



想象一下,有一天你走进办公室,AI助手对你说:
“你今天脸色不太好,是不是昨晚又熬夜?要不要我帮你推迟上午的会议?”
这一切,它是**“看”出来的**,不是你说的。
这听起来像科幻,但其实背后的核心技术已经在我们身边悄然落地——这就是今天要聊的主角:
🎯 多模态大模型融合技术(Multimodal Foundation Models)
让AI不仅能听懂语言,还能看图识人、看视频理事、甚至“脑补”情绪。
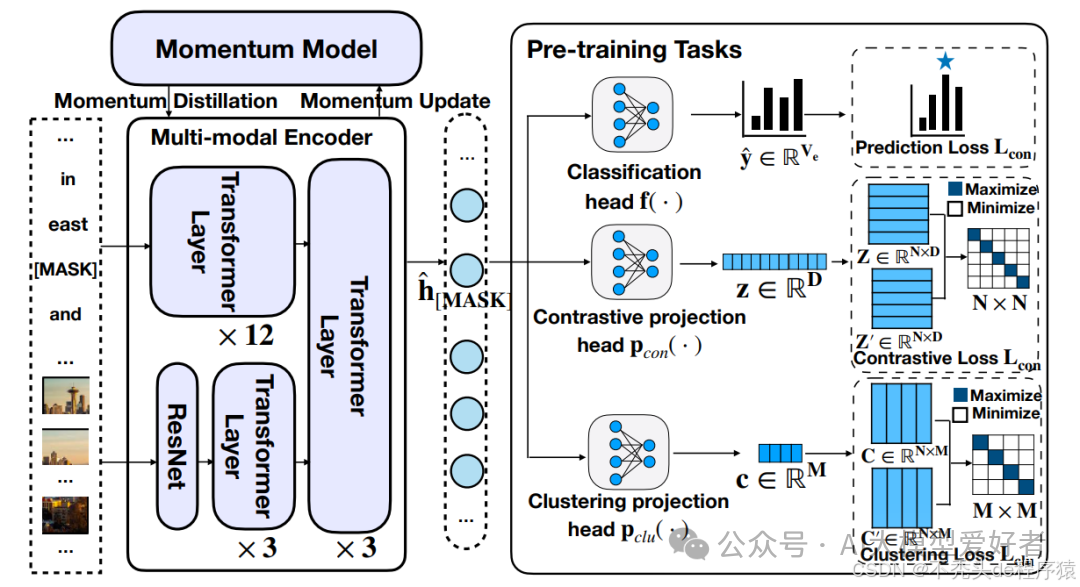
🌈什么是多模态?简单说:AI不再是“文盲”了!
我们人类天生就是多模态的生物——看图识物、听声辨人、读文知意。
而传统的AI大多是“单模态”的,比如:
- GPT-3:只能处理文字;
- CLIP:只能将图像和文字联系;
- Whisper:能听音频但不能看图;
- DALL·E:能生成图像,但不会分析图像内容。
而多模态大模型(Multimodal Large Models),就像是给AI安装了五官,能同时处理文字、图片、音频、视频等信息。
📌换句话说:多模态 = AI的“感官融合”系统!
🧬融合不只是拼接,而是“深度理解”
很多人以为:“那就把图像喂给模型,把文字也喂进去,不就完了?”
其实融合并不是“简单堆数据”,而是让不同模态的数据在底层语义空间对齐,也就是:
🧠 把图像的意思“翻译”成文字能懂的表达
🧠 把语音中的语气“转化”为情绪信息
🧠 把视频的帧序列变成“叙事结构”去理解
这背后依赖三种关键技术:
1️⃣ 模态编码器(Modal Encoder)
不同模态的数据要用不同方法“编码”:
- 文本:Transformer(BERT、GPT)
- 图像:CNN、ViT(视觉Transformer)
- 音频:声纹提取、频谱图卷积等
2️⃣ 多模态对齐(Modality Alignment)
通过共享空间、交叉注意力等方式,把图像和文字的信息“对齐”成统一理解。
3️⃣ 融合机制(Fusion)
有三种方式:
- 早期融合(输入前就拼一起);
- 中期融合(模型内部层层融合);
- 后期融合(各自处理再合并结果)。
🛠多模态大模型代表“全明星阵容”
| 模型名 | 能力 | 发布者 |
|---|---|---|
| GPT-4V | 文+图(看图写字、解图) | OpenAI |
| Gemini | 文+图+视频+代码 | Google DeepMind |
| Qwen-VL | 中文图文多模态 | 阿里通义千问 |
| BLIP-2 | 图像问答、图文生成 | Salesforce |
| Florence-2 | 图像识别+理解 | 微软 |
| MiniGPT-4 | 轻量开源图文模型 | 开源社区 |
📱应用场景举例:多模态AI,正“渗透”生活的方方面面!
📸 图文问答助手
- 用户上传一张餐厅菜单,AI能告诉你哪个菜适合减肥。
- 照张快递单,AI自动读取内容并帮你查快递进度。
🧑⚕️ 医疗影像辅助诊断
-
上传一张X光片+病历文本,AI协助初步判断风险等级;
-
结合语音问诊内容+眼底图像,生成诊断摘要。
🎓 教育场景
- 学生上传一道几何图形题,AI不仅能答题,还能生成详细讲解;
- 视频课件+文本大纲+语音讲解 → 自动生成AI老师!
🛒 智能电商导购
- 拍一张你喜欢的穿搭图 → AI推荐同款商品;
- 输入语音:“我想要适合秋天通勤的咖啡色大衣”,AI能给出图文推荐+搭配建议。
⚙️一个简化的技术实现:做一个“小型图文问答机器人”
这里用开源模型 MiniGPT-4 + Gradio 做个简单demo:
🚀 环境准备
git clone https://github.com/Vision-CAIR/MiniGPT-4.gitconda create -n minigpt python=3.10pip install -r requirements.txt
📦 运行服务
python demo.py
上传图片,输入提问,比如:
“图中这道菜有什么原料?”
AI即可输出“这是糖醋排骨,主要包含猪肉、酱油、白糖和醋”等。
🔮多模态AI是通向“通用人工智能”的必经之路!
为什么谷歌、OpenAI、阿里、Meta都在抢多模态赛道?
因为人类智能就是多模态的!所以想要AI具备“通用推理、认知能力”,多模态融合是根本前提。
未来趋势包括:
🌟 1. 多模态 Agent 系统
不仅能看、听、说,还能自主执行任务。比如:帮你查行程、订票、提醒出发。
🌟 2. 低资源多模态模型
轻量化部署到手机、摄像头、汽车、穿戴设备,实现边缘智能。
🌟 3. 多模态增强记忆
让AI像人一样,通过视觉、语言、场景一起“构建记忆”。
💬写在最后:融合的不是模态,是更接近人类的AI思维!
“会说话”的AI很聪明,
“能看图”的AI更厉害,
而能“看+听+说+理解+行动”的AI,才是真正的数字伙伴。
多模态技术,是AI从工具走向“助理”、从对话走向“理解”的进化之路。
所以:
🎯 Prompt只是开始,
🎯 多模态才是未来,
🎯 谁先掌握融合技术,谁就站上AI时代的浪潮之巅!
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发

大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可

本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









