 vLLM推理引擎架构深度解析
vLLM推理引擎架构深度解析




前言
vLLM Offcie Hours #32 又披露了一批新技术。其中有两个比较特殊,它们不是新技术,而是协助用户更好的理解 vLLM 项目。一个是 vLLM Recipes ,用来分享 vLLM 启动及使用的最佳实践。而另一个是 《Inside vLLM: Anatomy of a High-Throughput LLM Inference System》,这个篇 Blog 可以帮助大家快速深入了解 vLLM 内部构造。今天就给大家深度拆解以下这个剖析这篇 Blog 。这个 Blog 很长,涉及的内容很多,我会分几篇文章来慢慢解读这篇Blog 的技术要点,并且补充一部分基础信息,以便大家深入理解 vLLM 的构成原理。
今天是第一篇,先给大家剖析整体架构。
https://blog.vllm.ai/2025/09/05/anatomy-of-vllm.html
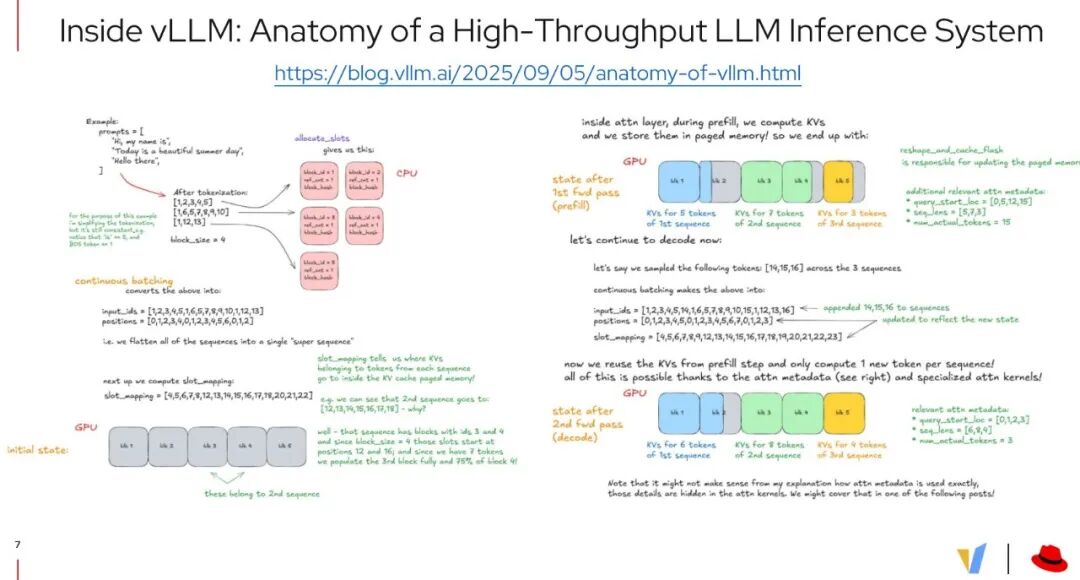
一行代码背后的"超速引擎"
我们从最简单的 LLM 执行代码开始,来了解 vLLM 究竟是如何运作的:
from vllm import LLM, SamplingParams
prompts = [ "Hello, my name is", "The president of the United States is",]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
def main(): llm = LLM(model="TinyLlama/TinyLlama-1.1B-Chat-v1.0") outputs = llm.generate(prompts, sampling_params)
if __name__ == "__main__": main()
这段代码非常容易理解。它是标准加载、执行 AI 模型的过程。其中的 LLM engine 对象是 vLLM 的基础构建模块。它本身已经支持高吞吐量推理(包括基于 PageAttention 的模型推理执行逻辑),但仅限于离线设置。目前还无法通过 Web 将其提供给客户。
这里需要用到两个环境变量:
VLLM_USE_V1=”1” # 使用 V1 引擎
VLLM_ENABLE_V1_MULTIPROCESSING=”0” # 使用单进程
基于当前配置 vLLM 的运行是:
- 离线的(无需 Web/分布式系统搭建)
- 同步阻塞执行的(所有执行均在单个阻塞进程中进行)
- 单 GPU 的(无数据/模型/流水线/专家并行;DP/TP/PP/EP = 1)
- 使用标准 Transformer 架构的模型(支持像 Jamba 这样的混合模型需要更复杂的混合键值缓存内存分配器)
从这里开始,我们将逐步理解 vLLM 项目的意义:
从最简单的角度理解。vLLM 项目的目标就是基于这个基础的,已经优化过的 LLM 执行模块,扩展构建出一套可以在线的(这样用起来会更方便,更灵活)、异步的(可以更好的支持企业级并发)、支持多 GPU 的(多个GPU,多种GPU,分布式GPU,分拆GPU等等)、多节点的推理系统。但不论如何加工这个框架,它的本质始终是提供服务于标准 Transformer 架构的模型推理运行环境。
宏观的四大核心组件
先从解读 vLLM 核心引擎的整体架构图开始:
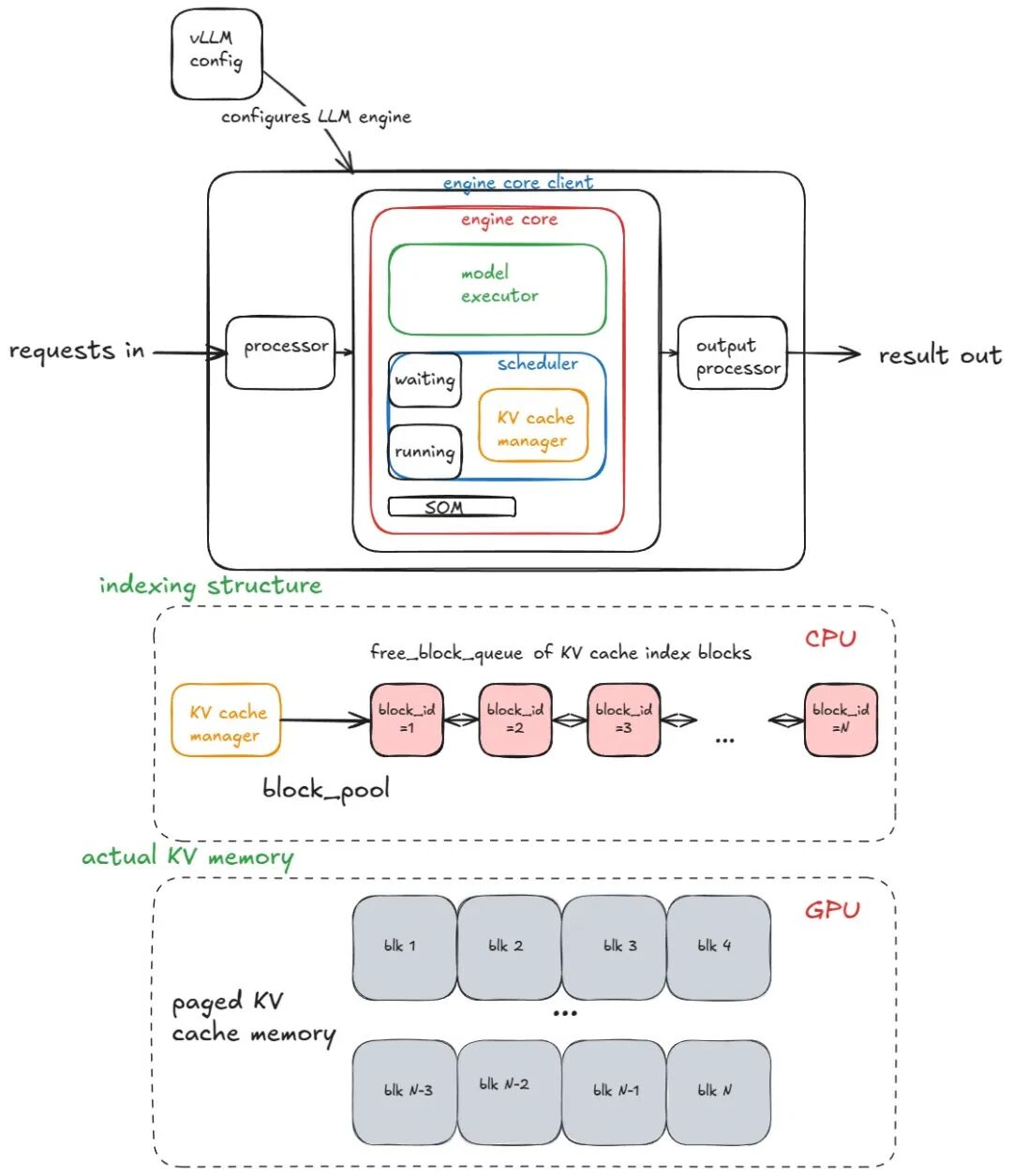
vLLM引擎的核心是一套清晰且合理的基础框架:
1 配置总开关:掌控全局参数。
vLLM config:配置 LLM 引擎的核心参数(如模型路径、缓存大小、并行策略等)。
2 请求翻译官:把各种格式的输入统一成引擎能理解的语言。
processor:预处理输入请求,将请求转化为 EngineCoreRequests 对象。先 “验证”validation 输入格式合法性,再通过 “词元化”tokenization 将文本转为模型可理解的词元序列,最后经 “处理”processing 封装为引擎能识别的 EngineCoreRequests
3 核心联络员:确保各个模块无缝对接。
engine core client:引擎核心客户端作为 “客户端”,是外部请求与「引擎核心」交互的入口。

4 输出美化师:把原始计算结果包装成人类友好的格式
output processor:将原始输出 EngineCoreOutputs 对象转化为标准输出对象RequestOutput 成为用户最终看到的样子。
换一个角度来看,它也可以理解为下图这样一个分层框架,这个框架正式 Red Hat 在 AI Inference Server 文档中给出的容器内执行逻辑架构图。从这个角度也可以将上面那个比较复杂的逻辑图理解为简单的两个进程,在调用 vLLM 框架过程中 EngineCoreRequests -> EngineCore -> RequestsOutput 之间的逻辑关系。
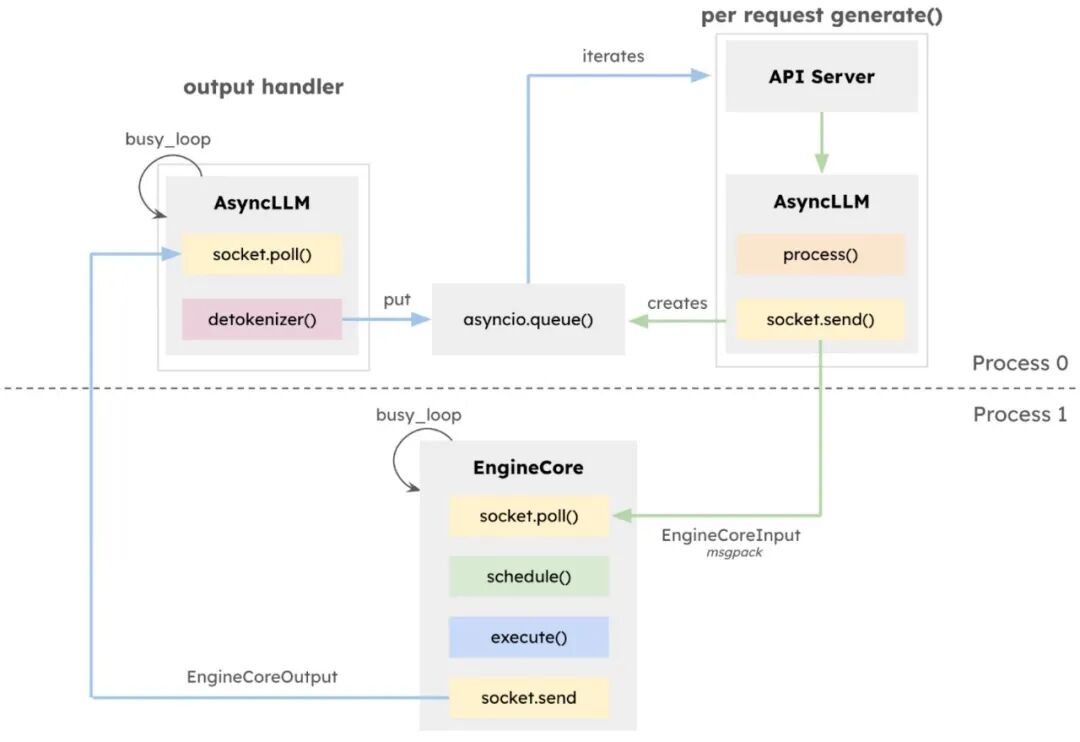
从整体框架来看,vLLM 是一个完美的可阔拓展基础架构!它更倾向于基于相对完整的 IT 基础架构来实现一个全角度可拓展的 AI 模型推理服务框架。对于可预期的 AI 模型推理技术发展都提供了可扩展的模块或接口。这使得 vLLM 社区项目非常适合与现有最新技术快速融合,高效协调。例如快速将最新的矩阵乘法的进化,分布式执行的进化,模型内部结构的进化等等开源项目快速整合至 vLLM 生态之中。加之 Red Hat 软件会通过 AI Inference Server 这样的企业级产品对这个开源技术提供企业级执行能力的服务支撑,进而在企业级应用的角度不断反馈社区,将更成熟、稳定的技术回补进社区项目的未来发展之中。这种开源协作精神吸引了国内外众多 AI 领域的顶尖企业。 这一切因素都促使它成为目前开源领域最火热的推理服务社区项目。
核心的“核心引擎” engine core
剥开 vLLM 的外壳,我们可以再深入分析引擎核心的 engine core(引擎核心):
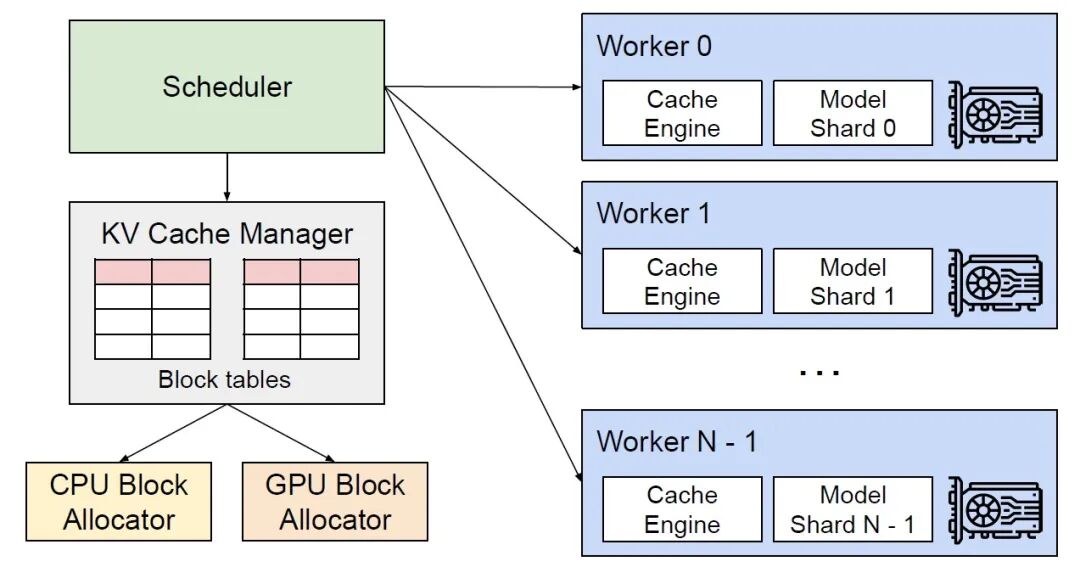
从前面介绍的总体架构图我们可以看到,engine core(引擎核心)模块负责处理推理的核心逻辑。它包含许多子模块。为了更易于了解,我们先从最重要的三个模块入手来理解这个 core :
model executor 模型执行器:
执行 LLM 模型的前向传播,生成 token。(我们目前使用的是 UniProcExecutor,它在单个 GPU 上只有一个 Worker 进程)。我们将逐步构建支持多 GPU 的 MultiProcExecutor。
scheduler 执行调度器:
管理请求的 “等待队列(waiting)” 和 “运行队列(running)”,决定哪些请求优先被调度执行。(决定哪些请求进入下一个引擎步骤)- 它进一步包含:
- 策略设置 - 可以是 FCFS(first come first served 先到先得)或 priority 优先级(高优先级请求优先处理) 等待队列和运行队列
- 维护 waiting 和 running 队列
- KV 缓存管理器 - 它是分页注意力机制的核心。
KV 缓存管理器维护一个 free_block_queue - 一个可用的 KV 缓存块池(通常数量级为数十万,具体取决于 VRAM 大小和块大小)。在分页注意力机制期间,这些块充当索引结构,会将 token 映射到其计算的 KV 缓存块上。
SOM(Structured Output Manager)结构化输出管理器:
处理 “结构化输出约束”(如引导解码、语法限制生成等)。
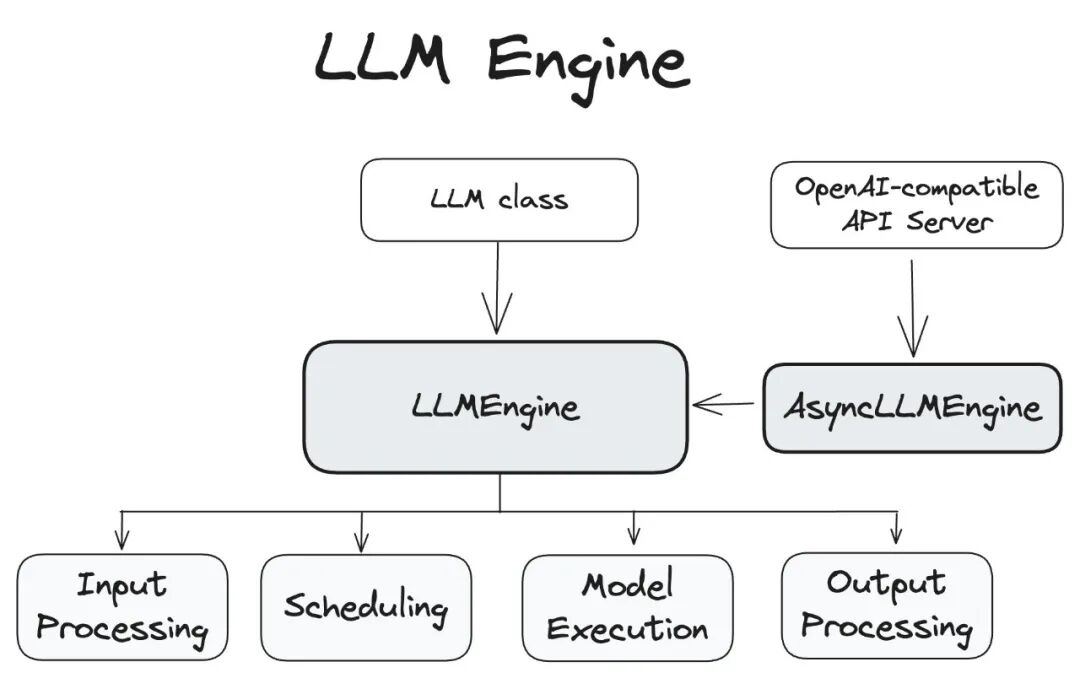
初始化背后的秘密操作
vLLM 执行推理任务之所以更加高效,是因为从启动开始已经就为整体执行构建了一个高效的处理架构。vLLM在启动时悄悄做了三件大事:
第一步:初始化设备
1 首先为工作器分配一个 CUDA 设备(例如“cuda:0” ,这个设备名来自NVIDIA-Container-Toolkit,想了解如何用可以查看之前的文章。),并检查模型数据类型是否受支持。(例如 FP8 或 FP4 等,这取决于所用 GPU 。vLLM 通过 Marlin 内核调度底层矩阵计算加速。以 NVIDIA 为例,当 NVIDIA GPU 计算能力大于 8.0 时,就可以启用 Marlin 内核实现混合精度自回归线性计算。而在支持 CUTLASS 的设备上就会自动调度 NVIDIA 的硬件加速能力,从而加速矩阵运算。因此 vLLM 帮助用户解决了不同时代硬件设备的自适应支持能力)
2 根据请求的 gpu_memory_utilization(例如 0.8 → 总 VRAM 的 80%),验证是否有足够的 VRAM。
3 根据设置来执行分布式设置(。DP / TP / PP / EP 等,后面我们解析D/P分离与分布式执行的时候再详细解释这些并行的基础原理)
4 实例化 model_runner 对象。(包含采样器sampler、Key/Value 缓存KV cache和前向传播缓冲区 forward-pass buffers,例如 input_id、positions 等)
5 实例化 InputBatch 对象。(控制一个 CPU 端前向传播缓冲区(forward-pass buffers)、生成用于 KV 缓存索引的块表(block tables)、控制采样元数据(sampling metadata)等)
第二步:加载模型
1 实例化模型架构
2 加载模型权重
3 调用 model.eval()(PyTorch 的推理模式)
4 可选步骤:在模型上调用 torch.compile()
对于 vLLM 来说,model.eval() 是推理前的必要步骤,目的是消除训练机制对推理结果的影响,确保生成的 token 序列可复现且符合预期。而 torch.compile() 则是可选的性能优化步骤,它不改变模型的功能(推理模式已由 model.eval() 确保),但能显著降低推理 latency 并提升吞吐量。torch.compile()``可以协助 vLLM 实现:
- 算子融合:将多个连续的小算子(如激活函数、矩阵乘法)合并为一个大算子,减少 kernel 启动次数和内存访问开销。
- 常量折叠:提前计算推理过程中不变的常量(如固定的位置编码),避免重复计算。
- 动态控制流优化:对条件分支、循环等逻辑进行静态分析,生成更高效的执行路径(尤其适合 Transformer 中的注意力掩码等逻辑)。
- 硬件适配优化:针对特定 GPU 架构(如 Ampere、Hopper)生成专用指令,最大化利用硬件算力(如 Tensor Core)。
动态控制流优化可参考论文: https://arxiv.org/pdf/2305.10611
第三步:初始化 KV 缓存
- 获取每层 KV 缓存规范。传统 Transformer 一直使用
FullAttentionSpec(同构 Transformer)规范,但对于混合架构模型(如滑动窗口注意力模型、Transformer 与 SSM 结合的 Jamba 模型等),它会变得更加复杂。
- 传统 Transformer 是 “同构的”(homogeneous),所有注意力层均采用 “全注意力”(FullAttention),即每个 token 需与序列中所有其他 token 交互,因此 KV 缓存规格统一(FullAttentionSpec),每层的 KV 缓存大小仅由序列长度、头数、头维度决定。
- 但混合架构模型会导致每层的 KV 缓存规格不一致(如滑动窗口层仅需缓存最近 N 个 token 的 KV,而非全部)。这种复杂性需要参考 Jenga 等技术来动态适配每层的缓存需求。
- 通过一次 “虚拟前向传播”(dummy pass)或性能分析(profiling),获取 GPU 内存快照,计算可用显存(VRAM)能容纳多少个 KV 缓存块。
- 虚拟前向传播:用一个小批量输入跑一次推理,不产生实际输出,但触发模型各层的 KV 缓存分配逻辑,从而获取每层 KV 缓存的实际内存占用。
- KV 缓存块(blocks):vLLM 采用 “分页式注意力”(PagedAttention),将 KV 缓存分割为固定大小的块(类似操作系统内存分页),便于动态管理(如复用、回收)。
- 目的:根据可用 VRAM 大小,确定最大可缓存的 KV 块数量,避免显存溢出,同时为后续动态调度(如请求批处理时的缓存分配)提供依据。
- 分配/塑性/分类(Allocate, reshape and bind) KV 缓存张量,根据每个 层的规格重塑其形状,并将其绑定到对应的注意力层(attention layers )。
- 分配(Allocate):根据上一面虚拟前传或性能分析所计算的最大块数量,在 GPU 显存中预留连续或离散的内存区域作为 KV 缓存。
- 重塑(Reshape):由于不同层的 KV 缓存规格可能不同(如混合模型中滑动窗口层与全注意力层的缓存维度不同),需按每层需求调整张量形状(如序列长度维度、头数维度)。
- 绑定(Bind):将分配好的 KV 缓存与对应注意力层关联,确保层在推理时能直接访问到自己的缓存(而非每次重新计算),这是实现高效自回归生成的基础。
- 准备注意力机制的元数据(attention metadata),供前向传播时的 GPU 内核(kernels)使用。
- 元数据(metadata):包括注意力类型(全注意力 / 滑动窗口)、头数、头维度、是否启用稀疏性、计算后端(如 FlashAttention、Marlin 等)等配置信息。
- 后端选择:例如指定 FlashAttention 作为后端,可调用其优化的 GPU 内核加速注意力计算(通过算子融合、显存高效访问等降低延迟)。
- 作用:元数据是连接高层模型配置与底层 GPU 计算的 “桥梁”,确保内核在执行时能适配具体的注意力逻辑,避免冗余判断或错误计算。
- 除非启用 --enforce-eager(强制即时执行),否则会对每个预热批次大小进行虚拟运行,并捕获 CUDA 图(这里以 NVIDIA GPU 为例,如使用 AMD GPU 则使用 HIP graphs)。CUDA 图将 GPU 操作序列记录为有向无环图(DAG),后续推理时直接重放这些预记录的图,减少内核启动开销,从而降低延迟。
- CUDA 图(CUDA graphs):GPU 内核启动本身存在开销(如 CPU-GPU 通信、参数解析等),对于重复的计算模式(如固定批次大小的推理),可将整个 GPU 操作序列(如注意力计算、激活函数、采样等)记录为一个 “图”,后续直接重放图即可,无需重复启动内核。
- 预热(warmup):对不同批次大小(batch sizes)进行虚拟运行并捕获图,确保在实际推理时,无论输入批次多大,都有对应的预优化图可用。
- –enforce-eager:禁用 CUDA 图,强制 GPU 操作即时执行(eager execution),通常用于调试(避免图捕获的复杂性),但会牺牲性能。
整体逻辑:从适配模型到优化执行的全流程
这些步骤是 vLLM 等框架实现高性能推理的核心链路:
- 适配模型多样性:通过获取每层 KV 缓存规格,支持传统 Transformer 或混合架构模型,或未来某种更新技术的模型;
- 高效显存利用:通过虚拟前向传播计算缓存容量,结合分页管理实现 KV 缓存的动态分配;
- 绑定资源与配置:将缓存与层绑定,并准备元数据,确保计算逻辑与硬件最佳适配。同时也确保不同种类或品牌的硬件在这一过程中都可以被最优资源适配;
- 降低执行开销:通过 CUDA 图捕获与重放,减少内核启动延迟,最终实现高吞吐量与低延迟的推理。
这一流程体现了 “软件 - 硬件协同优化” 的思路:既考虑模型架构的多样性,又深度利用不同 GPU 硬件各自的优化特性(如 CUDA 图、张量核),是大模型推理框架高性能的关键所在。
从上述步骤中,我们可以看到,虽然总体来说是三个步骤,其实 vLLM 内部做了很多事情,每个动作都基于并不是非常难以理解 IT 技术,且进行充足的架构优化。这些优化的累积大幅度提升 vLLM 的推理性能。再加之整体架构可以快速使用底层 AI 技术的各种革新,因此 vLLM 的使用者可以跟随版本变更尽快使用到最新技术的红利。通过实际测试,在某些场景下,vLLM的推理速度能达到传统方法的5-10倍!
举例来说在 vLLM 中矩阵乘法可以利用 Marlin、DeepGEMM 和 CUTLASS 等技术进行加速。这几个技术的协同是 “场景驱动的分层加速”:CUTLASS 作为通用基础支撑全精度计算,DeepGEMM 专攻 FP8 场景,Marlin 聚焦 4 位量化优化,三者通过 vLLM 的动态调度逻辑(基于模型量化类型和硬件能力)实现无缝切换。最终在各类大模型推理场景中最大化矩阵乘法效率,支撑 vLLM 的高吞吐量和低延迟特性。
- CUTLASS (CUDA Templates for Linear Algebra Subroutines) 是由 NVIDIA 开源的高性能矩阵运算模板库,是 “通用基础层”。支持 FP16、BF16、FP8 等多种精度,可生成针对特定 GPU 架构(如 Ampere、Hopper)优化的矩阵乘法内核,提供低层次的 GEMM(General Matrix Multiply)实现。
- MARLIN(Mixed-Precision Auto-Regressive LINear 由 IST Austria、Neural Magic 等团队研发)是针对大语言模型(LLMs)设计的混合精度自回归并行推理内核,通过4 位权重量化、异步内存访问、多级别流水线、条纹分区等技术,解决了动态批处理场景下传统量化内核性能快速下降的问题。Marlin 在 GPU(当使用 NVIDIA GPU 时)上实现峰值性能(均匀精度)矩阵乘法会遵循 CUTLASS 分层并行化模型。
- DeepGEMM 是由 DeepSeek 推出,专为简洁高效的通用矩阵乘法 (GEMM) 而设计的库。它在针对**‘矩阵乘法累加(MMA)’的 C++ 模板代码方面,基于 CUTLASS 库进行结构重构与逻辑优化,以替代原有的自定义 MMA 实现。与 CUTLASS 中传统的分组 GEMM 不同,DeepGEMM 仅对 M 轴进行分组,而 N 轴和 K 轴必须保持不变。此设计专为 MoE 模型**中专家拥有相同形状的场景量身定制。
这三种技术来源不同,设计目的不同,出现时间不同。但在 vLLM 项目中,通过架构兼容性,相互之间可以交互整合,按场景准确实现透明的推理性能加速。无需用户参与或者定制优化手段。而这种持续的最优技术自由选择与集成就是 vLLM 性能会随着版本迭代越来越出色的重要原因。
再深入一步:拆解 model_runner 模块
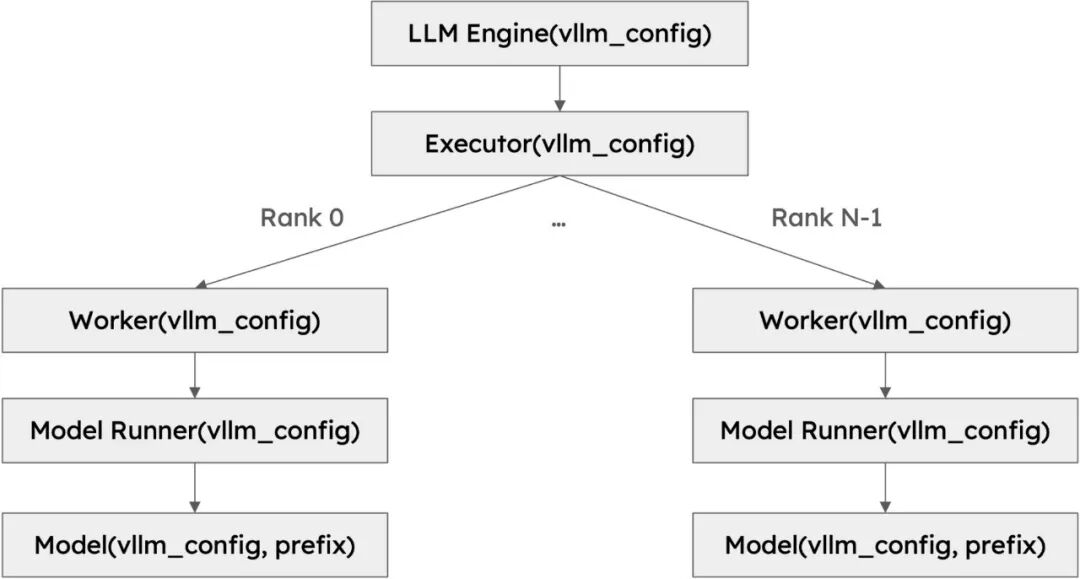
model_runner 并非独立完成某一步计算,而是作为 “协调者” 将上述组件串联成完整的推理流水线,典型流程如下:
- 初始化:接收用户输入 prompt,将其转换为
input_ids并初始化positions,同时为KV cache分配初始显存。 - 首次前向计算:将
input_ids和positions传入模型,计算所有 token 的K/V向量并存入KV cache,输出最后一个 token 的logits(中文常译为 “对数几率” 或 “原始得分”)。 - 采样生成:
sampler对象根据logits生成第一个新 token,更新input_ids和positions。 - 循环生成:重复以下步骤直到满足停止条件(如生成
<EOS>或达到最大长度): - 从
KV cache读取历史K/V向量; - 仅对新 token 计算
Query向量,与缓存的K/V交互完成注意力计算; - 输出新的
logits,由sampler生成下一个 token; - 更新
KV cache(追加新 token 的K/V)和缓冲区。
sampler 是自回归生成的 “决策模块”,其核心功能是根据模型前向计算输出的 logits(概率分布),按照指定策略(如贪心搜索、beam search、top-k 采样等)选择下一个 token。
https://zhuanlan.zhihu.com/p/694442998
KV cache 是 vLLM 实现高性能推理的核心优化之一,用于缓存历史 token 的 Key 和 Value 向量(Transformer 注意力机制中的关键计算量),因此在 model_runner 执行的过程中始终会与 KV cache 持续交互。
例如,生成第 n 个 token 时,model_runner 会从 KV cache 中直接读取前 n-1 个 token 的 K/V 向量,仅计算第 n 个 token 的 Query 向量并与缓存的 K/V 交互,大幅减少计算量。vLLM 的核心技术 PagedAttention ,也是通过 model_runner 整合到 KV cache 中的,从而实现高效的显存碎片管理和动态扩容管理。
前向传播缓冲区(forward-pass buffers 包括 input_ids、positions 等)是输入数据的 “临时仓库”,
这些缓冲区用于存储模型前向计算所需的输入数据,是连接用户输入与模型计算的 “数据接口”,主要包括:
input_ids:当前输入的 token 序列(整数编码,如 “今天天气” 对应的[101, 2023, 3000, 4000]),每次生成新 token 后会追加更新。positions:位置编码信息(记录每个 token 在序列中的位置,如[0, 1, 2, 3]),用于 Transformer 的位置感知。- 其他临时缓冲区:如模型中间层输出(
hidden_states)、注意力权重等,用于暂存计算过程中的中间结果。
在 model_runner 中,这些缓冲区被统一维护,确保每次前向计算时输入数据的完整性和时效性(例如,新 token 生成后及时更新 input_ids 和 positions,为下一轮计算做好准备)。
再深入一步:拆解 Key/Value Cache 的使用
1. 什么是 KV Cache:
让我们从 Transformer 开始。在 Transformer 的自注意力机制中,每个 token(可以被认为是单词或字符的编码)都会生成三个向量:
Q(查询):我正在寻找什么信息?
K(键):我是谁?(特征坐标)
V(值):我带来了什么内容?(特征内容)
当 Transformer 生成文本时,它一次只生成一个新的 token。然后,模型会将此 token 的 Q 与所有先前 token 的 K 进行比较,以找到相关性,并使用这些相关性 V 来计算输出。然而,在推理过程中,标准的 Transformer 会逐个 token 地生成数据。例如:
输入:“我想读一本”
生成:“我想读一本书”
继续生成:“我想读一本书”
但是,在生成第三个 token 时,它会重新计算所有先前 token 的 K 和 V,即使这些数据已经计算过了。这种重复计算导致推理的计算复杂度随着 token 数量的增加呈二次方增长,使其变得非常缓慢。
如上所述 KV Cache 的核心原则是避免重复劳动。KV Cache 的核心思想是直接存储历史的 K 和 V 计算结果,避免每次重新计算。
这样,每次生成新的 token 时,只需计算新 token 的 K 和 V,并将其添加到之前缓存的结果中,然后使用缓存的值再次生成新的 token。这将推理的计算复杂度从二次方降低到线性,显著加快了推理速度。
2. 为什么 KV Cache 对 Transformer 架构如此重要?
在 LLM 中,KV Cache 已成为 Transformer 架构高效运行的关键机制。它不仅解决了长上下文带来的计算冗余问题,还直接有助于控制延迟并提升吞吐量。其重要性主要体现在以下几个方面:
降低计算开销:避免对历史序列进行重复的注意力计算,将推理复杂度从二次方降低到近似线性。
提升推理速度:显著降低生成长文本时的延迟,提升用户体验。
提升资源利用率:减少不必要的 GPU 内存和计算能力消耗,为内存优化提供空间。
支持可扩展性和优化:为 KV Cache Offload 等解决方案奠定基础,这些解决方案可以将部分缓存移至 CPU 内存,在保持性能的同时缓解 GPU 内存压力。
3. 什么是 KV Cache Offload?它的作用是什么?
KV Cache 在加速 Transformer 推理的同时,也带来了一个副作用:它会消耗大量的显存。随着大型语言模型上下文长度的不断增长,这个问题变得越来越突出。例如:
当上下文长度达到 80,000 个 token 时,每个 token 都必须存储其对应的键和值。仅 KV Cache 一项就可能消耗数十 GB 的显存。更重要的是,GPU 显存不仅要容纳 KV Cache,还要存储模型权重和中间计算结果。一旦这些资源被占满,推理就会崩溃甚至失败。
为了解决这一矛盾,业界提出了 KV Cache Offload。其核心思想是将非活动或暂时未使用的 KV 数据从 GPU 内存迁移到其他存储介质。
例如:
CPU 内存(RAM):容量大,适合存储大型缓存,但带宽和延迟比 GPU 更低。
SSD:提供海量存储容量,但速度较慢,通常作为极端场景下的补充解决方案。
高带宽内存 (HBM):其速度接近 GPU 内存,但价格昂贵且容量有限。
卸载可以释放 GPU 内存,优先保证正在进行的推理的平稳运行。必要时,系统会将相关的键值数据从外部存储移回 GPU。虽然这会产生一些数据传输开销,但与内存耗尽导致的推理中断相比,卸载在大规模推理部署中至关重要。它本质上是一种内存优化策略,在性能和资源利用率之间取得最佳平衡。
结论:
通过缓存历史注意力状态,KV Cache 显著减少了冗余计算并加快了响应时间。另一方面,卸载策略可以在 GPU、CPU 甚至存储层之间智能地迁移数据,以满足大型模型不断增长的内存需求。这些技术组合不仅提升了效率和可扩展性,也为部署更大规模、上下文窗口更长的语言模型铺平了道路。随着研究和工程实践的不断推进,KV Cache 与 KV Cache Offload 的组合将是高性能 LLM 服务的基石。
再深入一步:拆解 KV Cache 的用量计算
在 vLLM 的启动参数中,有几个关键参数,它们直接决定了 KV 缓存的使用方式。在了解这些参数之前,我们首先要了解 KV 缓存的计算原理。
标准 transformer layer 层 KV 缓存单块内存占用计算公式
(非 MLA 多头注意力模型,MOE模型会更复杂一些)完整拆解为:
2 (key/value) * block_size (default=16) * num_kv_heads * head_size * dtype_num_bytes (e.g. 2 for bf16)
1. “2(Key/Value)”:对应 KV 缓存的矩阵容量,因为有 Key 还有 Value 所以要 *2 。
Transformer 的自注意力机制中,每个 token 会生成 3 个向量:Query(Q)、Key(K)、Value(V)。而我们计算所使用
- 推理时,Q 会实时计算(因每次输入的 token 不同),但K 和 V 会缓存(已处理的 token 的 K/V 无需重复计算);
- 因此 KV 缓存需要同时存储 K 和 V 两个独立矩阵,故公式中需乘以 “2”,代表 “K 矩阵的内存 + V 矩阵的内存”。
2. “block_size”(默认 = 16):KV 缓存的 “序列块长度”
这里的block_size是工程优化中的 “分块参数”,指将输入序列拆分为多个 “小块” 处理(而非一次性处理整段序列),目的是平衡推理速度与内存占用:
- 例如默认值 16,代表每个缓存块对应16 个连续 token的 K/V 数据;
- 注意:此处的
block_size是 “序列分块长度”,与最终计算结果 “KV 缓存单块内存大小” 是两个概念(前者是 “token 数量”,后者是 “内存字节数”)。
3. “num_kv_heads”:KV 注意力头的数量
Transformer 的注意力机制通过 “多头部并行” 提升建模能力,但部分架构(如 MQA 混合注意力、GQA 分组注意力)中,KV 头数(num_kv_heads)≠ Query 头数(num_q_heads):
- 例如 GPT-4 采用 GQA,若 num_q_heads=40,num_kv_heads=8(即 5 个 Q 头共享 1 个 KV 头);
- 公式中必须用
num_kv_heads(而非 Q 头数),因为 KV 缓存只存储 “KV 头” 对应的 K/V 矩阵,与 Q 头无关。
4. head_size:单个 KV 注意力头的维度
注意力头的 “维度” 是 Transformer 的核心参数,由模型总维度(d_model)和头数推导而来:
- 公式:
head_size = d_model ÷ num_heads(若 Q/KV 头数一致);若 KV 头数更少(如 GQA),则head_size仍与 Q 头维度相同(确保矩阵可匹配计算); - 例如:模型总维度
d_model=1024,num_kv_heads=8,则head_size=1024÷8=128(每个 KV 头处理 128 维的向量)。
5. dtype_num_bytes:数据类型的字节数
Transformer 模型的参数(包括 K/V 矩阵)需用具体数据类型存储,不同类型的字节数直接影响内存占用:
- 常见类型对应字节数:
bf16(脑浮点数)/fp16(半精度浮点数):2 字节;fp32(单精度浮点数):4 字节;fp8(低精度浮点数):1 字节;- 公式中用
dtype_num_bytes将 “向量维度” 转换为 “实际内存字节数”,是工程落地的关键(低精度如 bf16 可大幅减少缓存占用)。
总结为:
KV 缓存单块内存大小 = 2(Key/Value 矩阵) × block_size(序列块长度) × num_kv_heads(KV 注意力头数) × head_size(单个 KV 头维度) × dtype_num_bytes(数据类型字节数)
而涉及到计算公式中的各项因素,可以从 vLLM 或是 Red Hat Inference Server 的启动参数对它们进行快速定制:
https://docs.redhat.com/en/documentation/red_hat_ai_inference_server/3.2/html-single/vllm_server_arguments/index
[–block-size {1,8,16,32,64,128}]
block-size 控制 KV 缓存的 “分块大小”(单位:token),即每次为 KV 缓存分配内存时的最小粒度。
[–max-model-len MAX_MODEL_LEN]
限制模型支持的 “最大序列总长度”(输入 token 数 + 生成 token 数),超过此长度的序列会被截断。
[–kv-cache-dtype {auto,fp8,fp8_e4m3,fp8_e5m2}]
指定 KV 缓存的数据类型,影响显存占用和计算效率。
[–max-num-seqs MAX_NUM_SEQS]
限制 GPU 同时处理的 “最大并发序列数”(即同时处理的独立请求数)。
[–cpu-offload-gb CPU_OFFLOAD_GB]
指定可用于 “KV 缓存 CPU 卸载” 的内存大小(单位:GB),当 GPU 显存不足时,将部分 KV 缓存临时迁移到 CPU 内存。
此外,还有几个参数会从被加载模型的 config.json 文件中读取。
例如:传统 Transformer(无 GQA/MQA)num_kv_heads = num_attention_heads,含分组注意力的模型则通过num_attention_heads / num_key_value_groups 计算:
“deepseek-ai/DeepSeek-R1-Distill-Qwen-1.5B” 模型的的 num_kv_heads 就等于 num_attention_heads 。
“num_attention_heads”: 12,
“hidden_size”: 1536,
head_size = hidden_size ÷ num_attention_heads
在 vLLM 的执行中,这几个参数可以直接影响整体模型执行性能。因此我们可以通过熟悉这几个参数开始对企业级 AI 应用进行有的放矢的专项调优。
这只是冰山一角
今天的拆解只是vLLM技术的入门课。更劲爆的内容还在后面:执行前向传播,分块预填充、前缀缓存、推测解码…每一项都是能让推理速度再上一个台阶的黑科技!
最后
为什么要学AI大模型
当下,⼈⼯智能市场迎来了爆发期,并逐渐进⼊以⼈⼯通⽤智能(AGI)为主导的新时代。企业纷纷官宣“ AI+ ”战略,为新兴技术⼈才创造丰富的就业机会,⼈才缺⼝将达 400 万!
DeepSeek问世以来,生成式AI和大模型技术爆发式增长,让很多岗位重新成了炙手可热的新星,岗位薪资远超很多后端岗位,在程序员中稳居前列。

与此同时AI与各行各业深度融合,飞速发展,成为炙手可热的新风口,企业非常需要了解AI、懂AI、会用AI的员工,纷纷开出高薪招聘AI大模型相关岗位。

最近很多程序员朋友都已经学习或者准备学习 AI 大模型,后台也经常会有小伙伴咨询学习路线和学习资料,我特别拜托北京清华大学学士和美国加州理工学院博士学位的鲁为民老师给大家这里给大家准备了一份涵盖了AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频 全系列的学习资料,这些学习资料不仅深入浅出,而且非常实用,让大家系统而高效地掌握AI大模型的各个知识点。
这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】
AI大模型系统学习路线
在面对AI大模型开发领域的复杂与深入,精准学习显得尤为重要。一份系统的技术路线图,不仅能够帮助开发者清晰地了解从入门到精通所需掌握的知识点,还能提供一条高效、有序的学习路径。

但知道是一回事,做又是另一回事,初学者最常遇到的问题主要是理论知识缺乏、资源和工具的限制、模型理解和调试的复杂性,在这基础上,找到高质量的学习资源,不浪费时间、不走弯路,又是重中之重。
AI大模型入门到实战的视频教程+项目包
看视频学习是一种高效、直观、灵活且富有吸引力的学习方式,可以更直观地展示过程,能有效提升学习兴趣和理解力,是现在获取知识的重要途径

光学理论是没用的,要学会跟着一起敲,要动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。

海量AI大模型必读的经典书籍(PDF)
阅读AI大模型经典书籍可以帮助读者提高技术水平,开拓视野,掌握核心技术,提高解决问题的能力,同时也可以借鉴他人的经验。对于想要深入学习AI大模型开发的读者来说,阅读经典书籍是非常有必要的。

600+AI大模型报告(实时更新)
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

AI大模型面试真题+答案解析
我们学习AI大模型必然是想找到高薪的工作,下面这些面试题都是总结当前最新、最热、最高频的面试题,并且每道题都有详细的答案,面试前刷完这套面试题资料,小小offer,不在话下


这份完整版的大模型 AI 学习资料已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









