



KV(Key-Value)缓存是实现大语言模型(LLM)在生产环境中高效推理的关键技术之一。KV 缓存是 LLM 推理阶段中提高计算效率的重要组件。本文将从概念和代码两个层面出发,通过一个从零构建、可读性强的实现,解释它是如何工作的。
内容概览
简而言之,KV 缓存在推理(即模型训练完成后)阶段用于存储中间的 key(K)和值(V)计算结果,并在后续生成过程中复用,从而显著加快文本生成速度。
KV 缓存的不足之处包括:
- 增加代码复杂度;
- 占用更多内存(这是我当初未在书中加入它的主要原因);
- 在训练阶段无法使用。
然而,在实际生产中部署 LLM 时,KV 缓存在推理速度上的提升通常远远超过了这些代价,因此是值得采用的优化策略。
什么是 KV 缓存?
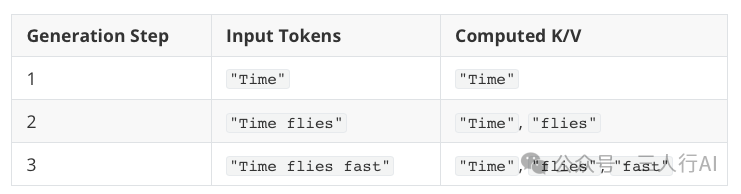
想象一下,LLM 正在生成一段文本。假设模型接收到如下提示词: Time
如你所知,LLM 是按一个词(token)一个词地进行生成的。以下是模型在生成过程中可能发生的两个文本生成步骤的示意:
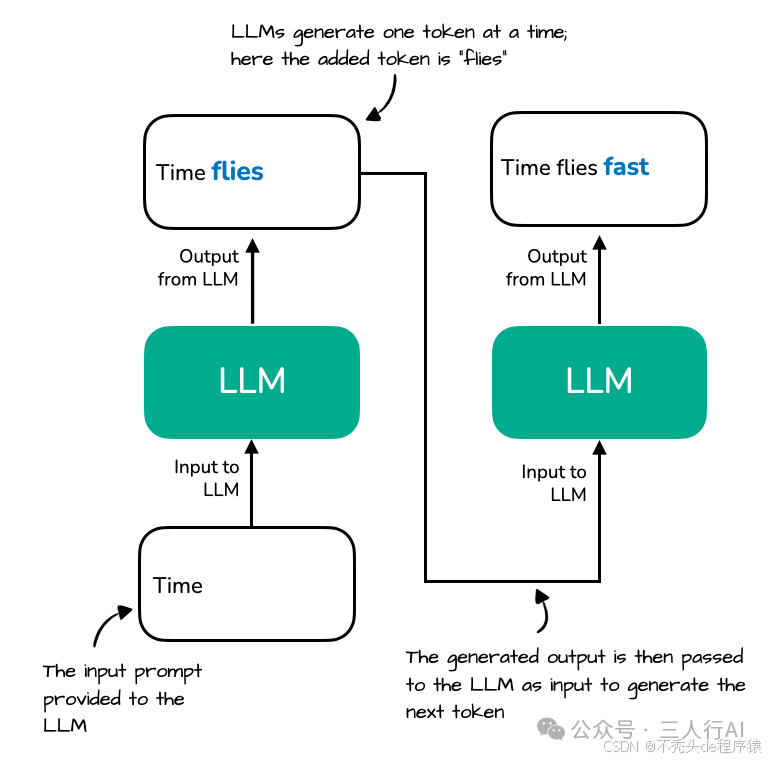
图展示了一个大语言模型(LLM)如何逐个 token 地生成文本。以提示词 "Time" 开始,模型生成下一个 token "flies"。在下一步中,完整的序列 "Time flies" 被重新处理,以生成新的 token "fast"。
请注意,LLM 文本生成输出中存在一些冗余,如下图所示:
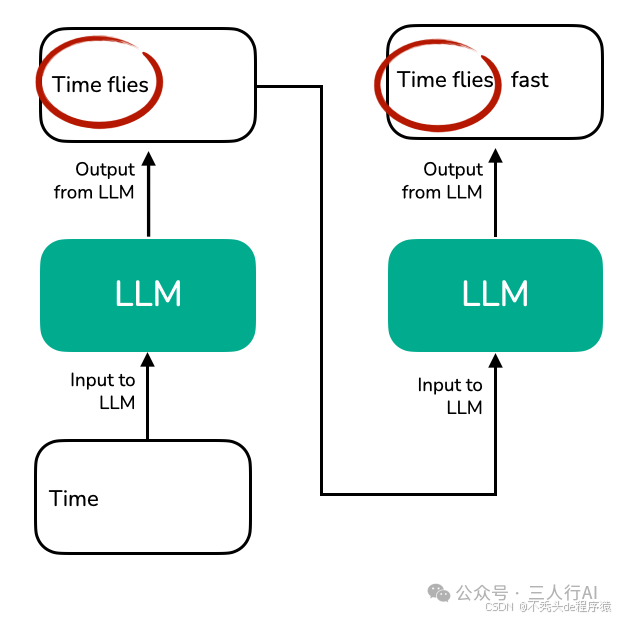
LLM 每一步都必须重新处理整个上下文 "Time flies",以生成下一个 token(例如 "fast"),因为它没有缓存中间的 key/value 状态,这导致了重复编码整个序列的情况。
当我们实现一个 LLM 的文本生成函数时,通常每次只使用上一步生成的最后一个 token。但上图揭示了一个概念层面上的低效之处:每生成一个新 token,都要重复处理已有上下文。如果我们深入查看 注意力机制(attention mechanism),这种冗余将更为明显。
下图展示了 LLM 核心部分——注意力机制中的计算片段。在这个例子中,输入 token "Time" 和 "flies" 被编码为 3 维向量(实际中通常是几百维或上千维,为了便于图示简化为三维)。注意力机制中的矩阵 W 是权重矩阵,它们将这些输入转换为 Key(K)、Value(V) 和 Query(Q) 向量。
图中展示了注意力得分计算的部分内容,重点标出了 key 和 value 向量的生成过程。
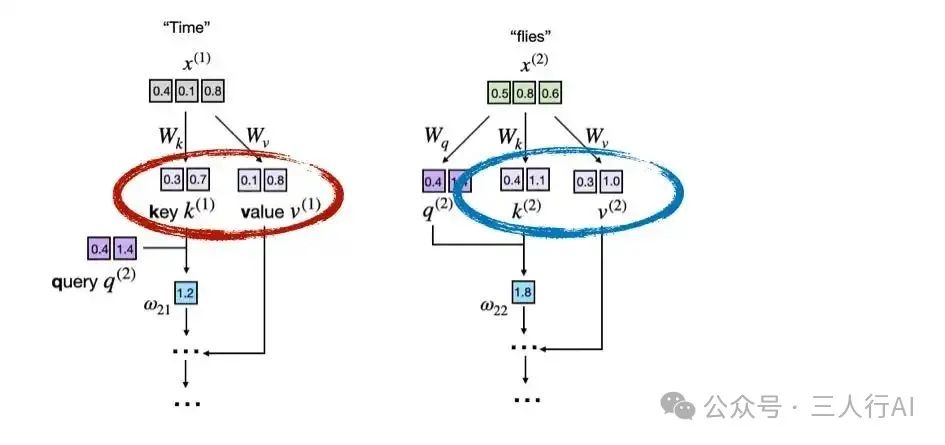
下图说明了 LLM 如何在注意力机制计算中,从 token 的嵌入向量中派生出 key(k)和值(v)向量。
每个输入 token(例如 "Time" 和 "flies")都会通过学习得到的投影矩阵 W_k 和 W_v 进行映射,从而得到对应的 key 和 value 向量。
如前所述,LLM 是一次生成一个词(token)。假设模型已经生成了 "fast",则下一轮的输入变为 "Time flies fast",如下图所示:
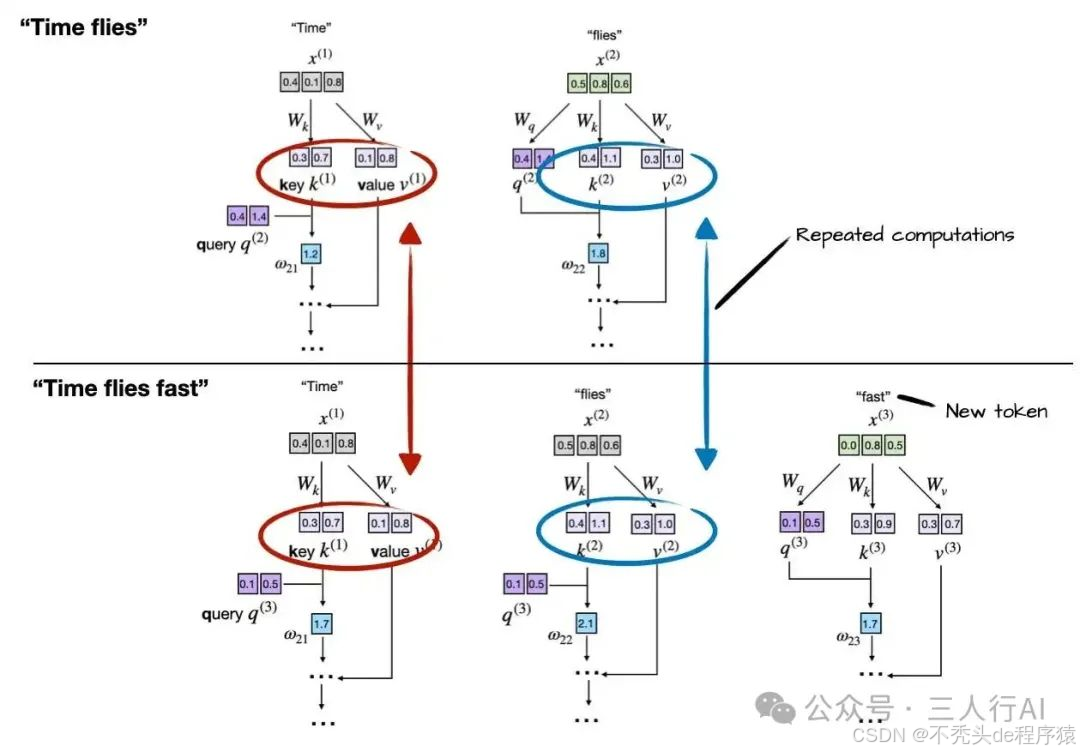
每次生成新 token 时,LLM 会重新为之前的 token(如 "Time" 和 "flies")计算 key 和 value 向量。
比如在生成第三个 token "fast" 时,模型再次计算了 k(1)/v(1) 和 k(2)/v(2),而不是复用之前已经得出的结果。
这种重复计算突显了在自回归(autoregressive)解码过程中未使用 KV 缓存所带来的低效问题。
通过对比前两个图可以看出,前两个 token 的 key 和 value 向量在每一步生成中是完全相同的,而每次都重新计算显然是一种资源浪费。
KV 缓存的核心思想
KV 缓存的目的是:
建立一个缓存机制,将已经生成的 key 和 value 向量保存起来以便复用,从而避免这些不必要的重复计算。

没有 KV 缓存 vs 有 KV 缓存的文本生成过程
我们在上一节中已经了解了 KV 缓存的基本概念,下面在进入具体代码实现之前,我们再详细分析一下其差异。
以 "Time flies fast" 这句文本为例,在没有使用 KV 缓存的情况下,生成过程如下:
每生成一个新 token,模型都重新计算此前所有 token 的 key 和 value 向量。
比如:“Time” 和 “flies” 的向量在每一步都被重复计算。
而使用 KV 缓存后,这种冗余被有效消除,机制如下:
-
首次生成时
,模型计算并缓存输入 token 的 key 和 value 向量;
-
之后每生成一个新 token
,仅计算该 token 的 key 和 value;
-
之前的向量从缓存中读取
,无需重新计算。
总结:计算与缓存流程一览表

KV 缓存带来的好处在于:
-
"Time"只被计算了一次,却被复用了两次;
-
"flies"只被计算了一次,被复用了一次。
(这是一个简短的文本示例,为了简洁易懂。但你应该可以直观地理解:文本越长,可复用的 key 和 value 越多,生成速度提升就越明显。)
使用与不使用 KV 缓存的对比图示
下图并列展示了第 3 个 token 的生成步骤在有无 KV 缓存时的差异:
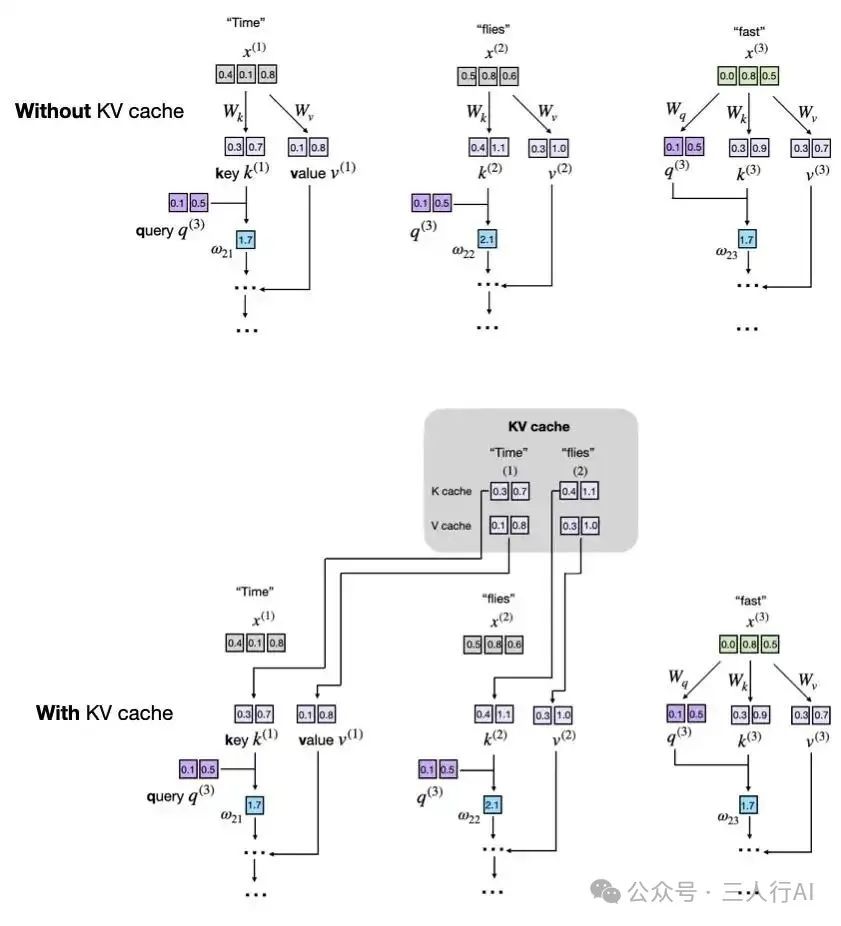
上半部分(无缓存):每个 token 的生成步骤都重新计算 key 和 value,导致操作重复;下半部分(有缓存):直接从 KV 缓存中读取已计算的 key 和 value,避免了重复计算,实现更快生成。
实现 KV 缓存的原理其实很简单:
我们只需像平常一样计算 key 和 value 向量,然后将它们缓存起来,以便下一步可以读取复用。
接下来,我们将通过一个具体代码示例演示 KV 缓存的实现方式。
从零实现 KV 缓存
KV 缓存的实现方式有很多种,其核心思想是:
在每个生成步骤中,仅计算新生成 token 的 key 和 value 向量,而之前的结果通过缓存获取。
这里我选择了一个重点突出“可读性”的简洁实现方式。
最好的理解方式就是直接浏览代码改动,看看是如何实现的。
我在 GitHub 上分享了两个自包含的 Python 脚本,用于从零实现 LLM(带/不带 KV 缓存):
📄 gpt_ch04.py
- 摘自我《从零构建大型语言模型》一书的第 3 和第 4 章;
- 包含基本的 LLM 实现及简单的文本生成函数;
- 不包含 KV 缓存。
📄 gpt_with_kv_cache.py
- 与上面相同,但加入了 KV 缓存的必要改动。
如何查看 KV 缓存的相关代码改动?
你可以按以下方式操作:
✅ 方法一:打开 gpt_with_kv_cache.py
- 搜索
# NEW标签,这些标记的部分即为新增实现 KV 缓存的代码。 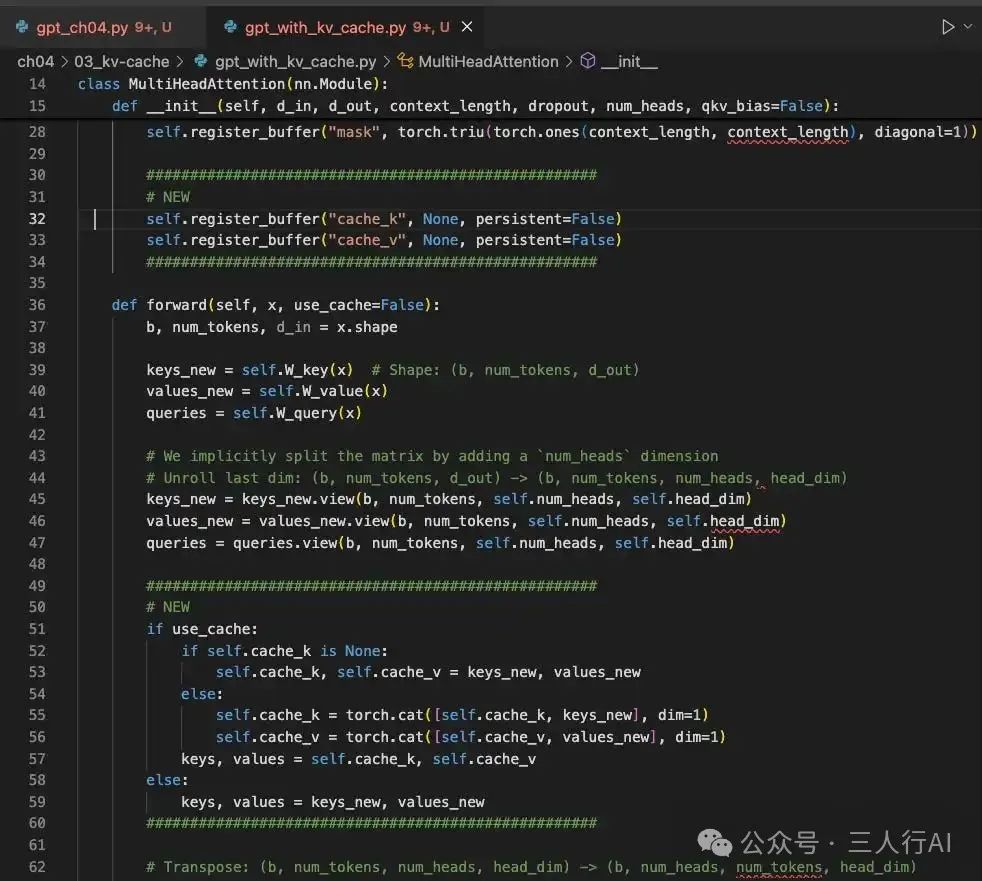
✅ 方法二:使用代码差异比较工具
你也可以使用自己喜欢的文件差异比较工具(diff 工具),来对比 gpt_ch04.py 与 gpt_with_kv_cache.py 两个文件之间的变化内容。
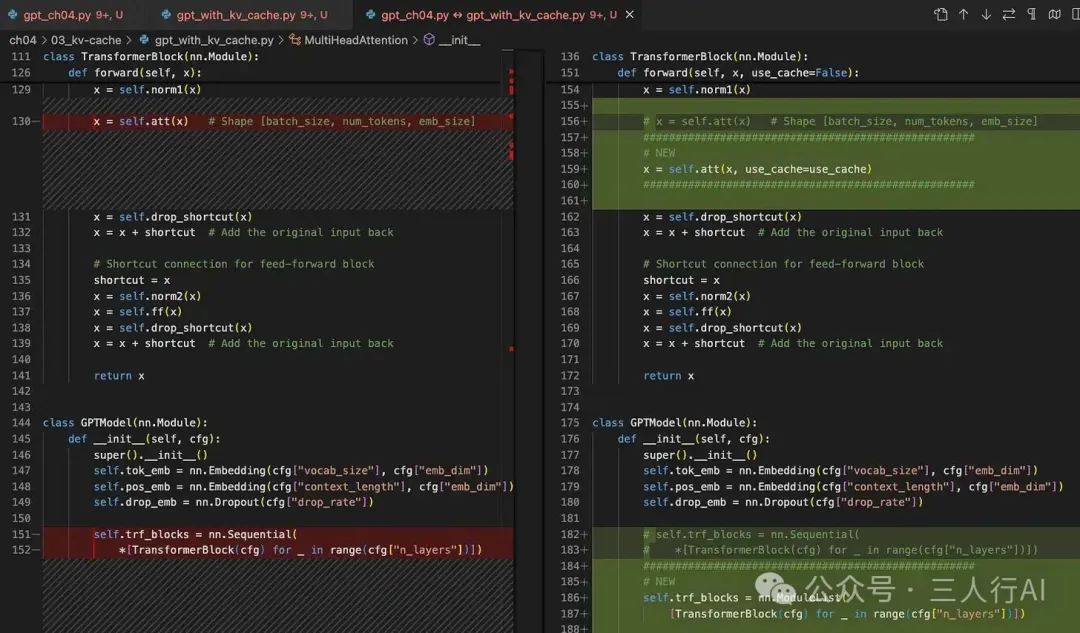
KV 缓存实现细节概览
下面几小节将简要走通整个 KV 缓存的实现过程。
1. 注册缓存缓冲区(Registering the Cache Buffers)
在 MultiHeadAttention 构造函数中,添加两个非持久化的缓存 buffer:cache_k 和 cache_v,用于在生成过程中逐步拼接并存储历史 key 和 value:
self.register_buffer("cache_k", None, persistent=False)
self.register_buffer("cache_v", None, persistent=False)
2. 在前向传播中加入 use_cache 标志
接下来,我们扩展 MultiHeadAttention 类的 forward 方法,新增一个参数 use_cache:
复制
编辑```
def forward(self, x, use_cache=False):
b, num_tokens, d_in = x.shape
keys_new = self.W_key(x) # 形状: (b, num_tokens, d_out)
values_new = self.W_value(x)
queries = self.W_query(x)
# ...
如果启用了 KV 缓存(即 use_cache=True),则使用如下逻辑:
if use_cache:
if self.cache_k is None:
self.cache_k, self.cache_v = keys_new, values_new
else:
self.cache_k = torch.cat([self.cache_k, keys_new], dim=1)
self.cache_v = torch.cat([self.cache_v, values_new], dim=1)
keys, values = self.cache_k, self.cache_v
else:
keys, values = keys_new, values_new
这段逻辑实现了 KV 缓存的核心思想:
- 每次只计算当前新 token 的
key和value; - 然后将其拼接到之前的缓存中;
- 后续步骤中直接复用缓存中累积的 key 和 value,避免重复计算。
🧠 存储(Storing)
具体来说,在缓存初始化之后(通过 if self.cache_k is None: 分支),我们使用如下语句将新生成的 key 和 value 添加到缓存中:
self.cache_k = torch.cat([...], dim=1)
self.cache_v = torch.cat([...], dim=1)
这样,当前步骤生成的 key 和 value 就被拼接进了缓存中。
📥 **读取(Retrieving)**之后,我们通过以下语句从缓存中读取 key 和 value:
keys, values = self.cache_k, self.cache_v
这就是 KV 缓存的核心机制:存储 + 读取。 而接下来的第 3 和第 4 部分,则处理一些补充的实现细节。
3. 清空缓存(Clearing the Cache)
在多轮文本生成任务中,我们需要注意:在每次文本生成调用之间,必须重置缓存中的 key 和 value,否则模型会在新提示词(prompt)中错误地关联到上一次生成残留的上下文,导致生成不连贯、甚至完全错误。
为此,我们在 MultiHeadAttention 类中添加一个 reset_cache 方法,用于在文本生成前清除缓存:
def reset_cache(self):
self.cache_k, self.cache_v = None, None
4. 在完整模型中传播 use_cache 参数
在修改完 MultiHeadAttention 后,我们还需要修改顶层的GPTModel类:
➕ 添加当前 token 的位置追踪在模型初始化中添加以下变量:
self.current_pos = 0
这是一个简单的计数器,用于记录当前缓存中已经包含了多少个 token,方便在增量生成时正确计算位置编码。
🔁 用显式循环替代 block 调用,传递 use_cache 参数 修改 GPTModel 的 forward 方法如下:
def forward(self, in_idx, use_cache=False):
# ...
if use_cache:
pos_ids = torch.arange(
self.current_pos, self.current_pos + seq_len,
device=in_idx.device, dtype=torch.long
)
self.current_pos += seq_len
else:
pos_ids = torch.arange(
0, seq_len, device=in_idx.device, dtype=torch.long
)
pos_embeds = self.pos_emb(pos_ids).unsqueeze(0)
x = tok_embeds + pos_embeds
# ...
for blk in self.trf_blocks:
x = blk(x, use_cache=use_cache)
🔄 效果说明当 use_cache=True 时:
- 我们从
self.current_pos开始生成pos_ids; - 并将当前位置指针 ``+= seq_len`;
- 这样下一次生成可以从上次停止的地方接着生成。
self.current_pos 跟踪的原因是:新生成的 query 必须紧接在已缓存的 key 和 value 之后对齐。如果不使用计数器,每一步都会从位置 0 开始,模型就会误认为新 token 与之前的 token 是重叠的。 (另外一种方式是通过偏移量追踪:offset = block.att.cache_k.shape[1])
上述更改也要求对 TransformerBlock 类做一个小的修改,以接受 use_cache 参数:
def forward(self, x, use_cache=False):
# ...
self.att(x, use_cache=use_cache)
最后,我们在 GPTModel 中添加一个模型级别的 reset 方法,用于一次性清除所有 block 的缓存,便于使用:
def reset_kv_cache(self):
for blk in self.trf_blocks:
blk.att.reset_cache()
self.current_pos = 0
5. 使用缓存进行文本生成
随着 GPTModel、TransformerBlock 和 MultiHeadAttention 的更改,
最终我们可以在一个简单的文本生成函数中使用 KV 缓存:
def generate_text_simple_cached(
model, idx, max_new_tokens, use_cache=True
):
model.eval()
ctx_len = model.pos_emb.num_embeddings # 最大支持长度,例如 1024
if use_cache:
# 使用完整提示词初始化缓存
model.reset_kv_cache()
with torch.no_grad():
logits = model(idx[:, -ctx_len:], use_cache=True)
for _ in range(max_new_tokens):
# a) 选择具有最高 log-probability 的 token
next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)
# b) 将其追加到当前序列中
idx = torch.cat([idx, next_idx], dim=1)
# c) 仅将新 token 输入模型
with torch.no_grad():
logits = model(next_idx, use_cache=True)
else:
for _ in range(max_new_tokens):
with torch.no_grad():
logits = model(idx[:, -ctx_len:], use_cache=False)
next_idx = logits[:, -1].argmax(dim=-1, keepdim=True)
idx = torch.cat([idx, next_idx], dim=1)
return idx
请注意,在 c) 步中我们只将新 token 喂给模型: logits = model(next_idx, use_cache=True)如果不使用缓存,我们需要将完整输入再次送入模型:
logits = model(idx[:, -ctx_len:], use_cache=False) 因为模型没有缓存的 key 和 value 可供复用。
一个简单的性能对比
在讲解完 KV 缓存的概念后,接下来的关键问题是:
在实践中它的性能表现如何?
为了验证这一点,我们可以运行前文提到的两个 Python 脚本,使用一个包含 1.24 亿参数的小型 LLM 来生成 200 个新 token(初始 prompt 为 4 个 token:“Hello, I am”):
pip install -r https://raw.githubusercontent.com/rasbt/LLMs-from-scratch/refs/heads/main/requirements.txt
python gpt_ch04.py
python gpt_with_kv_cache.py
在一台搭载 M4 芯片的 Mac Mini(CPU)上运行,结果如下:
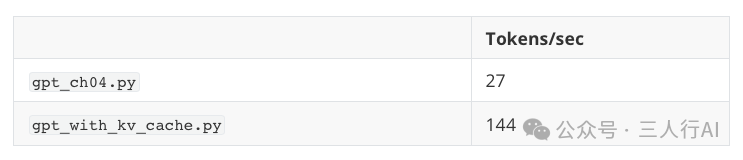
📊 实验结果: 即使是只有 1.24 亿参数的小模型,在 200 token 的短文本上也能实现 约 5 倍的加速效果!
(注意:本实现以“代码可读性”为优先目标,未针对 CUDA 或 MPS 进行性能优化,例如预分配张量而不是每次重新分配并拼接。)
⚠️ 注意:无论是否使用 KV 缓存,模型生成的文本看起来都是“乱码”,例如:css
输出文本:Hello, I am Featureiman Byeswickattribute argue logger Normandy Compton analogous bore ITVEGIN ministriesysics Kle functional recountrictionchangingVirgin embarrassedgl … 这是因为当前模型尚未训练。下一章节将会训练该模型,并可在训练后的模型上启用 KV 缓存以生成连贯文本。不过请记住:KV 缓存仅用于推理阶段(inference),不能用于训练阶段。
✅ 更重要的一点:尽管我们使用了两种不同的实现方式(gpt_ch04.py 和 gpt_with_kv_cache.py),它们生成的文本是完全一致的。这说明我们实现的 KV 缓存是正确的。因为在 KV 缓存中非常容易因索引错误而导致生成结果出现偏差,确保一致性是验证实现正确性的重要方式。
KV 缓存的优缺点
随着序列长度的增加,KV 缓存的优劣势将愈发明显,表现如下:
- ✅ [优点] 计算效率显著提升:不使用缓存:在第 t 步中,注意力机制需要将当前 query 与前 t 个 key 进行比较,累计计算量呈平方增长,复杂度为 O(n²); 使用缓存:每个 key 和 value 只需计算一次,并可复用,每步推理复杂度降低为线性 O(n)。
- ⚠️ [缺点] 内存占用线性增加:每生成一个新 token,就会将其对应的 key 和 value 添加进缓存;对于长序列和大模型,KV 缓存的累计大小可能非常庞大,甚至占满 GPU 内存;可通过截断 KV 缓存作为权衡(例如只保留最近一部分 token),但这会进一步增加实现复杂度。然而在实际部署 LLM 时,这些复杂度往往是值得的。
优化 KV 缓存的实现
上文中讲解的 KV 缓存实现主要是为了可读性和教学目的。 但如果要应用到实际生产环境(尤其是在处理更大模型和更长序列时),则需要更多优化措施。
常见的扩展陷阱(Pitfalls)
-
内存碎片 & 重复分配
:持续使用
torch.cat拼接张量,会频繁触发内存重新分配,造成性能瓶颈; -
内存线性增长
:未加处理时,KV 缓存会随着序列增长而占用不可控的大量内存。
💡 Tip 1:预分配内存(Pre-allocate Memory)
与其不断拼接张量,不如在一开始就根据最大可能序列长度预分配足够大的缓存张量:
# 预分配 key 和 value 缓存示例
max_seq_len = 1024 # 预计最大序列长度
cache_k = torch.zeros(
(batch_size, num_heads, max_seq_len, head_dim), device=device
)
cache_v = torch.zeros(
(batch_size, num_heads, max_seq_len, head_dim), device=device
)
在推理过程中,只需将每一步新计算结果写入对应的切片即可。
💡 Tip 2:滑动窗口截断缓存(Sliding Window)
为避免 GPU 内存暴涨,可以采用滑动窗口机制,仅保留最近的一部分 token 缓存:
# 滑动窗口缓存示例
window_size = 512
cache_k = cache_k[:, :, -window_size:, :]
cache_v = cache_v[:, :, -window_size:, :]
实践中的优化版本
这些优化方案可以在 gpt_with_kv_cache_optimized.py 文件中找到。
在一台 M4 芯片的 Mac Mini(CPU)上,使用 200 token 序列生成、窗口大小等于模型上下文长度的条件下(保证结果一致、对比公平),得到如下运行时间对比:

⚠️ 注意:在 CUDA 设备上,KV 缓存的速度优势几乎消失。这是因为当前模型较小,设备之间的通信和张量传输所耗时间反而超过了缓存所节省的时间。
结语:权衡与实用性
尽管 KV 缓存会带来一定的代码复杂度与内存管理压力,但它带来的效率提升在生产环境中通常是非常可观的。
本教程为了教学目的,优先强调了代码的可读性而非性能。但在实际部署中,你可能需要结合如下优化方式:预分配内存;使用滑动窗口缓存机制
普通人如何抓住AI大模型的风口?
领取方式在文末
为什么要学习大模型?
目前AI大模型的技术岗位与能力培养随着人工智能技术的迅速发展和应用 , 大模型作为其中的重要组成部分 , 正逐渐成为推动人工智能发展的重要引擎 。大模型以其强大的数据处理和模式识别能力, 广泛应用于自然语言处理 、计算机视觉 、 智能推荐等领域 ,为各行各业带来了革命性的改变和机遇 。
目前,开源人工智能大模型已应用于医疗、政务、法律、汽车、娱乐、金融、互联网、教育、制造业、企业服务等多个场景,其中,应用于金融、企业服务、制造业和法律领域的大模型在本次调研中占比超过 30%。

随着AI大模型技术的迅速发展,相关岗位的需求也日益增加。大模型产业链催生了一批高薪新职业:

人工智能大潮已来,不加入就可能被淘汰。如果你是技术人,尤其是互联网从业者,现在就开始学习AI大模型技术,真的是给你的人生一个重要建议!
最后
只要你真心想学习AI大模型技术,这份精心整理的学习资料我愿意无偿分享给你,但是想学技术去乱搞的人别来找我!
在当前这个人工智能高速发展的时代,AI大模型正在深刻改变各行各业。我国对高水平AI人才的需求也日益增长,真正懂技术、能落地的人才依旧紧缺。我也希望通过这份资料,能够帮助更多有志于AI领域的朋友入门并深入学习。
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发
大模型全套学习资料展示
自我们与MoPaaS魔泊云合作以来,我们不断打磨课程体系与技术内容,在细节上精益求精,同时在技术层面也新增了许多前沿且实用的内容,力求为大家带来更系统、更实战、更落地的大模型学习体验。

希望这份系统、实用的大模型学习路径,能够帮助你从零入门,进阶到实战,真正掌握AI时代的核心技能!
01 教学内容

-
从零到精通完整闭环:【基础理论 →RAG开发 → Agent设计 → 模型微调与私有化部署调→热门技术】5大模块,内容比传统教材更贴近企业实战!
-
大量真实项目案例: 带你亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!
02适学人群
应届毕业生: 无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型: 非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能突破瓶颈: 传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。

vx扫描下方二维码即可
本教程比较珍贵,仅限大家自行学习,不要传播!更严禁商用!
03 入门到进阶学习路线图
大模型学习路线图,整体分为5个大的阶段:

04 视频和书籍PDF合集

从0到掌握主流大模型技术视频教程(涵盖模型训练、微调、RAG、LangChain、Agent开发等实战方向)

新手必备的大模型学习PDF书单来了!全是硬核知识,帮你少走弯路(不吹牛,真有用)

05 行业报告+白皮书合集
收集70+报告与白皮书,了解行业最新动态!

06 90+份面试题/经验
AI大模型岗位面试经验总结(谁学技术不是为了赚$呢,找个好的岗位很重要)

07 deepseek部署包+技巧大全

由于篇幅有限
只展示部分资料
并且还在持续更新中…
真诚无偿分享!!!
vx扫描下方二维码即可
加上后会一个个给大家发


















 1590
1590

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









