过程结构化为图而不是简单的线性链,从而允许复杂的思维模式,如多路径探索和循环思维。
其他使用的技术包括 GraphRAG,它将复杂的结构化知识浓缩为文本摘要,使 LLM 能够处理需要对语料库进行全局理解的复杂查询。
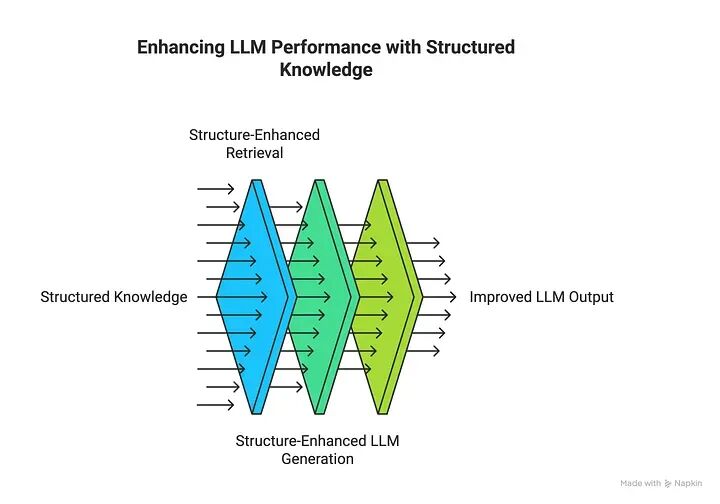
RAS 范式的基本原则
为 RAG 创建和添加结构的技术,并附带实施示例:
1. 为数据添加简单结构:
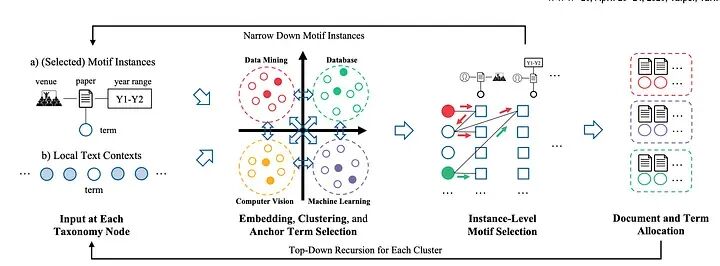
为数据添加结构涉及多个步骤。但它始于分类法构建,然后是分类法的增强、实体提取和知识图谱创建。
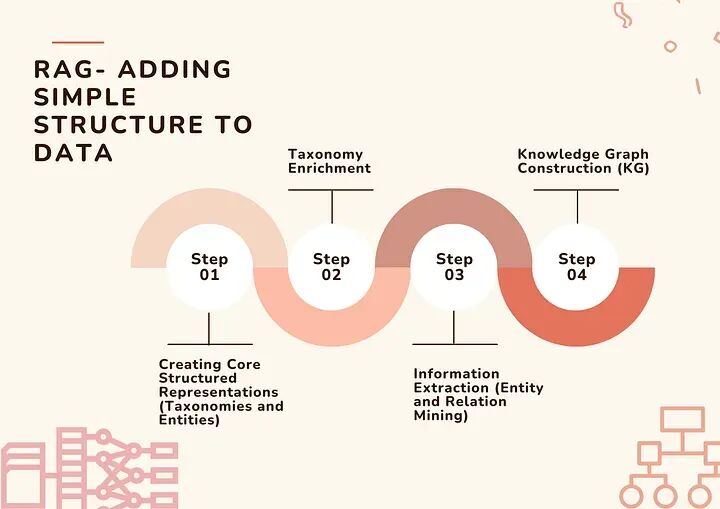
为数据添加简单结构的步骤——图片由作者 (Vivedha Elango) 制作
步骤 1:创建核心结构化表示(分类法和实体)
此阶段为领域知识建立组织结构。因此,我们可以采取的第一步是构建分类法。
什么是分类法?
分类法是一种树状结构。它将概念从顶部的广义类别(父节点)组织到下面的更具体类别(子节点)。在文本挖掘中,分类法有助于结构化标签和组织信息。
分类法构建从一个基本结构(称为“种子”)开始。不同的方法以广度和深度扩展这个种子,然后调整整体结构。
HiExpan 通过扩展实体来发展分类法,然后使用词语类比进行细化。它旨在从领域聚焦的文本语料库中创建特定任务的分类法。用户可以提供一个种子分类法来指导过程,确保结果与其需求相关。
首先,它自动从语料库中生成一个关键术语列表。然后,从种子分类法开始,它逐步发展分类法。对于每个节点,HiExpan 将其子节点视为一个集合并递归地扩展它们,确保每组子节点保持连贯和相关。HiExpan 还包括一个弱监督关系提取模块。
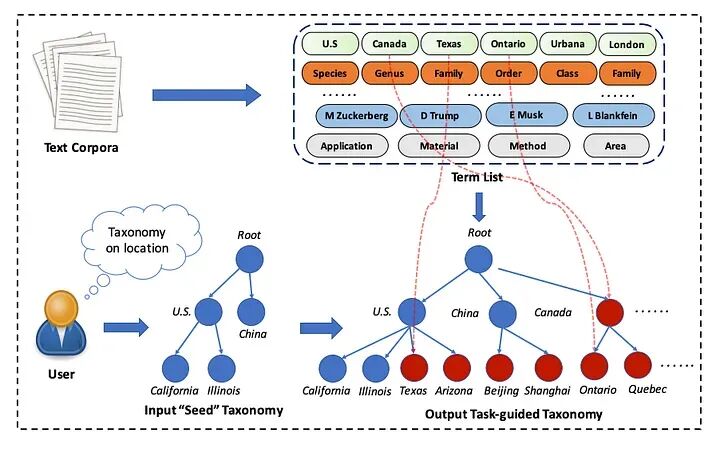
任务引导的分类法构建。用户提供一个“种子”分类法树作为任务指导,我们将从原始文本语料库中提取关键术语并自动生成所需的分类法。
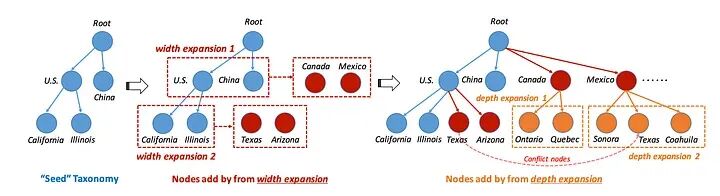
我们的层次树扩展算法概述——来源
CoRel**:** CoRel 使用预训练语言模型来学习父子关系如何泛化。ColRel 提供了一种构建分类法的新方法,可以更好地匹配用户兴趣。ColRel 不仅仅使用广泛的词对,而是从用户提供的种子分类法和文本语料库开始。然后,它构建一个具有更丰富覆盖范围的定制分类法。在这里,每个节点不仅仅是一个词,而是一组相关术语的集群,使分类法对用户需求更具意义和相关性。
ColRel 使用两个主要模块:
- • 关系转移: 此模块学习用户关心的关系。它在分类法中的不同路径之间转移这些关系,扩展其广度和深度。这意味着您将获得一个更详细、更广泛的结构,根据您的兴趣量身定制。
- • 概念学习: 此模块通过嵌入分类法和文本语料库来增强每个节点的含义,因此每个概念都由一组连贯、相关的术语表示。
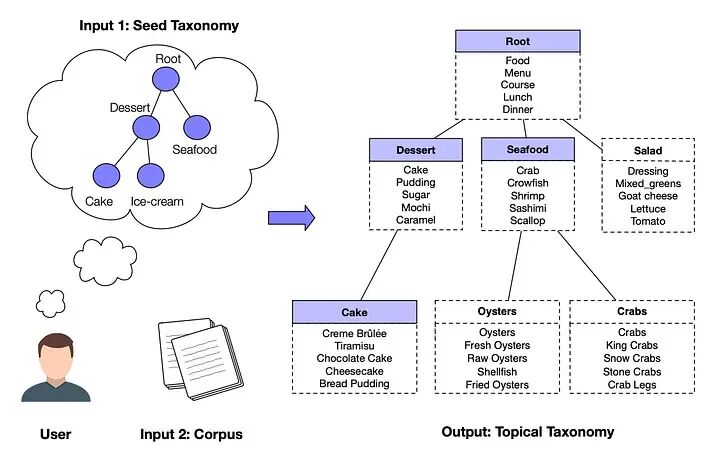
种子引导的主题分类法构建——来源
步骤 2:分类法增强
此步骤通过将构建的分类法节点与描述性文本(例如关键词)关联起来,从而增强它们。
在此步骤中,我们使结构中的每个节点更具信息性和区分性。这里使用的技术试图在增强过程中对树状结构进行建模。
TaxoGen: TaxoGen 递归地聚类词嵌入,并使用本地语料库细化聚类。
TaxoGen 将相关术语组合成一个主题,使分类法更具信息性。它首先将术语转换为嵌入以捕获其含义,然后使用一种特殊类型的聚类逐步将广义主题分解为更具体的主题,同时确保通用术语保持在较高层次,而特定术语深入。为了在较小主题中对术语进行更精细的区分,TaxoGen 仅使用与该主题相关的文档学习新的嵌入,从而能够分离细微的差异。该方法是完全自动化的,并创建比以前方法更清晰、更有用的分类法,帮助用户和系统更好地导航和理解大型文本数据集。
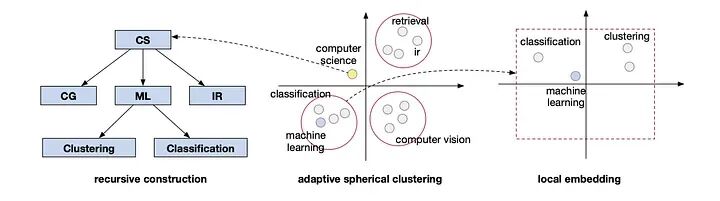
TaxoGen 概述 来源
NetTaxo: NetTaxo 通过结合网络结构信息扩展了 TaxoGen。主要思想是让文档之间的连接和文本的实际内容协同工作,以创建更丰富、更准确的主题层次结构。这使得发现主要主题及其子主题更容易、更精确,帮助人们快速查找信息并理解不同主题之间的联系。总的来说,NetTaxo 通过使用文本及其关系网络,超越了旧系统,从而产生了更具信息性和实用性的主题分类法。
 NetTaxo 概述 来源
NetTaxo 概述 来源
步骤 3:信息提取(实体和关系挖掘)
信息提取(IE)侧重于提取实体级信息,这些信息作为知识结构化的构建块。
在此步骤中,我们识别真实世界的实体以及它们之间的关系,这对于知识图谱的构建至关重要。
此步骤中使用的技术包括实体挖掘(用于提取实体的命名实体识别 - NER)和细粒度实体类型化(FET)(用于将实体分类到本体中)、关系提取。
步骤 4:知识图谱构建(KG)
在此步骤中,提取的信息被具体化为知识图谱(KG)。在这里,我们尝试将真实世界的实体表示为节点,将其关系表示为边。
一些创建知识图谱的关键技术和框架是:
管道方法: 历史上使用开放信息提取(OpenIE)工具来提取三元组,然后对其进行过滤和合并。
开放信息提取(OpenIE)标注器提取开放域关系三元组,表示一个主语、一个关系和该关系的对象。
除了提取关系三元组之外,标注器还生成与给定原始句子中隐含片段对应的多个句子片段。这些片段存储在 CoreMap(即句子)的 EntailedSentencesAnnotation 键上。
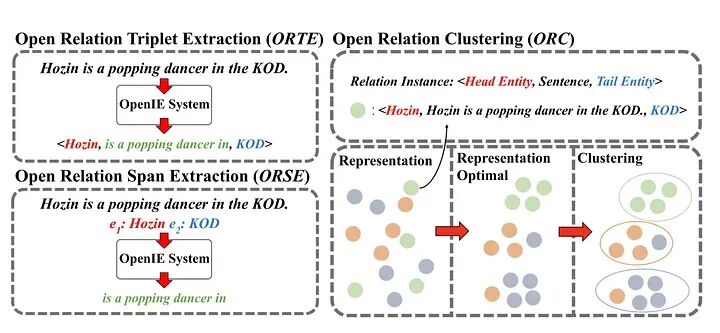
OpenIE 任务设置中的工作流过程概述 来源
**端到端模型:**REBEL 等框架和专门模型利用预训练语言模型将原始文本直接转换为结构化知识。
**基于 LLM 的构建:**KnowledgeGraph GPT 等现代方法直接提示 LLM(例如 GPT-4)将纯文本转换为 KG。
因此,总结简单 RAS 循环中的所有步骤以及可以使用的框架。下面的流程图将有助于更好地理解过程和步骤。

RAS 流程图——图片由作者 (Vivedha Elango) 制作
为RAG添加简单结构的实现
KG-gen包为这个问题提供了简单的实现方案。它是一个文本到知识图谱(KG)生成器,使用LLM模型直接从纯文本构建高质量图谱。KG-gen将相关实体组合在一起,这有助于减少稀疏性并使图谱更加有用。该包易于使用,可通过pip install kg-gen作为Python库安装。
from kg_gen import KGGen
# Initialize KGGen with optional configuration
kg = KGGen(
model="openai/gpt-4o", # Default model
temperature=0.0, # Default temperature
api_key="YOUR_API_KEY" # Optional if set in environment or using a local model
)
# EXAMPLE 1: Single string with context
text_input = "Linda is Josh's mother. Ben is Josh's brother. Andrew is Josh's father."
graph_1 = kg.generate(
input_data=text_input,
context="Family relationships"
)
# Output:
# entities={'Linda', 'Ben', 'Andrew', 'Josh'}
# edges={'is brother of', 'is father of', 'is mother of'}
# relations={('Ben', 'is brother of', 'Josh'),
# ('Andrew', 'is father of', 'Josh'),
# ('Linda', 'is mother of', 'Josh')}
对于长文本,你可以指定一个 chunk\_size 参数,将文本分成更小的块进行处理:
graph = kg.generate(
input_data=large_text,
chunk_size=5000 # Process in chunks of 5000 characters
)
你可以在生成阶段或者之后的阶段聚类相同的实体和关系:
# During generation
graph = kg.generate(
input_data=text,
cluster=True,
context="Optional context to guide clustering"
)
# Or after generation
clustered_graph = kg.cluster(
graph,
context="Optional context to guide clustering"
)
聚合多个图谱
你可以使用aggregate方法连接多个图谱在一起
graph1 = kg.generate(input_data=text1)
graph2 = kg.generate(input_data=text2)
combined_graph = kg.aggregate([graph1, graph2])
2. 为 RAG 添加高级结构:
高级结构化技术超越了简单的实体和关系提取,以捕获更复杂的知识表示,例如事件、时间信息和多模态数据。
为 RAG 添加高级结构——图片由作者 (Vivedha Elango) 制作
步骤 1:事件提取
事件提取(EE)旨在识别文本中描述的事件,例如“收购”、“发布”或“疾病爆发”,并提取其关键论元(例如,谁、什么、何时、何地)。
什么是事件?
事件是文本中描述的特定发生,通常涉及参与者、时间、地点和原因。
事件模式: 事件模式定义了特定类型事件的结构,包括事件触发词和论元角色。例如,对于“收购”事件,模式可能包括“收购方”、“被收购方”、“收购价格”和“日期”。
事件图谱: 事件图谱是知识图谱的扩展,专门用于表示事件及其论元。它们允许对事件进行更丰富的推理,例如识别事件序列或因果关系。
步骤 2:时间信息提取
时间信息提取(TIMEX)侧重于识别和标准化文本中提及的时间表达式,例如“昨天”、“下周”或“2023 年 10 月 26 日”。
时间表达式: TIMEX 表达式是文本中对时间点的引用,可以是绝对的(例如,“2023 年 10 月 26 日”)或相对的(例如,“昨天”)。
时间关系: 时间关系描述了事件和时间表达式之间的顺序或持续时间关系。例如,“事件 A 发生在事件 B 之前”或“事件 C 持续了三天”。
步骤 3:多模态信息提取
多模态信息提取(MIE)旨在从图像、视频和音频等多种模态中提取结构化信息,并将其与文本信息集成。
视觉实体和关系: MIE 可以从图像中识别对象、场景和它们之间的关系。例如,从一张图片中识别出“一个人在公园里骑自行车”。
音频事件: MIE 可以从音频中识别事件,例如“说话”、“音乐”或“警报声”。
多模态知识图谱: 多模态知识图谱将来自不同模态的结构化信息集成到一个统一的表示中,从而实现更全面的知识推理。
3. 使用结构化数据增强 RAG 的实施示例:
现在我们已经了解了为 RAG 添加结构的不同技术,让我们看看如何将它们集成到 RAG 管道中。
基于知识图谱的 RAG (KG-RAG):
KG-RAG 将知识图谱作为 RAG 管道的核心组件。它涉及以下步骤:
-
- 知识图谱构建: 从文本语料库中提取实体和关系,并构建知识图谱。
-
- 查询扩展: 使用知识图谱扩展用户查询,以捕获更丰富的语义信息。
-
- 检索: 使用扩展的查询从知识图谱中检索相关实体和关系。
-
- 生成: LLM 使用检索到的结构化信息生成响应。
实施示例:
假设我们有一个关于公司及其产品的知识图谱。当用户询问“告诉我关于 NVIDIA 的最新产品”时,KG-RAG 管道将:
-
- 查询扩展: 将“NVIDIA”扩展为知识图谱中的相应实体。
-
- 检索: 从知识图谱中检索与 NVIDIA 实体相关的“产品”关系和产品实体。
-
- 生成: LLM 使用检索到的产品信息生成响应,例如“NVIDIA 的最新产品包括 Blackwell AI 芯片和 GeForce RTX 40 系列显卡。”
基于事件图谱的 RAG (Event-RAG):
Event-RAG 专注于从文本中提取和利用事件信息。它涉及以下步骤:
-
- 事件提取: 从文本语料库中识别事件及其论元,并构建事件图谱。
-
- 查询匹配: 将用户查询与事件图谱中的事件模式进行匹配。
-
- 检索: 从事件图谱中检索与匹配事件相关的事件实例和论元。
-
- 生成: LLM 使用检索到的事件信息生成响应。
实施示例:
假设我们有一个关于新闻报道的事件图谱。当用户询问“谁收购了 Twitter?”时,Event-RAG 管道将:
-
- 查询匹配: 将查询与“收购”事件模式进行匹配。
-
- 检索: 从事件图谱中检索与“收购”事件相关的事件实例,其中“被收购方”是“Twitter”,并提取“收购方”论元。
-
- 生成: LLM 使用检索到的信息生成响应,例如“Elon Musk 收购了 Twitter。”
总结
检索-结构化(RAS)方法是将大语言模型从‘令人惊艳却并不可靠的工具’升级为‘可信、知识驱动型系统’的下一步。
传统 RAG 试图通过引入外部文档来解决既有问题,它有所帮助,但仍显不足。当面对杂乱、非结构化数据时——信息重复、残缺或难以解析——RAG 常常失效。
RAS 的核心思路很简洁:把非结构化数据转化为可验证的结构化知识。具体做法是利用文本结构化技术构建分类体系、建立层级、抽取实体。
然而,RAS 仍面临挑战:检索必须更快、更可扩展;知识图谱在规模扩张时需保持准确与一致;结构化数据需要持续维护、精炼与校验。
展望未来,RAS 研究正朝着更深度的集成与更强的适应性迈进:涵盖文本、图像、视频、音频等多模态数据,并构建跨语言结构,实现知识在不同语言间的共享。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 3050
3050

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









