






2025深度学习发论文&模型涨点之——机器学习+组合优化
机器学习与组合优化的结合是近年来的研究热点之一,这种结合利用机器学习的强大数据处理和模式识别能力,以及组合优化的高效问题求解能力,为解决复杂优化问题提供了新的思路和方法。
-
端到端机器学习方法:通过机器学习算法直接求解组合优化问题,避免了传统优化算法复杂的迭代过程。例如,深度强化学习可以用于路径规划和调度问题。
-
预测+优化框架:先利用机器学习模型预测问题的关键参数,再结合传统优化算法求解。例如,使用图神经网络(GNN)预测变量的边际概率,然后在预测解的基础上进行搜索。
- 神经启发式方法:将机器学习模型与传统启发式算法结合,提升优化效率。例如,DeepACO框架通过深度强化学习增强蚁群优化算法。
小编整理了一些机器学习+组合优化【论文】合集,以下放出部分,全部论文PDF版皆可领取。
需要的同学
回复“ 机器学习+组合优化”即可全部领取
论文精选
论文1:
Revocable Deep Reinforcement Learning with Affinity Regularization for Outlier-Robust Graph Matching
具有亲和力正则化的可撤销深度强化学习用于鲁棒的图匹配
方法
-
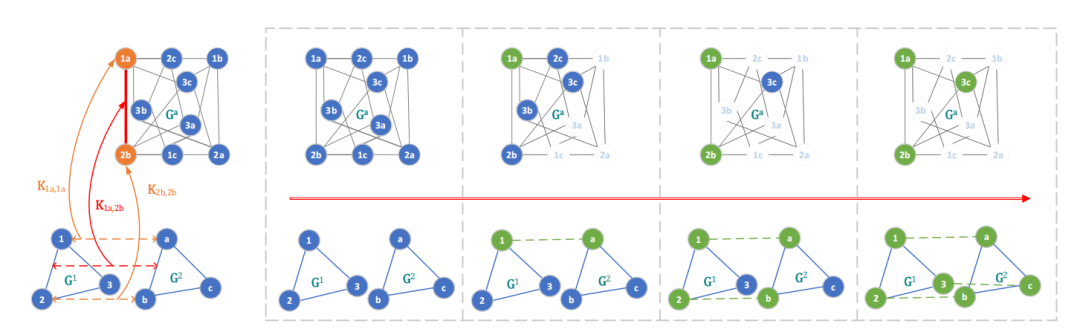
可撤销深度强化学习(RGM):提出了一种基于强化学习的图匹配方法,通过序贯节点匹配方案自然适应选择性内点匹配策略以对抗离群点。
可撤销动作框架:设计了一种允许代理在复杂约束的图匹配中撤销错误动作的框架,提高了灵活性。
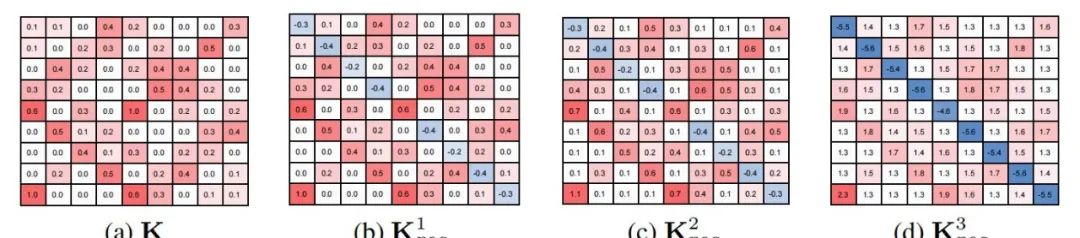
亲和力正则化:提出了一种基于二次近似的亲和力正则化技术,通过为匹配打分引入负值来避免过度匹配离群点。
关联图构建:通过构建关联图作为输入表示,将图匹配问题转化为二次分配问题(QAP),并利用强化学习求解。
创新点
-
可撤销动作机制:首次提出可撤销动作机制,允许代理在匹配过程中撤销错误决策,显著提高了图匹配的灵活性和准确性。
亲和力正则化:通过二次近似技术对亲和力矩阵进行正则化,避免了离群点的过度匹配,提升了匹配的鲁棒性。
强化学习的应用:首次将强化学习应用于图匹配问题,尤其是在处理离群点方面表现出色,与现有方法相比,RGM在多个数据集上平均F1分数提升了4%。
性能提升:在Willow Object数据集上,RGM在不同数量的离群点设置下均优于现有方法,尤其是在有3个离群点时,F1分数达到87.68%,显著高于其他基线方法。
论文2:
LinSATNet: The Positive Linear Satisfiability Neural Networks
LinSATNet:正线性可满足性神经网络
方法
-
多集Sinkhorn算法:扩展了经典的Sinkhorn算法,使其能够处理多组边际分布,为正线性约束的可满足性提供理论支持。
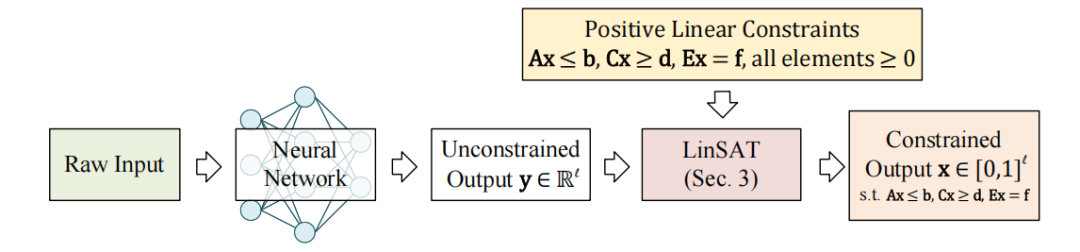
LinSAT层:设计了一个可微且无参数的轻量级层,用于将正线性约束编码到神经网络的输出中。
端到端训练:通过将正线性约束视为边际分布,实现了端到端的可微训练,确保了约束的严格满足。
应用案例:展示了LinSAT在三个场景中的应用:带额外约束的旅行商问题(TSP)、带离群点的部分图匹配问题以及具有连续约束的金融投资组合预测。

创新点
-
多集Sinkhorn算法:首次将Sinkhorn算法扩展到多组边际分布,为处理复杂的正线性约束提供了理论支持。
端到端可微性:通过LinSAT层实现了正线性约束的端到端可微性,确保了约束的严格满足,同时保持了神经网络的高效性。
性能提升:在带额外约束的TSP问题中,LinSAT在TSP-SE和TSP-PRI变体上均优于现有方法,平均巡游长度分别降低了15.2%和17.7%。
部分图匹配:在Pascal VOC数据集上,LinSAT实现了61.2%的F1分数,优于现有方法,证明了其在处理离群点方面的优势。
论文3:
SurCo: Learning Linear Surrogates for Combinatorial Nonlinear Optimization Problems
SurCo:为组合非线性优化问题学习线性代理
方法
-
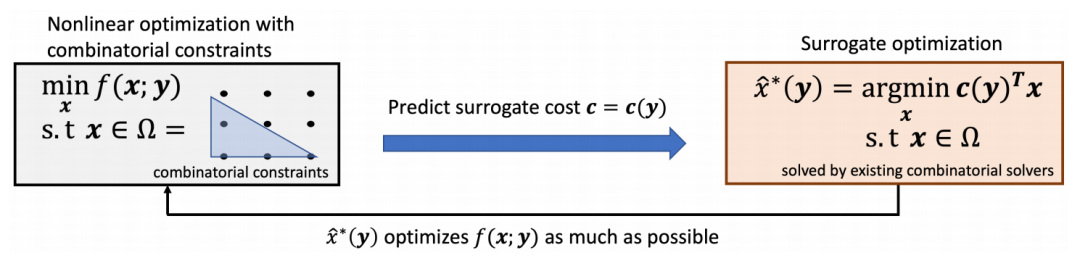
线性代理成本学习:提出了一种学习线性代理成本的方法,通过线性组合优化器(SO)输出接近原始非线性成本最优解的解。
SurCo变体:提出了三种SurCo变体:SurCo-zero用于单个非线性问题,SurCo-prior用于问题分布,SurCo-hybrid结合了分布和问题特定信息。
端到端优化:通过线性代理求解器的可微性,实现了从问题描述到线性代理成本的端到端优化。
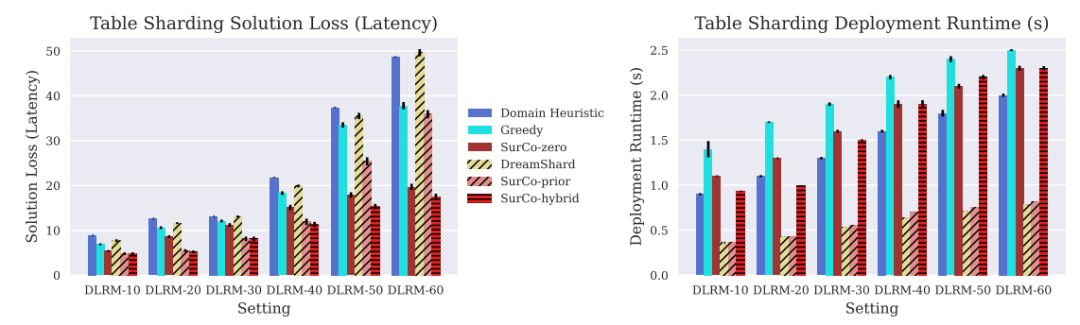
应用案例:在嵌入表分片、逆向光子设计和非线性路径规划三个实际问题中验证了SurCo的有效性。
创新点
-
线性代理成本学习:通过学习线性代理成本,SurCo能够利用高效的组合优化求解器解决非线性问题,显著提高了求解效率。
SurCo-prior:通过在训练集上学习代理成本模型,SurCo-prior能够为新的问题实例快速生成高质量的解,减少了优化时间。
性能提升:在嵌入表分片任务中,SurCo-zero在运行时间上与现有方法相当,但找到了更低延迟的分片计划;SurCo-prior在保持与DreamShard相似运行时间的同时,找到了更低延迟的解。
非线性路径规划:在非线性路径规划任务中,SurCo-zero在紧截止时间下成功率达到8.5%,显著高于现有方法。
论文4:
The Machine Learning for Combinatorial Optimization Competition (ML4CO): Results and Insights
机器学习与组合优化竞赛(ML4CO):结果与见解
方法
-
机器学习增强求解器:通过机器学习模型替换传统组合优化求解器中的关键启发式组件,以提高求解效率。
三个任务:竞赛包括三个任务:寻找最佳可行解(Primal Task)、生成最紧的最优性证明(Dual Task)和配置求解器参数(Configuration Task)。
数据驱动的算法设计:利用历史数据训练机器学习模型,以适应特定问题分布的求解需求。
应用案例:在平衡物品放置、工作负载分配和海运库存路由三个实际问题中验证了机器学习方法的有效性。
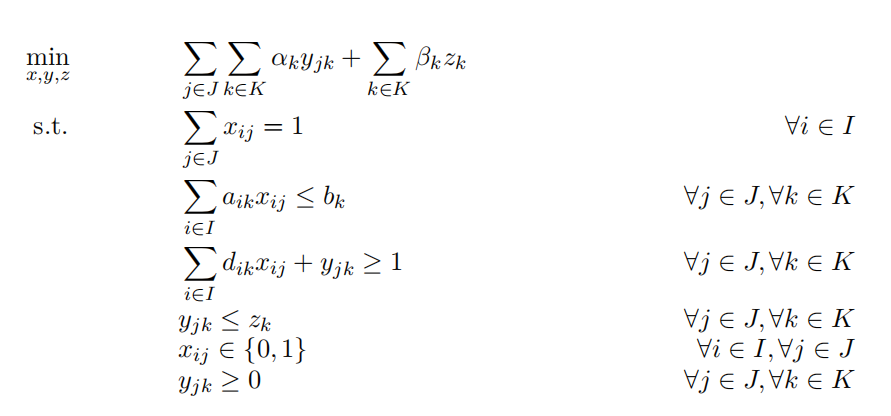
创新点
-
数据驱动的求解器优化:通过机器学习模型优化求解器的启发式组件,显著提高了求解效率和解的质量。
任务特定的算法设计:针对不同任务设计了专门的机器学习方法,例如在Primal Task中利用启发式算法生成高质量的初始解。
性能提升:在平衡物品放置任务中,获胜方法将求解时间缩短了约30%,同时提高了解的质量。
广泛的适用性:机器学习方法在多个实际问题中表现出色,证明了其在组合优化中的广泛适用性。
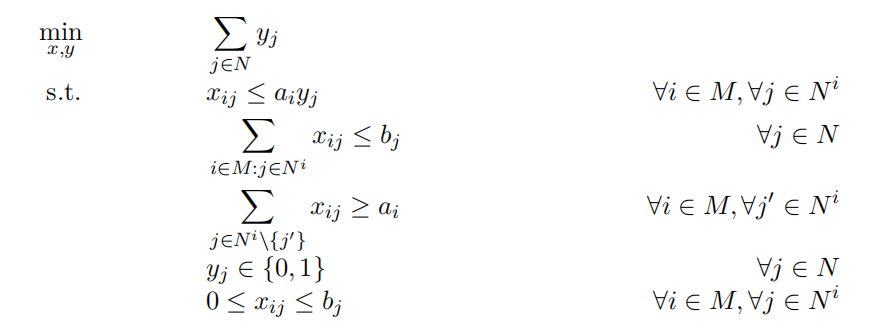
小编整理了机器学习+组合优化论文代码合集
需要的同学扫码添加我
回复“ 机器学习+组合优化”即可全部领取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









