




 本文介绍了作者在做hive相关项目时,如何从无到有建立数仓的过程。通过了解数仓知识,建立事实表与维度表,明确了从原子层到专题库再到mysql的数据流向。文章强调了业务需求的重要性,并分享了数据仓库的分层结构,包括ODS、维表和事实表、主题层、聚合层和应用层。此外,还讨论了增量数据合并的处理位置和维度表的处理思路。
本文介绍了作者在做hive相关项目时,如何从无到有建立数仓的过程。通过了解数仓知识,建立事实表与维度表,明确了从原子层到专题库再到mysql的数据流向。文章强调了业务需求的重要性,并分享了数据仓库的分层结构,包括ODS、维表和事实表、主题层、聚合层和应用层。此外,还讨论了增量数据合并的处理位置和维度表的处理思路。
最近在做hive相关的项目,以前做spark也没有太关注数仓,这更多的是关于切入问题解决问题的思路记录。
主要就是基于主题库的数据建立对应的专题库以供对应专题服务。一开始因为spark招的我,结果让我来做hive,没办法,拿人钱财,替人解忧,于是乎哼哧哼哧做数仓去了,但是没有经验的我,又没人带只有自己加油搞了咯。好歹自己还有些hive的底子。
速成策略:
1.首先了解数仓相关知识
2.了解事实表与维度表的建立与实施,
3.找出业务需求然后寻找对应的解决方案。
4,后期开发顺利推进。
- 1,数仓
学习一样新的东西不都得是先概念再具体嘛,不然做得一脸懵逼,出来的成果也是不合适。
1.1上图先,毕竟图片易于理解
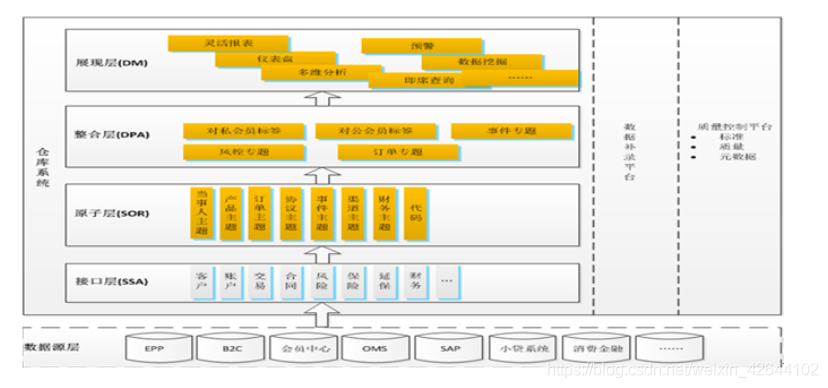 数据仓库的分层结构,有人说是基于ETL作为基础来分层的,(抽取,清洗,转换,加载(mysql))但是基于上图可能会更具体一些,主要就是贴近我们这个项目。
数据仓库的分层结构,有人说是基于ETL作为基础来分层的,(抽取,清洗,转换,加载(mysql))但是基于上图可能会更具体一些,主要就是贴近我们这个项目。
1.2通过这样子的一个架构明确我就可以明确自己接下的工作方向了。
从原子层(主题)的数据转换整合成对应专题库的数据,然后再加载到mysql供展现层调用数据。
1.3具体怎么做?
问题细分为两步:
第一步:是从原子层转换成对应专题库的数据,
第二步:是从专题库将数据加载到mysql供展现层使用。
但是这样想只是口号。我们最终要解决的还是业务导向,我们需要明确的是我们的业务需求。明确业务需求了就会知道mysql最终需要一些什么数据才能支撑。
而知道mysql数据才会知道专题库需要些什么,知道专题题库需要些什么数据。
- 2项目的实际情况架构
一、数据仓库的分层结构
1)ods层:原始数据直接同步过来;ODS作为数据缓冲层,保留的是所有的数据,理论上粒度和源系统保持一致,同时不丢数据,业务DB基本上是直接同步过来,LOG主要是做结构化。
2)维表和事实表层:该主要是将ods的数据经过规范化处理、业务逻辑处理等得到的。在该层以后使用的所有数据都必须且只能来自该层,不能再从ods层提取。
3)主题层:主要将维表和事实层的数据按照相同的业务主题进行整合得到。
4)聚合层:在事实层和主题层的基础上,按照业务需求对数据进行相应的汇总,直接面向应用层。
5)应用层:主要用于生成报表,展现给需求方。
那我们就是做聚合层应该做的事情了;
二、数据流向规范
1)原始数据需要先同步到ods层,除ods外的其他任何层都不能直接使用原始数据
2)汇总层/app层数据 不能直接依赖ods层数据
 补充:
补充:
数仓分层
数仓前几层一般包括:ODS、STD、DWD
ODS是原始数据汇集层,一般把生产库的数据同步过来即可(当然要有增量数据,增量方式后面有讨论)
STD是数据标准层,针对ODS的原始数据做些基础的清洗、标准化
DWD常做为数据描述层,通常对STD层的数据按照主题、或者大的业务分类,进行数据整合,常包括数据合并拆分(表合并、分类)、数据计算(简单的计算逻辑生成需要的数据)
数仓建设完成后,通过DWD层,对使用人员提供服务。使用人员可以通过DWD层进行业务专题库建设或者数据建模,进行数据轻度汇总再对外使用等等。
作者:远处的一只猫
来源:优快云
原文:https://blog.youkuaiyun.com/micklf/article/details/82893776
对于增量数据的合并动作(把1、2、3月的变化数据合并),在哪一层做,是有歧义的。这里有2种做法:
方案一,在ODS层合并好,然后每天晚上重新生成STD、DWD层
好处在于干净,可以由负责入库的ETL同学做掉。后面建仓的时候完全不关心。
方案二,在STD层合并好,然后每天晚上重新生成DWD层
减少一次数据拷贝(ODS到STD一般不做字段合并和拆分,所以也省不太多时间)
方案三,在DWD层,最后合并
限制较多。如果STD到DWD的按主题整理过程比较复杂(除了常见的多表合并,还会涉及计算,那从STD增量表到DWD增量表的过程就很复杂了)
由于是DWD层对外提供服务,所以上述方案都不影响使用者。
续更:
今天周五,一整天都在琢磨维度表的处理:
贴上交叉维度处理思路,接下来就是进行实施工作了
第一步;表一获取所需所有字段
第二步:将来源表字段数据转换成自己所需字段
第三步:进行时间维度进行计算
第三步:根据地域层维度进行管理
第四步:根据部门层维度进行管理
第五步:根据主题类型、问题类型、年龄段、职业类型,问题来源,高频词,性别,
第六步:计算受理案件数,受理案件数占比、办结案件数,办结中案件数、超期未办结案件总数量,案件办结率,平均投诉次数,退件次数,退件次数占比,同一邮箱频次;
第七步:得出最终结果表;
结论:如果今后拿到一分需求让做专题库;
主要思路是1.先找常量(不变的量,做维度),再找变量做计算
2.处理常量应该先找层级常量,用于下钻。
3.再找维度常量做处理。
4.处理好维度之后再做统计指标计算。

















 1462
1462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









