



 这篇博客详细介绍了MySQL InnoDB存储引擎的锁机制,包括锁的基本概念、行锁和表锁(意向锁)的类型及差异。重点讨论了行锁的三种形式:共享锁、排它锁以及它们在不同场景下的应用。此外,还深入解析了锁的原理,如为何没有索引时会锁住整张表,以及如何通过主键索引理解行锁的实现。
这篇博客详细介绍了MySQL InnoDB存储引擎的锁机制,包括锁的基本概念、行锁和表锁(意向锁)的类型及差异。重点讨论了行锁的三种形式:共享锁、排它锁以及它们在不同场景下的应用。此外,还深入解析了锁的原理,如为何没有索引时会锁住整张表,以及如何通过主键索引理解行锁的实现。
一、锁
1.基本概念
MySQL的锁是为了解决资源竞争的问题,Java 里面的资源是对象,数据库的资源就是数据表或者数据行。所以锁是用来解决事务对数据的并发访问的问题的。
InnoDB锁有两种
- 表锁(意向锁,Intention Locks)
- 意向共享锁(Intention Shared Locks)
- 意向排它锁(Intention Exclusive Locks)
- 行锁
- 共享锁(Shared Locks)
- 排它锁(Exclusive Locks)
行锁的算法:
- 记录锁
- 间隙锁
- 临键锁
表锁与行锁对比:
-
锁定粒度:表锁 > 行锁
-
加锁效率:表锁 > 行锁
因为表锁只管锁住整张表,而行锁还要检索这一行数据再加锁
-
冲突概率:表锁 > 行锁
锁住一张表的时候,其他任何一个事务都不能操作这张表。但是
锁住一行数据的时候,其他的事务还可以来操作其他没有被锁的行
-
并发性能:表锁 < 行锁
2.行锁
1.共享锁(shared Locks)
简称S锁,也称读锁,多个事务对于同一数据可以共享一把锁,都能访问到数据,但是只能读不能修改。
# 加读锁方式
select .... LOCK IN SHARE MODE;
释放锁方式:事务结束(提交或其他终止事务方式),锁自动释放
2.排它锁(exclusive locks)
简称X锁,也称写锁,只要一个事务获取了一行数据的排它锁,其他的事务就不能再获取这一行数据的共享锁和排它锁。
加锁方式:
- 操作数据时(增删改),会自动加上一个排它锁
- 手动加锁
# 手动加锁
UPDATE .... FOR UPDATE
3.表锁(意向锁)
表锁有两个:
- 意向共享锁
- 意向排它锁
表锁是由数据库自己维护的:
- 给一行数据加上S锁之前,数据库会自动在这张表上加一个意向共享锁
- 给一行数据加上X锁之前,数据库会自动在这张表上加一个意向排他锁
表锁的意义
可以把InnoDB里面的表锁理解成一个标志。
如果说没有意向锁的话,当准备给一行数据加上排他锁的时候:
- 首先要去判断有没其他的事务锁定了其中了某些行
- 那么这个时候就要去扫描整张表才能确定这行数据能不能加排它锁
- 如果数据量特别大,比如有上千万的数据的时候,加锁的效率就会很低
但是引入了意向锁之后就不一样了。只要判断这张表上面有没有意向锁,如果有,就直接返回失败。如果没有,就可以加锁。
二、锁的原理
了解了锁的类型,那么现在考虑一下锁到底锁住了什么?是一行数据,还是一个字段,还是其他什么别的东西?
1.假设
假如现在有三张表:
- 没有索引的 t1(int id,varchar name)
- 有主键索引的 t2(int id(PK),varchar name)
- 有唯一索引的t3(int id(PK),varchar name(unique))
假设1——锁的是一行数据
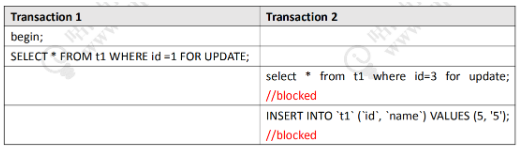
对t1进行操作,开启两个事务:
- 事务1锁住id = 1的数据
- 事务2尝试锁住id = 3的数据
- 如果锁的是一条记录,那么事务2尝试对id = 3数据的加锁应该成功,但是最终失败了,这时尝试在事务2中插入一条新的数据,同样失败了。
这就说明锁住的并不是一条记录,因此假设1不成立。
假设2——锁的是一个字段
对t2进行操作,t2和t1字段一样,只不过id设为了主键,开启两个事务:
- 事务1锁住id = 1的数据
- 事务2尝试对id = 1的数据再次加锁,发现加锁失败
- 对不同id的数据尝试加锁,发现加锁成功
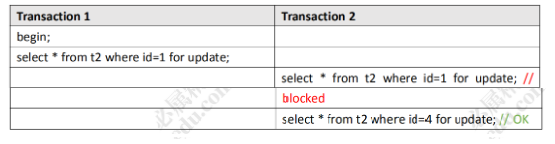
由假设1知道,锁住的并不是一条记录,那么又经由对t2的操作,可以假设:锁的可能是一个字段。
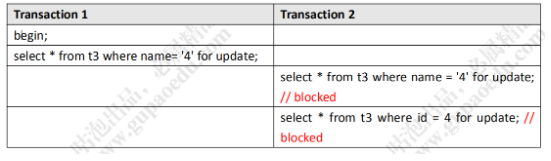
使用t3进行验证
t3在id上创建了一个主键索引,name上创建了一个唯一索引。开启两个事务:
- 事务1使用name字段锁定name = 4的数据
- 事务2尝试再次获取排它锁(一定失败,排它锁只能加一次)
- 然后再使用name = 4这条记录的id尝试获取,发现也失败了
验证后可以发现,锁的也不是字段,如果锁的是字段,那么name锁上并不会影响再给id上锁,所以假设2也失败
2.锁的是主键索引
假设1、假设2中的三张表的区别在于索引,索引导致了加锁的行为差异。所以可以推断,行锁锁的不是记录也不是字段,而是索引。
- 当没有索引的时候,MySQL会选择第一个不包含有 NULL 值的唯一索引作为主键索引
- 如果不存在这样的唯一索引,那么会隐式创建一个rowid作为主键
2.1 为什么假设1中会锁住整张表
因为rowid是一个隐式的主键,并不能被外操作,所以在这种表中,查询没有使用索引,会进行全表扫描,然后把每一个隐藏的rowid(主键索引)都锁住了,即锁住了整个表
2.2 为什么假设2中使用唯一索引也会锁住主键索引
因为唯一索引属于非聚集索引,查询会经过回表走主键索引,所以主键索引最终仍会被锁住
3.行锁算法
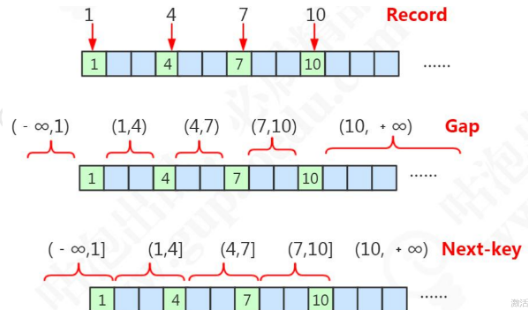
以t2表做演示,假设有4条记录,id分别为{1, 4, 7, 10}
3.1 三种范围的概念
因为锁是加在主键索引上的,所以这里的划分标准也是主键索引的值。
| 范围 | 说明 |
|---|---|
| Record | 数据库中存在的索引值 |
| Gap | 根据Record隔开的数据不存在的区间,是一个左开右开的区间 |
| Next-key | Gap连同它左边的Record,称作临键的区间,是一个左开右闭的区间 |
3.2 记录锁
当查询时,对唯一性的索引(主键索引和唯一索引)使用等值查询,精准匹配到一条记录的时候,这个时候使用的就是记录锁。
比如
SELECT name FROM t2 WHERE id = 1;
这时使用不同的索引去加锁,不会产生冲突,因为它只锁住当前的Record

3.3 间隙锁
当查询的记录不存在,没有命中任何一个Record,无论使用的是等值查询还是范围查询,这时使用间隙锁,锁住的是没有记录的这个区间
比如
SELECT name FROM t2 WHERE id > 4 and id < 7;
**间隙锁只在 RR 事务隔离级别存在。**间隙锁主要是阻塞插入 insert(防止幻读)。相同的间隙锁之间不冲突。

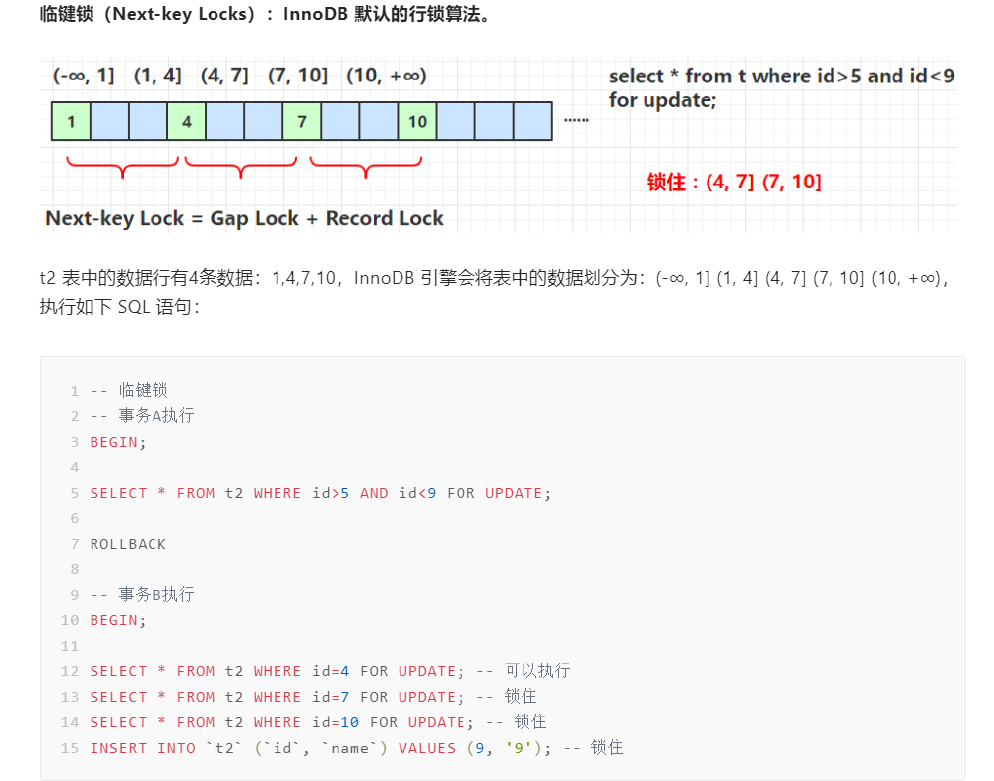
3.4 临键锁
临键锁是MySQL的默认行锁算法,当查询使用了范围查询,不仅命中了Record,还命中了间隙,这时使用的是临键锁,不仅锁住记录,还锁住区间,即:临键锁=记录锁+间隙锁。
幻读问题是在 RR 事务通过临键锁和 MVCC 解决的

















 1949
1949

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









