



Hive初识

Hive是一种构建数据仓库的工具。里面有表的概念。
在Mysql里从表中插入的数据,会放在磁盘上。再打开这个表的时候,会把磁盘上的数据规整到一个表格里显示。
但是计算机不会自己规整成表格,所以在Hive中需要一份元数据
这份元数据包括:
元数据(
行的分隔符(这样在映射成表的时候知道能映射成几行)
字段分隔符(这样在映射成表的时候知道能映射成几列)
字段的类型
字段的名称
)
Hive内部也是有表的概念,Hive把数据存储到HDFS上。
它的元数据存到了本地的轻量级的Derby数据库中。
Hive依赖于HDFS和MapReduce,可以看成是分布式的大表。也是支持使用SQL语句进行数据的处理。
Hive原理
1.客户端传一条SQL语句给Hive(Hive支持所有的SQL标准)
2.Hive对SQL进行解析,优化SQL,策略选择器,消耗模型(看下哪种计划是最好的,看下消耗时间),把一个个的SQL解析成一个个MapReduce。(解析器,编译器,优化器)
3.MR计算的数据在HDFS上。MR处理HDFS上的数据。
效率问题
封装的越高层,效率越低
Hive做了什么事情
通过SQL语句解析成MapReduce这个过程是Hive做的。
其它的事情是它指挥别人来做的。
Hive架构
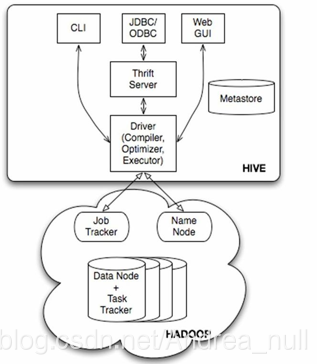
Hive提供了一个服务叫做thrift server[干嘛用的:方便用户通过JDK操作Hive]
1.客户端可以写JDBC程序,先连thrift server。
Hive工具里有:解析器,优化器,编译器等等。
2.thrift server连接Hive工具。然后把客户端里写的SQL语句传给Hive。
3.Hive解析完了以后,就会产生一个个MapReduce应用程序。这些节点既是DataNode,也是NodeManager。
我们也可以通过其它客户端,利用Hive提供的CLI工具直接连接Hive。
在Hive脚本直接执行hive命令,会进入一个命令提示符hive>。
在里面可以直接书写hive语句,回车以后后台会直接运行,之后把结果提示出来。
Hive也提供了另一个工具,叫做WEB GUI,通过Web界面操作Hive(兼容性不是那么好)
可以在UI界面上写SQL语句,点击页面的某个按钮提交给Hive工具
Hive工具解析成MapReduce
将SQL语句给Hive,它会做哪些过程
在Hive里面写SQL语句。那语句叫做HQL

Hive搭建模式
搭建HiveT具的模式分为三种:
local本地:元数据库(derby)与工具都是在本地
1、配置完成后在Hive中创建一张表
create table Andrea1(id Int,name String)
2、往表中插入数据
insert into Andrea1 values(1,“zs”);启动MR任务
3、select * from Andrea1;不会启动MR,直接去HDFS上读取就行
如果SQL语句中有where,count,sum等聚合类的函数,会启动一个MR任务。
缺点

不允许多个用户同时操作hive,是由于derby的缺陷导致。
另外一个用户已经创建这个数据库了,你不可以再用了。
local(mysql)模式:hive工具与mysql在同一个节点上
这样元数据库使用mysql来替换。
基于mysql的远程模式

我们在客户端上搭建了一个Hive工具,这个工具可以直接拿来就用不用启动。在客户端上配置了一个mysql数据库。好处:解耦
这个Hive工具提供了一个服务叫做meta store service(提供了元数据的存储服务)。
如何开启这个服务?hive --service metastore
这个服务,作为一个永驻的进程。
假设node01上也有一个Hive安装包。在hive-site.xml中配置了连接client的元数据服务。这样如果有node02,操作的可以是同一个数据库。因为连接的是同一个meta store服务。支持数据共享。
Hive中表的类型
内部表(受控表):受Hive控制。删除内部表的时候,HDFS上的数据及元数据都会被删除。
外部表:删除外部表的时候,HDFS上的数据不会被删除但是元数据会被删除。
临时表(测试):在当前会话期间内存在,会话结束自动消失。生命周期随着session
分区表:将一批数据分成多个目录来存储
为什么创建分区表?
防止暴力扫描全表,需要一个分区表来提高查询效率
往分区中添加数据有四种方式:
(1)insert 指定分区
(2)load data 指定分区
(3)查询已有表的数据,insert到新表中
from day_hour_table insert into table newt partition(dt=01,hour=9898) select id,content
(4)alter table add partition创建空分区,然后使用HDFS命令往空分区目录中上传数据
(5)创建分区,并且指定分区数据的位置
分桶表:取模存储
为什么创建分桶表?
思想:引例找两个文件的url—将url装成hashcode取模,转成小文件,比对小文件。
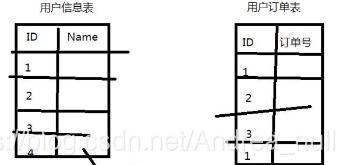
比如,有两个表如上。要找所有用户的订单数,就要进行join。
join底层的原理:先搞一个笛卡尔积。遍历右表n次,效率很慢。
解决:
把用户信息表存储的时候,根据ID与number(分成小文件的个数)取模,分成多个表来存。
订单表也同样根据ID与number(分成小文件的个数)取模,分成多个表来存。
对应的表两两join就可以完成。

















 837
837

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









