









存储引擎
InfluxDB 数据的写入如下图所示:
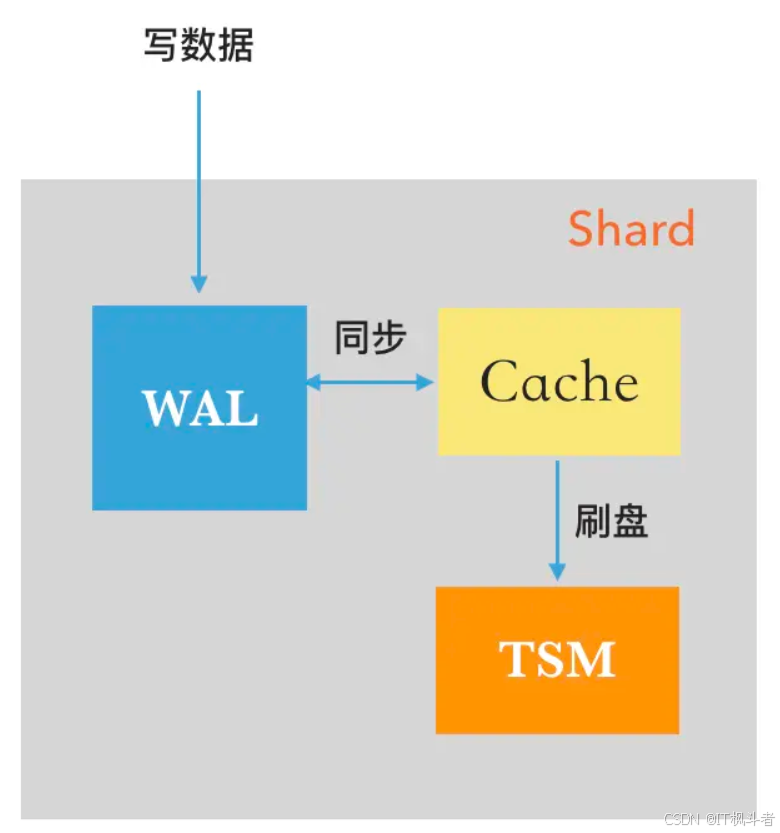
所有数据先写入到 WAL( Write Ahead Log )预写日志文件,并同步到 Cache 缓存中,当 Cache 缓存的数据达到了一定的大小,或者达到一定的时间间隔之后,数据会被写入到 TSM 文件中。
为了更高效的存储大量数据,存储引擎会将数据进行压缩处理,压缩的输入和输出都是 TSM 文件,因此为了以原子方式替换以及删除 TSM 文件,存储引擎由 FileStore 负责调节对所有 TSM 文件的访问权限。
Compaction Planner 负责确定哪些 TSM 文件已经准备好了可以进行压缩,并确保多个并发压缩不会互相干扰。
Compactor 压缩器则负责具体的 Compression 压缩工作。
为了处理文件,存储引擎通过 Writers/Readers 处理数据的写和读。另外存储引擎还会使用 In-Memory Index 内存索引快速访问 measurements、tags、series 等数据。
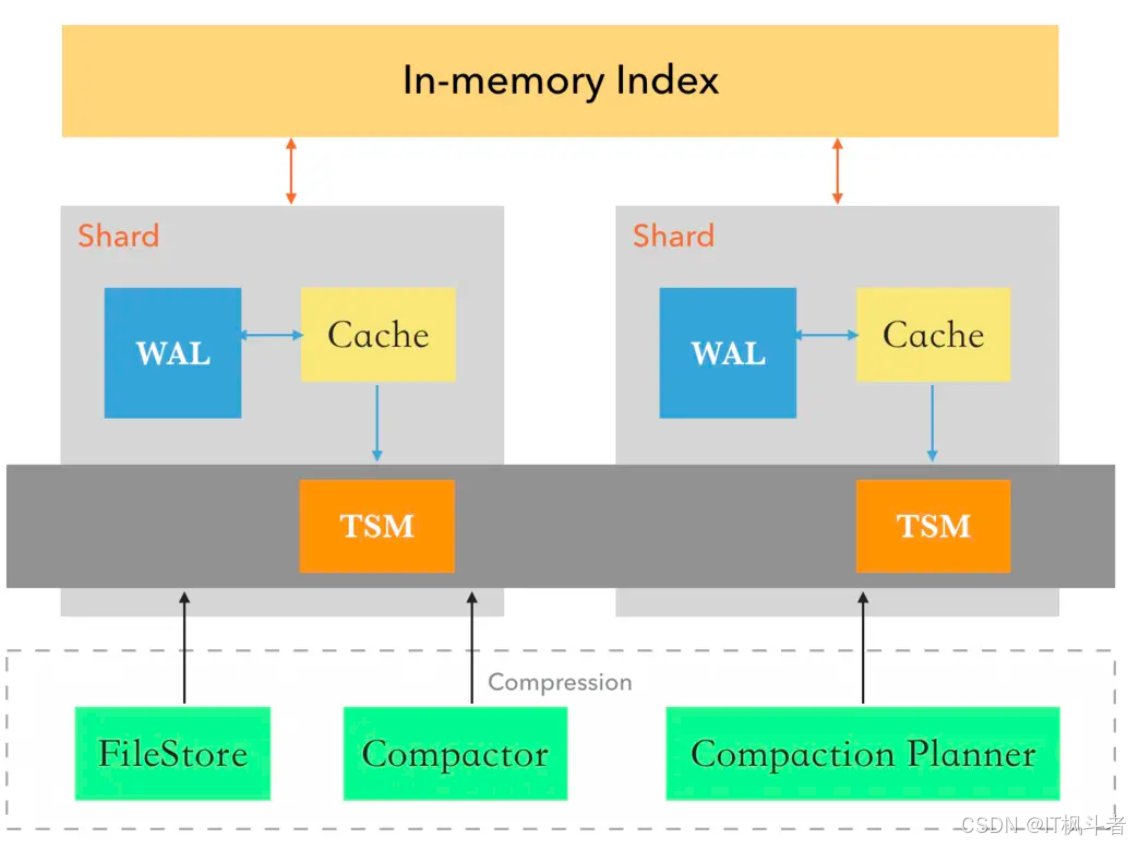
存储引擎的组成部分:
- In-Memory Index :跨分片的共享内存索引,并不是存储引擎本身特有的,存储引擎只是用到了它。
- WAL :预写日志。
- Cache :同步缓存 WAL 的内容,并最终刷写到 TSM 文件中去。
- TSM Files :特定格式存储最终数据的磁盘文件。
- FileStore :调节对磁盘上所有TSM文件的访问。
- Compactor :压缩器。
- Compaction Planner :压缩计划。
- Compression :编码解码压缩。
- Writers/Readers :读写文件。
硬件指南
为了应对不同的负载情况,我需要机器具有怎样的硬件配置?
由于集群模式只有商业版本,因此这里只看免费的单机版的情况。
为了定义负载,我们关注以下三个指标:
- 每秒写入
- 每秒查询
- series 基数
对于查询情况,我们根据复杂程度分为三级:
- 简单查询:
- 几乎没用函数和正则表达式
- 时间范围在几分钟,几小时,或者一天之内
- 执行时间通常在几毫秒到几十毫秒
- 中等复杂度查询:
- 使用了多个函数和一两个正则表达式
- 可能使用了复杂的 GROUP BY 语句,或者时间范围是几个星期
- 执行时间通常在几百毫秒到几千毫秒
- 复杂查询:
- 使用了多个聚合、转换函数,或者多个正则表达式
- 时间跨度很大,有几个月或几年
- 执行时间达到秒级
硬件配置需要关注的有:CPU 核数,RAM 内存大小,IOPS 性能。
IOPS( Input/Output Operations Per Second ):每秒读写数,衡量存储设备(如 SSD 固态硬盘、HDD 机械硬盘等)的性能指标。
不同负载情况下的硬件配置参考如下:
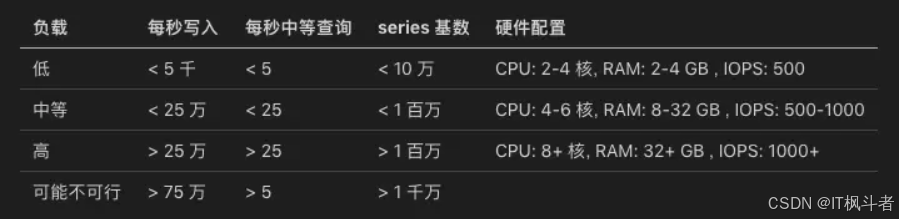
由于 SSD 固态硬盘的性能更高,官方也建议使用 SSD ,上图也是使用 SSD 的情况。
对于元数据,诸如 database name、measurement、tag key、tag value、field key 都只会存储一次,只有 field value 和 timestamp 每个点都存储。非字符串的值大约需要三个字节,字符串的值需要的空间大小不固定,需要由压缩情况确定。
内存肯定是越大越好,但是如果 series 基数超过千万级别,在默认使用的 in-memory 索引方式下,会导致内存溢出,在数据结构设计时需要注意。
通过将 wal 和 data 目录设置到不同的存储设备上,有利于减少磁盘的争用,从而应对更高的写入负载。相关配置项(默认的配置文件为 influxdb.conf ):
[data]
dir = "/var/lib/influxdb/data"
wal-dir = "/var/lib/influxdb/wal"



















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











