






层次化存储
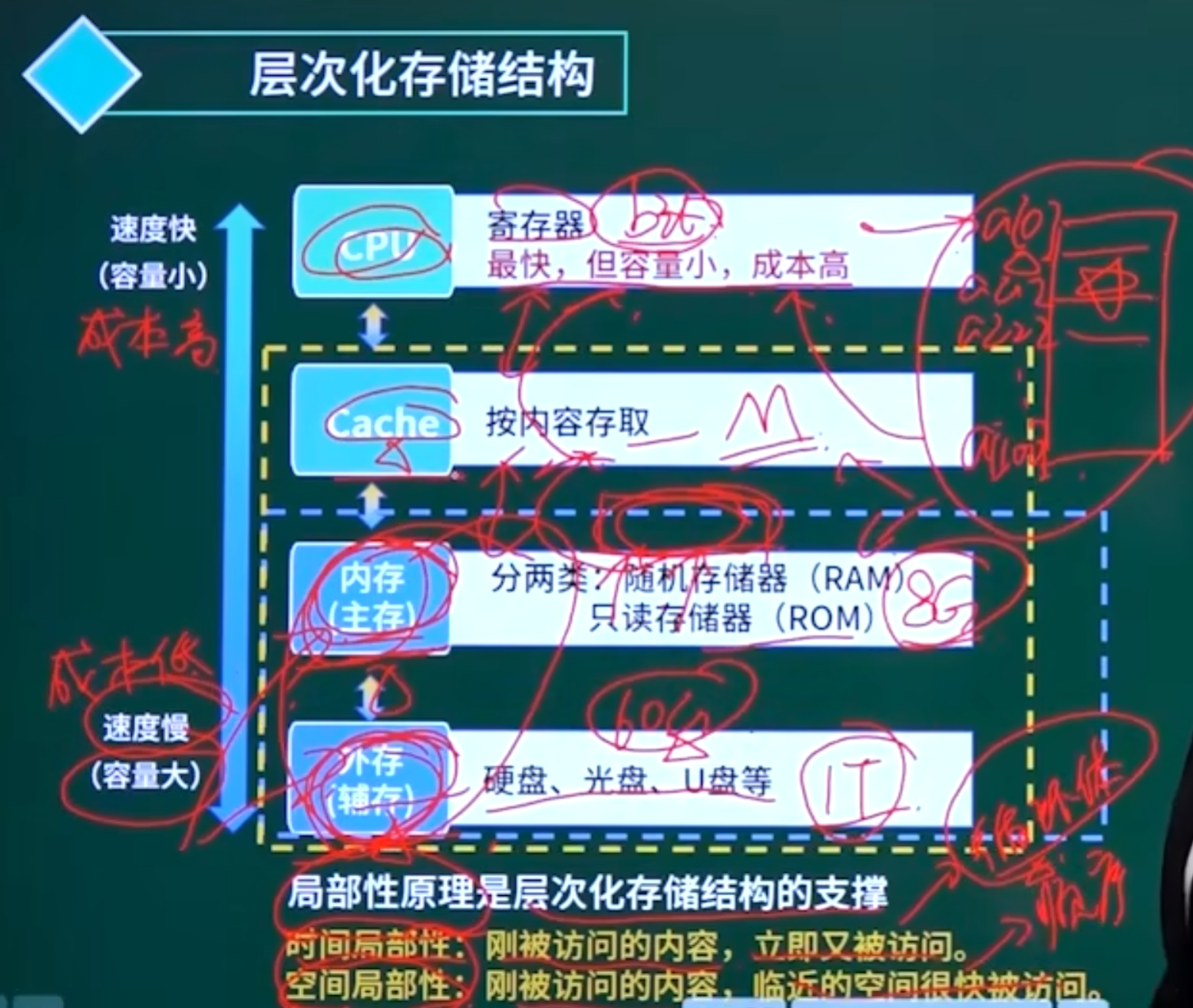

空间局部性是被访问了相邻的可能还要被访问。
时间局部性是被访问了,可能会再次被访问。

虚拟存储体系由 主存-外存(辅存) 两级存储器构成
Cache- 主存-外存(辅存)叫三级存储结构
ROM,掉电安全
RAM,掉电丢数据
BIOS系统掉电不会丢失,一直存在,所以选A。
Cache


Cache性能分析与计算
-
命中率(Hit Rate)
-
命中率 = 命中次数 / 总访问次数。
-
-
平均访问时间
-
平均时间(t3) = 命中时间(命中率 (h)* Cache周期(t1)) + 缺失率(1-h) × 缺失惩罚(访问主存时间(t2))。
-
-
缺失类型
-
强制缺失(Compulsory Miss):首次访问数据必然缺失。
-
冲突缺失(Conflict Miss):因映射冲突导致的缺失(直接/组相联中存在)。
-
容量缺失(Capacity Miss):Cache容量不足导致。
-
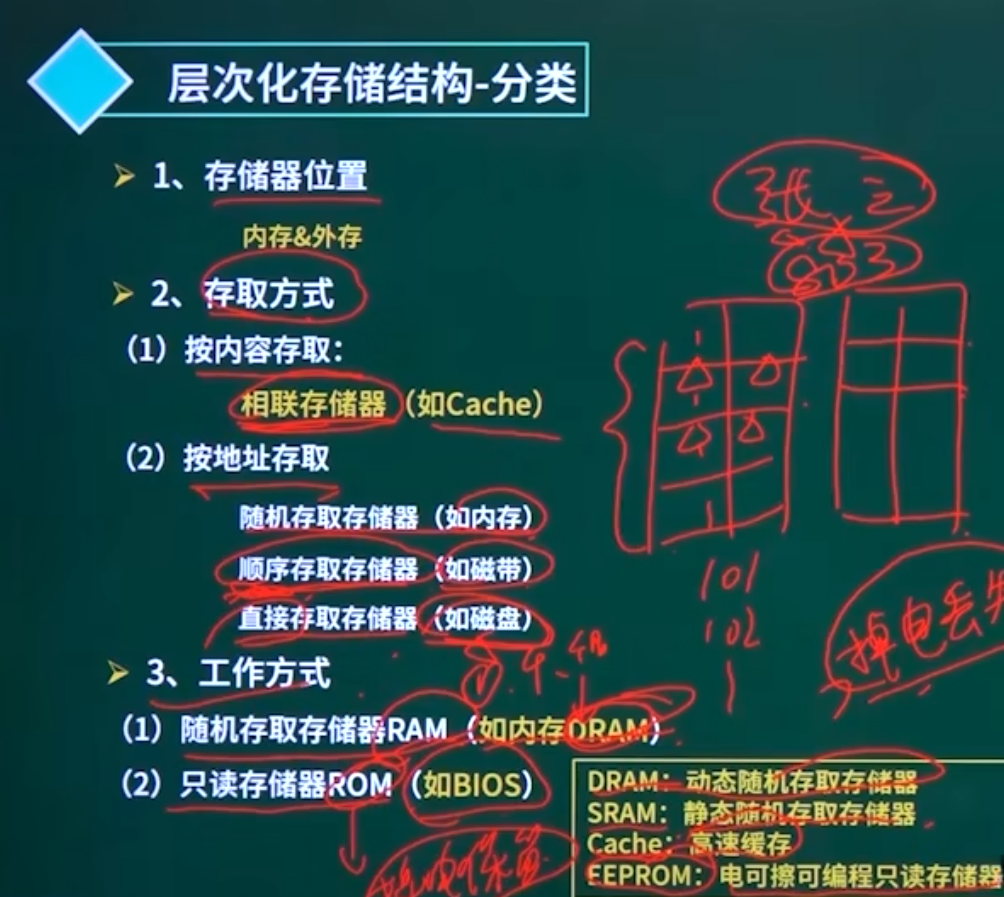
了解一下主存与Cache的映射关系。

主存与Cache之间的映射关系由硬件直接完成,与程序员和操作系统都无关。

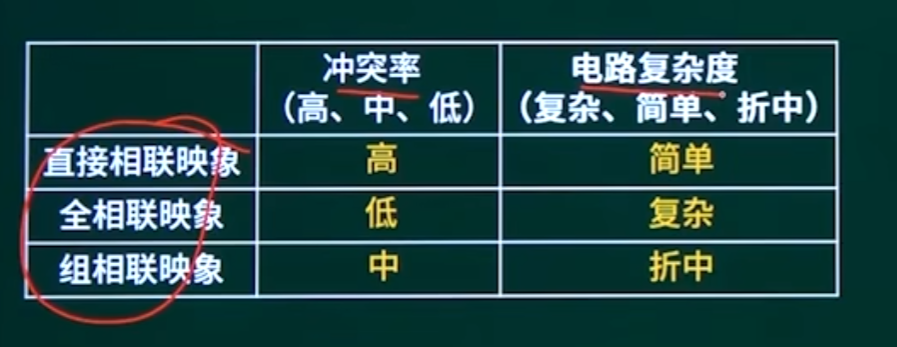
Cache的三大映射方式
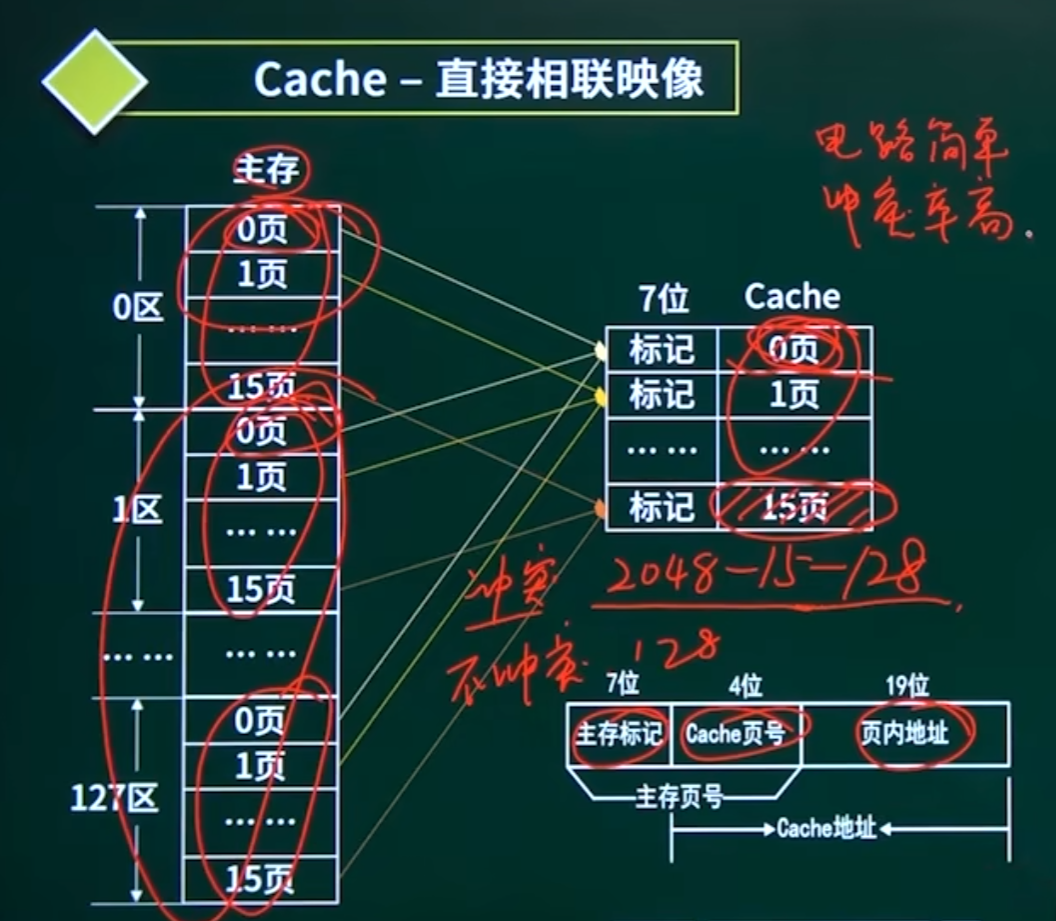
1. 直接映射(Direct Mapped)
-
原理:主存块固定映射到Cache的唯一位置(如
Cache行号 = 主存块号 % Cache行数)。 -
优点:硬件简单,访问速度快。
-
缺点:易冲突(不同主存块竞争同一Cache行)。
-
软考题:给定主存地址(标记位+行号+块内偏移),计算Cache命中位置。
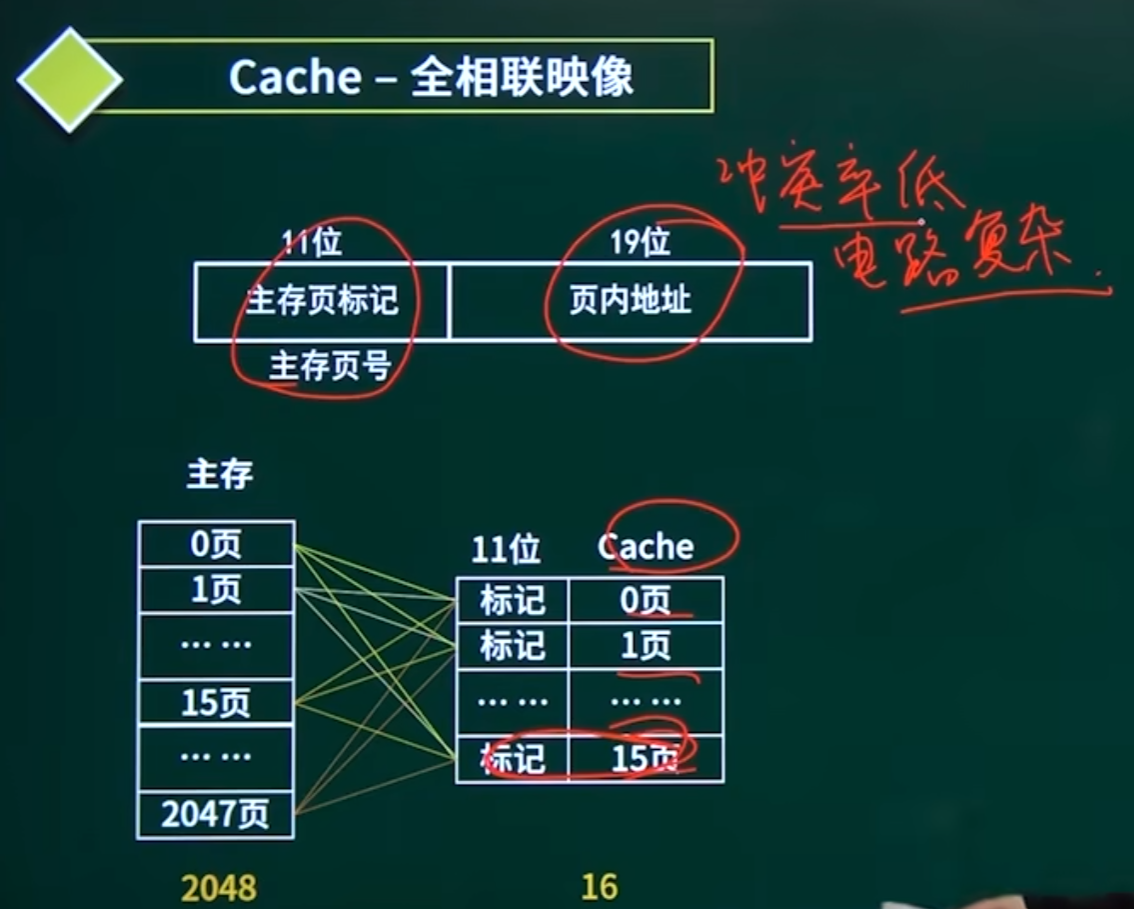
2. 全相联映射(Fully Associative)
-
原理:主存块可存入Cache的任意位置。
-
优点:冲突率低。
-
缺点:查找需比较所有行的标记位(硬件成本高)。
-
应用场景:小容量Cache(如TLB)。
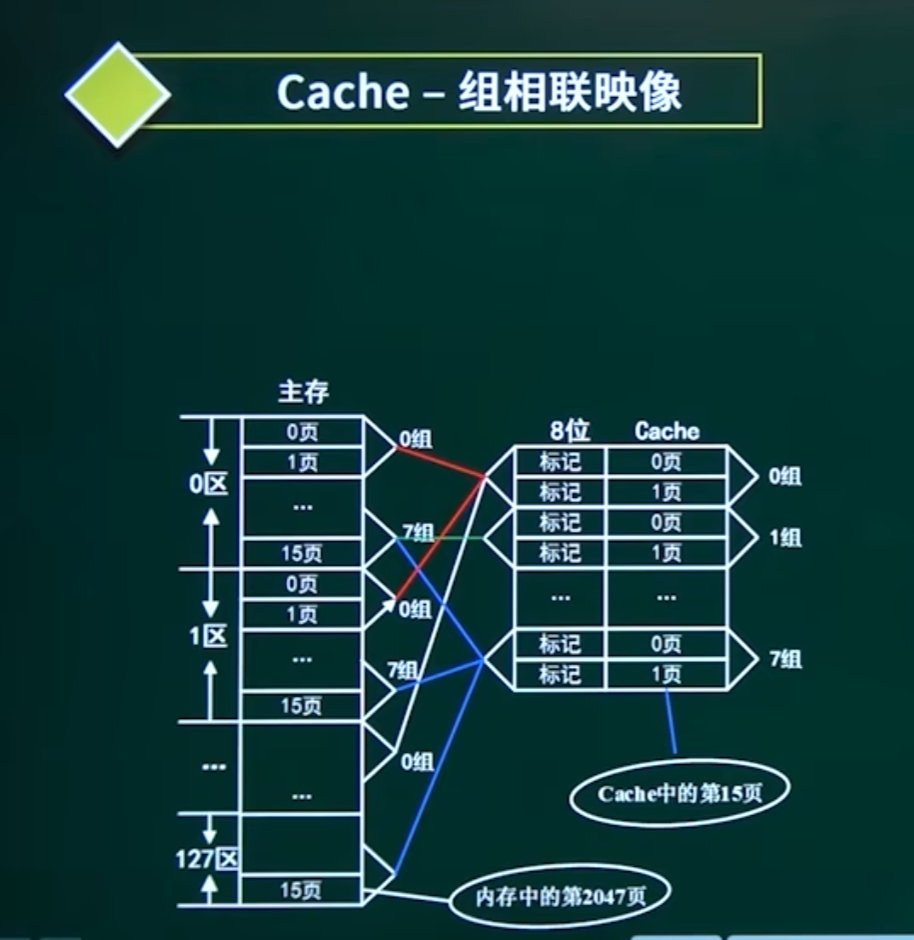
3. 组相联映射(Set Associative)
-
原理:Cache分组,主存块映射到特定组内的任意行(如2路组相联:每组2行)。
-
优点:平衡冲突率和硬件成本(最常用)。
-
计算题:
-
组号 = 主存块号 % 组数
-
标记位 = 主存块号 / 组数
-
当Cache满且需要调入新数据时,如何选择被替换的行?
| 策略 | 规则 | 特点 | 应用场景 |
|---|---|---|---|
| 随机(RAND) | 随机选择一行替换 | 实现简单,性能不稳定 | 极少使用 |
| FIFO | 替换最早调入的行 | 可能替换频繁使用的行 | 较少使用 |
| LRU | 替换最久未使用的行 | 命中率高,硬件实现复杂 | 最常用(如4路组相联) |
| LFU | 替换使用频率最低的行 | 需维护计数器,可能积累旧数据 | 特定场景 |
例题

Cache的命中率并不会随其容量增大而线性提高,当容量越大,提升率就越低,提升曲线越平缓。

全相联是任意地方都能映射,直接相连是映射到Cache的对应位置,组相连是分组对应,是前两个的折中。
软考高频考点
-
选择题
-
问:“2路组相联Cache,容量8KB,每行32B,主存地址32位,块内偏移占多少位?”
-
解:块内偏移 = log₂(32B) = 5位;组数 = 8KB/(2×32B) = 128组 → 组号占7位;标记位 = 32-5-7=20位。
-
-
-
简答题
-
比较直接映射和全相联映射的优缺点。
-
-
设计题
-
如何通过优化Cache行大小提升命中率?(权衡空间局部性与容量利用率)
-
自测题
-
某系统Cache命中率95%,命中时间2ns,缺失惩罚100ns,求平均访问时间?
-
答:2ns + 5%×100ns = 7ns。
-
-
为什么组相联映射能减少冲突缺失?
-
答:同一主存块可映射到组内多行,降低竞争概率。
-
主存编址计算
内存不够时可以横向扩容也可以纵向扩容
核心概念
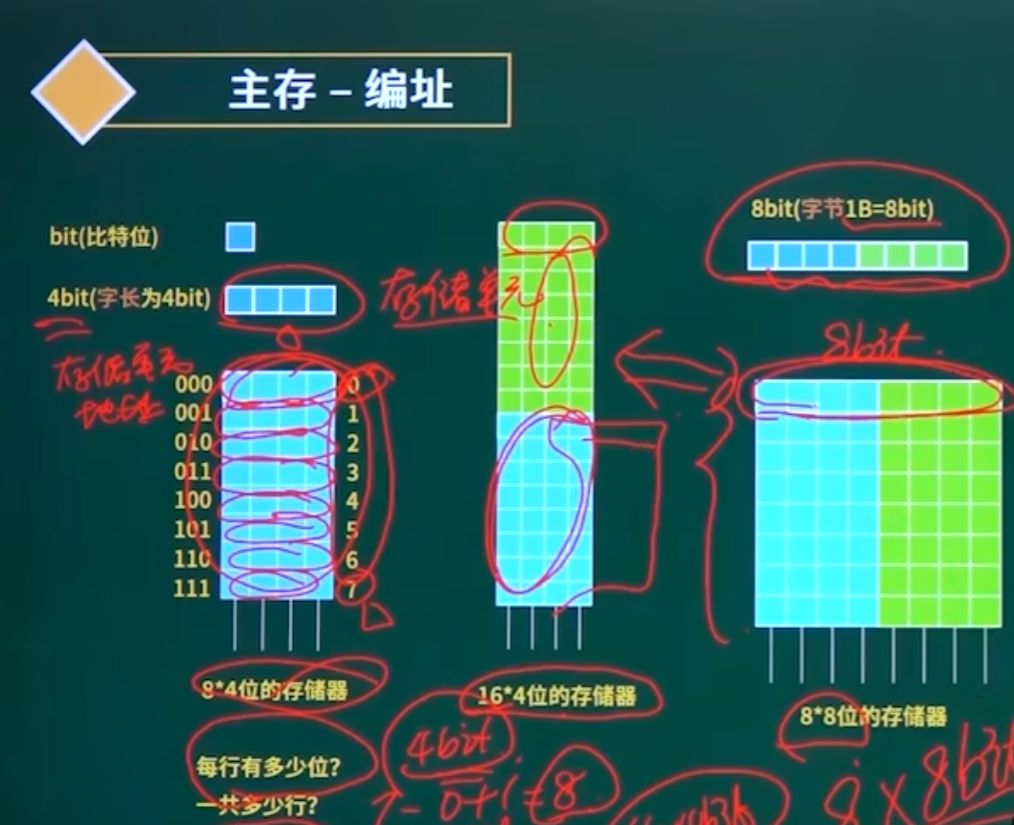
1. 主存编址的基本单位
-
位(bit):最小单位,0或1。
-
字节(Byte):1 Byte = 8 bit(现代计算机的基本编址单位)。
-
字(Word):与CPU位数相关(如32位CPU的1 Word = 4 Byte)。
2. 关键术语
-
地址线(Address Bus):CPU通过地址线访问主存,
n根地址线可寻址2^n个单元。 -
数据线(Data Bus):决定每次读写的数据位数(如32位数据线一次传输4 Byte)。
-
存储容量:
存储单元数 × 每个单元的位数(如64K×8位表示64K个单元,每单元8位)。

主存编址计算步骤
1. 确定地址空间
-
例:若地址线为20根,按字节编址,则:
-
可寻址空间 =
2^20 = 1MB(因为2^20 Byte = 1MB)。 -
地址范围:
0x00000 ~ 0xFFFFF(十六进制)。
-
2. 计算芯片数量
-
需求容量 vs 芯片容量:
-
若需
64KB主存,使用16K×4位的存储芯片:-
数量 = (总容量) / (单芯片容量) =
(64K×8) / (16K×4) = 8片。
-
-
连接方式:位扩展 + 字扩展(见下文)。
-
3. 地址分配与片选逻辑
-
地址线分配:
-
低位地址线连接芯片内部地址(如
16K=2^14,需14根地址线A0~A13)。 -
高位地址线通过译码器生成片选信号(如剩余
A14~A15用于片选)。
-
-
片选信号:通过译码器(如2-4译码器)选择不同芯片组。
例题
题型1:计算主存容量
-
题目:CPU地址线24根,按字节编址,主存容量是多少?
-
解法:
-
可寻址单元数 =
2^24 = 16M。 -
容量 =
16M × 1 Byte = 16MB。
-
题型2:存储芯片扩展
-
题目:用
8K×8位芯片扩展为32K×16位主存,需多少芯片?如何连接? -
解法:
-
字扩展:容量从
8K→32K,需32K/8K=4组。 -
位扩展:位数从
8位→16位,需16/8=2片/组。 -
总芯片数 =
4组 × 2片/组 = 8片。 -
连接图:
-
低位地址线
A0~A12连接所有芯片(8K=2^13)。 -
高位
A13~A14通过译码器选择组(4组需2根线)。 -
数据线:每组2片分别提供高8位和低8位。
-
-
题型3:地址范围计算
-
题目:某存储芯片地址范围为
8000H~BFFFH,求容量(按字节编址)。 -
解法:
-
计算地址跨度:
BFFFH - 8000H + 1 = 4000H。 -
转十进制:
4000H = 2^14 = 16K。 -
容量 =
16K × 1 Byte = 16KB。
-

第一步:计算内存总容量
1. 确定地址范围跨度
-
起始地址:
A0000H -
结束地址:
CFFFFH -
地址跨度 = 结束地址 - 起始地址 + 1
CFFFFH - A0000H + 1 = 30000H
-
注意:
CFFFFH - A0000H = 2FFFFH,再加1得到30000H。
-
2. 将十六进制转换为十进制
-
30000H转换为十进制:3 × 16^4 + 0 × 16^3 + 0 × 16^2 + 0 × 16^1 + 0 × 16^0 = 3 × 65536 = 196608 Byte
-
转换为KB(1KB = 1024 Byte):
196608 / 1024 = 192 KB
-
选项匹配:
D、192KB。
3. 快速验证
-
十六进制
30000H直接转换为十进制:-
30000H=3 × 64K=192KB(因为10000H=64KB)。
-
第二步:计算所需芯片数量
1. 明确芯片容量
-
题目给出芯片规格:
64K×8bit。-
64K表示地址单元数(字扩展)。 -
8bit表示每个单元的数据位数(位扩展)。
-
-
芯片容量 =
64K × 1 Byte=64KB(因为8bit = 1Byte)。
2. 计算芯片数量
-
总内存容量 =
192KB(第一步结果)。 -
单芯片容量 =
64KB。 -
所需芯片数量 =
总容量 / 单芯片容量=192KB / 64KB = 3片。 -
选项匹配:
B、3。
3. 连接方式说明
-
由于题目要求的是按字节编址,且芯片本身是
64K×8bit(即64KB),因此:-
无需位扩展(因为
8bit已经满足字节编址要求)。 -
只需字扩展,将
3片64KB芯片的地址空间拼接为192KB。
-

















 466
466

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









