



Stable Diffusion,一款强大的AI模型,让我们能够创造出惊人的艺术作品。本文将为您介绍如何安装StableDiffusion以及深入使用的学习教程。

1. 安装Stable Diffusion
(主义需要的小伙伴可以文末自行扫描获取)
StableDiffusion的安装可能是第一步,但它绝对是重要的一步。以下是一些安装方式:**AutoDL:**AutoD镜像版本,现在维护到V16。镜像地址:AUTOMATIC1111/stablediffusionwebui/tzwm_sd_webui_A1111。webui 1.6.0 整合版,支持 SDXL,一键启动,带视频教程。预置ControlNet v1.1.410 所有模型含 IP-Adapter、汉化、tagger等常用插件、模型路径优化。有问题可以在微信交流讨论群咨询。
● 秋叶整合包:**可在B站搜索,Stable Diffusion,第一个就是秋叶大佬。Stable
Diffusion整合包有适合不同环境的版本。Stable Diffusion整合包v4.4发布
● 星空大佬:**AI绘画整合包(新增 Controlnet1.1和SadTalker)
● kaggle:**Kaggle上也可以找到稳定的版本。stable-diffusion-webui-kaggle、zh-stable-
diffusion-webui-kaggle
● 腾讯云:**腾讯云也提供了低成本的Stable Diffusion部署方式。
2. 模型Checkpoint
Checkpoint文件对于训练模型的作者和使用者都至关重要。它们包含了模型参数和优化器状态等信息,是训练过程中的状态快照。对于使用者而言,可以将
Checkpoint 文件理解为一种风格滤镜,例如肖像、漫画、水墨、写实风等。通过选择对应的 Checkpoint 文件,您可以将 Stable
Diffusion 模型生成的结果转换为您所选择的特定风格。
下载Checkpoint文件时,请查看相关的模型说明,作者通常提供了文件和使用说明,以帮助您更好地使用和理解文件。

Checkpoint按画风可以分为三类:

官方发布的Stable
Diffusion1.4/1.5/2.0/2.1等模型效果都比较一般,现在大家用的比较多的,都是私炉模型。目前主流的模型下载网站有:Hugging
Face、Civitai(需要有魔法) 、libilibi等。
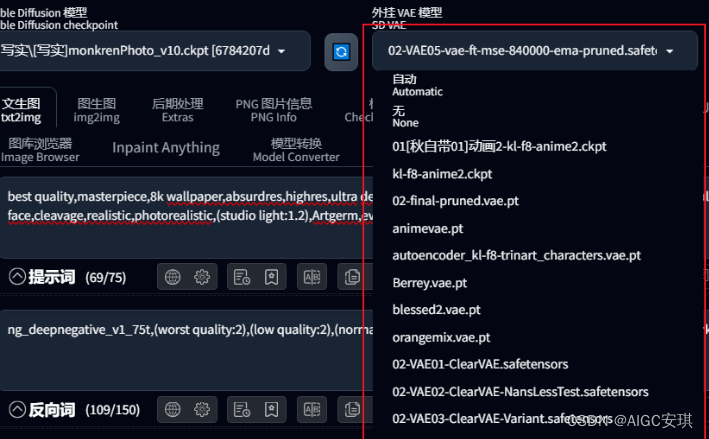
3. VAE(变分自解码器)
VAE负责将加噪后的潜空间数据转为正常图像,可以简单理解为模型的调色滤镜,主要影响画面的色彩质感。目前大多数新模型在文件中已经融合了VAE,还有一些作者会在model
介绍中推荐合适的VAE。
VAE文件后缀一般是.pt,或者是.safetensor,存放路径是将VAE文件也放在models/Stable-
diffusion文件夹下,然后将文件名改成和模型名一致,再在后缀.pt前添加.vae字段,这样就可以在加载模型时选择自动加载VAE了。
4. Embeddings
Embeddings技术可以将输入数据转化为向量表示,以便模型更好地进行处理和生。Embeddings可以用于控制人物特征、动作和风格。与其他模型(如LORA)相比,Embeddings的大小较小,更加方便存储和使用。它通常用于生成特定的样本,而不需要手动输入大量描述词汇。下面是一些常用的Embeddings:
● 特定人物形象:例如Corneo’s D.va,这些Embeddings用于控制特定角色的特征。
● 风格Embeddings:用于控制生成图片的风格。
● 画风Embeddings:用于赋予生成图片不同的画风。
● 概念(Concept)Embeddings:用于实现不同概念或主题的图片生成。
● 服饰Embeddings:用于控制角色的服装。

在C站或者liblibai网站上,常用的负面embeddings:
badhandv4、EasyNegativeV2(针对二次元模型训练的,解决肢体混乱、颜色混杂、灰度异常等等一系列负面问题,触发词easynegative)、Deep
Negative
V1.x(针对真人模型训练的。解决包括错误的人体解剖结构、令人反感的配色方案、颠倒的空间结构等等问题。触发词NG_DeepNegative_V1_75T。)

5. LORA(Local Operation Repeatedly Applied)
LORA是一种重要的技术,用于改善整体的画风,使生成的图片更具特定特征。LORA模型可以被用来实现以下几种效果:

● 人物角色LORA:用于控制特定人物的外貌和特征。
● 画风LORA:改变生成图片的整体画风。
● 概念(Concept)LORA:用于实现特定概念或主题的图片生成。
● 服饰LORA:用于控制角色的服装。

新手必备的lora:
Detail Tweaker LoRA (细节调整LoRA)、leosam’s filmgirl 胶片风 lora、Adjuster 衣物增/减
LoRA、Polaroid LoRA(拍立得LORA)、娜乌斯嘉角色lora、墨幽角色LoRa、国风未来lora、汉服宋服lora、小李国风系列。
需要注意的是,在LORA作者的信息总,会介绍 LORA 模型对应的底模和触发、权重,需要注意查看。
加载LORA扩展模型方法:
SD1.5版本:我们点击文生图下面红色小按钮,就可以显示扩展模型选项。
SD1.6版本如下图:点击窗口中的lora,TAB页切换。

点击lora图片上的图标,可在弹出窗口页面维护触发词和权重,下次使用时可自动带出。

在设置——扩展模型中,可以设置一些细节。比如设置模型展示方式是卡牌还是缩略图,卡牌宽高尺寸、LORA模型加载权重等等。

LORA使用介绍:
使用真实系大模型+角色LORA,就可以得到一个真人coser形象。结合controlnet还可以设计角色的姿势及构图,定制自己的作品。

idillustration互联网插画风模型

真实室内模型_realistic interior design v1

永一丨凤冠霞帔

当想强化作品中某种方面的特质时,可以叠加使用多个lora,例如使用人物+服装+风格lora来生成图片。具体使用时,你可以通过控制不同lora的权重,使得作品更像某一种lora。
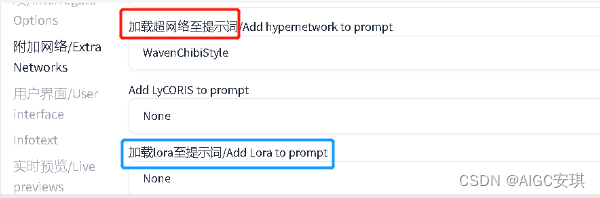
6. Hypernetwork
Hypernetwork与LORA类似,但通常用于改善整体的画风,而不是改变画风。Hypernetwork的效果更细腻,可以处理不同画风之间的微小差异。这对于创造特定的画面风格非常有用。
7. 插件安装
为了更好地使用Stable
Diffusion,您可以安装一些插件,例如图库浏览器、提示词补全、提示词反推、局部细节重绘等。这些插件可以提供更多的功能和便捷性。
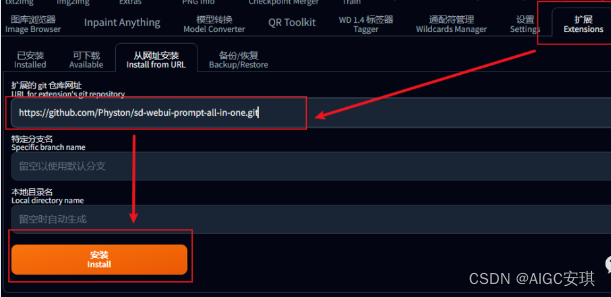
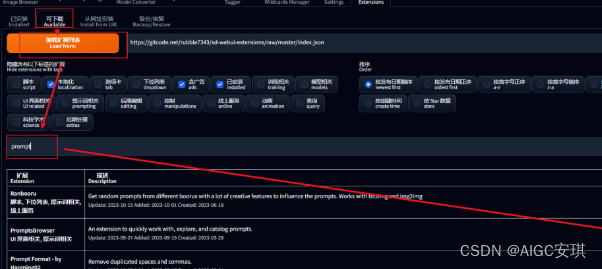
1. 安装方法:网址安装
打开可安装选框,点击load form就可以看到所有可安装的插件。在搜素框搜索到要安装的插件,点击右侧install就可以自动安装了。
2. 安装方法:可下载-加载可安****装应用
3. 安装方法:下载安装
前两种方式在网络不好时可能会安装错误,更彻底的方式是直接下载插件安装包进行安装。比如将下载好的压缩包解压后放到extensions文件夹下。https://github.com/Physton/sd-
webui-prompt-all-in-one.git
安装完后点击重启webui进行刷新,插件安装正确就会出现在已安装列表中。


如果某个插件不能用了,点击右侧的检查更新按钮,一般更新到最新版本就可以解决了。如果某个插件还是有问题,可以点击前面的复选框暂时取消使用。

也可以在启动器中的模型管理–扩展栏目进行更新,卸载。
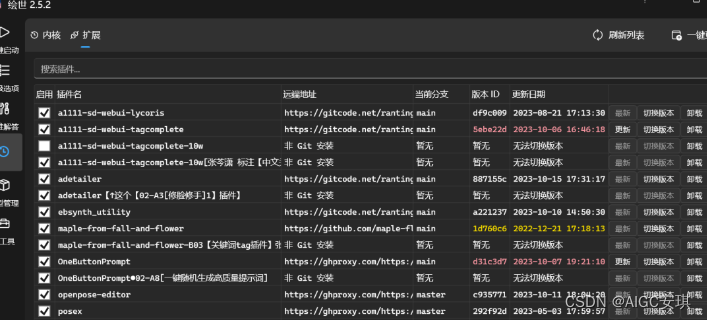
介绍几款常用插件:
中文语言包:搜索zh(取消勾选本地化/Localization的筛选)
图库浏览器:搜索image browser
提示词补全: 搜索tag complete,中文词库见网盘
提示词反推:搜索tagger
Ultimate Upscale脚本:SD upscale升级版,用于图片放大。 搜索ultimate upscale
Local Latent Couple:局部细节重绘,搜索llul
Cutoff:精准控色,防止串色,搜索cut off
prompt-all-in-one:prompt综合插件,《提示词补全插件》
8.提示词工具:
魔咒百科词典、NovelAi魔导书、AI提示词加速器、AI tag生成工具、NovelAI tag生成器 V2.1、:可以简单生成提示词:
提示词参考网站:Civitai(魔法)
、libilibi、炼丹阁、DesAi、openart(偏欧美)、arthub(偏亚洲)这几个网站都有很多优秀的图片可以参考。

但由于AIGC刚刚爆火,网上相关内容的文章博客五花八门、良莠不齐。要么杂乱、零散、碎片化,看着看着就衔接不上了,要么内容质量太浅,学不到干货。
这里分享给大家一份Adobe大神整理的《AIGC全家桶学习笔记》,相信大家会对AIGC有着更深入、更系统的理解。
有需要的朋友,可以长按下方二维码,免费领取!

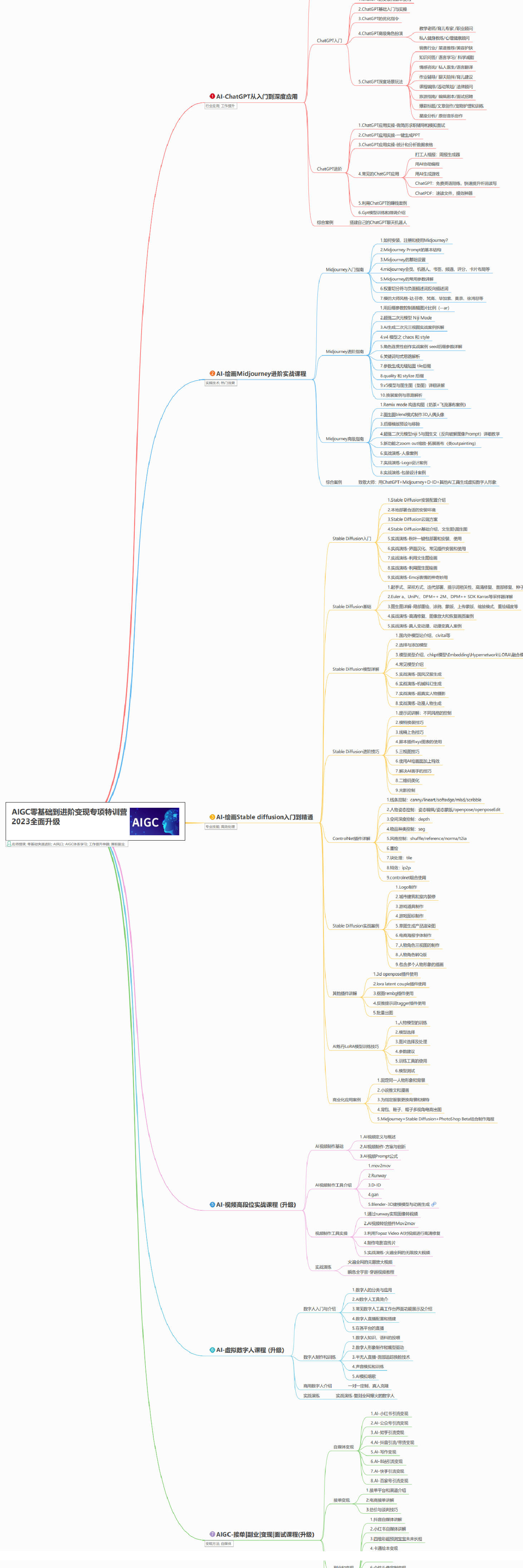
AIGC所有方向的学习路线思维导图
这里为大家提供了总的路线图。它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。如果下面这个学习路线能帮助大家将AI利用到自身工作上去,那么我的使命也就完成了:
AIGC工具库
AIGC工具库是一个利用人工智能技术来生成应用程序的代码和内容的工具集合,通过使用AIGC工具库,能更加快速,准确的辅助我们学习AIGC

有需要的朋友,可以点击下方卡片免费领取!
精品AIGC学习书籍手册
书籍阅读永不过时,阅读AIGC经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验,结合自身案例融会贯通。
AI绘画视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,科学有趣才能更方便的学习下去。

有需要的朋友,可以长按下方二维码,免费领取!

















 2771
2771

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









