




Apache Paimon-流数据湖
1、概述
1.1、核心功能
1、统一批处理和流处理:Paimon支持批写和批读,以及流式写更改和流式读表更改日志。
2、数据湖:Paimon具有成本低、可靠性高、元数据可扩展等优点,具有数据湖存储的所有优势。
3、合并引擎:Paimon支持丰富的合并引擎。缺省情况下,保留主键的最后一项记录,可以“部分更新”或“聚合”。
4、变更日志生成:Paimon支持丰富的Changelog producer例如“lookup”和“full-compaction”,可以从任何数据源生成正确且完整的变更日志从而简化流管道的构建。
5、丰富的表类型: 除了主键表,Paimon还支持append-only只追加表,自动压缩小文件,并提供有序的流读取来替换消息队列。
6、模式演化:支持完整的模式演化,例如可以重新命名列和重新排序。
1.2、适合场景
Apache Paimon 适用于需要在流数据上进行实时查询和分析的场景。它可以帮助用户更容易地构建流式数据湖,实现高吞吐、低延迟的数据摄入、流式订阅以及实时查询能力。例如在金融、电子商务、物联网等行业中,可以使用 Apache Paimon 来实现实时推荐、欺诈检测、异常检测等应用。
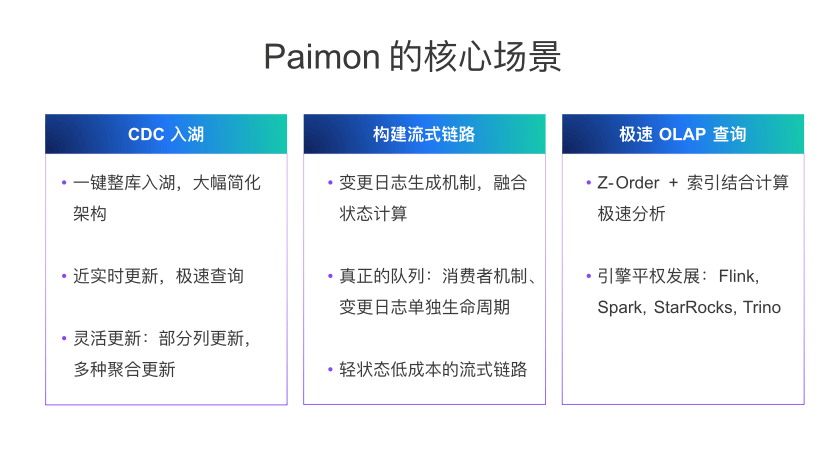
(1)CDC入湖
Paimon 对此做了相当多的优化,来保证更简化的架构、更好的性能与实时性。具体有:一键整库入湖,大幅简化架构;也可达到实时更新、极速查询的场景,且在此基础上成本不高;可以灵活更新,定义部分列更新、多种聚合更新。
(2)构建流式链路
可以用 Paimon 来构建完整的 Streaming 链路,有以下几个支撑的场景:第一,可生成变更日志,在流读时就能拿到已更新好的全行的 Record 数据,这非常有利于 Streaming 链路的构建;第二,Paimon 也朝着变成真正的队列的方式向前发展,有消费者机制,在最新版本当中,有变更日志单独生命周期管理,可像 Kafka 一样定义更长的变更日志的生命周期,比如 Kafka 保存一天以上或者三天;在此基础上,构成了轻状态低成本的流式链路。
(3)极速OLAP查询
支持多种执行引擎查询。
1.3、架构原理
1.3.1、总体架构
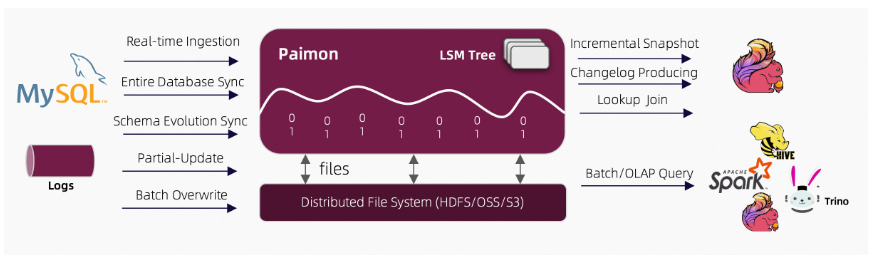
Paimon 创新的结合了湖存储 + LSM + 列式格式 (ORC, Parquet),为湖存储带来大规模实时更新能力
1.3.2、文件布局
表的所有文件都存储在一个基本目录下。Paimon文件以分层的方式组织。下图说明了文件布局。从快照文件开始,Paimon读取器可以递归地访问表中的所有记录。
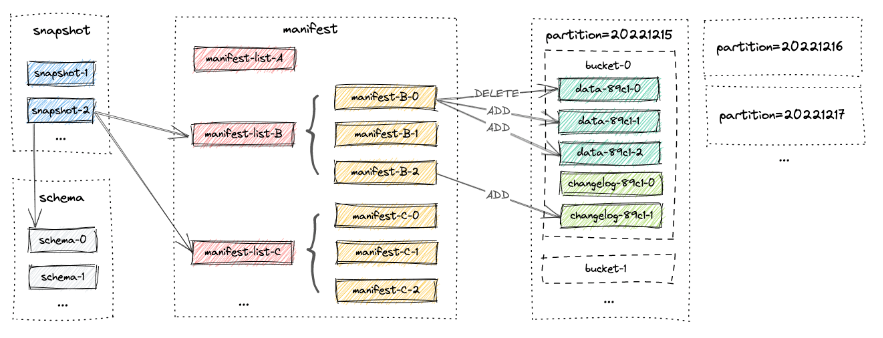
快照文件 :所有快照文件都保存在快照目录下。快照文件是一个JSON文件,其中包含有关该快照的信息,包括架构文件使用包含此快照的所有更改的清单列表。
Manifest文件:所有清单列表和清单文件都存储在manifest目录中。清单列表是清单文件名的列表,清单文件是包含有关LSM数据文件和更改日志文件的更改的文件。例如在相应的快照中创建了哪个LSM数据文件,删除了哪个文件。
数据文件:数据文件按分区和桶分组。每个桶目录包含一个LSM树及其变更日志文件。目前,Paimon支持使用orc(默认)、parquet和avro作为数据文件格式。
LSM树:Paimon采用LSM树(日志结构的合并树)作为文件存储的数据结构。数据文件中的记录按其主键排序;在Sorted Runs中,数据文件的主键范围从不重叠。不同Sorted Runs可能有重叠的主键范围,甚至可能包含相同的主键。在查询LSM树时,必须将所有Sorted Runs组合起来,并且必须根据用户指定的合并引擎和每条记录的时间戳合并具有相同主键的所有记录。写入LSM树的新记录将首先在内存中进行缓冲。当内存缓冲区已满时,将对内存中的所有记录进行排序并刷新到磁盘。得益于 LSM 数据结构的追加写能力,Paimon 在大规模的更新数据输入的场景中提供了出色的性能。
Sorted Runs:LSM 树将文件组织成多个Sorted Run。Sorted Run由一个或多个数据文件组成,并且每个数据文件恰好属于一个Sorted Run,数据文件中的记录按其主键排序。
合并(Compaction):当越来越多的记录写入LSM树时,Sorted Runs次数将会增加。因为查询LSM树需要将所有Sorted Runs组合在一起,太多的Sorted Runs将导致查询性能差,甚至导致内存不足。为了限制排序运行的次数,必须偶尔将几个Sorted Runs合并为一个大的Sorted Runs,这个过程称为合并或压缩,合并是一个资源密集型过程,它会消耗一定的CPU时间和磁盘IO,因此过于频繁的压缩可能会导致写速度变慢。这是查询性能和写性能之间的权衡。目前,Paimon采用了一种与Rocksdb的通用压实类似的压实策略。默认情况下,当Paimon将记录追加到LSM树时,它还将根据需要执行压缩,还可以选择在专用压缩作业中执行所有压缩。
2、集成FLink和Spark
支持通过Flink SQL对Paimon进行读写操作。下文通过实例介绍Flink SQL对Paimon进行读写操作。
2.1、Flink SQL集成Paimon
2.1.1、Catalog配置
通过Flink SQL对Paimon进行读写操作的三种方法:Filesystem Catalog、Hive Catalog和DLF Catalog:
启动FLink SQL:
sql-client.sh
(1)Filesystem Catalog
Filesystem Catalog仅将元数据保存在文件系统或对象存储中。
(需要注意的是:如果warehouse是首次制定,会在当前sql session中创建;如果是非首次,会在当前sql session中映射出之前首次创建Catalog)
CREATE CATALOG test_catalog WITH (
'type' = 'paimon',
'metastore' = 'filesystem',
'warehouse' = 'oss://<yourBucketName>/warehouse'
) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3907
3907

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









