 Raft算法详解
Raft算法详解





Raft算法
背景
分布式是一组独立的计算机,利用网络协同来工作的系统。客户看来就如同一台机器在进行工作。在信息爆照时代,传统的单机以无法应对需求了,分布式具有可扩展性强,可用性高,廉价高效的特点称为了服务发展的趋势。
问题
解决了高需求的问题,但同时也引入了新的问题,需求与服务之间的矛盾并没有彻底解决只是转换成可以分解的问题。CAP理论是分布式理论的基础,它提出三个要素:
Consistency(强一致性):任何客户端都可以读取到其他客户端最近的更新;
Availability(可用性): 系统一直处于可服务状态。
Partition-tolenrance(分区可容忍性):单机故障或网络分区,系统仍然可以保证强一致性和可用性。
很明显这三个是存在需求的矛盾区,一个分布式系统最多只能满足两个,P是必不可少的,AP保证服务的高可用性,但是对于数据的一致性问题,如金融系统中显现出数据丢失的风险。CP保证了数据的一致性,但是损失了性能。传统的主备强同步模式虽然可以保证保证数据一致性,但是对于网络分区或者网络故障就无法使用。paxos和raft等一致性算法的提出,弥补了这部分缺陷,它们在保证CP的前提下,只要大部分机器可以使用,就认为整个系统是可以使用的。
在消息中间件领域,金融支付场景是非常需要强一致性和高可靠性,目前主流的消息中间件存在或多或少的问题:
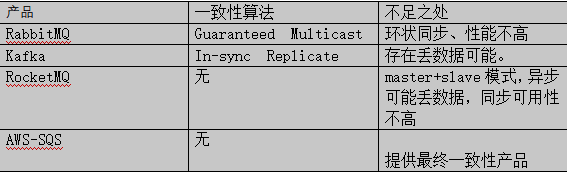
RabbitMQ:一个请求需要在所有节点上处理2次才能保证一致性,性能不高。
Kafka:kafka主要应用在日志、大数据等方向,少量丢失数据业务可以忍受,但不适合要求数据高可靠性的系统。
RocketMQ:未采用一致性算法,如果配置成异步模式可能丢失数据,同步模式下节点故障或网络分区都会影响可用性。
SQS:只提供最终一致性,不保证强一致性。
针对这些问题我们研究一下基于Raft的一致性算法。
Raft算法基本原理
概述:
Raft算法主要包括选举和日志同步。
第一阶段:选举
从集群中选择一台机器作为Leader。
第二阶段:日志同步:
选举出的Leader接收客户端的请求,将其转换为Raft日志;
Leader将日志同步到其他的节点,当大多数节点写入成功后,标志为committed,已经committed的日志不再发生更改;
Leader发生故障时跳到第一阶段进行选举。
Raft算法的术语解释:
Term : 当前的节点所处的周期,可以当作某一个帝王统治时期;
votedFor:当前Term的投票信息,每个节点在一个Term上只能投一次票;
Entry:raft日志的基本单元,包括index,user_dara,term,其中index在日志文件中顺序分配,term是创建该entry所处的term,user_data是业务数据;
State:节点状态(角色)(Leader、Candidate、Follower之一)
CommittedIndex:已提交日志的索引;
State Machine:状态机,业务模块;
ApplyIndex: 已应用的日志索引;
ElectionTime:选举超时时间。
节点之间通过rpc来进行通信,发送方在发送时会携带自身的term,接收方在处理时按照两种流程
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 501
501

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









