







Q1.存在重复元素
给定一个整数数组,判断是否存在重复元素。
如果存在一值在数组中出现至少两次,函数返回 true 。如果数组中每个元素都不相同,则返回 false 。
示例 1:
输入: [1,2,3,1]
输出: true
示例 2:
输入: [1,2,3,4]
输出: false
示例 3:
输入: [1,1,1,3,3,4,3,2,4,2]
输出: true
我的解法:
#include<iostream>
#include<vector>
#include<cstdio>
using namespace std;
bool containsDuplicate(vector<int>& nums) {
bool flag = false;
int count[ 100000000 ];
int temp = 0;
memset(count, 0, sizeof(count));
for (int i = 0; i < nums.size(); ++i)
{
temp = (100000000 + nums[i]) % 100000000;
count[temp]++;
if (count[temp] > 1) { flag = true; break; }
}
return flag;
}
int main()
{
int temp = 0;
vector<int> vec;
bool flag=false;
while (scanf_s("%d", &temp) != EOF)
{
vec.push_back(temp);
}
flag=containsDuplicate(vec);
cout << flag;
return 0;
}官方没有这一种方法,但是思路很简单---通过一个大数组来填充元素,时间复杂度和空间复杂度都是O(n),但是空间复杂度明显有点大了.
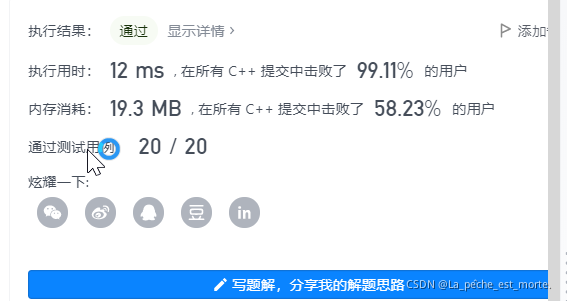
官方题解很简洁:
1)sort排序,空间上直接在原vector上进行排序(但是考虑是递归调用,所以要考虑栈的空间复杂度O(logn)),然后依次比较n和n+1号元素,如果相等就直接退出
2)下面重点介绍这样一种解法--哈希表unordered_set<int> s
它对于元素访问来说,时间复杂度
1、unordered_set是一种容器,它以不特定的顺序存储惟一的元素,并允许根据元素的值快速检索单个元素。
2、在unordered_set中,元素的值同时是唯一标识它的键。键是不可变的,只可增删,不可修改
3、在内部,unordered_set中的元素没有按照任何特定的顺序排序,而是根据它们的散列值组织成桶,从而允许通过它们的值直接快速访问单个元素(平均时间复杂度为常数)。
4、unordered_set容器比set容器更快地通过它们的键访问单个元素,尽管它们在元素子集的范围迭代中通常效率较低。
5、容器中的迭代器至少是前向迭代器。
这是修改之后的代码
bool containsDuplicate(vector<int>& nums) {
unordered_set<int> s;
bool flag = false;
for (int x : nums)
{
if (s.find(x) != s.end()) //找到了重复元素
{
flag = true;
break;
}
else {
s.insert(x);
}
}
return flag;
}
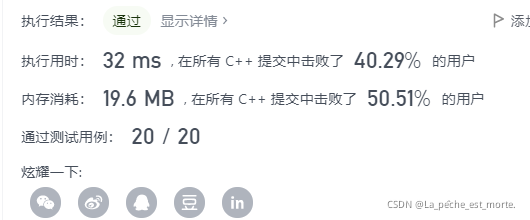
这么一看,还是我开始的笨方法最优,(#^.^#)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











