




 这篇博客介绍了互联网和HTTP的基本概念,强调了HTTP在客户端和服务器间的作用。此外,讲解了网页的基础知识,包括HTML、CSS和JavaScript的组成,以及如何使用开发者工具检查和解析网页。最后,通过实例展示了爬取网页内容的初步步骤。
这篇博客介绍了互联网和HTTP的基本概念,强调了HTTP在客户端和服务器间的作用。此外,讲解了网页的基础知识,包括HTML、CSS和JavaScript的组成,以及如何使用开发者工具检查和解析网页。最后,通过实例展示了爬取网页内容的初步步骤。
爬虫学习day01
互联网、HTTP概念
互联网
互联网也叫因特网(Internet),是指网络与网络所串联成的庞大网络,这些网络以一组标准的网络协议族相连,连接全世界几十亿个设备,形成逻辑上的单一巨大国际网络。它由从地方到全球范围内几百万个私人的、学术界的、企业的和政府的网络所构成。通过电子、无线和光纤等一系列广泛的技术来实现。这种将计算机网络互相连接在一起的方法可称作“网络互联”,在此基础上发展出来的覆盖全世界的全球性互联网络称为“互联网”,即相互连接在一起的网络。
HTTP
HTTP是一个客户端(用户)和服务器端(网站)之间进行请求和应答的标准。通过使用网页浏览器、网络爬虫或者其他工具,客户端可以向服务器上的指定端口(默认端口为80)发起一个HTTP请求。这个客户端成为客户代理(user agent)。应答服务器上存储着一些资源码,比如HTML文件和图像。这个应答服务器成为源服务器(origin server)。在用户代理和源服务器中间可能存在多个“中间层”,比如代理服务器、网关或者隧道(tunnel)。尽管TCP/IP是互联网最流行的协议,但HTTP中并没有规定必须使用它或它支持的层。
事实上。HTTP可以在互联网协议或其他网络上实现。HTTP假定其下层协议能够提供可靠的传输,因此,任何能够提供这种保证的协议都可以使用。使用TCP/IP协议族时RCP作为传输层。通常由HTTP客户端发起一个请求,创建一个到服务器指定端口(默认是80端口)的TCP链接。HTTP服务器则在该端口监听客户端的请求。一旦收到请求,服务器会向客户端返回一个状态(比如“THTTP/1.1 200 OK”),以及请求的文件、错误信息等响应内容。
HTTP的请求方法有很多种,主要包括以下几个:
GET:向指定的资源发出“显示”请求。GET方法应该只用于读取数据,而不应当被用于“副作用”的操作中(例如在Web Application中)。其中一个原因是GET可能会被网络蜘蛛等随意访问。
HEAD:与GET方法一样,都是向服务器发出直顶资源的请求,只不过服务器将不会出传回资源的内容部分。它的好处在于,使用这个方法可以在不必传输内容的情况下,将获取到其中“关于该资源的信息”(元信息或元数据)。
POST:向指定资源提交数据,请求服务器进行处理(例如提交表单或者上传文件)。数据被包含在请求文本中。这个请求可能会创建新的资源或修改现有资源,或二者皆有。
PUT:向指定资源位置上传输最新内容。
DELETE:请求服务器删除Request-URL所标识的资源,或二者皆有。
TRACE:回显服务器收到的请求,主要用于测试或诊断。
OPTIONS:这个方法可使服务器传回该资源所支持的所有HTTP请求方法。用“*”来代表资源名称向Web服务器发送OPTIONS请求,可以测试服务器共能是否正常。
CONNECT:HTTP/1.1 协议中预留给能够将连接改为管道方式的代理服务器。通常用于SSL加密服务器的连接(经由非加密的HTTP代理服务器)。方法名称是区分大小写的。当某个请求所针对的资源不支持对应的请求方法的时候,服务器应当返回状态码405(Method Not Allowed),当服务器不认识或者不支持对应的请求方法的时候,应当返回状态码501(Not Implemented)。
网页基础
网页组成
网页是由 HTML 、 CSS 、JavaScript 组成的。
HTML 是用来搭建整个网页的骨架,而 CSS 是为了让整个页面更好看,包括我们看到的颜色,每个模块的大小、位置等都是由 CSS 来控制的, JavaScript 是用来让整个网页“动起来”,这个动起来有两层意思,一层是网页的数据动态交互,还有一层是真正的动,比如我们都见过一些网页上的动画,一般都是由 JavaScript 配合 CSS 来完成的。
打开 Chrome 浏览器,随便打开某一网页,例如360导航(https://hao.360.com/),按‘F12’ 可以进入开发者模式,选项 Elements 中就是网页的源代码,这里展示的就是 HTML 代码。
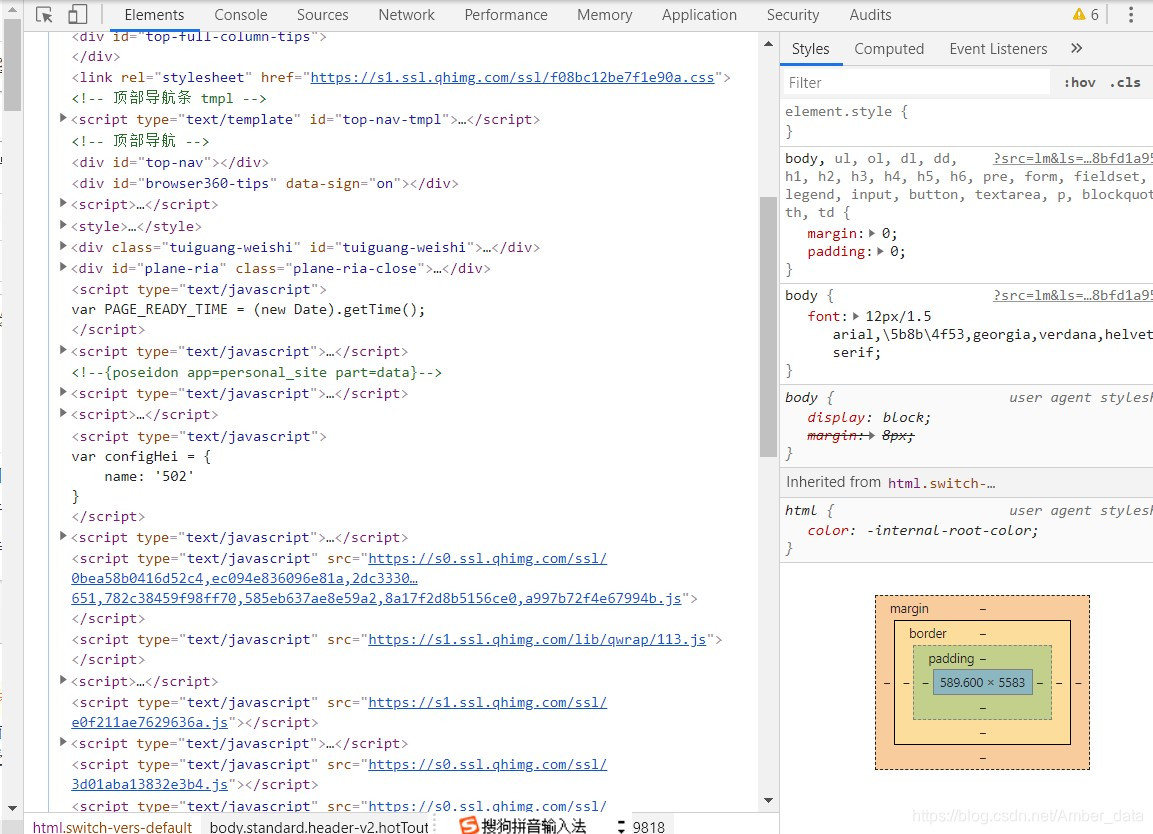
不同类型的文字通过不同类型的标签来表示,如图片用 标签表示,视频用 标签表示,段落用
标签表示,它们之间的布局又常通过布局标签
在右边 Style 标签页中,显示的就是当前选中的 HTML 代码标签的 CSS 层叠样式,“层叠”是指当在HTML中引用了数个样式文件,并且样式发生冲突时,浏览器能依据层叠顺序处理。“样式”指网页中文字大小、颜色、元素间距、排列等格式。
而 JavaScript 就厉害了,它在 HTML 代码中通常使用
网页结构
这里我们手写一个简单 HTML 页面来直观感受下。
首先创建一个文本文件,写入如下内容,再将后缀名改为 .html ,比如demo.html。
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Demo</title>
</head>
<body>
<div id="container">
<div class="wrapper">
<h1>Hello World</h1>
<div>Hello Python.</div>
</div>
</div>
</body>
</html>
首先,整个文档是以 DOCTYPE 来开头的,这里定义了文档类型是 html ,整个文档最外层的标签是 ,并且结尾还以 来表示闭和。
整个 HTML 文档一般分为 head 和 body 两个部分,在 head 头中,我们一般会指定当前的编码格式为 UTF-8 ,并且使用 title 来定义网页的标题,这个会显示在浏览器的标签上面。
大多数原色的属性以“名称-值”的形式成对出现,由“=”连接并写在开始标签元素名之后。值一般由单引号或双引号包围,有些值的内容包含特定字符,在html中可以去掉引号。不加引号的属性值被认为是不安全的。要注意的是,许多元素存在一些共同的属性:
id 属性为元素提供在全文档内的唯一标识。它用于识别元素,以便样式表可以改变其外观属性,脚本可以改变、显示或删除其内容或格式化。对于添加到页面的url,它为元素提供了一个全局唯一识别,通常为页面的子章节。
class 属性提供了一种将类似元素分类的方式,常被用于语义化或格式化。例如,一个html文档可以指定class="标记"来表明所有具有这一类值得元素都属于文档的主文本。格式化后,这样的元素可能会聚集在一起,并作为页面脚注而不会出现在html代码中。类值也可以多值声明。如class="标记 重要"将元素同时放入“标记”与“重要”两类中。
style 属性可以将表现性质赋予一个特定原色。比起使用id或class属性从样式表中选择元素,“style”被认为是一个更好的做法。
tile 属性用于给元素一个附加的说明。大多数浏览器中这一属性显示为工具提示。
如上的demo.html页面显示如下:

HTML DOM
在 HTML 中,所有标签定义的内容都是节点,它们构成了一个 HTML DOM 树。
根据 W3C 的 HTML DOM 标准,HTML 文档中的所有内容都是节点:
整个文档是一个文档节点
每个 HTML 元素是元素节点
HTML 元素内的文本是文本节点
每个 HTML 属性是属性节点
注释是注释节点
HTML DOM 将 HTML 文档视作树结构。这种结构被称为节点树:
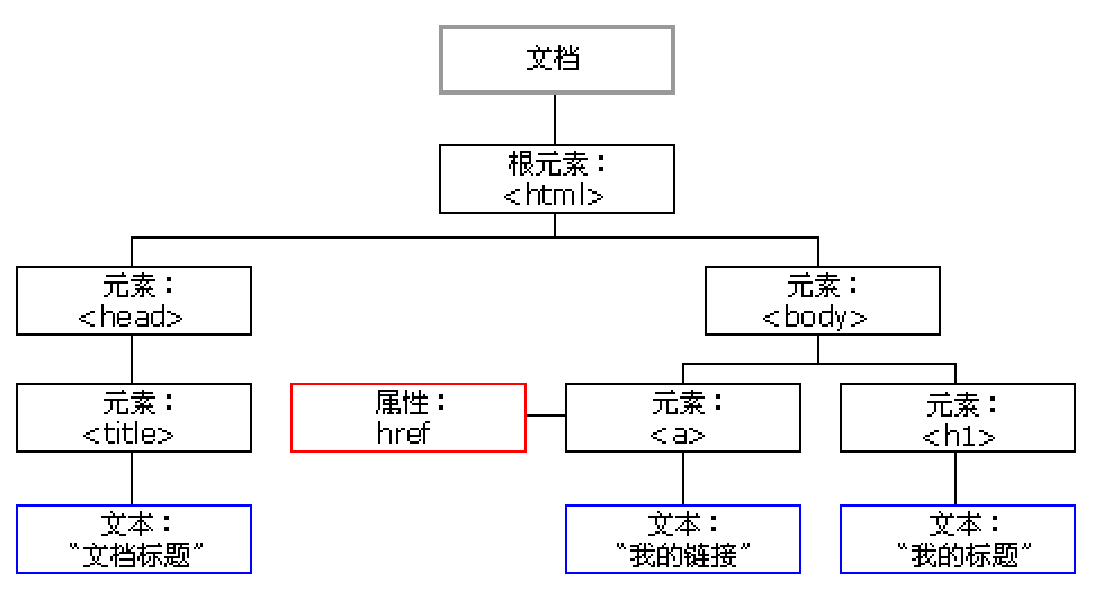
通过 HTML DOM,树中的所有节点均可通过 JavaScript 进行访问。所有 HTML 元素(节点)均可被修改,也可以创建或删除节点。
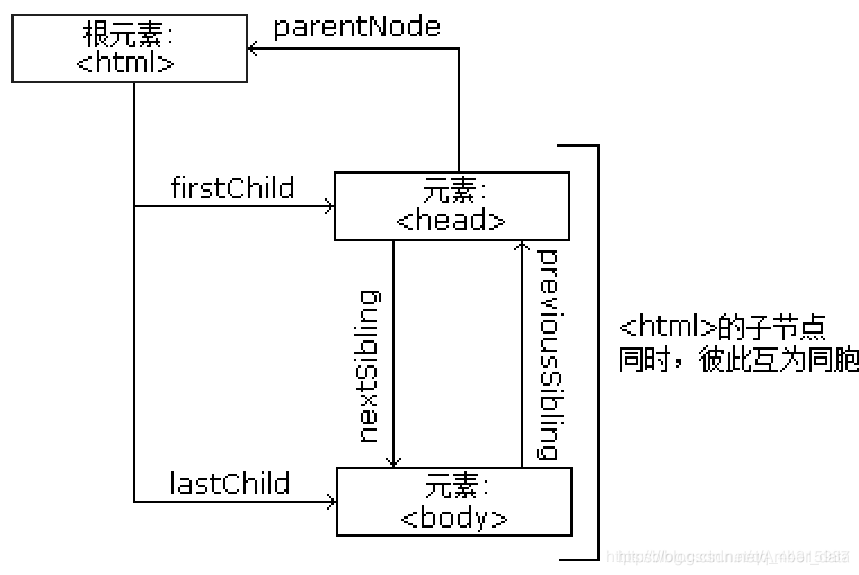
节点树中的节点彼此拥有层级关系。
父(parent)、子(child)和同胞(sibling)等术语用于描述这些关系。父节点拥有子节点。同级的子节点被称为同胞(兄弟或姐妹)。
在节点树中,顶端节点被称为根(root)
每个节点都有父节点、除了根(它没有父节点)
一个节点可拥有任意数量的子
同胞是拥有相同父节点的节点
下面的图片展示了节点树的一部分,以及节点之间的关系:
前面我们介绍到 CSS 可以用来美化网页,那么我们简单加一点 CSS 修改下页面的显示效果,修改如下:
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<title>Demo</title>
<style type="text/css">
.wrapper {
text-align: center;
}
</style>
</head>
<body>
<div id="container">
<div class="wrapper">
<h1>Hello World</h1>
<div>Hello Python.</div>
</div>
</div>
</body>
</html>
我们在 head 中添加了 style 标签,并注明其中的内容解析方式为 CSS 。增加CSS的页面效果:

原来居左的文字已经居中显示了。
CSS 可以修饰文档结构。
在CSS中,我们使用CSS选择器来定位节点。例如,上例中 div 节点的 id 为 container ,那么就可以表示为 #container ,其中 # 开头代表选择 id ,其后紧跟 id 的名称。另外,如果我们想选择 class 为 wrapper 的节点,便可以使用 .wrapper ,这里以点 . 开头代表选择 class ,其后紧跟 class 的名称。
另外, CSS 选择器还支持嵌套选择,各个选择器之间加上空格分隔开便可以代表嵌套关系,如 #container .wrapper p 则代表先选择 id 为 container 的节点,然后选中其内部的 class 为 wrapper 的节点,然后再进一步选中其内部的 p 节点。另外,如果不加空格,则代表并列关系,如 div#container .wrapper p.text 代表先选择 id 为 container 的 div 节点,然后选中其内部的 class 为 wrapper 的节点,再进一步选中其内部的 class 为 text 的 p 节点。这就是 CSS 选择器,其筛选功能还是非常强大的。
爬虫小程序
想要爬取网页内容,需要经过检查目标网页–>解析网页–>编写程序三个阶段。
使用开发者工具检查网页
如果想要编写一个爬取网页内容的爬虫程序,在动手编写前,最重要的准备工作可能就是检查目标网页了。下面以Chrome为例,看看如何使用开发者工具。以python官网的“python之禅”为例,首先在Chrome中打开https://www.python.org/dev/peps/pep-0020/ ,可以选择“菜单”中的“更多工具”–>“开发者工具”,也可以直接在网页内容中右击并选择“检查”选项,还可以按f12键。效果如下图所示。
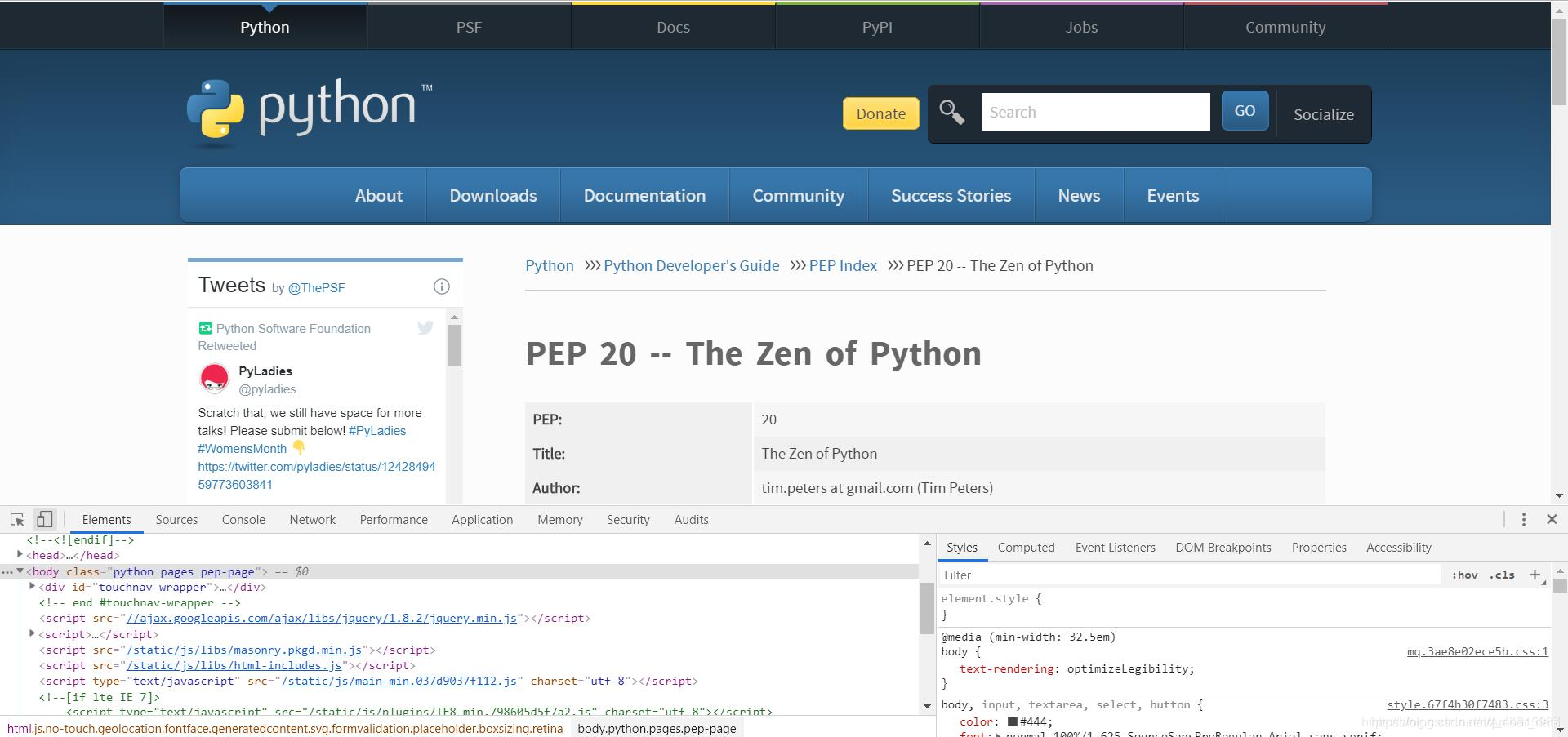
Chrome的开发者模式为用户提供了下面几组工具。
Elements:允许用户从浏览器的角度来观察网页,用户可以借此看到Chrome渲染页面所需要的HTML、CSS和DOM(Document Object Model)对象。
Network:可以看到网页向服务气请求了哪些资源、资源的大小以及加载资源的相关信息。此外,还可以查看HTTP的请求头、返回内容等。
Source:即源代码面板,主要用来调试JavaScript。
Console:即控制台面板,可以显示各种警告与错误信息。在开发期间,可以使用控制台面板记录诊断信息,或者使用它作为shell在页面上与JavaScript交互。
Performance:使用这个模块可以记录和查看网站生命周期内发生的各种事情来提高页面运行时的性能。
Memory:这个面板可以提供比Performance更多的信息,比如跟踪内存泄漏。
Application:检查加载的所有资源。
Security:即安全面板,可以用来处理证书问题等。
解析网页
在“Element”面板中,开发者可以检查和编辑页面的HTML与CSS。选中并双击元素就可以编辑元素了,比如将“python”这几个字去掉,右键该元素,选择“Delete Element”,效果如下图所示:
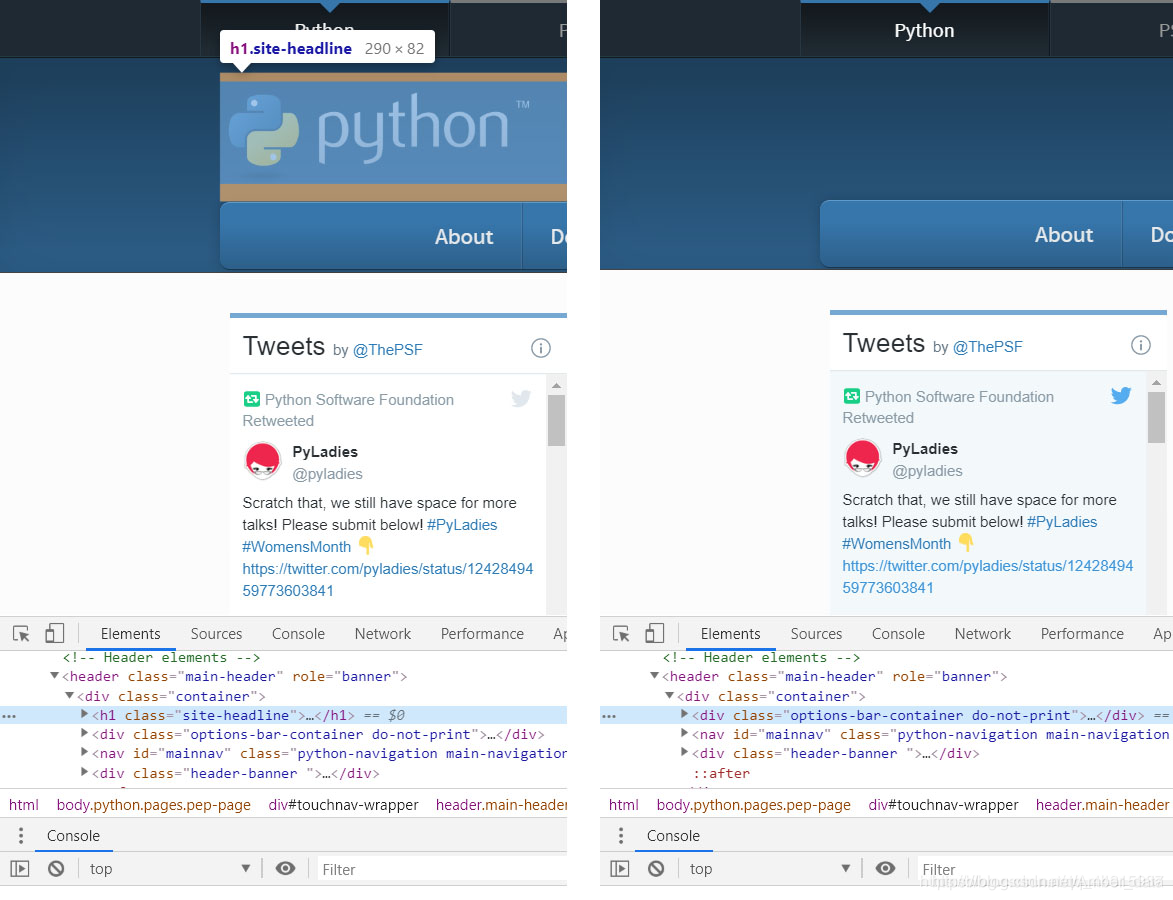
右击后还有很多操作,值得一提的是快捷菜单中的“Copy XPath”选项。由于XPath是解析网页的利器,因此Chrome中的这个功能对于爬虫程序编写而言就显得十分实用和方便了。
使用“Network”工具可以清楚地查看网页加载网络资源地过程和相关信息。请求的每个资源在“Network”表格中显示为一行,对于某个特定的网络请求,可以进一步查看请求头、响应头及已经返回的内容等信息。对于需要填写并发送表单的网页而言(比如执行用户登录操作,以百度贴吧为例),在“Network”面板勾选“Preserve log”复选框,然后进行登录,就可以记录HTTP POST信息,查看发送的表单信息详情。之后在贴吧首页开启开发者工具后再登录时,就可以看到下图所示的信息,其中“Form Data”就包含向服务器发送的表单信息详情。

另外“Network”中的“Preview”也是比较常用,可以用来预览数据。
爬取python之禅
第一种:requests.get方法
#第一种方法
import requests
url = 'https://www.python.org/dev/peps/pep-0020/'
res = requests.get(url)
text = res.text
#print(text)
#爬取python之禅并存入txt文件
with open('zon_of_python.txt','w') as f:
f.write(text[text.find('<pre')+28:text.find('</pre>')-1])
print(text[text.find('<pre')+28:text.find('</pre>')-1])
第二种:使用python自带的urllib库
#第二种方法
import requests
import urllib
url = 'https://www.python.org/dev/peps/pep-0020/'
res = requests.get(url)
text = res.text
url = 'https://www.python.org/dev/peps/pep-0020/'
res = urllib.request.urlopen(url).read().decode('utf-8')
print(res[res.find('<pre')+28:text.find('</pre>')-1])
urllib是python3的标准库,包含了很多基本功能,比如向网络请求数据、处理cookie、自定义请求头等。但是由上面可以看出,就代码量而言,urllib的工作量比Requests要大,而且不甚简洁
金山词霸翻译Python之禅
#用金山词霸来翻译python之禅
import requests
def translate(word):
url = 'http://fy.iciba.com/ajax.php?a=fy'
data = {
'f':'auto',
't':'auto',
'w':word,
}
headers = {'user-agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/80.0.3987.163 Safari/537.36'}
response = requests.post(url,data=data,headers=headers) #发起请求
json_data = response.json() #获取json数据
#print(json_data)
return json_data
def run(word):
result = translate(word)['content']['out']
print(result)
return result
def main():
with open('zon_of_python.txt') as f:
zh = [run(word) for word in f]
with open('zon_of_python_zh-CN.txt','w') as g:
for i in zh:
g.write(i + '\n')
if __name__=='__main__':
main()
爬取豆瓣热门电影
首先,打开豆瓣网页,按f12进入开发者模式,点击“Network”,可以看到网页,查看网页结构,观察电影名在哪个标签里,如下

import requests
from lxml import etree
class Spider(object):
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.110 Safari/537.36",
"Referer": "https://movie.douban.com/top250"
}
def start_request(self):
response = requests.get("https://movie.douban.com/top250", headers=self.headers)
html = etree.HTML(response.content.decode())
film = html.xpath('//*[@id="content"]/div/div[1]/ol/li') # 拿到所有的li标签
self.log_data(film)
def log_data(self, film):
for div in film:
film_name = div.xpath('./div/div[2]/div[1]/a/span[1]/text()')[0] # [0]的u作用 因为获取到的事list列表所以用这个来获取str
film_score = div.xpath('./div/div[2]/div[2]/div/span[2]/text()')[0]
film_msg = div.xpath('./div/div[2]/div[2]/p[2]/span/text()')[0]
print('{} {} {}'.format(film_name, film_score, film_msg)) # 格式化输出
spider = Spider()
spider.start_request()
爬取结果:


















 1203
1203

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









