



本文将通过代码实战带你快速掌握NLP三大核心任务,使用Hugging Face Transformer库实现工业级AI应用开发。
一、环境准备
pip install transformers datasets torch tensorboard
二、文本分类实战(情感分析)
1. 数据加载与预处理
from datasets import load_datasetfrom transformers import AutoTokenizerdataset = load_dataset("imdb")tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")def tokenize_function(examples): return tokenizer(examples["text"], padding="max_length", truncation=True)tokenized_datasets = dataset.map(tokenize_function, batched=True)
2. 模型训练
from transformers import AutoModelForSequenceClassification, TrainingArguments, Trainermodel = AutoModelForSequenceClassification.from_pretrained( "distilbert-base-uncased", num_labels=2)training_args = TrainingArguments( output_dir="./results", evaluation_strategy="epoch", learning_rate=2e-5, per_device_train_batch_size=16, num_train_epochs=3,)trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_datasets["train"], eval_dataset=tokenized_datasets["test"],)trainer.train()
3. 推理预测
from transformers import pipelineclassifier = pipeline("text-classification", model=model, tokenizer=tokenizer)result = classifier("This movie was absolutely fantastic!")print(result) # [{'label': 'POSITIVE', 'score': 0.999}]
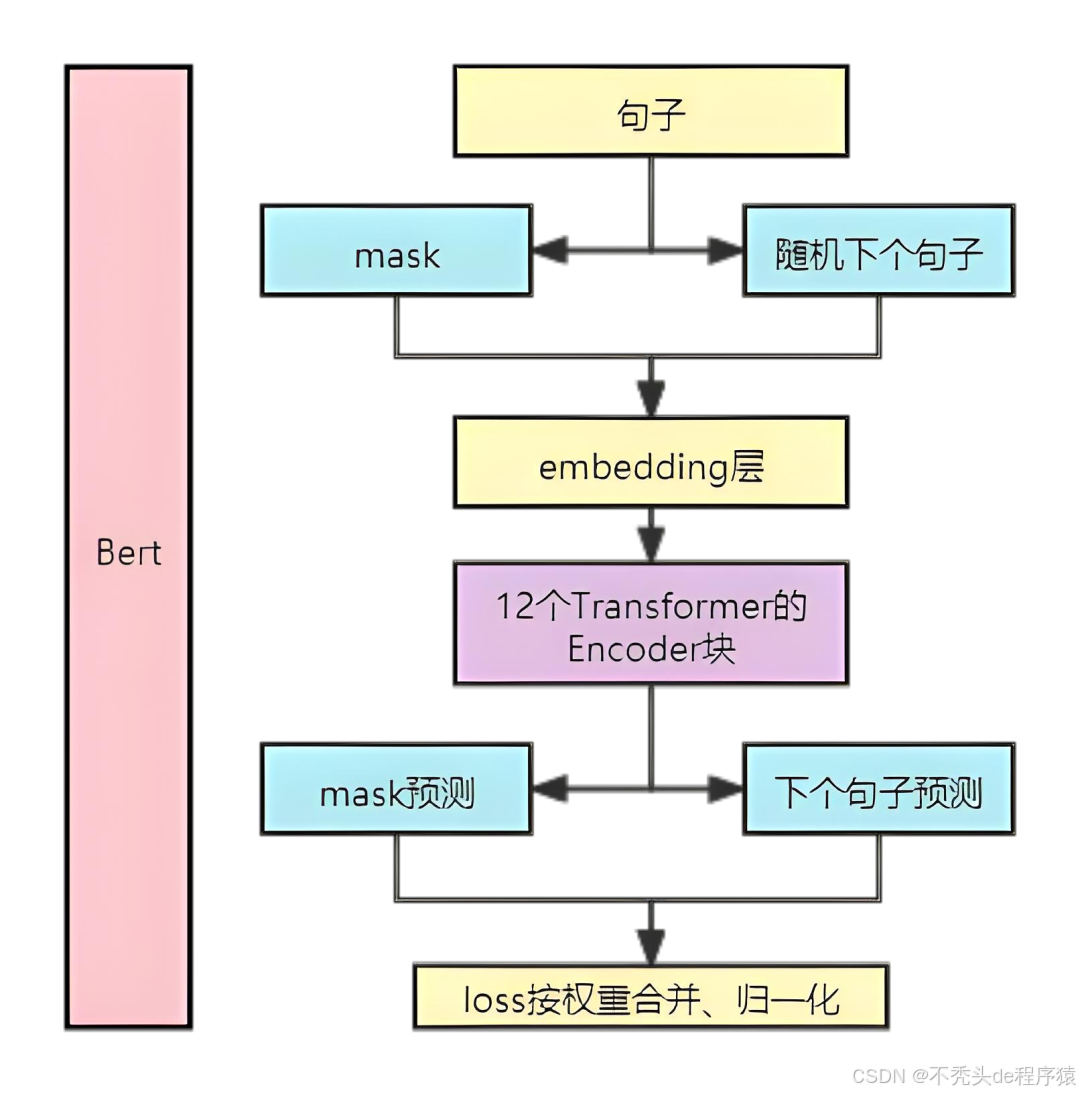
三、问答系统实战(SQuAD数据集)
1. 加载问答数据集
dataset = load_dataset("squad")tokenizer = AutoTokenizer.from_pretrained("distilbert-base-uncased")def preprocess_function(examples): questions = [q.strip() for q in examples["question"]] inputs = tokenizer( questions, examples["context"], max_length=384, truncation="only_second", return_offsets_mapping=True, padding="max_length", ) return inputstokenized_squad = dataset.map(preprocess_function, batched=True)
2. 训练问答模型
from transformers import AutoModelForQuestionAnsweringmodel = AutoModelForQuestionAnswering.from_pretrained("distilbert-base-uncased")training_args = TrainingArguments( output_dir="./qa_results", evaluation_strategy="epoch", learning_rate=3e-5, per_device_train_batch_size=12, num_train_epochs=2,)trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_squad["train"], eval_dataset=tokenized_squad["validation"],)trainer.train()
3. 执行问答
question = "What does NLP stand for?"context = "Natural Language Processing (NLP) is a subfield of artificial intelligence."qa_pipeline = pipeline("question-answering", model=model, tokenizer=tokenizer)result = qa_pipeline(question=question, context=context)print(result)# {'score': 0.982, 'start': 0, 'end': 24, 'answer': 'Natural Language Processing'}
四、命名实体识别实战(CoNLL-2003)
1. 数据预处理
dataset = load_dataset("conll2003")tokenizer = AutoTokenizer.from_pretrained("bert-base-cased")label_list = dataset["train"].features["ner_tags"].feature.namesdef tokenize_and_align_labels(examples): tokenized_inputs = tokenizer( examples["tokens"], truncation=True, is_split_into_words=True ) labels = [] for i, label in enumerate(examples["ner_tags"]): word_ids = tokenized_inputs.word_ids(batch_index=i) previous_word_idx = None label_ids = [] for word_idx in word_ids: if word_idx is None: label_ids.append(-100) elif word_idx != previous_word_idx: label_ids.append(label[word_idx]) else: label_ids.append(-100) previous_word_idx = word_idx labels.append(label_ids) tokenized_inputs["labels"] = labels return tokenized_inputstokenized_dataset = dataset.map(tokenize_and_align_labels, batched=True)
2. 训练NER模型
from transformers import AutoModelForTokenClassificationmodel = AutoModelForTokenClassification.from_pretrained( "bert-base-cased", num_labels=len(label_list) training_args = TrainingArguments( output_dir="./ner_results", evaluation_strategy="epoch", learning_rate=2e-5, per_device_train_batch_size=16, num_train_epochs=3,)trainer = Trainer( model=model, args=training_args, train_dataset=tokenized_dataset["train"], eval_dataset=tokenized_dataset["validation"],)trainer.train()
3. 实体识别推理
from transformers import pipelinener_pipeline = pipeline("ner", model=model, tokenizer=tokenizer)sample_text = "Apple was founded by Steve Jobs in Cupertino, California."entities = ner_pipeline(sample_text)for entity in entities: print(f"{entity['word']} -> {label_list[entity['entity'][-1]]}") # Apple -> B-ORG# Steve Jobs -> B-PER# Cupertino -> B-LOC# California -> B-LOC
五、核心技巧总结
迁移学习优势:使用预训练模型可节省90%训练时间
动态填充:使用DataCollator提升训练效率
混合精度训练:添加fp16=True参数加速训练
学习率调度:采用线性衰减策略更稳定收敛
早停机制:监控验证集损失防止过拟合
六、进阶学习方向
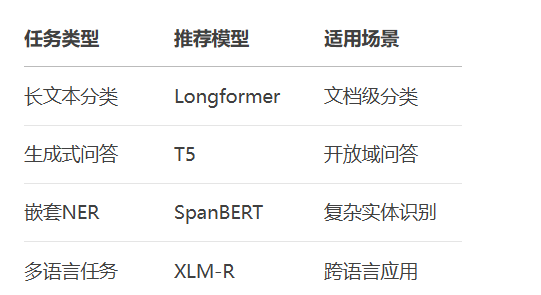
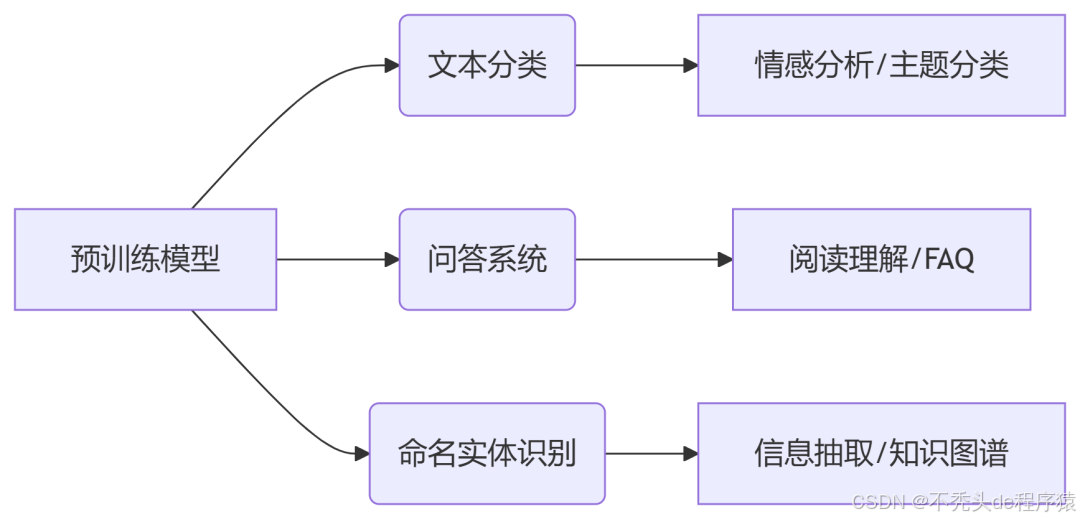
关键提示: 实践时注意调整超参数(batch size、学习率)以适应你的硬件配置,小显存设备建议使用distilbert等轻量模型。
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

















 551
551

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









