




2021 年,Gartner 取消了发布多年的元数据管理魔力象限,取而代之的是主动元数据市场指南。Gartner 断言,数据管理的焦点已经从数据内容管理向元数据管理升级,而主动元数据是让数据管理更自动更智能的关键,这开启了业界对元数据管理发展趋势的新思考。
企业数据管理日益复杂化,尤其是对数字化程度较高的企业而言,业务用数已经成为常态,进而导致了数据更加分散——数据的生产和消费被分散到不同部门或分支机构建设,甚至存储在不同的数据源中,最终导致数据链路的复杂性日益增加,数据链路“看不清、管不住、治不动”矛盾越来越突出。
企业数据链路层次变得越来越难以管控,上游数据的变化很难被下游及时准确感知。通常情况下,只有在下游出现问题后,相关人员才会向上游追溯发现数据已发生变化或异常。
数据管理挑战十分明确且亟待解决,Aloudata BIG 作为全球首个实现算子级血缘解析的主动元数据平台,其研发目的正是通过技术手段达成数据管理自动化。
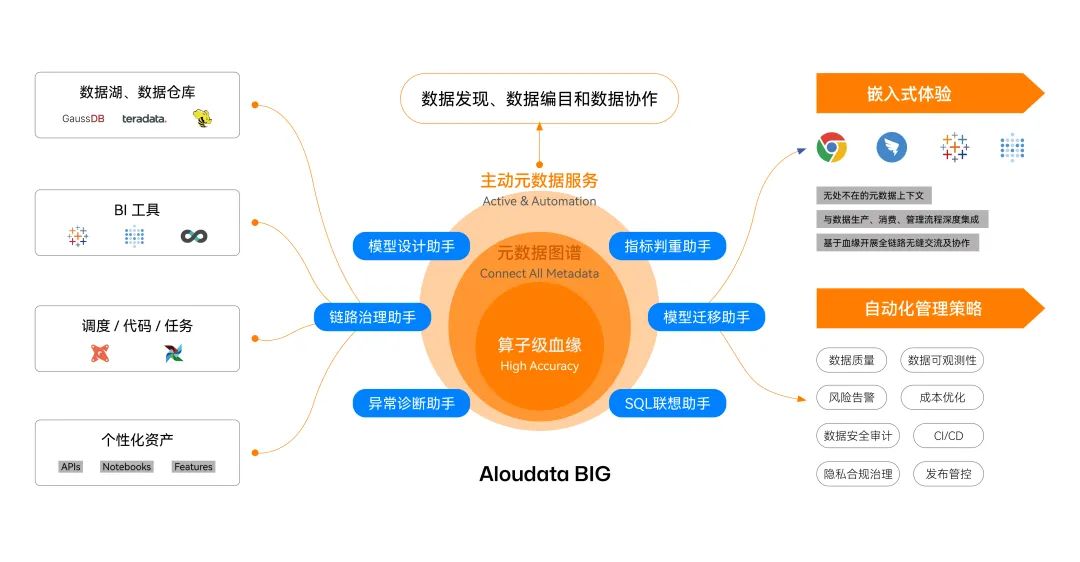
Aloudata BIG 主动元数据平台首先要解决的是企业数据管理的第一个主要难点——数据链路“看不清”的问题,当前数据血缘技术普遍存在不够全、不够准以及不够细的问题,由于无法精细、准确、全面地刻画数据链路,许多企业为了理清监管报送等重点链路的血缘以及各个字段的计算口径,只能耗费巨大人力进行人工盘点。
Aloudata BIG 在数据血缘解析技术上实现了重大突破,彻底根治了现有血缘技术的弊病。
Aloudata BIG 数据血缘的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 805
805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









