







A Surname Classification System based on MLP
基于MLP的姓氏分类系统
This notebook serves as my learning journey into the Multilayer Perceptron (MLP), which is a fundamental type of Feedforward Neural Network. Throughout this article, I will be undertaking the following tasks and documenting my learning process:
-
Master the Application of Multi-layer Perceptron in Multi-class Classification:
- Using the example of “Surname Classification with Multi-layer Perceptron” to understand the practical implementation.
-
Understand the Impact of Different Neural Network Layers:
- Analyzing how each type of neural network layer affects the size and shape of the data tensors it processes.
-
Experiment with the SurnameClassifier Model:
- Introducing dropout into the model and observing the changes in the results.
In addition to these tasks, I will also attempt to explain some of the challenges I encountered and clarify the underlying principles as best as I can. Even though my English is not such good, I choose English to be my article’s language, so that I can improve my English.
0 说明
本博客最开始作为笔者一次课程实验的汇报成果而开始写作,能力和精力实在有限,文章质量欠佳,后续笔者会更新更加实用有料的博客,欢迎关注。各位大佬轻喷。博客使用英文写作,原因一笔者最近在学习英语,希望创造一些练习的机会;原因二是在课程实验实施的环境中,使用中文模式无法使用一些快捷键。在完成实验的前提下,我还尽我所能阐述了必要原理,并黏贴了一些我所参考或推荐的网址。下面,正文开始!
1 Look into MLP
1.1 Perceptron (which we learnt in Lab1)
The perceptron is a fundamental building block of neural networks. It’s a type of artificial neuron that can perform binary classifications. The perceptron takes a set of inputs, applies weights to them, sums them up, and passes the result through an activation function to produce an output.
Here’s a simple diagram of a perceptron:
x1 ---- w1
\
x2 ---- w2
\
x3 ---- w3 ----> Σ (sum) ----> Activation Function ----> Output
/
... ----
/
xn ---- wn
1.2 How a Perceptron Works
- Inputs: Each input ( x 1 , x 2 , . . . , x n ) ( x_1, x_2, ..., x_n) (x1,x2,...,xn) represents a feature of the data.
- Weights: Each input has an associated weight ( w 1 , w 2 , . . . , w n ) ( w_1, w_2, ..., w_n) (w1,w2,...,wn). These weights are learned during the training process.
- Summation: The perceptron computes a weighted sum of the inputs:
z = ∑ i = 1 n w i x i + b z = \sum_{i=1}^{n} w_i x_i + b z=i=1∑nwixi+b
where $ b $ is the bias term. - Activation Function: The summation result $ z $ is then passed through an activation function & f &. For a simple perceptron, a common choice is the step function:
f ( x ) = { 1 if z ≥ 0 0 if z < 0 f(x)= \begin{cases} 1 & \text{if } z \ge 0 \\ 0 & \text{if } z < 0 \end{cases} f(x)={ 10if z≥0if z<0
The activation function determines the perceptron’s output, which is typically binary (0 or 1).
It can be mathematically represented as:
y ^ = f ( ∑ i = 1 n w i x i + b ) \hat{y} = f\left(\sum_{i=1}^{n} w_i x_i + b\right) y^=f(i=1∑nwixi+b)
where y ^ \hat{y} y^ is the predicted output, $ x_i $ are the input features, $ w_i$are the weights, $ b $ is the bias term and $ f $ is the activation function.

Consider a simple binary classification problem where we want to determine if an email is spam (1) or not spam (0). The perceptron takes features of the email as inputs (e.g., presence of certain keywords, length of the email, etc.), computes the weighted sum, applies the activation function, and produces the output: spam or not spam. Of course, due to the structure is to simple, the result may not be such good. There’s a article by Medium which’s far more good than my arcticle, and this is its link: https://towardsdatascience.com/what-the-hell-is-perceptron-626217814f53
1.3 Drawbacks of the Perceptron
While the perceptron is a fundamental concept in neural networks, it has some significant limitations:
-
Linear Separability: The perceptron can only solve problems that are linearly separable. This means it can only classify data points that can be separated by a straight line (in two dimensions), a plane (in three dimensions), or a hyperplane (in higher dimensions). For example, the XOR problem, which is not linearly separable, cannot be solved by a single perceptron.
-
Limited Expressiveness: Because it only involves a single layer of computation, a single-layer perceptron cannot capture complex patterns or relationships in the data. It lacks the ability to learn higher-order features.
1.4 How MLP Solves These Drawbacks
The Multilayer Perceptron (MLP), also known as a Feedforward Neural Network, addresses these drawbacks by introducing multiple layers of neurons. Here’s how MLP overcomes the limitations of a single-layer perceptron:
-
Non-linear Activation Functions: MLPs use non-linear activation functions (such as ReLU, sigmoid, or tanh) in hidden layers. These non-linearities allow the network to learn complex, non-linear relationships between the input and output.
-
Multiple Layers (Hidden Layers): By stacking multiple layers of neurons (hidden layers) between the input and output layers, MLPs can learn hierarchical representations of the data. Each layer captures different levels of abstraction:
- First Layer: Captures simple patterns or features.
- Subsequent Layers: Combine these simple patterns to capture more complex features.
-
Universal Approximation: An MLP with at least one hidden layer and non-linear activation functions can approximate any continuous function to any desired degree of accuracy, given sufficient neurons in the hidden layer. This is known as the Universal Approximation Theorem.
1.5 Architecture of an MLP
An MLP consists of an input layer, one or more hidden layers, and an output layer:
Input Layer --> Hidden Layer(s) --> Output Layer
x1 x2 h1 h2 h3 y1 y2
\ / \ / / \ /
h1 h1 h2 ... h1 h2 ...
/ \ / / \ / /
o1 o2 o1 o2 o3 o1 o2
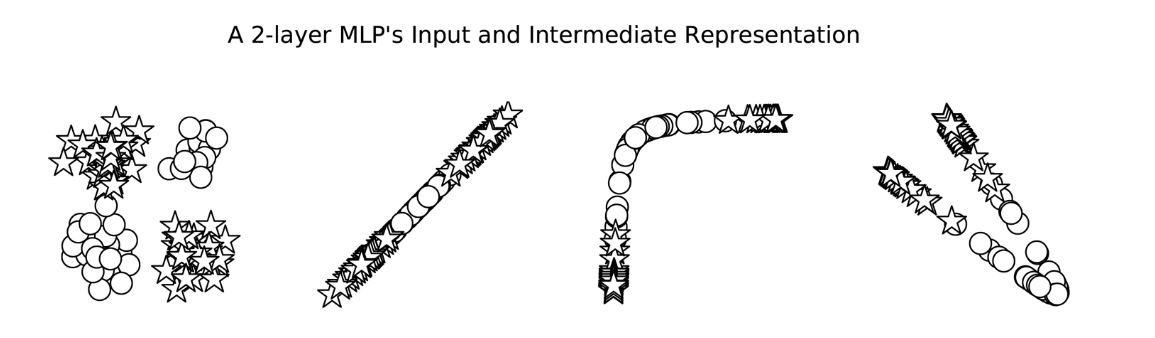
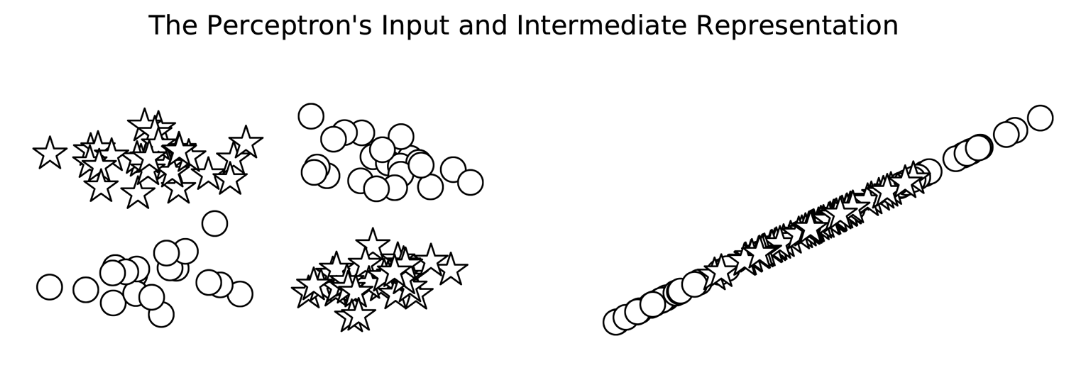
The XOR problem is a classic example that a single-layer perceptron cannot solve because the data points are not linearly separable. However, an MLP with one hidden layer can solve the XOR problem.
While the perceptron is limited to solving only linearly separable problems, the MLP overcomes these limitations through its layered architecture and non-linear activation functions. This allows MLPs to learn and approximate complex, non-linear functions, making them much more powerful and versatile for a wide range of classification and regression tasks.
For instance, MLP model can solve the problems below whereas Percertron can’t.

2 Implementing MLPs in PyTorch
This section serves as a guide to getting started with MLP using PyTorch, a machine learning library based on the Torch library. PyTorch is widely recognized as one of the two most popular machine learning libraries, alongside TensorFlow. It offers free and open-source software released under the modified BSD license. According to our professor, PyTorch is currently prevailing in the field. In this part, I will focus more on providing code examples rather than extensive explanations.
# import package
import torch.nn as nn
import torch.nn.functional as F
class MultilayerPerceptron(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
"""
Args:
input_dim (int): the size of the input vectors
hidden_dim (int): the output size of the first Linear layer
output_dim (int): the output size of the second Linear layer
"""
super(MultilayerPerceptron, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x_in, apply_softmax=False):
"""The forward pass of the MLP
Args:
x_in (torch.Tensor): an input data tensor.
x_in.shape should be (batch, input_dim)
apply_softmax (bool): a flag for the softmax activation
should be false if used with the Cross Entropy losses
Returns:
the resulting tensor. tensor.shape should be (batch, output_dim)
"""
intermediate = F.relu(self.fc1(x_in))
output = self.fc2(intermediate)
if apply_softmax:
output = F.softmax(output, dim=1)
return output
Let’s take a example:
batch_size = 2 # number of samples input at once
input_dim = 3
hidden_dim = 100
output_dim = 4
# Initialize model
mlp = MultilayerPerceptron(input_dim, hidden_dim, output_dim)
print(mlp)
MultilayerPerceptron(
(fc1): Linear(in_features=3, out_features=100, bias=True)
(fc2): Linear(in_features=100, out_features=4, bias=True)
)
Through the output, we can tell the MLP implemention by PuTorch consists of 2 fully connected layers: the first layer takes a 3-dimensional input and produces a 100-dimensional output, while the second layer takes this 100-dimensional input and generates a 4-dimensional output, representing the number of classification classes.
import torch # dl
def describe(x):
"""
This function is used to describe tensor
"""
print("Type: {}".format(x.type()))
print("Shape/size: {}".format(x.shape))
print("Values: \n{}".format(x))
x_input = torch.rand(batch_size, input_dim)
describe(x_input)
Type: torch.FloatTensor
Shape/size: torch.Size([2, 3])
Values:
tensor([[0.4838, 0.0619, 0.5794],
[0.9018, 0.9110, 0.3688]])
Let’s put the tensor x into our MLP model and see what’ll happen.
y_output = mlp(x_input, apply_softmax=False)
describe(y_output)
Type: torch.FloatTensor
Shape/size: torch.Size([2, 4])
Values:
tensor([[-0.3002, -0.0441, -0.0726, -0.1772],
[-0.3877, 0.1662, 0.0653, 0.0621]], grad_fn=<AddmmBackward>)
We can conclude:
MLPs are linear layers that transform tensors into other tensors. Nonlinearities are incorporated between each pair of linear layers to introduce nonlinearity and enable the model to deform the vector space. In a classification scenario, this deformation should result in linear separability among classes. Alternatively, an MLP’s outputs can be interpreted as probabilities using a softmax function; however, it is not advisable to combine softmax with a specific loss function due to potential exploitation of advanced mathematical/computational shortcuts.
3 Our Project:Surname Classification with a MLP
In this section the MLP model will be implemented to predict an individual’s nationality based on their surname using The Surname Dataset.
3.1 About The Surname Dataset
The Surname dataset, which collects 10,000 surnames from 18 different countries, collected by the authors from different sources of names on the Internet. The first feature is that it is rather unbalanced. The second feature is that there is a valid and intuitive relationship between nationality and last name orthography. Some spelling variants are very strongly linked to the country of origin.
First, we will munging the dataset.
import collections
import numpy as np
import pandas as pd
import re
from argparse import Namespace
args = Namespace(
raw_dataset_csv="surnames.csv",
train_proportion=0.7,
val_proportion=0.15,
test_proportion=0.15,
output_munged_csv="surnames_with_splits.csv",
seed=1337
)
# Read raw data
surnames = pd.read_csv(args.raw_dataset_csv, header=0)
surnames.head()
| surname | nationality | |
|---|---|---|
| 0 | Woodford | English |
| 1 | Coté | French |
| 2 | Kore | English |
| 3 | Koury | Arabic |
| 4 | Lebzak | Russian |
The raw data’s header is shown above.
# Unique classes
set(surnames.nationality)
{'Arabic',
'Chinese',
'Czech',
'Dutch',
'English',
'French',
'German',
'Greek',
'Irish',
'Italian',
'Japanese',
'Korean',
'Polish',
'Portuguese',
'Russian',
'Scottish',
'Spanish',
'Vietnamese'}
The countries/regions are shown above.
# Splitting train by nationality
# Create dict
by_nationality = collections.defaultdict(list)
for _, row in surnames.iterrows():
by_nationality[row.nationality].append(row.to_dict())
# Create split data
final_list = []
np.random.seed(args.seed)
for _, item_list in sorted(by_nationality.items()):
np.random.shuffle(item_list)
n = len(item_list)
n_train = int(args.train_proportion*n)
n_val = int(args.val_proportion*n)
n_test = int(args.test_proportion*n)
# Give data point a split attribute
for item in item_list[:n_train]:
item['split'] = 'train'
for item in item_list[n_train:n_train+n_val]:
item['split'] = 'val'
for item in item_list[n_train+n_val:]:
item['split'] = 'test'
# Add to final list
final_list.extend(item_list)
# Write split data to file
final_surnames = pd.DataFrame(final_list)
final_surnames.split.value_counts()
train 7680
test 1660
val 1640
Name: split, dtype: int64
# Write munged data to CSV
final_surnames.to_csv(args.output_munged_csv, index=False)
Now we have got the splited dataset by Nationality.
3.2 Vocabulary, Vectorizer, and DataLoader
To classify surnames using characters, we convert surname strings into vectorized minibatches using a vocabulary, a vectorizer, and a DataLoader.
3.2.1 The Vocabulary Class
The Vocabulary class is a utility for handling text data in NLP tasks. It manages the mapping between tokens and indices, handles unknown tokens, and supports serialization and deserialization for saving and loading the vocabulary. This class is essential for converting text data into a numerical format suitable for machine learning models.
# import package
from argparse import Namespace
from collections import Counter
import json
import os
import string
import numpy as np
import pandas as pd
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.utils.data import Dataset, DataLoader
from tqdm import tqdm_notebook
class Vocabulary(object):
"""Class to process text and extract vocabulary for mapping"""
def __init__(self, token_to_idx=None, add_unk=True, unk_token="<UNK>"):
"""
Args:
token_to_idx (dict): a pre-existing map of tokens to indices
add_unk (bool): a flag that indicates whether to add the UNK token
unk_token (str): the UNK token to add into the Vocabulary
"""
if token_to_idx is None:
token_to_idx = {
}
self._token_to_idx = token_to_idx
self._idx_to_token = {
idx: token
for token, idx in self._token_to_idx.items()}
self._add_unk = add_unk
self._unk_token = unk_token
self.unk_index = -1
if add_unk:
self.unk_index = self.add_token(unk_token)
def to_serializable(self):
""" returns a dictionary that can be serialized """
return {
'token_to_idx': self._token_to_idx,
'add_unk': self._add_unk,
'unk_token': self._unk_token}
@classmethod
def from_serializable(cls, contents):
""" instantiates the Vocabulary from a serialized dictionary """
return cls(**contents)
def add_token(self, token):
"""Update mapping dicts based on the token.
Args:
token (str): the item to add into the Vocabulary
Returns:
index (int): the integer corresponding to the token
"""
try:
index = self._token_to_idx[token]
except KeyError:
index = len(self._token_to_idx)
self._token_to_idx[token] = index
self._idx_to_token[index] = token
return index
def add_many(self, tokens):
"""Add a list of tokens into the Vocabulary
Args:
tokens (list): a list of string tokens
Returns:
indices (list): a list of indices corresponding to the tokens
"""
return [self.add_token(token) for token in tokens]
def lookup_token(self, token):
"""Retrieve the index associated with the token
or the UNK index if token isn't present.
Args:
token (str): the token to look up
Returns:
index (int): the index corresponding to the token
Notes:
`unk_index` needs to be >=0 (having been added into the Vocabulary)
for the UNK functionality
"""
if self.unk_index >= 0:
return self._token_to_idx.get(token, self.unk_index)
else:
return self._token_to_idx[token]
def lookup_index(self, index):
"""Return the token associated with the index
Args:
index (int): the index to look up
Returns:
token (str): the token corresponding to the index
Raises:
KeyError: if the index is not in the Vocabulary
"""
if index not in self._idx_to_token:
raise KeyError("the index (%d) is not in the Vocabulary" % index)
return self._idx_to_token[index]
def __str__(self):
return "<Vocabulary(size=%d)>" % len(self)
def __len__(self):
return len(self._token_to_idx)
3.2.2 THE SURNAME VECTORIZER
The SurnameVectorizer class is designed to handle the conversion of surnames and nationalities into numerical formats suitable for machine learning models. It coordinates two Vocabulary instances:
- One for converting surname characters into indices.
- One for converting nationalities into indices.
The vectorize method converts surnames into one-hot encoded vectors, making them ready for model input. The class methods from_dataframe and from_serializable provide ways to create a SurnameVectorizer from a pandas DataFrame and a serialized dictionary, respectively. The to_serializable method allows the SurnameVectorizer to be easily saved and loaded.
class SurnameVectorizer(object):
""" The Vectorizer which coordinates the Vocabularies and puts them to use"""
def __init__(self, surname_vocab, nationality_vocab):
"""
Args:
surname_vocab (Vocabulary): maps characters to integers
nationality_vocab (Vocabulary): maps nationalities to integers
"""
self.surname_vocab = surname_vocab
self.nationality_vocab = nationality_vocab
def vectorize(self, surname):
"""
Args:
surname (str): the surname
Returns:
one_hot (np.ndarray): a collapsed one-hot encoding
"""
vocab = self.surname_vocab
one_hot = np.zeros(len(vocab), dtype=np.float32)
for token in surname:
one_hot[vocab.lookup_token(token)] = 1
return one_hot
@classmethod
def from_dataframe(cls, surname_df):
"""Instantiate the vectorizer from the dataset dataframe
Args:
surname_df (pandas.DataFrame): the surnames dataset
Returns:
an instance of the SurnameVectorizer
"""
surname_vocab = Vocabulary(unk_token="@")
nationality_vocab = Vocabulary(add_unk=False)
for index, row in surname_df.iterrows():
for letter in row.surname:
surname_vocab.add_token(letter)
nationality_vocab.add_token(row.nationality)
return cls(surname_vocab, nationality_vocab)
@classmethod
def from_serializable(cls, contents):
surname_vocab = Vocabulary.from_serializable(contents['surname_vocab'])
nationality_vocab = Vocabulary.from_serializable(contents['nationality_vocab'])
return</ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









