



前言
开始
│
├─ 数据准备阶段
│ ├─ 加载四个航空发动机数据集(FD001-FD004)
│ ├─ 数据预处理与增强
│ └─ 划分训练集、验证集和测试集
│├─ 模型构建阶段
│ ├─ 创建时间维度分支
│ │ ├─ 添加位置编码
│ │ ├─ 卷积层提取局部特征
│ │ ├─ 多头自注意力机制捕捉长期依赖
│ │ └─ 残差连接与层归一化
│ ││ ├─ 创建传感器维度分支
│ │ ├─ 维度置换与位置编码
│ │ ├─ 卷积层提取特征间关系
│ │ ├─ 多头自注意力机制
│ │ └─ 残差连接与层归一化
│ ││ ├─ 跨域注意力机制
│ │ ├─ 时间到传感器的注意力
│ │ └─ 传感器到时间的注意力
│ ││ ├─ 全局池化与特征融合
│ └─ 全连接预测层
│├─ 模型训练阶段
│ ├─ 五折分层交叉验证
│ ├─ 早停与学习率调整
│ └─ 全数据最终训练
│├─ 模型评估阶段
│ ├─ 计算RMSE指标
│ ├─ 计算PHM指标
│ └─ 生成预测结果可视化
│└─ 结束
算法步骤:
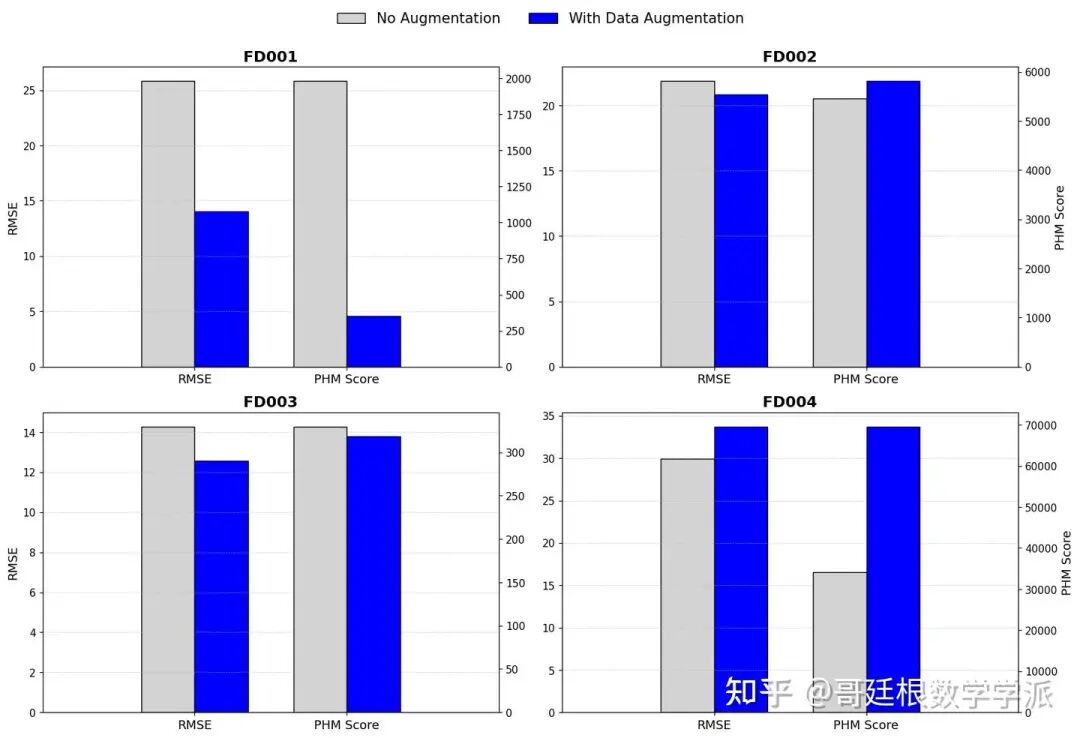
- 数据准备与预处理:加载四个航空发动机退化数据集,对数据进行标准化处理,应用数据增强技术扩充训练样本,限制剩余使用寿命最大值为130,创建滑动窗口样本。
- 模型构建:设计双分支变换器架构,时间分支处理序列数据并捕捉时间依赖性,传感器分支分析不同测量指标间的相关性,两个分支通过跨域注意力机制相互交换信息。
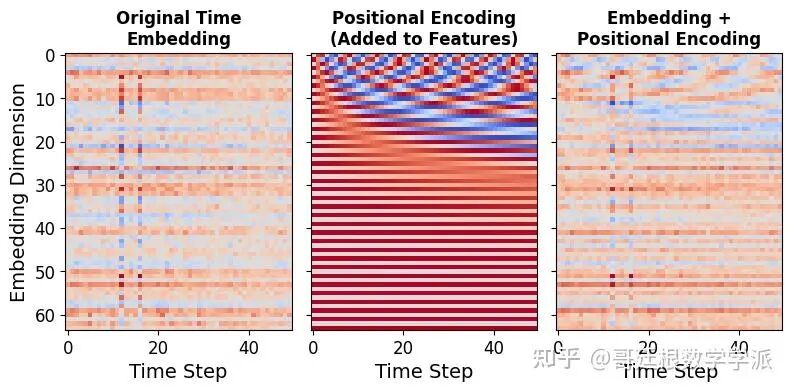
- 位置编码:为时间分支和传感器分支分别生成正弦余弦位置编码,帮助模型理解序列中元素的位置关系。
- 特征提取:使用一维卷积层提取局部特征模式,应用多头自注意力机制捕捉长距离依赖关系。
- 残差连接:在每个主要组件后添加残差连接,确保梯度流畅传播,缓解深层网络训练难题。
- 特征融合:通过全局平均池化和最大池化操作汇总两个分支的特征表示,拼接形成综合特征向量。
- 预测输出:经过多个全连接层进行最终预测,使用Dropout和批归一化提高模型泛化能力。
- 模型训练:采用五折分层交叉验证策略,使用早停机制防止过拟合,动态调整学习率优化训练过程。
- 性能评估:在测试集上计算均方根误差和PHM分数两种评估指标,PHM分数特别加强对过高预测的惩罚。
- 结果可视化:生成训练过程损失曲线和预测值与真实值对比散点图,直观展示模型性能。
import os
import json
import time
import copy
import pickle
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import gc
from scipy.interpolate import interp1d
from scipy.stats import pearsonr
from sklearn.cluster import KMeans
from sklearn.feature_selection import VarianceThreshold
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import StratifiedKFold
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
from tensorflow.keras.metrics import RootMeanSquaredError
from tensorflow.keras import backend as K
# 定义数据集名称列表
dataset_names = ["FD001", "FD002", "FD003", "FD004"]
# 设置文件路径
main_path = ''
file_path = f'{main_path}tensors/'
save_dir = f'{main_path}results/'
# 创建必要的目录
os.makedirs(file_path, exist_ok=True)
os.makedirs(save_dir, exist_ok=True)
# 定义训练参数
batch_size = 32 # 批量大小
n_epochs = 100 # 训练轮数
def get_positional_encoding(seq_len, d_model):
"""
生成位置编码矩阵
参数:
seq_len: 序列长度
d_model: 嵌入维度
返回:
位置编码矩阵,形状为(1, seq_len, d_model)
"""
# 初始化位置编码矩阵
position_enc = np.zeros((1, seq_len, d_model))
# 计算每个位置和每个维度的位置编码
for pos in range(seq_len):
for i in range(d_model):
if i % 2 == 0: # 偶数维度使用正弦函数
position_enc[0, pos, i] = np.sin(pos / (10000 ** (i / d_model)))
else: # 奇数维度使用余弦函数
position_enc[0, pos, i] = np.cos(pos / (10000 ** ((i - 1) / d_model)))
return tf.cast(position_enc, dtype=tf.float32)
def residual_connection(x, residual):
"""
实现残差连接
参数:
x: 主路径的输出
residual: 残差路径的输出
返回:
两个张量的和,如果维度不匹配则先进行线性变换
"""
if x.shape[-1] != residual.shape[-1]:
residual = layers.Dense(x.shape[-1])(residual)
return layers.Add()([x, residual])
def build_enhanced_dast_model(input_shape):
"""
构建增强的双注意力时空变换器模型
参数:
input_shape: 输入数据的形状(时间步数, 特征数)
返回:
编译好的Keras模型
"""
time_steps, num_features = input_shape
inputs = keras.Input(shape=input_shape)
# 时间维度分支
# 位置编码
time_embed = layers.Conv1D(filters=64, kernel_size=1, padding='same')(inputs)
pos_encoding = get_positional_encoding(time_steps, 64)
time_embed_with_pos = layers.Add()([time_embed, pos_encoding])
time_embed_with_pos = layers.Activation('relu')(time_embed_with_pos)
# 卷积块
time_conv = layers.Conv1D(filters=64, kernel_size=3, padding='same', activation='relu')(time_embed_with_pos)
time_branch = layers.Dense(64, activation='relu')(time_conv)
# 第一个注意力块
time_att_input = time_branch
time_att = layers.MultiHeadAttention(key_dim=16, num_heads=4, dropout=0.1)(time_branch, time_branch)
time_branch = layers.LayerNormalization(epsilon=1e-6)(residual_connection(time_att, time_att_input))
# 第二个注意力块
time_att_input2 = time_branch
time_att2 = layers.MultiHeadAttention(key_dim=16, num_heads=4, dropout=0.1)(time_branch, time_branch)
time_branch = layers.LayerNormalization(epsilon=1e-6)(residual_connection(time_att2, time_att_input2))
# 全连接块
time_ffn_input = time_branch
time_ffn = layers.Dense(128, activation="relu")(time_branch)
time_ffn = layers.Dropout(0.1)(time_ffn)
time_ffn = layers.Dense(64)(time_ffn)
time_branch = layers.LayerNormalization(epsilon=1e-6)(residual_connection(time_ffn, time_ffn_input))
# 传感器维度分支
sensor_branch = layers.Permute((2, 1))(inputs) # 交换时间维度和特征维度
# 位置编码
sensor_embed = layers.Conv1D(filters=64, kernel_size=1, padding='same')(sensor_branch)
sensor_pos_encoding = get_positional_encoding(num_features, 64)
sensor_embed_with_pos = layers.Add()([sensor_embed, sensor_pos_encoding])
sensor_embed_with_pos = layers.Activation('relu')(sensor_embed_with_pos)
# 卷积块
sensor_conv = layers.Conv1D(filters=64, kernel_size=3, padding='same', activation='relu')(sensor_embed_with_pos)
sensor_branch = layers.Dense(64, activation='relu')(sensor_conv)
# 第一个注意力块
sensor_att_input = sensor_branch
sensor_att = layers.MultiHeadAttention(key_dim=16, num_heads=4, dropout=0.1)(sensor_branch, sensor_branch)
sensor_branch = layers.LayerNormalization(epsilon=1e-6)(residual_connection(sensor_att, sensor_att_input))
# 第二个注意力块
sensor_att_input2 = sensor_branch
sensor_att2 = layers.MultiHeadAttention(key_dim=16, num_heads=4, dropout=0.1)(sensor_branch, sensor_branch)
sensor_branch = layers.LayerNormalization(epsilon=1e-6)(residual_connection(sensor_att2, sensor_att_input2))
# 全连接块
sensor_ffn_input = sensor_branch
sensor_ffn = layers.Dense(128, activation="relu")(sensor_branch)
sensor_ffn = layers.Dropout(0.1)(sensor_ffn)
sensor_ffn = layers.Dense(64)(sensor_ffn)
sensor_branch = layers.LayerNormalization(epsilon=1e-6)(residual_connection(sensor_ffn, sensor_ffn_input))
# 跨域注意力机制
# 时间分支到传感器分支的注意力
time_to_sensor_input = time_branch
time_to_sensor = layers.MultiHeadAttention(key_dim=16, num_heads=4, dropout=0.1)(
query=time_branch,
key=sensor_branch,
value=sensor_branch
)
time_branch = layers.LayerNormalization(epsilon=1e-6)(residual_connection(time_to_sensor, time_to_sensor_input))
# 传感器分支到时间分支的注意力
sensor_to_time_input = sensor_branch
sensor_to_time = layers.MultiHeadAttention(key_dim=16, num_heads=4, dropout=0.1)(
query=sensor_branch,
key=time_branch,
value=time_branch
)
sensor_branch = layers.LayerNormalization(epsilon=1e-6)(residual_connection(sensor_to_time, sensor_to_time_input))
# 全局池化和特征融合
time_avg = layers.GlobalAveragePooling1D()(time_branch)
time_max = layers.GlobalMaxPooling1D()(time_branch)
sensor_avg = layers.GlobalAveragePooling1D()(sensor_branch)
sensor_max = layers.GlobalMaxPooling1D()(sensor_branch)
combined = layers.Concatenate()([time_avg, time_max, sensor_avg, sensor_max])
# 预测块
x = layers.Dense(128, activation="relu")(combined)
x = layers.BatchNormalization()(x)
x = layers.Dropout(0.4)(x)
x = layers.Dense(64, activation="relu")(x)
x = layers.BatchNormalization()(x)
x = layers.Dropout(0.3)(x)
outputs = layers.Dense(1)(x) # 输出层,预测RUL值
model = keras.Model(inputs, outputs)
return model
def compile_and_train(model, X_train, y_train, X_val, y_val, save_dir, name="unknown", loss='mse'):
"""
编译和训练模型
参数:
model: 要训练的模型
X_train: 训练数据
y_train: 训练标签
X_val: 验证数据
y_val: 验证标签
save_dir: 保存结果的目录
name: 模型名称
loss: 损失函数类型
返回:
训练历史记录
"""
# 编译模型
model.compile(
optimizer='adam',
loss=[loss],
metrics=[RootMeanSquaredError(name='rmse'), None]
)
# 定义回调函数
es = keras.callbacks.EarlyStopping(monitor='val_loss', patience=10, min_delta=0.0001, restore_best_weights=True)
lr = keras.callbacks.ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=5, min_lr=1e-6, verbose=1)
# 训练模型
history = model.fit(
X_train, y_train,
validation_data=(X_val, y_val),
epochs=n_epochs,
batch_size=batch_size,
callbacks=[es, lr]
)
# 绘制训练和验证RMSE曲线
plt.figure(figsize=(10, 10))
plt.plot(history.history['rmse'])
plt.plot(history.history['val_rmse'])
plt.xlabel('Epoch')
plt.ylabel('RMSE')
plt.legend(['Train', 'Validation'])
plt.title(f'RUL Prediction Loss (RMSE) - {name}')
plt.savefig(f'{save_dir}/rul_rmse_plot_{name}.png')
plt.show()
return history
def rmse(y_true, y_pred):
"""计算均方根误差"""
return np.sqrt(np.mean(np.square(y_true - y_pred)))
def phm_score(y_true, y_pred):
"""
计算PHM分数( Prognostics and Health Management Score)
参数:
y_true: 真实RUL值
y_pred: 预测RUL值
返回:
PHM分数,对高估RUL的惩罚更大
"""
scores = []
for true, pred in zip(y_true, y_pred):
if pred > true: # 高估RUL
score = np.exp(np.abs(pred - true) / 13) - 1
else: # 低估RUL
score = np.exp(np.abs(pred - true) / 10) - 1
scores.append(score)
return np.sum(scores)
def evaluate_model(model, test_data, save_dir, name="unknown"):
"""
评估模型性能
参数:
model: 要评估的模型
test_data: 测试数据
save_dir: 保存结果的目录
name: 模型名称
返回:
RMSE分数和PHM分数
"""
X_test = test_data['X_test']
y_test = test_data['y_test']
# 预测RUL值
y_pred = model.predict(X_test).flatten()
# 计算评估指标
rmse_score = rmse(y_test, y_pred)
phm = phm_score(y_test, y_pred)
print(f"RMSE: {rmse_score:.2f}")
print(f"PHM Score: {phm:.2f}")
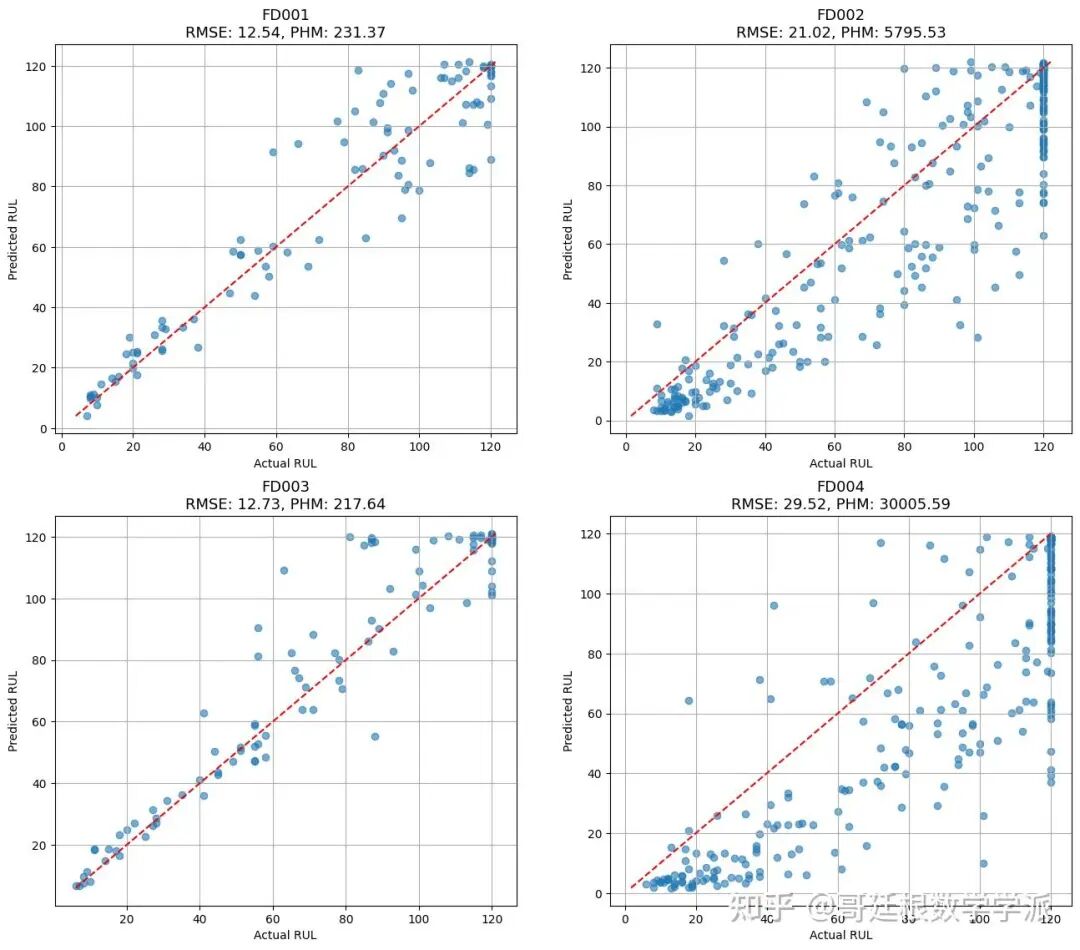
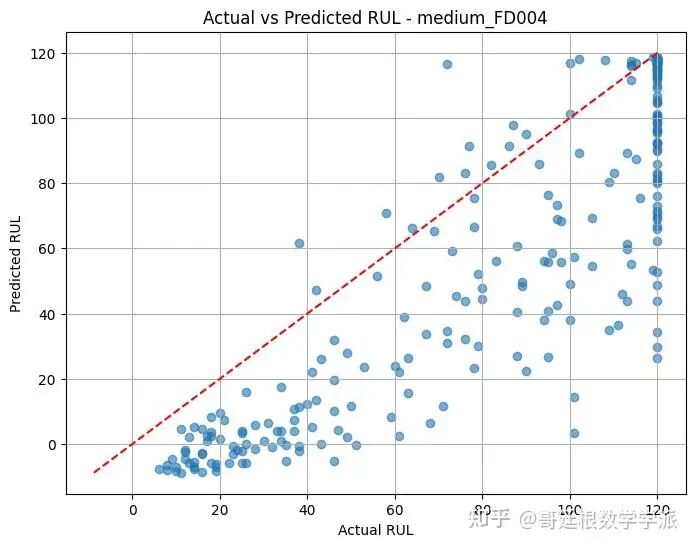
# 绘制实际值与预测值的散点图
plt.figure(figsize=(8,6))
plt.scatter(y_test, y_pred, alpha=0.6)
mn, mx = min(y_test.min(), y_pred.min()), max(y_test.max(), y_pred.max())
plt.plot([mn, mx], [mn, mx], 'r--') # 绘制理想预测线
plt.xlabel('Actual RUL')
plt.ylabel('Predicted RUL')
plt.grid(True)
plt.title(f'Actual vs Predicted RUL - {name}')
plt.savefig(f'{save_dir}/Actual_vs_pred_RUL{name}.png')
plt.show()
return rmse_score, phm
def pipeline(dataset_names, base_path, loss='mse', n_splits=5):
"""
完整的训练和评估流程
参数:
dataset_names: 数据集名称列表
base_path: 数据文件基础路径
loss: 损失函数类型
n_splits: 交叉验证折数
返回:
包含所有数据集结果的字典
"""
results = {}
for name in dataset_names:
# 加载数据
X = np.load(f'{base_path}/{name}_X_augmented.npy')
y = np.load(f'{base_path}/{name}_y_augmented.npy')
test_data = np.load(f'{base_path}/{name}_test_windows.npz')
# 将RUL值限制在130以内
y[y >= 130] = 130
# 交叉验证
cv_scores = []
kfold = StratifiedKFold(n_splits=n_splits, shuffle=True, random_state=42)
y_bins = np.floor(y / 10).astype(int) # 将RUL值分箱用于分层抽样
for train_idx, val_idx in kfold.split(X, y_bins):
X_train, X_val = X[train_idx], X[val_idx]
y_train, y_val = y[train_idx], y[val_idx]
# 构建和训练模型
input_shape = X_train.shape[1:]
model = build_enhanced_dast_model(input_shape)
history = compile_and_train(model, X_train, y_train, X_val, y_val, name=name, save_dir=save_dir, loss=loss)
# 评估模型
y_val_pred = model.predict(X_val).flatten()
fold_rmse = rmse(y_val, y_val_pred)
cv_scores.append(fold_rmse)
# 清理内存
del model
K.clear_session()
gc.collect()
# 计算交叉验证平均RMSE
avg_cv_rmse = np.mean(cv_scores)
# 在整个数据集上训练最终模型
input_shape = X.shape[1:]
final_model = build_enhanced_dast_model(input_shape)
history = compile_and_train(final_model, X, y, X, y, name=name, save_dir=save_dir, loss=loss)
# 在测试集上评估最终模型
y_test = test_data['y_test']
X_test = test_data['X_test']
y_pred = final_model.predict(X_test).flatten()
final_rmse = rmse(y_test, y_pred)
final_phm = phm_score(y_test, y_pred)
# 保存结果
results[name] = {
'CV_RMSE': avg_cv_rmse,
'Final_RMSE': final_rmse,
'PHM': final_phm,
'actual': y_test,
'final_preds': y_pred
}
# 清理内存
del final_model
K.clear_session()
gc.collect()
return results
# 运行完整流程
dataset_names = ["FD001", "FD002", "FD003", "FD004"]
results_pipeline = pipeline(dataset_names, f"{file_path}transformer/", loss='mse')
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









