




 本文详细介绍了LSTM(长短期记忆网络)和GRU(门控循环单元)的工作原理,包括遗忘门、输入门、输出门在LSTM中的作用,以及GRU如何通过更新门和重置门简化LSTM的复杂性,同时保持良好的性能表现。
本文详细介绍了LSTM(长短期记忆网络)和GRU(门控循环单元)的工作原理,包括遗忘门、输入门、输出门在LSTM中的作用,以及GRU如何通过更新门和重置门简化LSTM的复杂性,同时保持良好的性能表现。
2.1 LSTM(Long-short term memory)
长短期记忆((Long short-term memory)最早是1997年由Hochreiter 和 Schmidhuber在论文《LONG SHORT-TERM MEMORY》[3]^{[3]}[3]中提出的。
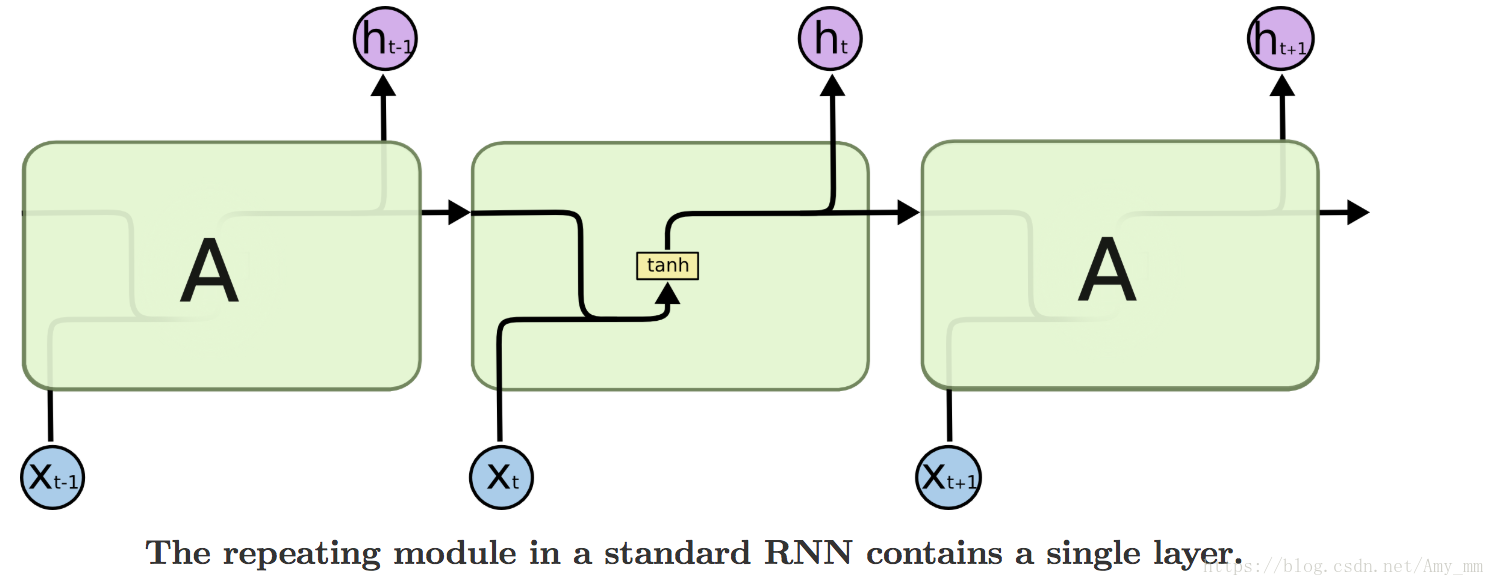
在所有的循环神经网络中都有一个如图所示的循环链,链式结构的每个单元将输入的信息进行处理后输出。在常规循环神经网络中的链式结构的单元中只含有一个非线性函数对数据进行非线性转换,比如tanh函数。而在LSTM等RNN变体的循环神经网络中,每个单元在不同位置多加了几个不同的非线性函数,实现不同的功能,解决不同的问题。如下图所示。
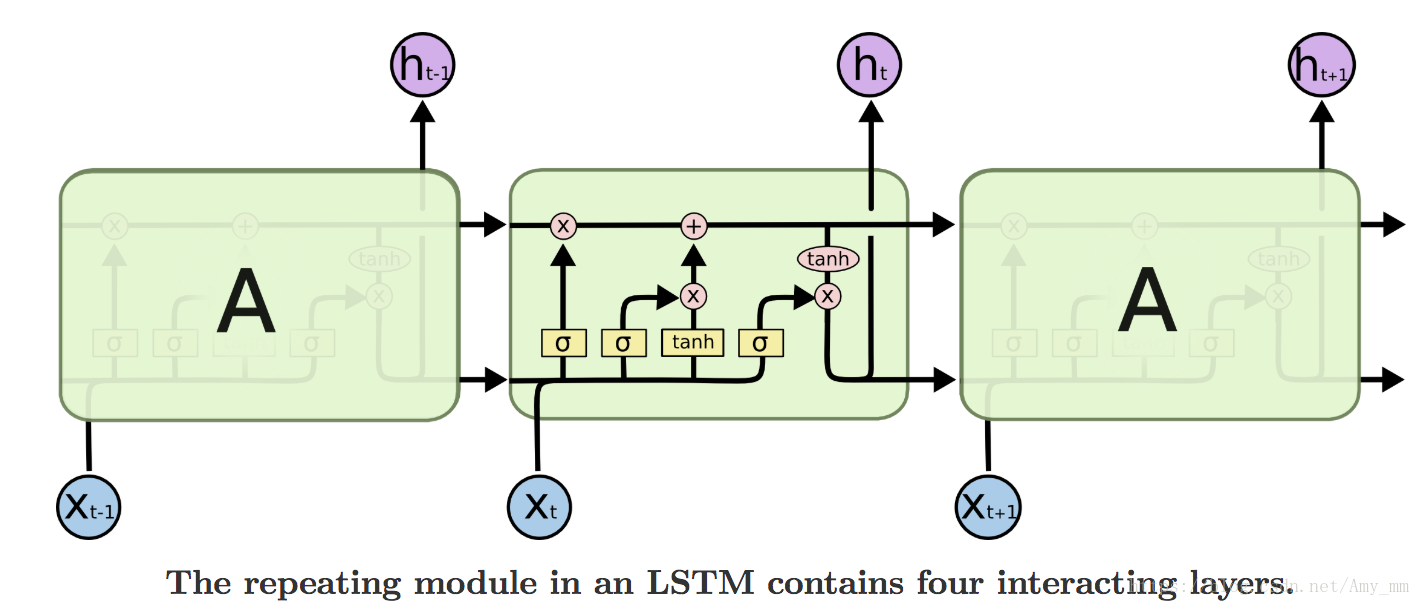
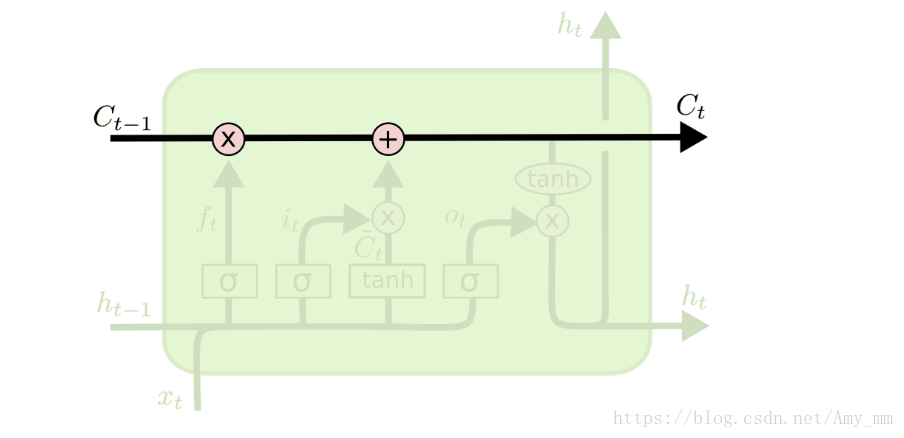
LSTM最主要的就是记忆细胞(memory cell ),处于整个单元的水平线上,起到了信息传送带的作用,只几个含有简单的线性操作,能够保证数据流动时保持不变,也就相当于上文说的渗漏单元。如下图所示。
详解LSTM
LSTM就是在每个小单元中增加了三个sigmoid函数,实现门控功能,控制数据的流入流出,分别称为遗忘门(forget gate),输入门(input gate)和输出门(output gate)。
1、遗忘门(forget gate)
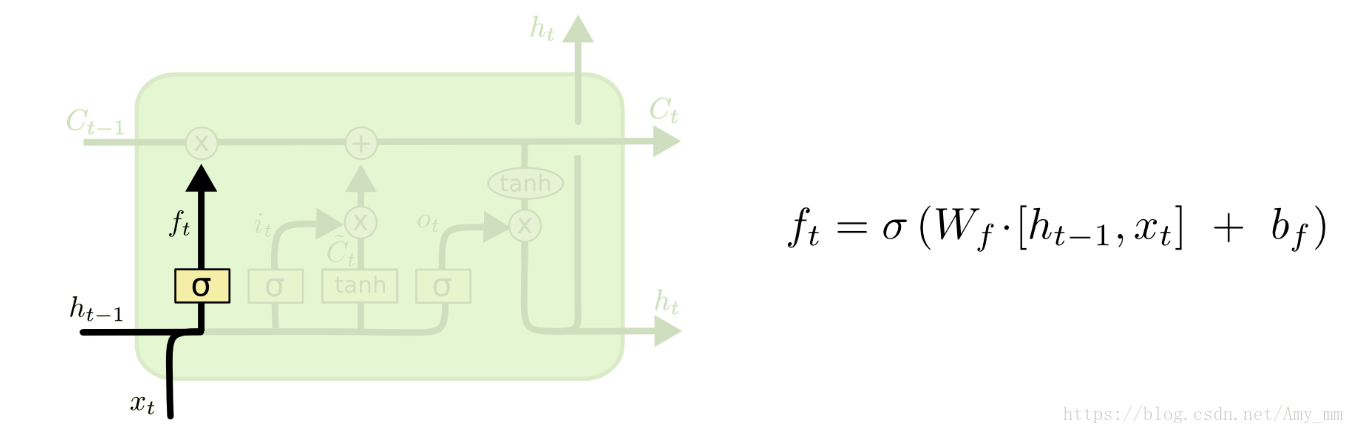
主要功能: 决定记忆细胞中要丢弃的信息,也就是决定前一时刻记忆细胞Ct−1C_{t-1}Ct−1中有多少信息能够继续传递给当前时刻的记忆细胞CtC_{t}Ct。
数学公式:
KaTeX parse error: No such environment: split at position 8: \begin{̲s̲p̲l̲i̲t̲}̲
f_{t} &=\sigma…
2、输入门(input gate)
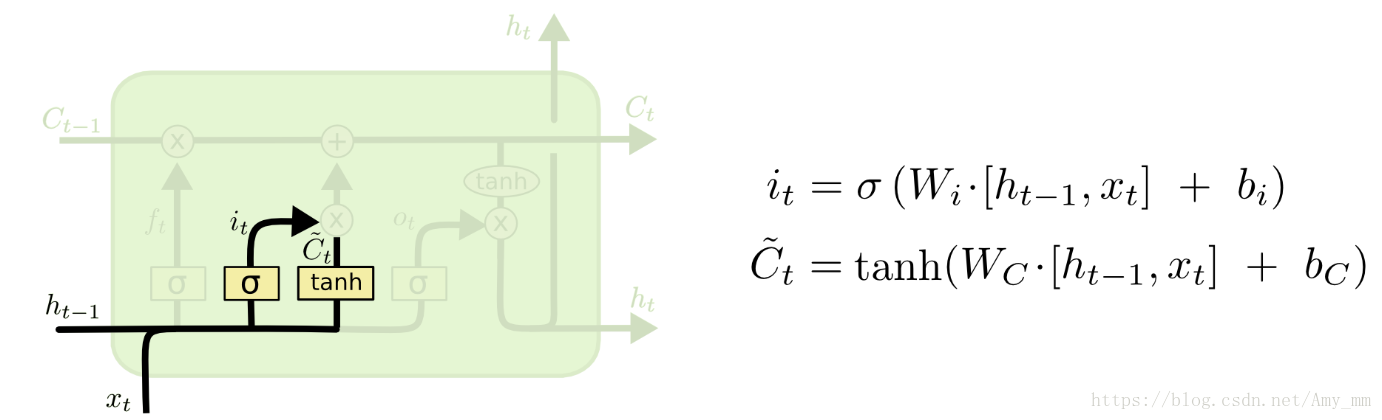
主要功能: 决定有多少新的输入信息能够进入当前时刻的记忆细胞CtC_{t}Ct。
数学公式:
KaTeX parse error: No such environment: split at position 8: \begin{̲s̲p̲l̲i̲t̲}̲
i_{t} &=\sigma…
3、输出门(output gate)
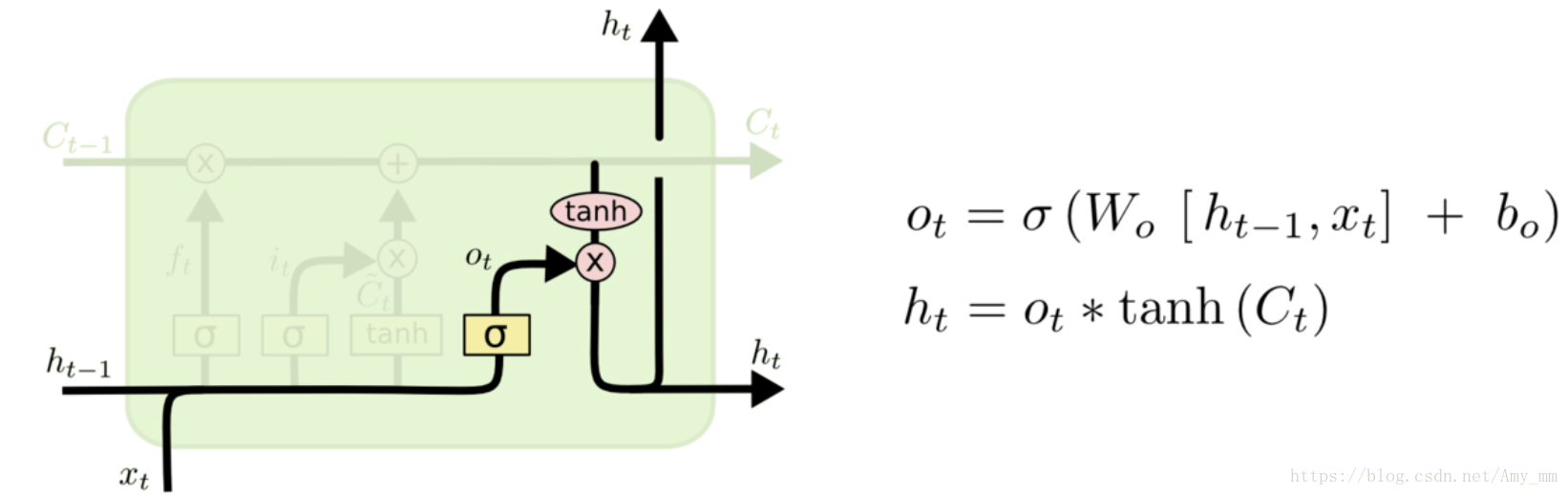
主要功能: 决定有多少当前时刻的记忆细胞CtC_{t}Ct中的信息能够进入到隐藏层状态hth_{t}ht中。
数学公式:
KaTeX parse error: No such environment: split at position 8: \begin{̲s̲p̲l̲i̲t̲}̲
o_{t} &=\sigma…
4、利用遗忘门和输入门更新记忆细胞:
利用tanh函数产生候选记忆细胞Ct~\tilde{C_{t}}Ct~,也就是即将要进入输入门的信息。
KaTeX parse error: No such environment: split at position 8: \begin{̲s̲p̲l̲i̲t̲}̲
\tilde{C_{t}} …
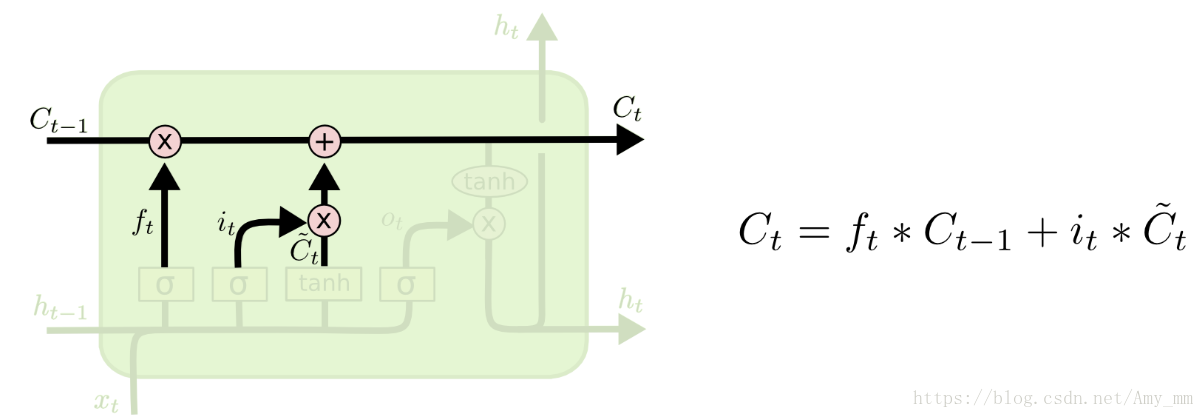
遗忘门的输出与旧状态相乘,决定有多少旧状态的信息能够进入到新的记忆细胞;输入门的输出与候选记忆细胞相乘,决定有多少信息要被更新。二者线性相加得到当前时刻被更新过的记忆细胞。
KaTeX parse error: No such environment: split at position 7: \begin{̲s̲p̲l̲i̲t̲}̲
C_{t} &= f_{t…
也正是这一过程实现了历史信息的累积。
5、利用输出门将信息输出到隐藏层
将数据经过tanh函数的处理(tanh(Ct))(tanh(C_{t}))(tanh(Ct)),将数据归一化在[-1, 1]区间内。然后输出门的结果与归一化的数据相乘,控制输出到隐藏层的数据量。
ht=ot∗tanh(Ct)(11) h_{t} = o_{t} \ast tanh(C_{t}) \qquad (11) ht=ot∗tanh(Ct)(11)
2.2 GRU
在神经网络发展的过程中,几乎所有关于LSTM的文章中对于LSTM的结构都会做出一些变动,也称为LSTM的变体。其中变动较大的是门控循环单元(Gated Recurrent Units),也就是较为流行的GRU。GRU是2014年由Cho, et al在文章《Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation》中提出的,某种程度上GRU也是对于LSTM结构复杂性的优化。LSTM能够解决循环神经网络因长期依赖带来的梯度消失和梯度爆炸问题,但是LSTM有三个不同的门,参数较多,训练起来比较困难。GRU只含有两个门控结构,且在超参数全部调优的情况下,二者性能相当,但是GRU结构更为简单,训练样本较少,易实现。
GRU在LSTM的基础上主要做出了两点改变 :
(1)GRU只有两个门。GRU将LSTM中的输入门和遗忘门合二为一,称为更新门(update gate),上图中的z(t)z_{(t)}z(t),控制前边记忆信息能够继续保留到当前时刻的数据量,或者说决定有多少前一时间步的信息和当前时间步的信息要被继续传递到未来;GRU的另一个门称为重置门(reset gate),上图中的r(t)r_{(t)}r(t),控制要遗忘多少过去的信息。
(2)取消进行线性自更新的记忆单元(memory cell),而是直接在隐藏单元中利用门控直接进行线性自更新。GRU的逻辑图如上图所示。

详解GRU
1、更新门(update gate)
主要功能:
决定有多少过去的信息可以继续传递到未来。 将前一时刻和当前时刻的信息分别进行线性变换,也就是分别右乘权重矩阵,然后相加后的数据送入更新门,也就是与sigmoid函数相乘,得出的数值在[0, 1]之间。
数学公式:
KaTeX parse error: No such environment: split at position 7: \begin{̲s̲p̲l̲i̲t̲}̲ z_{t} &= \sigm…
2、重置门(reset gate)
主要功能:
决定有多少历史信息不能继续传递到下一时刻。同更新门的数据处理一样,将前一时刻和当前时刻的信息分别进行线性变换,也就是分别右乘权重矩阵,然后相加后的数据送入重置门,也就是与sigmoid函数相乘,得出的数值在[0, 1]之间。只是两次的权重矩阵的数值和用处不同。
数学公式:
KaTeX parse error: No such environment: split at position 7: \begin{̲s̲p̲l̲i̲t̲}̲ r_{t} &= \sigm…
3、利用重置门重置记忆信息
GRU不再使用单独的记忆细胞存储记忆信息,而是直接利用隐藏单元记录历史状态。利用重置门控制当前信息和记忆信息的数据量,并生成新的记忆信息继续向前传递。
KaTeX parse error: No such environment: split at position 7: \begin{̲s̲p̲l̲i̲t̲}̲
\tilde{h_{t}} …
如公式(14),因为重置门的输出在区间[0, 1]内,所以利用重置门控制记忆信息能够继续向前传递的数据量,当重置门为0时表示记忆信息全部清除,反之当重置门为1时,表示记忆信息全部通过。
4、利用更新门计算当前时刻隐藏状态的输出
隐藏状态的输出信息由前一时刻的隐藏状态信息ht−1h_{t-1}ht−1和当前时刻的隐藏状态输出hth_{t}ht,利用更新门控制这两个信息传递到未来的数据量。
ht=zt∗ht−1+(1−zt)∗ht~(15) h_{t} = z_{t} \ast h_{t-1} + (1 - z_{t} ) \ast \tilde {h_{t}} \qquad (15) ht=zt∗ht−1+(1−zt)∗ht~(15)

















 447
447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









