






 本文详细介绍了数据清洗中的缺失数据处理方法,包括数据滤除和填充,并通过实例演示了如何使用dropna()和fillna()函数。此外,讲解了数据合并的不同方式,如行追加和列连接,以及如何利用merge()函数进行数据关联。最后,涉及了数据排序,包括值排序和排名操作,展示了如何根据成绩和年龄对数据进行排序和排名分析。
本文详细介绍了数据清洗中的缺失数据处理方法,包括数据滤除和填充,并通过实例演示了如何使用dropna()和fillna()函数。此外,讲解了数据合并的不同方式,如行追加和列连接,以及如何利用merge()函数进行数据关联。最后,涉及了数据排序,包括值排序和排名操作,展示了如何根据成绩和年龄对数据进行排序和排名分析。
本文章是3.4、3.5的内容,如果想要源代码和数据可以看以下链接:
https://download.youkuaiyun.com/download/Ahaha_biancheng/83338868
文章目录
3.4 数据清洗
3.4.1 缺失数据处理
主要有数据滤除和数据填充两类方法
缺失数据被表示为NaN, 赋值时使用np.nan
◆ 样本容量大,忽略缺失行
◆ 样本容量较小,采用合适的值来填充
例3-9:从studentsInfo.xlsx的Group1表单读取数据,滤除部分缺失数据,填充部分缺失数据。
import pandas as pd
import numpy as np
stu = pd.read_excel('data/studentsInfo.xlsx', index_col=0)
stu
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|---|
| 序号 | |||||||||
| 1 | male | 20.0 | 170 | 70.0 | LiaoNing | NaN | 800.0 | 5 | 4 |
| 2 | male | 22.0 | 180 | 71.0 | GuangXi | 77.0 | 1300.0 | 3 | 4 |
| 3 | male | NaN | 180 | 62.0 | FuJian | 57.0 | 1000.0 | 2 | 4 |
| 4 | male | 20.0 | 177 | 72.0 | LiaoNing | 79.0 | 900.0 | 4 | 4 |
| 5 | male | 20.0 | 172 | NaN | ShanDong | 91.0 | NaN | 5 | 5 |
| 6 | male | 20.0 | 179 | 75.0 | YunNan | 92.0 | 950.0 | 5 | 5 |
| 7 | female | 21.0 | 166 | 53.0 | LiaoNing | 80.0 | 1200.0 | 4 | 5 |
| 8 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 9 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 10 | male | 19.0 | 169 | 76.0 | HeiLongJiang | 88.0 | 1100.0 | 5 | 5 |
3.4.1.1 数据滤除
dropna()函数删除空值所在行或列,产生新数据对象,不改变原对象

# 缺省删除包含有缺失值的行(序号1、3、5的行被滤除)
stu.dropna()
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|---|
| 序号 | |||||||||
| 2 | male | 22.0 | 180 | 71.0 | GuangXi | 77.0 | 1300.0 | 3 | 4 |
| 4 | male | 20.0 | 177 | 72.0 | LiaoNing | 79.0 | 900.0 | 4 | 4 |
| 6 | male | 20.0 | 179 | 75.0 | YunNan | 92.0 | 950.0 | 5 | 5 |
| 7 | female | 21.0 | 166 | 53.0 | LiaoNing | 80.0 | 1200.0 | 4 | 5 |
| 8 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 9 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 10 | male | 19.0 | 169 | 76.0 | HeiLongJiang | 88.0 | 1100.0 | 5 | 5 |
# 保留有效数据个数≥8的行(序号5的行被滤除)
stu.dropna(thresh=8)
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|---|
| 序号 | |||||||||
| 1 | male | 20.0 | 170 | 70.0 | LiaoNing | NaN | 800.0 | 5 | 4 |
| 2 | male | 22.0 | 180 | 71.0 | GuangXi | 77.0 | 1300.0 | 3 | 4 |
| 3 | male | NaN | 180 | 62.0 | FuJian | 57.0 | 1000.0 | 2 | 4 |
| 4 | male | 20.0 | 177 | 72.0 | LiaoNing | 79.0 | 900.0 | 4 | 4 |
| 6 | male | 20.0 | 179 | 75.0 | YunNan | 92.0 | 950.0 | 5 | 5 |
| 7 | female | 21.0 | 166 | 53.0 | LiaoNing | 80.0 | 1200.0 | 4 | 5 |
| 8 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 9 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 10 | male | 19.0 | 169 | 76.0 | HeiLongJiang | 88.0 | 1100.0 | 5 | 5 |
# 未改变原始值
stu
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|---|
| 序号 | |||||||||
| 1 | male | 20.0 | 170 | 70.0 | LiaoNing | NaN | 800.0 | 5 | 4 |
| 2 | male | 22.0 | 180 | 71.0 | GuangXi | 77.0 | 1300.0 | 3 | 4 |
| 3 | male | NaN | 180 | 62.0 | FuJian | 57.0 | 1000.0 | 2 | 4 |
| 4 | male | 20.0 | 177 | 72.0 | LiaoNing | 79.0 | 900.0 | 4 | 4 |
| 5 | male | 20.0 | 172 | NaN | ShanDong | 91.0 | NaN | 5 | 5 |
| 6 | male | 20.0 | 179 | 75.0 | YunNan | 92.0 | 950.0 | 5 | 5 |
| 7 | female | 21.0 | 166 | 53.0 | LiaoNing | 80.0 | 1200.0 | 4 | 5 |
| 8 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 9 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 10 | male | 19.0 | 169 | 76.0 | HeiLongJiang | 88.0 | 1100.0 | 5 | 5 |
3.4.1.2 数据填充
fillna()函数可以实现NaN数据的批量填充,也可以对指定列进行填充;
填充操作产生新的数据对象,原始数据不会被修改
填充有两种基本思路:
◆ 用默认值填充
◆ 用已有数据的均值/中位数来填充

例3-9“年龄”和“体重”列有缺失数据
◆ 同年级学生年龄差距不大,用默认值填充
◆ 体重用平均值来填充
# 按列填充,构造{列索引名:值}形式的字典对象作为实参
stu.fillna({'年龄':21, '体重':stu['体重'].mean()})
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|---|
| 序号 | |||||||||
| 1 | male | 20.0 | 170 | 70.000000 | LiaoNing | NaN | 800.0 | 5 | 4 |
| 2 | male | 22.0 | 180 | 71.000000 | GuangXi | 77.0 | 1300.0 | 3 | 4 |
| 3 | male | 21.0 | 180 | 62.000000 | FuJian | 57.0 | 1000.0 | 2 | 4 |
| 4 | male | 20.0 | 177 | 72.000000 | LiaoNing | 79.0 | 900.0 | 4 | 4 |
| 5 | male | 20.0 | 172 | 63.666667 | ShanDong | 91.0 | NaN | 5 | 5 |
| 6 | male | 20.0 | 179 | 75.000000 | YunNan | 92.0 | 950.0 | 5 | 5 |
| 7 | female | 21.0 | 166 | 53.000000 | LiaoNing | 80.0 | 1200.0 | 4 | 5 |
| 8 | female | 20.0 | 162 | 47.000000 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 9 | female | 20.0 | 162 | 47.000000 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 10 | male | 19.0 | 169 | 76.000000 | HeiLongJiang | 88.0 | 1100.0 | 5 | 5 |
# 用前一行数据替换当前行的空值,第一行没有填充
stu.fillna(method='ffill')
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|---|
| 序号 | |||||||||
| 1 | male | 20.0 | 170 | 70.0 | LiaoNing | NaN | 800.0 | 5 | 4 |
| 2 | male | 22.0 | 180 | 71.0 | GuangXi | 77.0 | 1300.0 | 3 | 4 |
| 3 | male | 22.0 | 180 | 62.0 | FuJian | 57.0 | 1000.0 | 2 | 4 |
| 4 | male | 20.0 | 177 | 72.0 | LiaoNing | 79.0 | 900.0 | 4 | 4 |
| 5 | male | 20.0 | 172 | 72.0 | ShanDong | 91.0 | 900.0 | 5 | 5 |
| 6 | male | 20.0 | 179 | 75.0 | YunNan | 92.0 | 950.0 | 5 | 5 |
| 7 | female | 21.0 | 166 | 53.0 | LiaoNing | 80.0 | 1200.0 | 4 | 5 |
| 8 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 9 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 10 | male | 19.0 | 169 | 76.0 | HeiLongJiang | 88.0 | 1100.0 | 5 | 5 |
# 对于全是数字的文件,可以设置用标量填充所有的缺失值
stu.fillna(0)
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|---|
| 序号 | |||||||||
| 1 | male | 20.0 | 170 | 70.0 | LiaoNing | 0.0 | 800.0 | 5 | 4 |
| 2 | male | 22.0 | 180 | 71.0 | GuangXi | 77.0 | 1300.0 | 3 | 4 |
| 3 | male | 0.0 | 180 | 62.0 | FuJian | 57.0 | 1000.0 | 2 | 4 |
| 4 | male | 20.0 | 177 | 72.0 | LiaoNing | 79.0 | 900.0 | 4 | 4 |
| 5 | male | 20.0 | 172 | 0.0 | ShanDong | 91.0 | 0.0 | 5 | 5 |
| 6 | male | 20.0 | 179 | 75.0 | YunNan | 92.0 | 950.0 | 5 | 5 |
| 7 | female | 21.0 | 166 | 53.0 | LiaoNing | 80.0 | 1200.0 | 4 | 5 |
| 8 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 9 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 10 | male | 19.0 | 169 | 76.0 | HeiLongJiang | 88.0 | 1100.0 | 5 | 5 |
# 对于全是数字的文件,可以设置全用平均值填充
stu.fillna(stu.mean())
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|---|
| 序号 | |||||||||
| 1 | male | 20.000000 | 170 | 70.000000 | LiaoNing | 80.0 | 800.000000 | 5 | 4 |
| 2 | male | 22.000000 | 180 | 71.000000 | GuangXi | 77.0 | 1300.000000 | 3 | 4 |
| 3 | male | 20.222222 | 180 | 62.000000 | FuJian | 57.0 | 1000.000000 | 2 | 4 |
| 4 | male | 20.000000 | 177 | 72.000000 | LiaoNing | 79.0 | 900.000000 | 4 | 4 |
| 5 | male | 20.000000 | 172 | 63.666667 | ShanDong | 91.0 | 1027.777778 | 5 | 5 |
| 6 | male | 20.000000 | 179 | 75.000000 | YunNan | 92.0 | 950.000000 | 5 | 5 |
| 7 | female | 21.000000 | 166 | 53.000000 | LiaoNing | 80.0 | 1200.000000 | 4 | 5 |
| 8 | female | 20.000000 | 162 | 47.000000 | AnHui | 78.0 | 1000.000000 | 4 | 4 |
| 9 | female | 20.000000 | 162 | 47.000000 | AnHui | 78.0 | 1000.000000 | 4 | 4 |
| 10 | male | 19.000000 | 169 | 76.000000 | HeiLongJiang | 88.0 | 1100.000000 | 5 | 5 |
# 用每列的中位数填充
stu.fillna(stu.median())
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|---|
| 序号 | |||||||||
| 1 | male | 20.0 | 170 | 70.0 | LiaoNing | 79.0 | 800.0 | 5 | 4 |
| 2 | male | 22.0 | 180 | 71.0 | GuangXi | 77.0 | 1300.0 | 3 | 4 |
| 3 | male | 20.0 | 180 | 62.0 | FuJian | 57.0 | 1000.0 | 2 | 4 |
| 4 | male | 20.0 | 177 | 72.0 | LiaoNing | 79.0 | 900.0 | 4 | 4 |
| 5 | male | 20.0 | 172 | 70.0 | ShanDong | 91.0 | 1000.0 | 5 | 5 |
| 6 | male | 20.0 | 179 | 75.0 | YunNan | 92.0 | 950.0 | 5 | 5 |
| 7 | female | 21.0 | 166 | 53.0 | LiaoNing | 80.0 | 1200.0 | 4 | 5 |
| 8 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 9 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 10 | male | 19.0 | 169 | 76.0 | HeiLongJiang | 88.0 | 1100.0 | 5 | 5 |
3.4.2 去除重复数据
例3-10 从文件studentsInfo.xlsx的“Group1”页中读取数据,去除重复数据。
obj.drop_duplicates()
stu = pd.read_excel("data/studentsInfo.xlsx", index_col=0)
stu
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|---|
| 序号 | |||||||||
| 1 | male | 20.0 | 170 | 70.0 | LiaoNing | NaN | 800.0 | 5 | 4 |
| 2 | male | 22.0 | 180 | 71.0 | GuangXi | 77.0 | 1300.0 | 3 | 4 |
| 3 | male | NaN | 180 | 62.0 | FuJian | 57.0 | 1000.0 | 2 | 4 |
| 4 | male | 20.0 | 177 | 72.0 | LiaoNing | 79.0 | 900.0 | 4 | 4 |
| 5 | male | 20.0 | 172 | NaN | ShanDong | 91.0 | NaN | 5 | 5 |
| 6 | male | 20.0 | 179 | 75.0 | YunNan | 92.0 | 950.0 | 5 | 5 |
| 7 | female | 21.0 | 166 | 53.0 | LiaoNing | 80.0 | 1200.0 | 4 | 5 |
| 8 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 9 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 10 | male | 19.0 | 169 | 76.0 | HeiLongJiang | 88.0 | 1100.0 | 5 | 5 |
# 序号8、9的行重复,序号9的行被滤除
stu.drop_duplicates()
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|---|
| 序号 | |||||||||
| 1 | male | 20.0 | 170 | 70.0 | LiaoNing | NaN | 800.0 | 5 | 4 |
| 2 | male | 22.0 | 180 | 71.0 | GuangXi | 77.0 | 1300.0 | 3 | 4 |
| 3 | male | NaN | 180 | 62.0 | FuJian | 57.0 | 1000.0 | 2 | 4 |
| 4 | male | 20.0 | 177 | 72.0 | LiaoNing | 79.0 | 900.0 | 4 | 4 |
| 5 | male | 20.0 | 172 | NaN | ShanDong | 91.0 | NaN | 5 | 5 |
| 6 | male | 20.0 | 179 | 75.0 | YunNan | 92.0 | 950.0 | 5 | 5 |
| 7 | female | 21.0 | 166 | 53.0 | LiaoNing | 80.0 | 1200.0 | 4 | 5 |
| 8 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 10 | male | 19.0 | 169 | 76.0 | HeiLongJiang | 88.0 | 1100.0 | 5 | 5 |
3.5 数据规整化
3.5.1 数据合并
应用场景
同一实体的数据来自不同的业务系统
◆ 学生的基本信息来自教务系统
◆ 学生刷卡数据来自一卡通系统
相同实体的多个数据集
◆ 案例3-1中反馈数据存放在5张Excel表中
数据合并可分为两种处理方式
◆ 行数据追加
原数据的列与新增数据的列完全相同
轴向连接:concat()函数
◆ 列数据连接:merge()函数
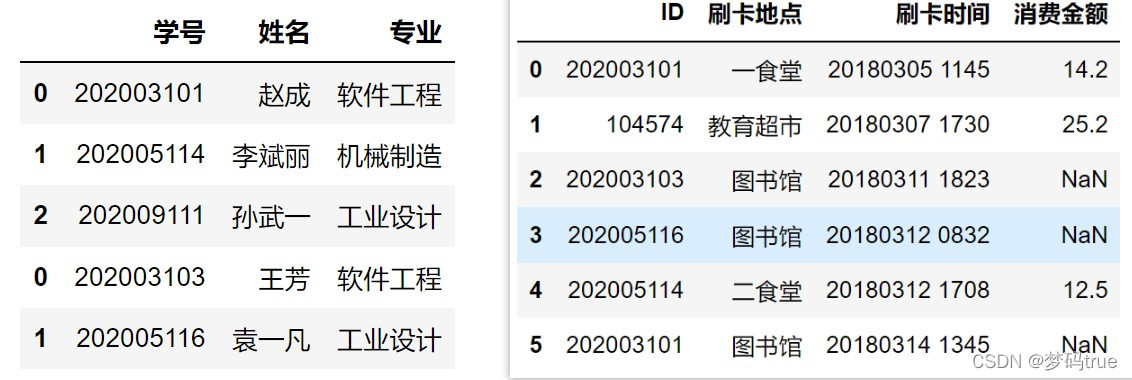
例3-11 将新同学的信息添加到学生基本信息中
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
#定义两个DataFrame对象存储两个表的数据
colname = ['学号','姓名','专业']
data1 = [['202003101','赵成','软件工程'], ['202005114','李斌丽','机械制造'], ['202009111','孙武一','工业设计']]
stu1 = DataFrame(data1, columns=colname)
stu1
| 学号 | 姓名 | 专业 | |
|---|---|---|---|
| 0 | 202003101 | 赵成 | 软件工程 |
| 1 | 202005114 | 李斌丽 | 机械制造 |
| 2 | 202009111 | 孙武一 | 工业设计 |
data2 = [ ['202003103','王芳','软件工程'], ['202005116','袁一凡','工业设计'] ]
stu2 = DataFrame( data2, columns=colname )
stu2
| 学号 | 姓名 | 专业 | |
|---|---|---|---|
| 0 | 202003103 | 王芳 | 软件工程 |
| 1 | 202005116 | 袁一凡 | 工业设计 |
stua = pd.concat([stu1, stu2], axis=0) # axis=0,表示按行进行数据追加
stua
| 学号 | 姓名 | 专业 | |
|---|---|---|---|
| 0 | 202003101 | 赵成 | 软件工程 |
| 1 | 202005114 | 李斌丽 | 机械制造 |
| 2 | 202009111 | 孙武一 | 工业设计 |
| 0 | 202003103 | 王芳 | 软件工程 |
| 1 | 202005116 | 袁一凡 | 工业设计 |
列数据连接
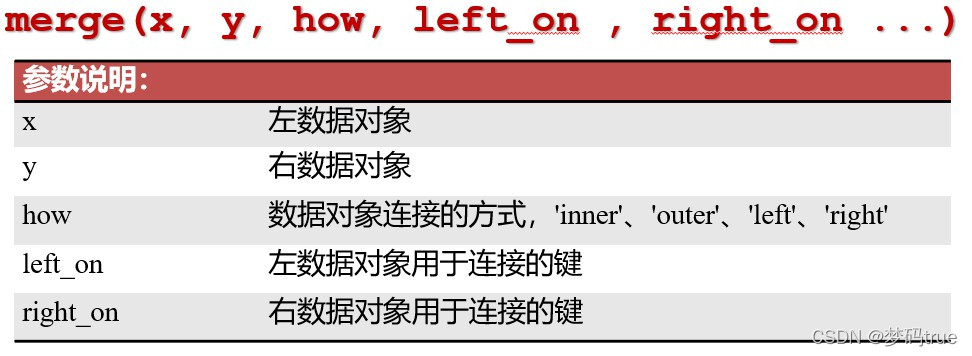
参数how的四种合并方式
1)inner:内连接,拼接两个数据对象中键值交集的行,其余忽略
2)outer:外连接,拼接两个数据对象中键值并集的行
3)left:左连接,取出x的全部行,拼接y中匹配的键值行。
4)right:右连接,取出y的全部行,拼接x中匹配的键值行。
2、3或4种合并方法,当某列数据不存在则自动填充NaN
例3-12 根据一卡通刷卡记录,分析各专业学生上图书馆的习惯,将教务数据表与刷卡信息表拼接起来
cardcol = ['ID','刷卡地点','刷卡时间','消费金额']
data3 = [ ['202003101','一食堂','20180305 1145',14.2], ['104574','教育超市','20180307 1730',25.2],['202003103','图书馆','20180311 1823'],['202005116','图书馆','20180312 0832'],['202005114','二食堂','20180312 1708',12.5],['202003101','图书馆','20180314 1345']]
card = DataFrame( data3, columns=cardcol ) #创建一卡通数据对象
card
| ID | 刷卡地点 | 刷卡时间 | 消费金额 | |
|---|---|---|---|---|
| 0 | 202003101 | 一食堂 | 20180305 1145 | 14.2 |
| 1 | 104574 | 教育超市 | 20180307 1730 | 25.2 |
| 2 | 202003103 | 图书馆 | 20180311 1823 | NaN |
| 3 | 202005116 | 图书馆 | 20180312 0832 | NaN |
| 4 | 202005114 | 二食堂 | 20180312 1708 | 12.5 |
| 5 | 202003101 | 图书馆 | 20180314 1345 | NaN |
stua
| 学号 | 姓名 | 专业 | |
|---|---|---|---|
| 0 | 202003101 | 赵成 | 软件工程 |
| 1 | 202005114 | 李斌丽 | 机械制造 |
| 2 | 202009111 | 孙武一 | 工业设计 |
| 0 | 202003103 | 王芳 | 软件工程 |
| 1 | 202005116 | 袁一凡 | 工业设计 |
# 采用左连接,忽略非学生记录
# 对应左边表格有的记录,右边表格没有的记录补空,右边表格多的记录丢弃
t = pd.merge(stua, card, how='left', left_on='学号',right_on ='ID')
t
| 学号 | 姓名 | 专业 | ID | 刷卡地点 | 刷卡时间 | 消费金额 | |
|---|---|---|---|---|---|---|---|
| 0 | 202003101 | 赵成 | 软件工程 | 202003101 | 一食堂 | 20180305 1145 | 14.2 |
| 1 | 202003101 | 赵成 | 软件工程 | 202003101 | 图书馆 | 20180314 1345 | NaN |
| 2 | 202005114 | 李斌丽 | 机械制造 | 202005114 | 二食堂 | 20180312 1708 | 12.5 |
| 3 | 202009111 | 孙武一 | 工业设计 | NaN | NaN | NaN | NaN |
| 4 | 202003103 | 王芳 | 软件工程 | 202003103 | 图书馆 | 20180311 1823 | NaN |
| 5 | 202005116 | 袁一凡 | 工业设计 | 202005116 | 图书馆 | 20180312 0832 | NaN |
t[t['刷卡地点']=='图书馆']
| 学号 | 姓名 | 专业 | ID | 刷卡地点 | 刷卡时间 | 消费金额 | |
|---|---|---|---|---|---|---|---|
| 1 | 202003101 | 赵成 | 软件工程 | 202003101 | 图书馆 | 20180314 1345 | NaN |
| 4 | 202003103 | 王芳 | 软件工程 | 202003103 | 图书馆 | 20180311 1823 | NaN |
| 5 | 202005116 | 袁一凡 | 工业设计 | 202005116 | 图书馆 | 20180312 0832 | NaN |
# 右链接,对应右边表格有的记录,左边表格没有的记录补空,左边表格多的记录丢弃
pd.merge(stua, card, how='right', left_on='学号', right_on='ID')
| 学号 | 姓名 | 专业 | ID | 刷卡地点 | 刷卡时间 | 消费金额 | |
|---|---|---|---|---|---|---|---|
| 0 | 202003101 | 赵成 | 软件工程 | 202003101 | 一食堂 | 20180305 1145 | 14.2 |
| 1 | 202003101 | 赵成 | 软件工程 | 202003101 | 图书馆 | 20180314 1345 | NaN |
| 2 | NaN | NaN | NaN | 104574 | 教育超市 | 20180307 1730 | 25.2 |
| 3 | 202003103 | 王芳 | 软件工程 | 202003103 | 图书馆 | 20180311 1823 | NaN |
| 4 | 202005116 | 袁一凡 | 工业设计 | 202005116 | 图书馆 | 20180312 0832 | NaN |
| 5 | 202005114 | 李斌丽 | 机械制造 | 202005114 | 二食堂 | 20180312 1708 | 12.5 |
# 内链接,保存两个表格都有的记录,不论哪个表格没有的记录都去掉,找交集
pd.merge(stua, card, how='inner', left_on='学号', right_on='ID')
| 学号 | 姓名 | 专业 | ID | 刷卡地点 | 刷卡时间 | 消费金额 | |
|---|---|---|---|---|---|---|---|
| 0 | 202003101 | 赵成 | 软件工程 | 202003101 | 一食堂 | 20180305 1145 | 14.2 |
| 1 | 202003101 | 赵成 | 软件工程 | 202003101 | 图书馆 | 20180314 1345 | NaN |
| 2 | 202005114 | 李斌丽 | 机械制造 | 202005114 | 二食堂 | 20180312 1708 | 12.5 |
| 3 | 202003103 | 王芳 | 软件工程 | 202003103 | 图书馆 | 20180311 1823 | NaN |
| 4 | 202005116 | 袁一凡 | 工业设计 | 202005116 | 图书馆 | 20180312 0832 | NaN |
# 外连接,求并集
pd.merge(stua, card, how='outer', left_on='学号', right_on='ID')
| 学号 | 姓名 | 专业 | ID | 刷卡地点 | 刷卡时间 | 消费金额 | |
|---|---|---|---|---|---|---|---|
| 0 | 202003101 | 赵成 | 软件工程 | 202003101 | 一食堂 | 20180305 1145 | 14.2 |
| 1 | 202003101 | 赵成 | 软件工程 | 202003101 | 图书馆 | 20180314 1345 | NaN |
| 2 | 202005114 | 李斌丽 | 机械制造 | 202005114 | 二食堂 | 20180312 1708 | 12.5 |
| 3 | 202009111 | 孙武一 | 工业设计 | NaN | NaN | NaN | NaN |
| 4 | 202003103 | 王芳 | 软件工程 | 202003103 | 图书馆 | 20180311 1823 | NaN |
| 5 | 202005116 | 袁一凡 | 工业设计 | 202005116 | 图书馆 | 20180312 0832 | NaN |
| 6 | NaN | NaN | NaN | 104574 | 教育超市 | 20180307 1730 | 25.2 |
3.5.2 数据排序
Series和DataFrame 都支持排序
◆ 按照列数据值排序
◆ 按照列数据生成排名
3.5.2.1 值排序

例3-13:从文件studentsInfo.xlsx的“Group3”表单中读取数据,对“成绩”进行排序分析。
# 读取文件
stuinfo = pd.read_excel('data/studentsInfo.xlsx', index_col=0)
stuinfo
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|---|
| 序号 | |||||||||
| 1 | male | 20.0 | 170 | 70.0 | LiaoNing | NaN | 800.0 | 5 | 4 |
| 2 | male | 22.0 | 180 | 71.0 | GuangXi | 77.0 | 1300.0 | 3 | 4 |
| 3 | male | NaN | 180 | 62.0 | FuJian | 57.0 | 1000.0 | 2 | 4 |
| 4 | male | 20.0 | 177 | 72.0 | LiaoNing | 79.0 | 900.0 | 4 | 4 |
| 5 | male | 20.0 | 172 | NaN | ShanDong | 91.0 | NaN | 5 | 5 |
| 6 | male | 20.0 | 179 | 75.0 | YunNan | 92.0 | 950.0 | 5 | 5 |
| 7 | female | 21.0 | 166 | 53.0 | LiaoNing | 80.0 | 1200.0 | 4 | 5 |
| 8 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 9 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 10 | male | 19.0 | 169 | 76.0 | HeiLongJiang | 88.0 | 1100.0 | 5 | 5 |
# 填充缺失值
stuc = stuinfo.fillna(method='bfill')
stuc
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|---|
| 序号 | |||||||||
| 1 | male | 20.0 | 170 | 70.0 | LiaoNing | 77.0 | 800.0 | 5 | 4 |
| 2 | male | 22.0 | 180 | 71.0 | GuangXi | 77.0 | 1300.0 | 3 | 4 |
| 3 | male | 20.0 | 180 | 62.0 | FuJian | 57.0 | 1000.0 | 2 | 4 |
| 4 | male | 20.0 | 177 | 72.0 | LiaoNing | 79.0 | 900.0 | 4 | 4 |
| 5 | male | 20.0 | 172 | 75.0 | ShanDong | 91.0 | 950.0 | 5 | 5 |
| 6 | male | 20.0 | 179 | 75.0 | YunNan | 92.0 | 950.0 | 5 | 5 |
| 7 | female | 21.0 | 166 | 53.0 | LiaoNing | 80.0 | 1200.0 | 4 | 5 |
| 8 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 9 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 10 | male | 19.0 | 169 | 76.0 | HeiLongJiang | 88.0 | 1100.0 | 5 | 5 |
# 按照单列排序
stuc.sort_values(by='成绩', ascending=False).loc[:, '成绩']
序号
6 92.0
5 91.0
10 88.0
7 80.0
4 79.0
8 78.0
9 78.0
1 77.0
2 77.0
3 57.0
Name: 成绩, dtype: float64
指定多个列排序,如:by=[‘成绩’, ‘年龄’],先按“成绩”排序,若某些行的“成绩”相同,这几行再按“年龄”排序
# 按照多列排序,可以看1,2两位学生
stuc.sort_values(by=['成绩', '年龄'], ascending=False)
| 性别 | 年龄 | 身高 | 体重 | 省份 | 成绩 | 月生活费 | 课程兴趣 | 案例教学 | |
|---|---|---|---|---|---|---|---|---|---|
| 序号 | |||||||||
| 6 | male | 20.0 | 179 | 75.0 | YunNan | 92.0 | 950.0 | 5 | 5 |
| 5 | male | 20.0 | 172 | 75.0 | ShanDong | 91.0 | 950.0 | 5 | 5 |
| 10 | male | 19.0 | 169 | 76.0 | HeiLongJiang | 88.0 | 1100.0 | 5 | 5 |
| 7 | female | 21.0 | 166 | 53.0 | LiaoNing | 80.0 | 1200.0 | 4 | 5 |
| 4 | male | 20.0 | 177 | 72.0 | LiaoNing | 79.0 | 900.0 | 4 | 4 |
| 8 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 9 | female | 20.0 | 162 | 47.0 | AnHui | 78.0 | 1000.0 | 4 | 4 |
| 2 | male | 22.0 | 180 | 71.0 | GuangXi | 77.0 | 1300.0 | 3 | 4 |
| 1 | male | 20.0 | 170 | 70.0 | LiaoNing | 77.0 | 800.0 | 5 | 4 |
| 3 | male | 20.0 | 180 | 62.0 | FuJian | 57.0 | 1000.0 | 2 | 4 |
3.5.2.2 排名
排名给出每行的名次
定义等值数据的处理方式,如并列名次取最小值或最大值,也可以取均值。

# 相同值设置为最小值
stuc['成绩排名'] = stuc['成绩'].rank(method='min', ascending=False)
stuc[['成绩','成绩排名']]
| 成绩 | 成绩排名 | |
|---|---|---|
| 序号 | ||
| 1 | 77.0 | 8.0 |
| 2 | 77.0 | 8.0 |
| 3 | 57.0 | 10.0 |
| 4 | 79.0 | 5.0 |
| 5 | 91.0 | 2.0 |
| 6 | 92.0 | 1.0 |
| 7 | 80.0 | 4.0 |
| 8 | 78.0 | 6.0 |
| 9 | 78.0 | 6.0 |
| 10 | 88.0 | 3.0 |
# 相同值设置为最大值
stuc['成绩排名'] = stuc['成绩'].rank(method='max', ascending=False)
stuc[['成绩','成绩排名']]
| 成绩 | 成绩排名 | |
|---|---|---|
| 序号 | ||
| 1 | 77.0 | 9.0 |
| 2 | 77.0 | 9.0 |
| 3 | 57.0 | 10.0 |
| 4 | 79.0 | 5.0 |
| 5 | 91.0 | 2.0 |
| 6 | 92.0 | 1.0 |
| 7 | 80.0 | 4.0 |
| 8 | 78.0 | 7.0 |
| 9 | 78.0 | 7.0 |
| 10 | 88.0 | 3.0 |
# 相同值设置为平均值,书本上写的是mean,应该是打印错误,得是average
# 更多参数详解可参考 https://juejin.cn/post/6979877027385966622
stuc.loc[3:5, '成绩'] = 77
stuc['成绩排名'] = stuc['成绩'].rank(method='average', ascending=False)
stuc[['成绩','成绩排名']]
| 成绩 | 成绩排名 | |
|---|---|---|
| 序号 | ||
| 1 | 77.0 | 8.0 |
| 2 | 77.0 | 8.0 |
| 3 | 77.0 | 8.0 |
| 4 | 77.0 | 8.0 |
| 5 | 77.0 | 8.0 |
| 6 | 92.0 | 1.0 |
| 7 | 80.0 | 3.0 |
| 8 | 78.0 | 4.5 |
| 9 | 78.0 | 4.5 |
| 10 | 88.0 | 2.0 |

















 327
327

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









