



前两天,OpenAI开源新模型Circuit-Sparsity,模型参数量仅0.4B,**99.9%**的权重为零。
▲Circuit-Sparsity开源(来源:Hugging Face)
这个技术试图解决模型的可解释性问题,简单来说就是回答“模型为什么做出这个决策?”以及“它是如何得出这个结果的?”这两个问题。
在AI飞速发展的今天,大语言模型(LLM)虽然表现出了惊人的能力,但其内部运作机制始终像一个神秘的“黑箱”。
我们不知道它为何做出某个回答,也不清楚它是如何从海量数据中提取知识的。这种不可解释性,成为了AI在医疗、金融、法律等高风险领域落地的重大障碍。
对此,OpenAI研究团队训练出了一个权重稀疏的Transformer模型,强制模型权重矩阵中**99.9%权重为零,仅保留0.1%**非零权重。
在这项研究中,研究团队在模型内部形成了紧凑且可读的**“电路”(Circuits)**,每个电路都仅保留了保证模型性能的关键节点,神经元的激活变得具有明确的语义。
有外网网友称这一技术让当下的MoE(混合专家模型)走到了尽头,并说“我们一直以来都将权重隔离到‘专家’中,以此粗略地近似稀疏性,仅仅是为了满足稠密矩阵核的要求。”

▲外网评价(图源:X)
更有网友将这项研究形容为将模型“减肥到只剩骨架”,还说这项研究就好像打开了黑匣子,不试图解开稠密模型而是直接构建稀疏模型,正是这项研究有趣的地方。
▲外网评价(图源:X)
但有些网友却不这么认为,称其没有看出MoE模型为何会因此走到尽头,并进一步解释说这一技术是针对XAI(可解释AI)的,它的训练成本要高100-1000倍,回到“研究时代”并不意味着让事情变得更复杂。
▲外网评价(图源:X)
该模型目前受限于计算效率瓶颈,其运算速度较密集模型慢100至1000倍,将该技术直接应用于千亿参数级别的前沿大模型,现阶段尚不具备可行性。
开源地址:
Github:
https://github.com/openai/circuit_sparsity
Hugging Face:
https://huggingface.co/openai/circuit-sparsity
01***.***
训练稀疏Transformer
OpenAI理清模型内部计算
要理解这项研究的突破,首先需要明白传统大模型为何难以解释。
在标准的密集模型(Dense Models)中,神经网络存在一种被称为**“超级位置”(Superposition)**的现象。简单来说,为了存储海量的信息,模型被迫让单个神经元或权重矩阵同时编码多个完全不同的概念。
这种特征纠缠导致了严重的后果,例如模型的决策不可追溯和逻辑混乱,当模型输出一个结果时,我们无法确定是哪个具体的“概念”在起作用。
针对以上问题,以前的研究通常从试图拆解密集、纠结的网络开始。但OpenAI团队采取了一种“反直觉”的策略,即训练权重稀疏的Transformer模型,强制模型权重矩阵中**99.9%权重为零,仅保留0.1%**非零权重。
强制模型限制了模型只能使用其神经元之间极少的可能连接,而这一简单的更改,几乎从根本上理清了模型的内部计算。
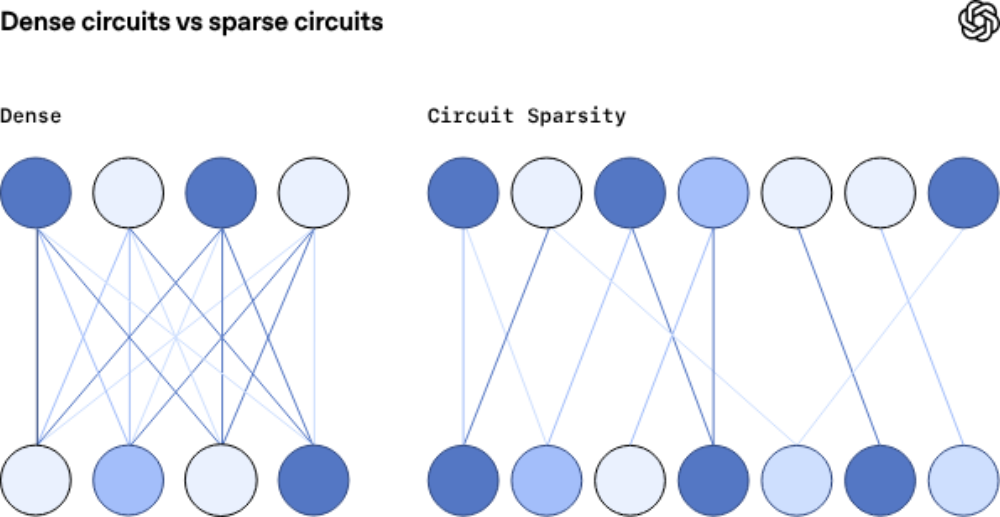
▲每个神经元只与下一个层的几个神经元相连(图源:OpenAI技术博客)
具体的技术手段包括:
**1、动态剪枝与稀疏约束:**在训练过程中,系统会动态执行“剪枝”操作,每一步优化后仅保留绝对值最大的权重(Top-K稀疏化)。
**2、激活稀疏化:**在残差流、注意力键/值矩阵等关键位置,研究团队引入了AbsTopK激活函数,强制仅保留前25%的激活值。
**3、架构微调:**为了配合稀疏化,研究团队用RMSNorm替代了传统的LayerNorm,避免归一化操作破坏稀疏性,同时引入了“Bigram表”来处理简单的模式匹配,从而释放模型的主干容量去处理复杂的逻辑推理。
02***.***
模型内部形成紧凑可读的“电路”
规模缩减16倍
这项技术的最大成果,是模型内部形成了紧凑且可读的**“电路”(Circuits)**。
在传统密集模型中,完成一个任务可能需要成千上万个节点协同工作,逻辑分散且难以捕捉。而在稀疏模型中,研究团队观察到了极简的计算路径:
1、极简的逻辑单元:例如在处理“字符串闭合”任务时,模型仅用12个节点就构建了一个完美的电路,清晰地展示了它是如何检测单引号或双引号是否闭合的。
**2、可读的特征:**神经元的激活变得具有明确的语义。研究人员发现了一些神经元专门负责检测“单引号”,另一些则像“计数器”一样精确地追踪列表的嵌套深度。
3、规模缩减16倍:对比实验显示,在相同的任务损失下,稀疏模型的电路规模比密集模型小了16倍。这意味着解读AI思维的难度降低了整整一个数量级。
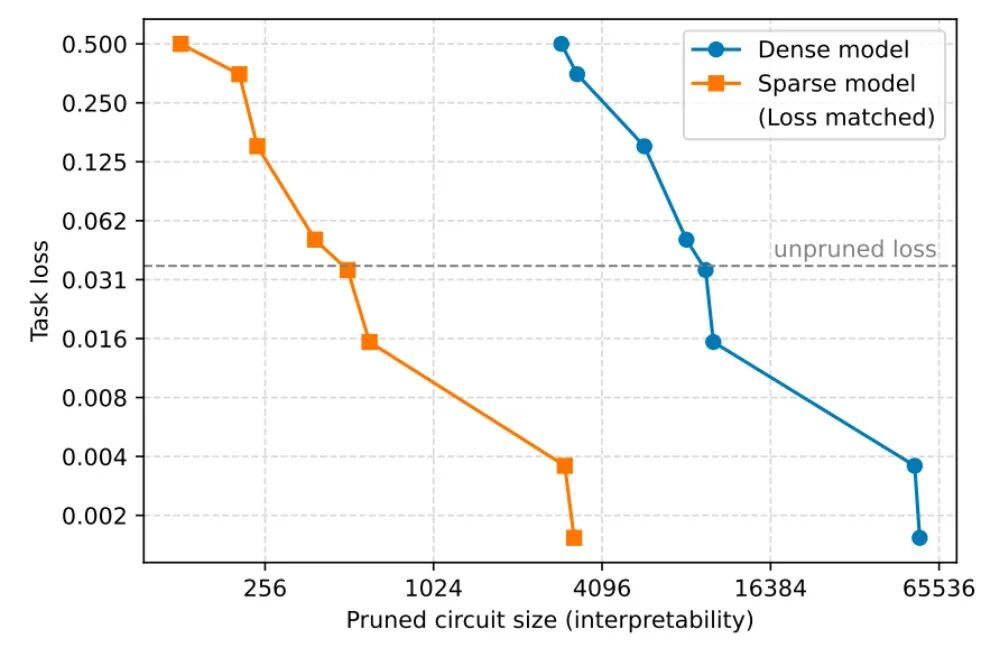
▲稀疏模型的电路规模比密集模型小了16倍(图源:OpenAI技术论文)
为了验证这些电路的真实性,团队进行了“均值消融”实验。结果证明,移除非电路节点对任务几乎没有影响,而一旦移除电路中的关键节点,模型性能就会瞬间崩塌。这证实了这些电路确实是模型执行任务的“必经之路”。
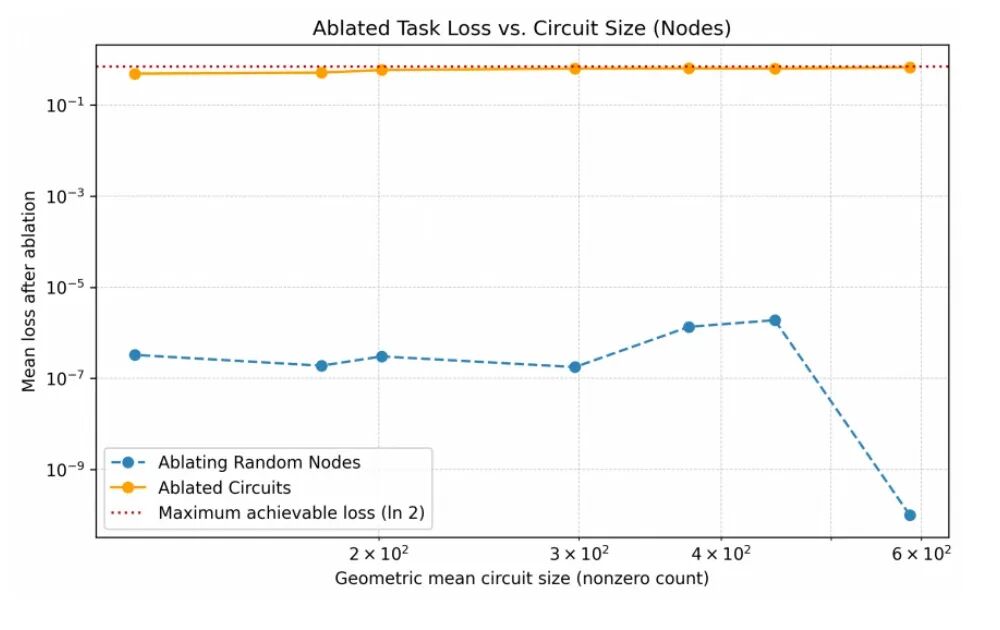
▲“均值消融”实验(图源:OpenAI技术论文)
03***.***
稀疏模型解读力强但速度慢千倍
OpenAI提出“桥梁网络”
为了测量稀疏模型计算的解耦程度。研究团队设计了一套简单的算法任务。对于每个模型,他们都将其剪裁成了仍能执行该任务的最小电路,并检查了该电路的简洁程度。
研究团队发现,用规模更大、稀疏度更高的模型进行训练后,就能够依托结构更简洁的电路,构建出性能更强的模型。
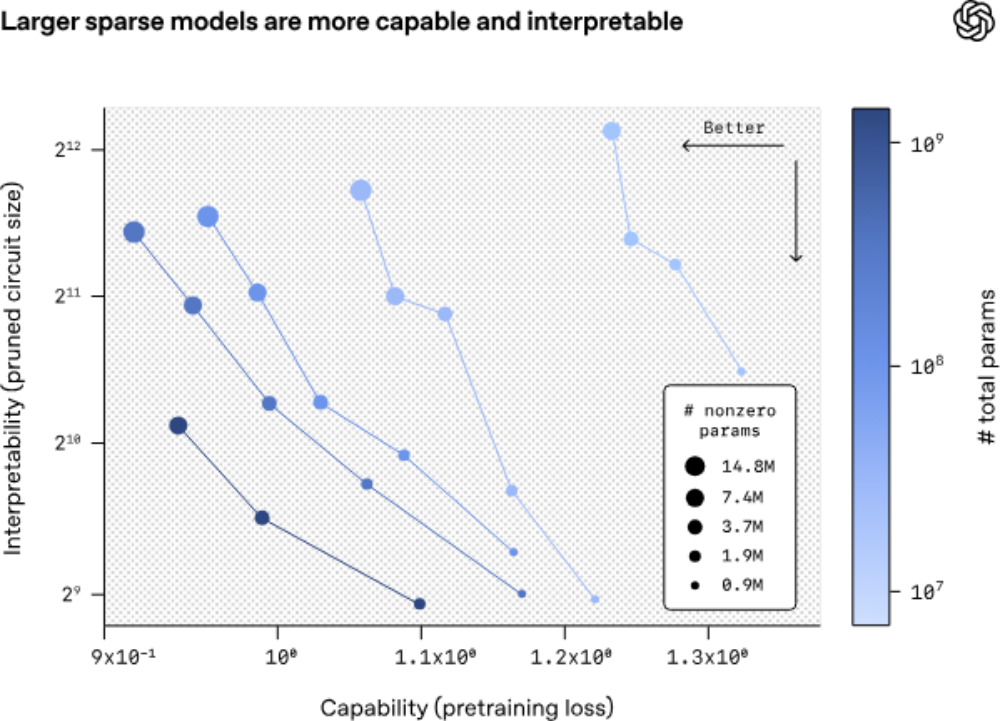
▲模型的可解释性与能力的对比图(图源:OpenAI技术博客)
从模型可解释性与性能的对比图可见,在稀疏模型规模固定的前提下,提升稀疏性,也就是将更多权重置零,虽会导致模型性能有所下降,但能显著增强其可解释性。
尽管稀疏模型在可解释性方面优势突出,但其应用目前受限于计算效率瓶颈:稀疏矩阵运算无法借助Tensor Cores实现加速,运算速度较密集模型慢100至1000倍。这意味着,将该技术直接应用于千亿参数级别的前沿大模型,现阶段尚不具备可行性。
为此,研究团队提出了“桥梁网络”(Bridges)方案:
1、编码-解码映射:在稀疏模型与预训练的密集模型之间插入一个编码器-解码器对。
2、跨模型干预:编码器将密集模型的激活映射到稀疏空间,解码器则反向转换。
“桥梁网络”(Bridges)方案可以在“透明”的稀疏模型上修改某个特征,然后通过桥梁将这种扰动映射回“黑箱”的密集模型,从而实现对现有大模型的可解释性行为编辑。
04***.***
结语:OpenAI提出稀疏化新路径
让大模型从“黑箱”走向“可解释”
OpenAI研究团队的这项研究,标志着AI可解释性领域的一项重要突破,也印证了理解AI并非遥不可及的目标。
研究团队在论文博客中称,这项工作是迈向更宏大目标的早期探索。接下来,他们计划将相关技术扩展至更大规模的模型,同时进一步解释更多模型的行为逻辑。
为解决稀疏模型训练效率低下的问题,团队提出了两个后续研究方向:一是从现有密集模型中提取稀疏电路,替代“从头训练稀疏模型”的传统方式;二是研发更高效的可解释性模型训练技术,推动相关技术更易落地生产。
“我们的目标是逐步扩大可可靠解释的模型范围,同时打造相关工具,让未来的AI系统更易于分析、调试与评估。”研究团队在论文博客中写道。
如何学习AI大模型?
如果你对AI大模型入门感兴趣,那么你需要的话可以点击这里大模型重磅福利:入门进阶全套104G学习资源包免费分享!
这份完整版的大模型 AI 学习和面试资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

这是一份大模型从零基础到进阶的学习路线大纲全览,小伙伴们记得点个收藏!

第一阶段: 从大模型系统设计入手,讲解大模型的主要方法;
第二阶段: 在通过大模型提示词工程从Prompts角度入手更好发挥模型的作用;
第三阶段: 大模型平台应用开发借助阿里云PAI平台构建电商领域虚拟试衣系统;
第四阶段: 大模型知识库应用开发以LangChain框架为例,构建物流行业咨询智能问答系统;
第五阶段: 大模型微调开发借助以大健康、新零售、新媒体领域构建适合当前领域大模型;
第六阶段: 以SD多模态大模型为主,搭建了文生图小程序案例;
第七阶段: 以大模型平台应用与开发为主,通过星火大模型,文心大模型等成熟大模型构建大模型行业应用。
100套AI大模型商业化落地方案

大模型全套视频教程

200本大模型PDF书籍

👉学会后的收获:👈
• 基于大模型全栈工程实现(前端、后端、产品经理、设计、数据分析等),通过这门课可获得不同能力;
• 能够利用大模型解决相关实际项目需求: 大数据时代,越来越多的企业和机构需要处理海量数据,利用大模型技术可以更好地处理这些数据,提高数据分析和决策的准确性。因此,掌握大模型应用开发技能,可以让程序员更好地应对实际项目需求;
• 基于大模型和企业数据AI应用开发,实现大模型理论、掌握GPU算力、硬件、LangChain开发框架和项目实战技能, 学会Fine-tuning垂直训练大模型(数据准备、数据蒸馏、大模型部署)一站式掌握;
• 能够完成时下热门大模型垂直领域模型训练能力,提高程序员的编码能力: 大模型应用开发需要掌握机器学习算法、深度学习框架等技术,这些技术的掌握可以提高程序员的编码能力和分析能力,让程序员更加熟练地编写高质量的代码。
LLM面试题合集

大模型产品经理资源合集

大模型项目实战合集

👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









