



一、正则表达式:匹配的是文本内容(文本三剑客:grep:过滤文本内容 sed:针对文本内容进行增删改查 awk:按行取列)
二、grep:过滤
1.grep:过滤文本内容,作用就是使用正则表达式来匹配文本内容。
grep命令格式:grep -m 1 “bash” /etc/passwd
cat /etc/passwd | grep -m 1 “bash”
grep -m +数字+内容:只取包含内容的那几行
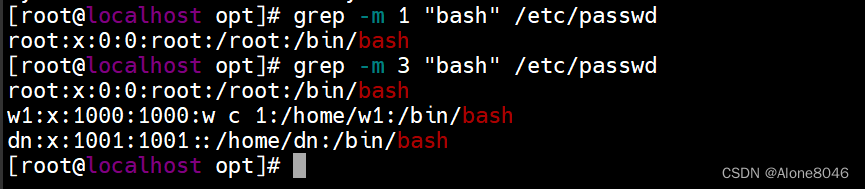 grep -v +内容:(取反)除了此内容所在行不显示,其它都显示
grep -v +内容:(取反)除了此内容所在行不显示,其它都显示
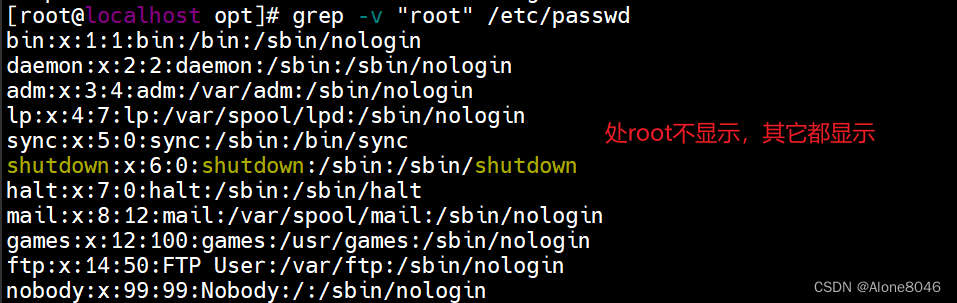 grep -n +内容:显示匹配内容行及其行号
grep -n +内容:显示匹配内容行及其行号
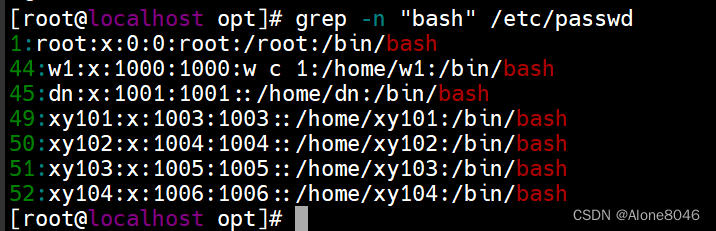 grep -c +内容:只统计匹配内容的总行数
grep -c +内容:只统计匹配内容的总行数
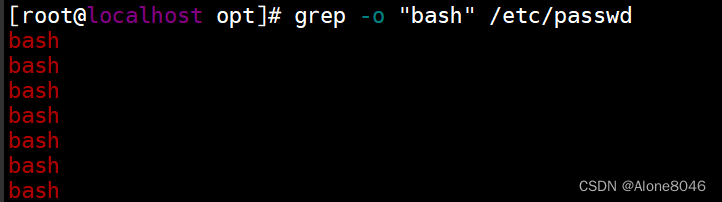
 grep -o +内容:只显示匹配内容的结果
grep -o +内容:只显示匹配内容的结果
 grep -q +内容:静默模式,不输出任何信息
grep -q +内容:静默模式,不输出任何信息
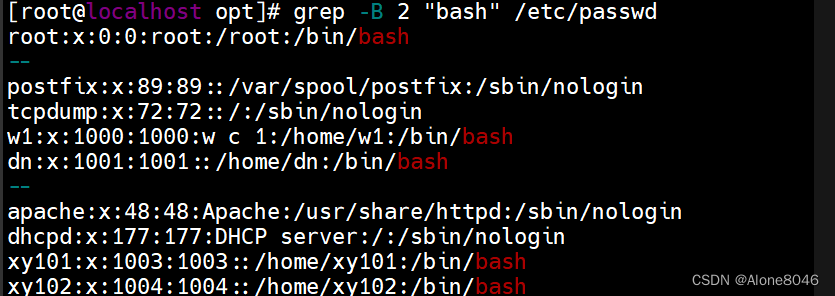
 grep -A 数字+内容:匹配文件内所属内容及内容的下几行
grep -A 数字+内容:匹配文件内所属内容及内容的下几行
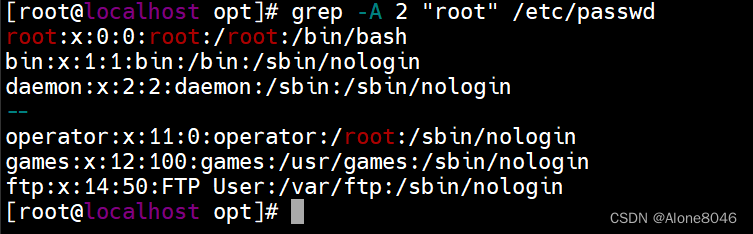 grep -B 数字+内容:匹配文件内容及内容的上几行
grep -B 数字+内容:匹配文件内容及内容的上几行
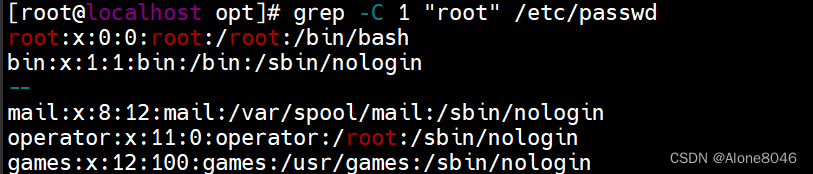
 grep -C 数字 +内容 :匹配文件内容及内容的上下几行
grep -C 数字 +内容 :匹配文件内容及内容的上下几行
 grep -e 内容 -e 内容:逻辑或,实现多个内容查找
grep -e 内容 -e 内容:逻辑或,实现多个内容查找

grep -E或egrep :都是正则表达式,省略表示次数命令繁琐的斜杠
grep -f 脚本1 脚本2:匹配两个不同脚本内相同的内容

grep -r:递归目录下的文件内容,不包含软连接
grep -R:递归目录下,所有包含过滤内容的文件以及匹配的内容行,包括软连接
2.sort:以行为单位对文件内容进行排序
格式:sort -选项 文本
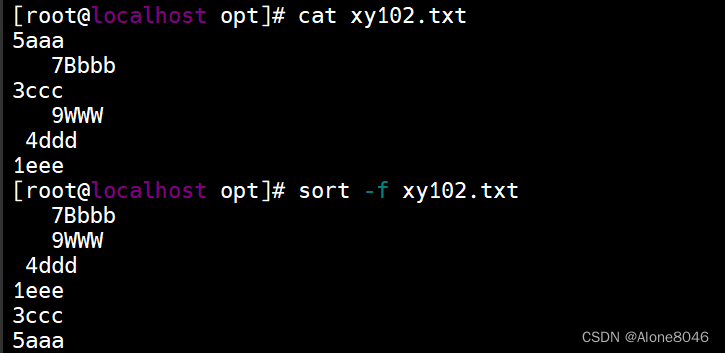
sort -f :忽略大小写,默认会把大写字母排在前面
sort -b:忽略每行的空格进行排序(有空格不影响排序)
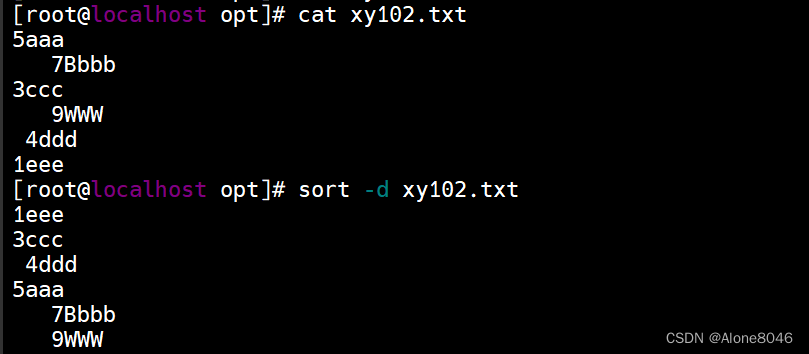
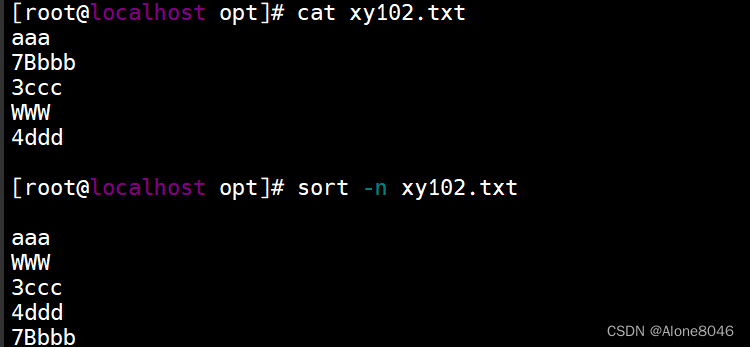
sort -n : 按照数字优先排序(类似-b)
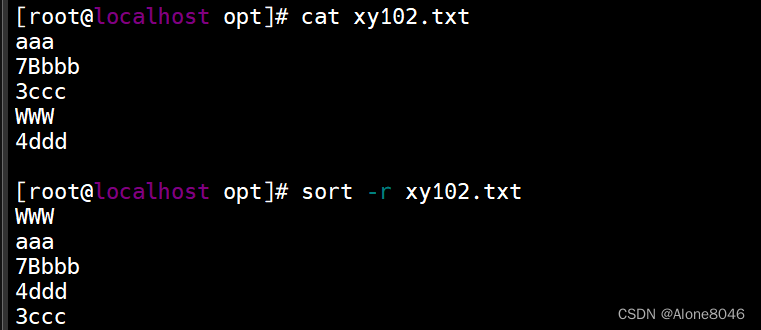
sort -r :反向排序
sort -u:去重,不连续相同的数据只显示一行
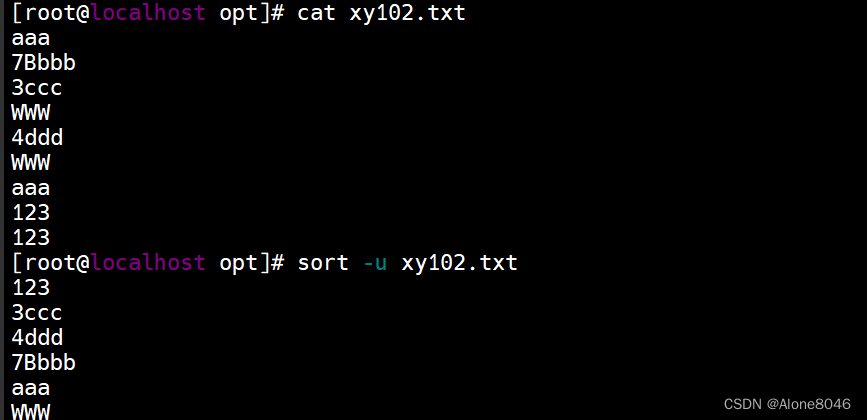
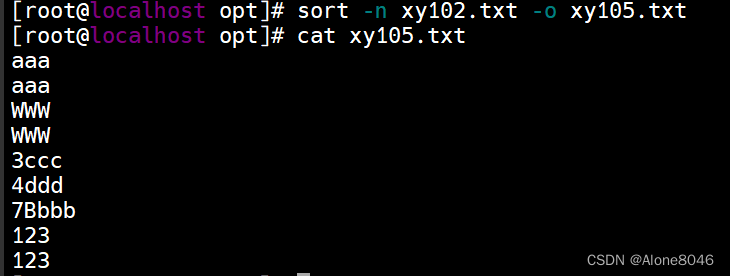
sort -n 文件1 -o 文件2 :把排序后的结果输出到指定文件
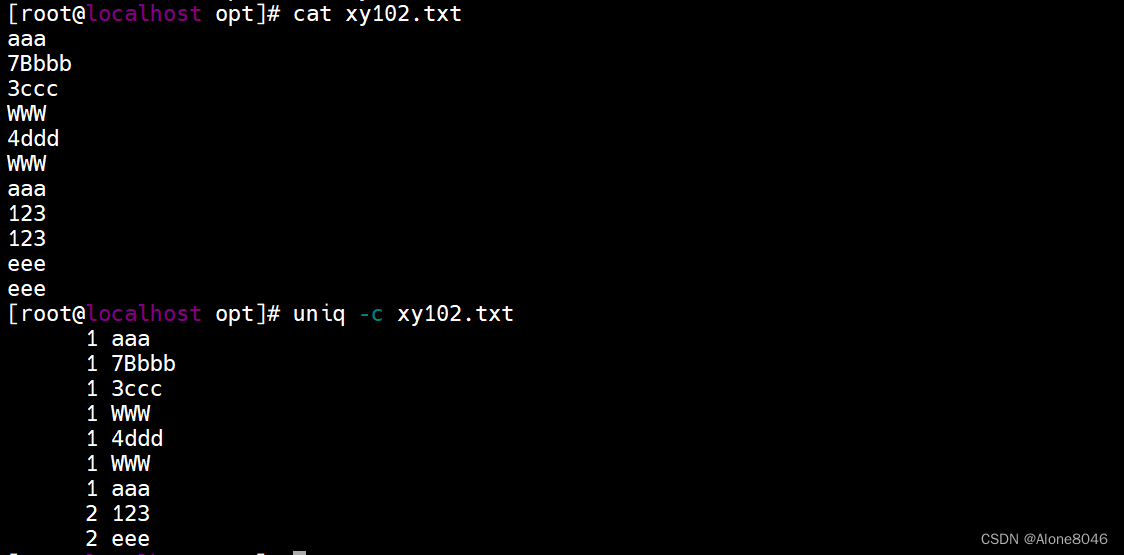
3.uniq:去除连续重复的行只显示一行
uniq -c:合并连续重复的行,不连续的不合并,并且统计重复行的次数
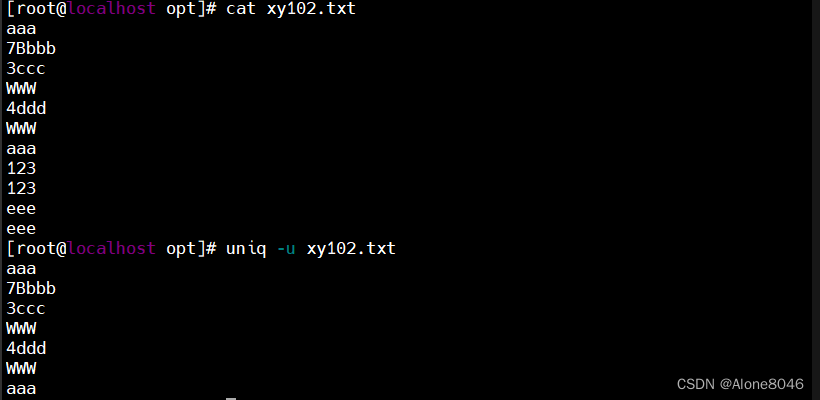
uniq -u :显示仅出现一次的行(包括不连续的重复行)
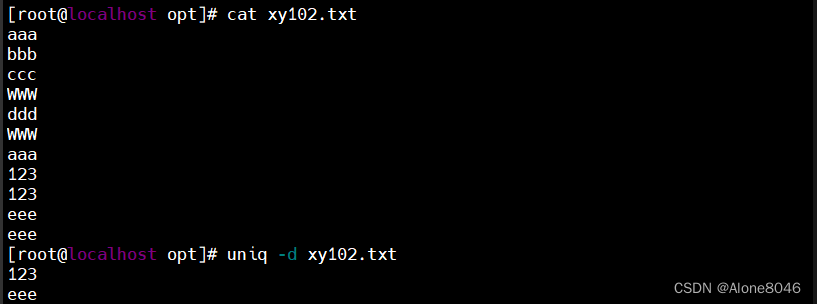
uniq -d : 仅显示重复出现的行(必须是连续的行)
4.tr:用来对标准输出的字符进行替换、压缩、删除
tr -c:保留字符集1的字符,其它的字符用字符集2来进行替换,并且会默认多打印一个字符

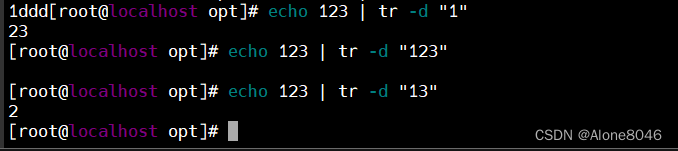
tr -d:删除字符
tr -s:把连续重复出现的字符串压缩为一个字符,也可以替换字符集

5.cut:对字段进行截取和剪裁
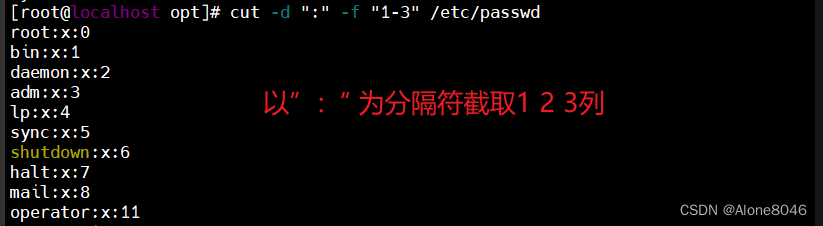
cut -d:指定分隔符
cut -f:对字段进行截取
cut -b :以字节为单位截取(不常用)
cut -c:以字符为单位截取(不常用)
head -n1 /etc/passwd:只显示文本的第一行

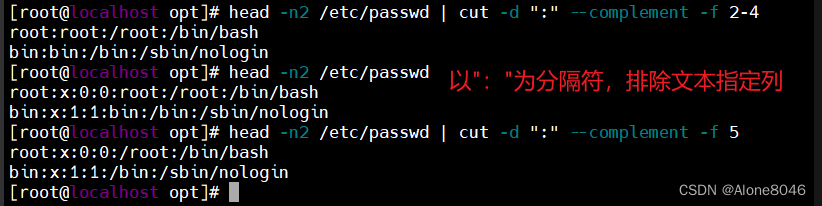
cut --complement :排除所指定的字段再输出
cut --output -delimiter:更改原内容的分隔符

6.split:对文件进行分割,把文件拆分成若干个小文件
split -l:指定行数进行拆分
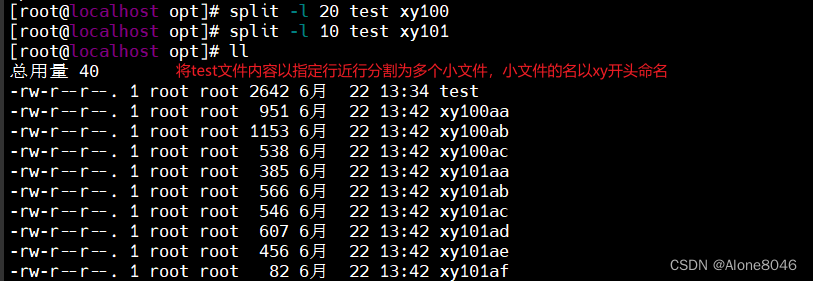
split -b:指定文件大小进行拆分

面试题:如果现在有一个日志文件,有5G大小,能不能快速的进行打开
回复:这种文件推荐使用split按大小进行拆分
7.paste、cat对文件进行合并
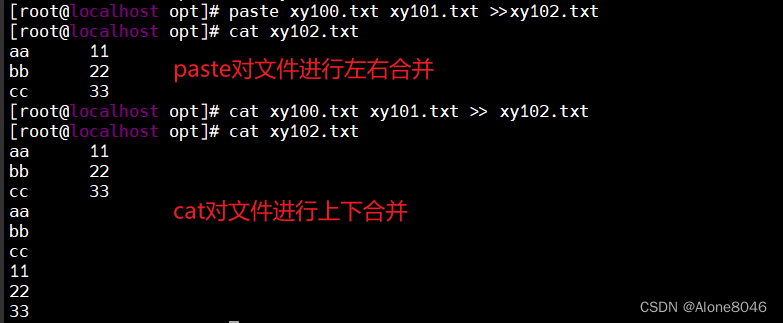
paste与cat区别:paste以左右合并,cat以上下合并。
8.统计当前主机的连接状态:有多少个LISTEN 有多少个 ESTAB
ss -antp:查看当前主机的连接状态
grep -v "^State" :过滤掉State行
cut -d " " -f 1 :以空格为分隔符截取文件的第一列
sort :对文件进行排序
uniq -c :合并重复出现的行,并且统计重复出现行的次数

三、1.正则表达的作用:由一类特殊字符以及文本字符所编写的一个模式,模式又来匹配文件当中的内容(字符)。主要匹配的是文件内容及命令结果。
2.通配符(* ? [ ]):只能用于匹配文件名和目录名,不能匹配文件内容和命令结果。
* :匹配任意一个或多个字符

?:匹配任意一个字符

[ ]:匹配指定范围内任意一个单个字符

3.基本正则表达式:
3.1元字符(字符匹配)
“.”(点) :任意单个字符

" \. ":转义符(恢复其本意,点就是点不代表任意字符)
[ ] :匹配指定范围内的任意单个字符
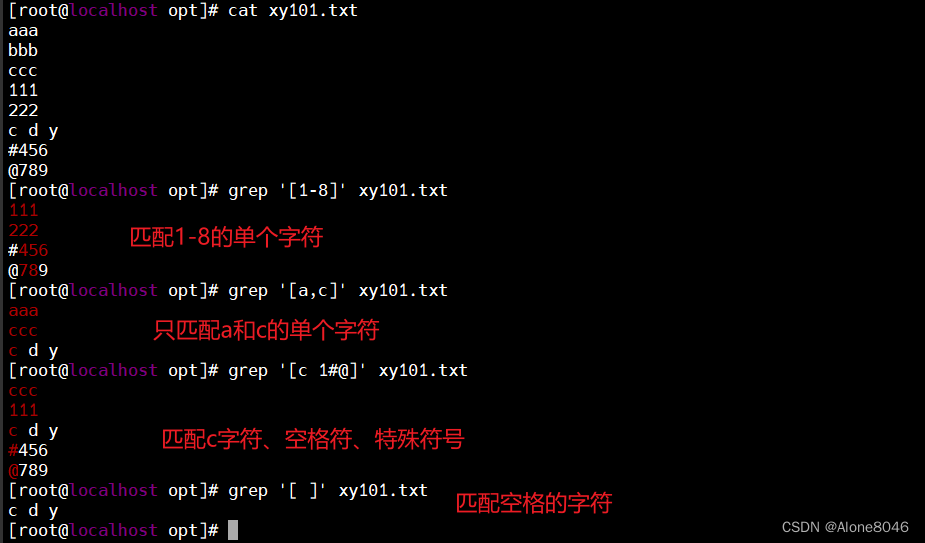 [^ ]:匹配指定范围外的任意单个字符
[^ ]:匹配指定范围外的任意单个字符
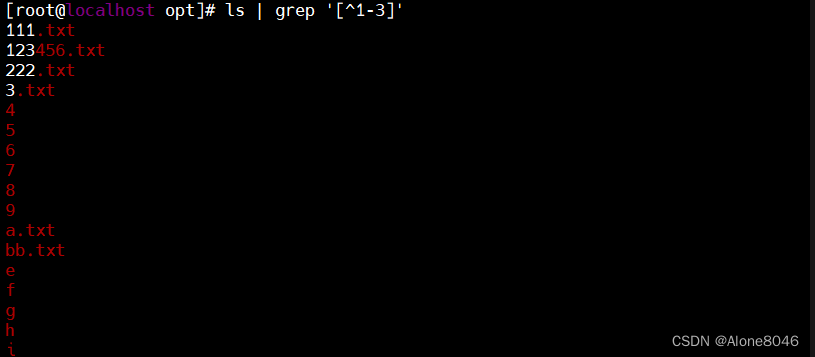
3.2表示次数:匹配字符出现的次数
* :匹配前面的字符任意次,包括0次,尽可能长的匹配
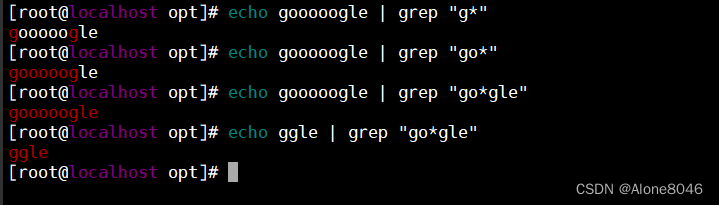
.* :匹配前面的字符至少要有一次

\?:匹配前面的字符0次或1次,可有可无
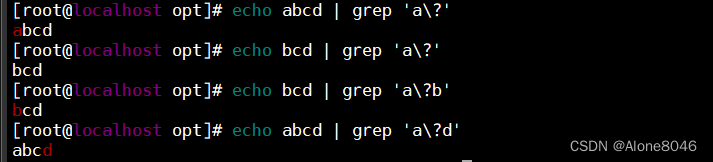
\+ :匹配前面的字符至少要出现一次

















 1638
1638

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









