



自己遇到过的一些坑,想记录下,方便以后其他人复现更顺利。如有问题可私信联系,看到后会及时回复。
整个过程准备好apikey,中转的即可。
一、论文地址
《Text-to-SQL Empowered by Large Language Models: A Benchmark Evaluation》
https://github.com/BeachWang/DAIL-SQL
二、代码复现跑通
在github上拉去源码后,我是使用Pycharm打开的。然后根据README.md文件搭建环境。
设置环境时,您需要下载 stanford-cornlp 并解压到 ./third_party 文件夹。 接下来,您需要启动 coreNLP 服务器:
apt install default-jre
apt install default-jdk
cd third_party/stanford-corenlp-full-2018-10-05
nohup java -mx4g -cp "*" edu.stanford.nlp.pipeline.StanfordCoreNLPServer &
cd ../../此外,还要设置 Python 环境:(我使用的是python3.8,在anconda中自己创建好虚拟环境后再Pycharm中选择刚刚创建的虚拟环境,附上conda常用命令)
// 查看conda中所有虚拟环境
conda env list
// 创建虚拟环境 conda create -n [环境名称] python=[版本号]
conda create -n DAIL-SQL python=3.8
// 激活虚拟环境
conda activate [环境名称]
// 退出虚拟环境
conda deactivate [环境名称]
// 删除虚拟环境
conda remove -n [环境名称] --allconda create -n DAIL-SQL python=3.8
conda activate DAIL-SQL
python -m pip install --upgrade pip
pip install -r requirements.txt
python nltk_downloader.py在运行 python nltk_downloader.py时可能会遇到问题,可以自行下载好相应的文件,包括corpora里面的stopwords,tokenizers里面的punkt,下载链接:GitHub - nltk/nltk_data: NLTK Data
在packages中均可找到,这里也可以把tokenizers里面的punkt_tab也下载下来,后面评估的时候会用到。
然后继续:
Data Preprocess
python data_preprocess.pyPrompt Generation
我运行的是README.md文件里面提到的两种的第一种
python generate_question.py \
--data_type spider \
--split test \
--tokenizer gpt-3.5-turbo \
--max_seq_len 4096 \
--prompt_repr SQL \
--k_shot 9 \
--example_type QA \
--selector_type EUCDISQUESTIONMASK运行的时候如果遇到sentence-transformers/all-mpnet-base-v2错误,可以找到官网下载下来all-mpnet-base-v2然后在DAIL-SQL根目录创建文件夹senetence-transformers,将下载的all-mpnet-base-v2放到该目录下
Calling the LLM
Without voting:(其中openaikey是自己的apikey,我的prompt_dir是 ./dataset/process/SPIDER-TEST_SQL_9-SHOT_EUCDISQUESTIONMASK_QA-EXAMPLE_CTX-200_ANS-4096/)
python ask_llm.py \
--openai_api_key [your_openai_api_key] \
--model gpt-4 \
--question [prompt_dir]这个过程会消耗大量token
需要修改一部分代码:加入红框中圈出的代码
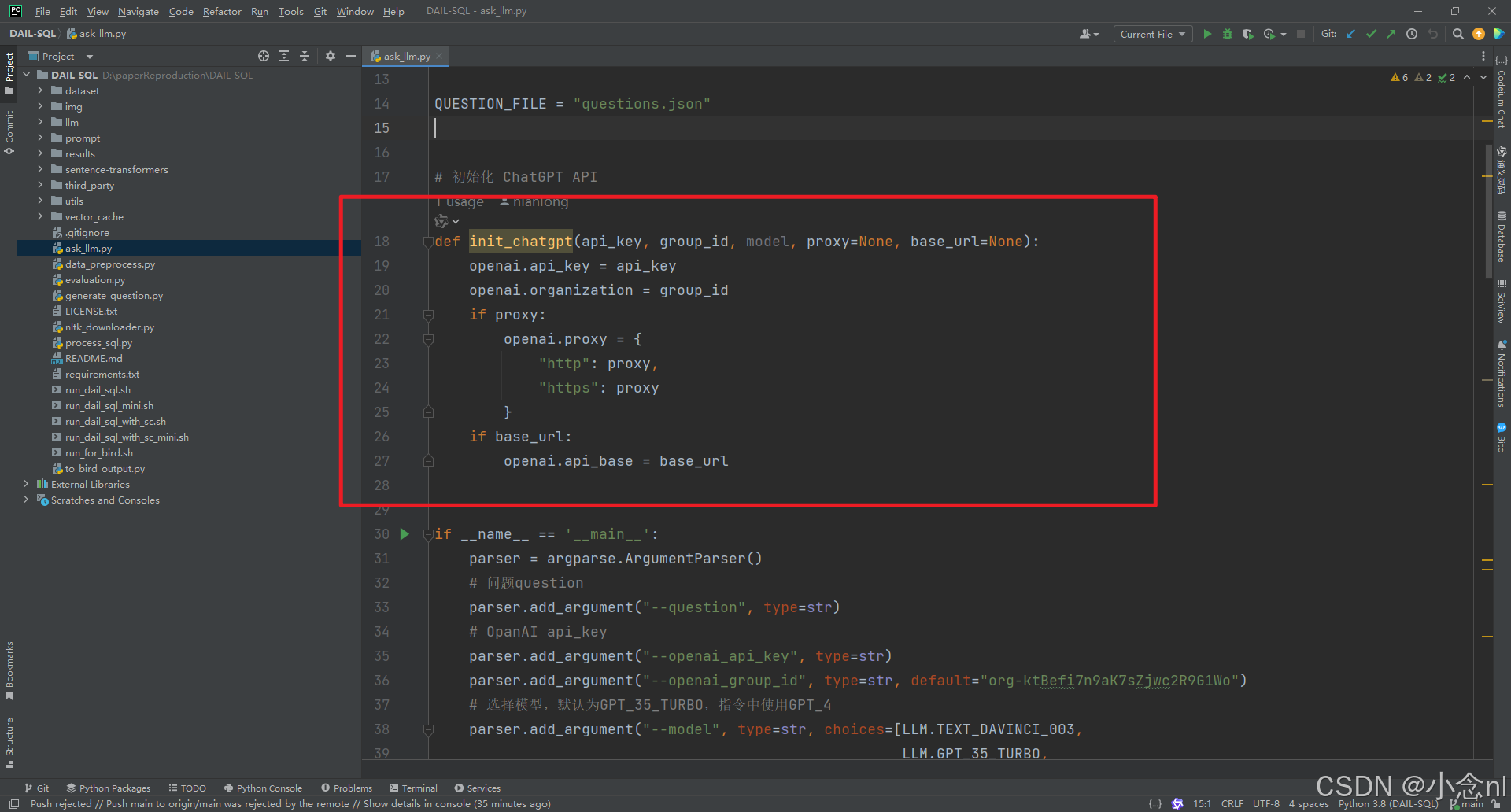
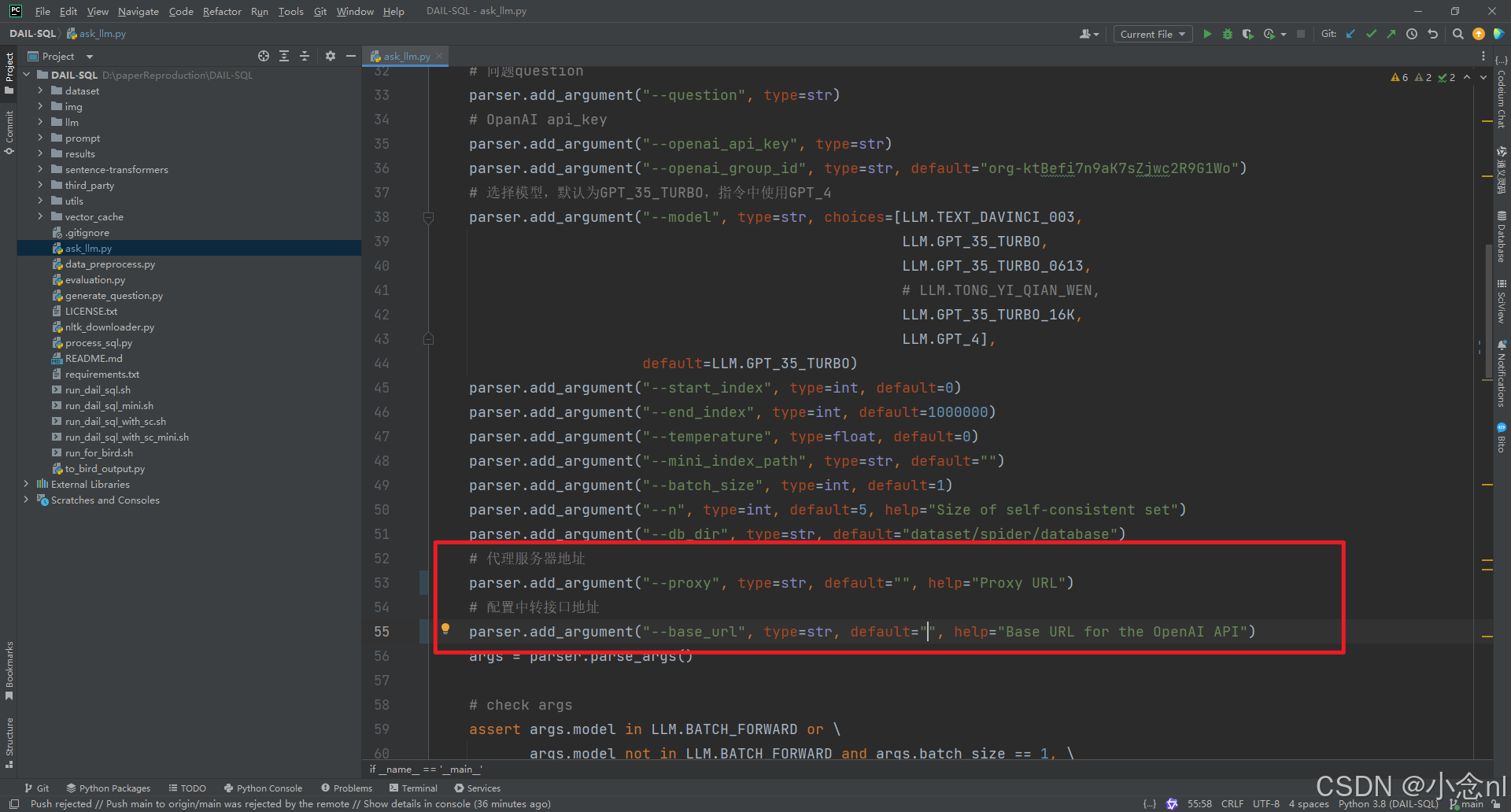
--proxy是我的代理(梯子),default填入代理的地址端口
--base_url是我的apikey的中转接口地址,在default中填入地址
然后就是
Running Example
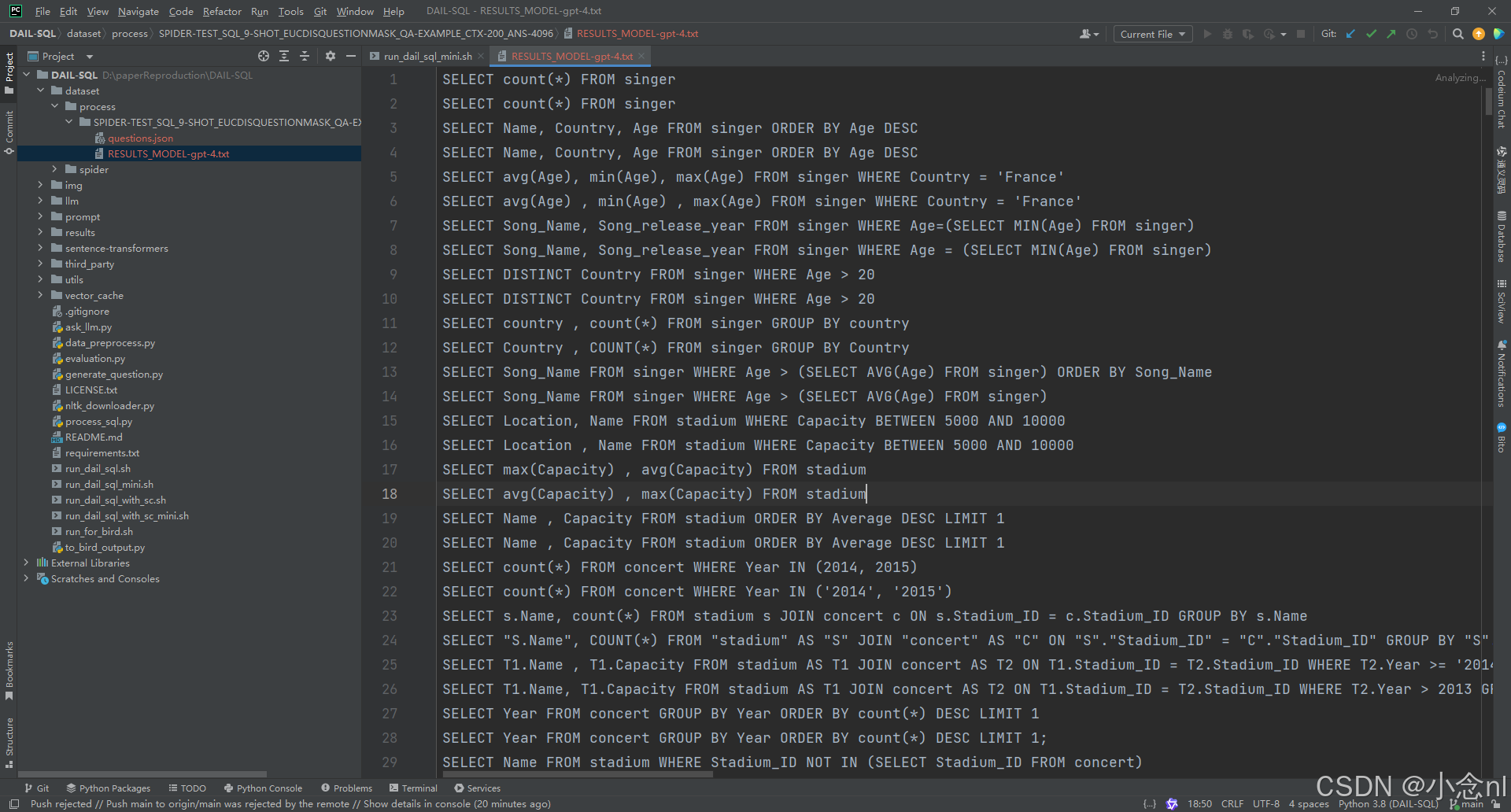
这里同样也需要apikey,可以运行下面两个命令中的任意一个,其中mini的是运行生成两条sql语句,在 ./dataset/process/SPIDER-TEST_SQL_9-SHOT_EUCDISQUESTIONMASK_QA-EXAMPLE_CTX-200_ANS-4096/下面可以看到RESULT_MODEL-gpt-4.txt,里面有2条sql语句。
如果想要多生成一些sql语句,可以修改下图中--end_index的值,修改为几则生成几条sql语句(生成sql语句是需要一定量token的)
bash run_dail_sql_mini.sh [your_openai_api_key]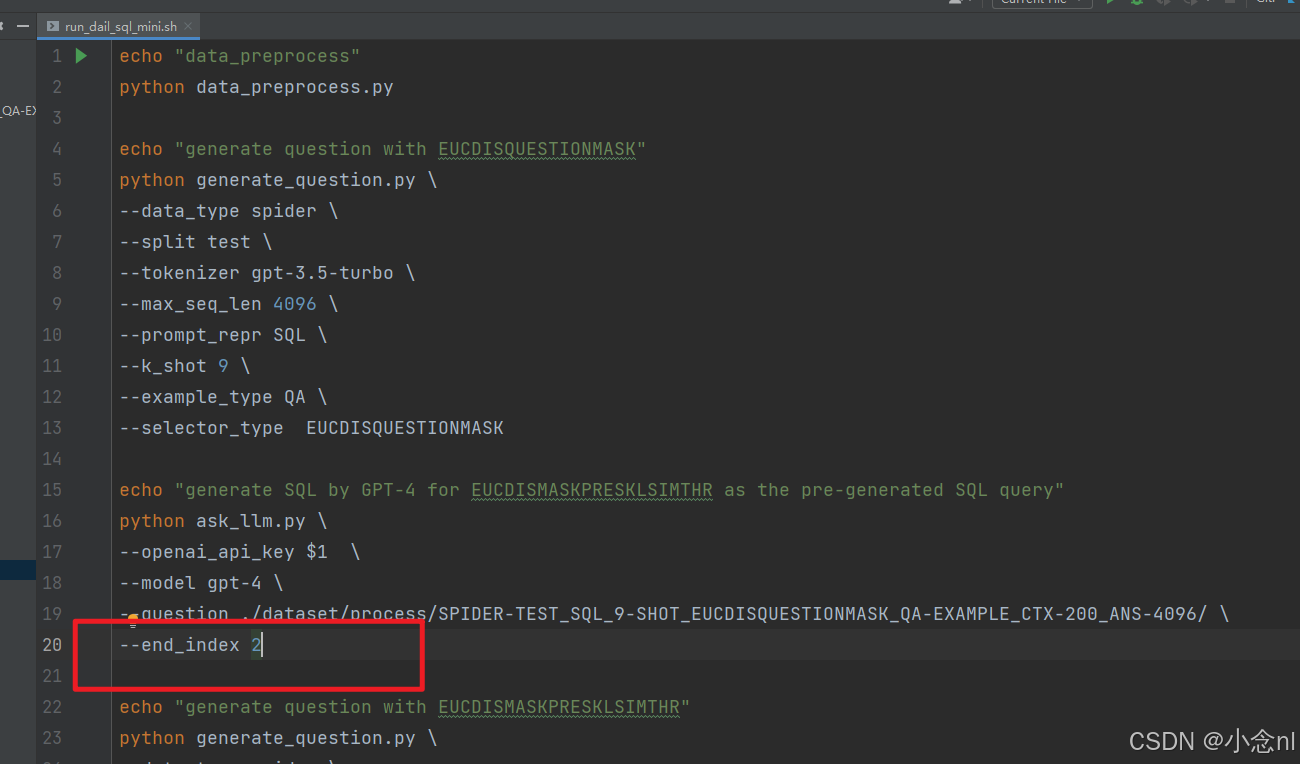
运行下面这个命令则会生成1034条sql语句,会消耗大量token,同样也是在上述路径下
bash run_dail_sql.sh [your_openai_api_key]如在上述路径的文件里面出现如下sql语句,则run阶段成功执行,接下来便是评估。
三、评估
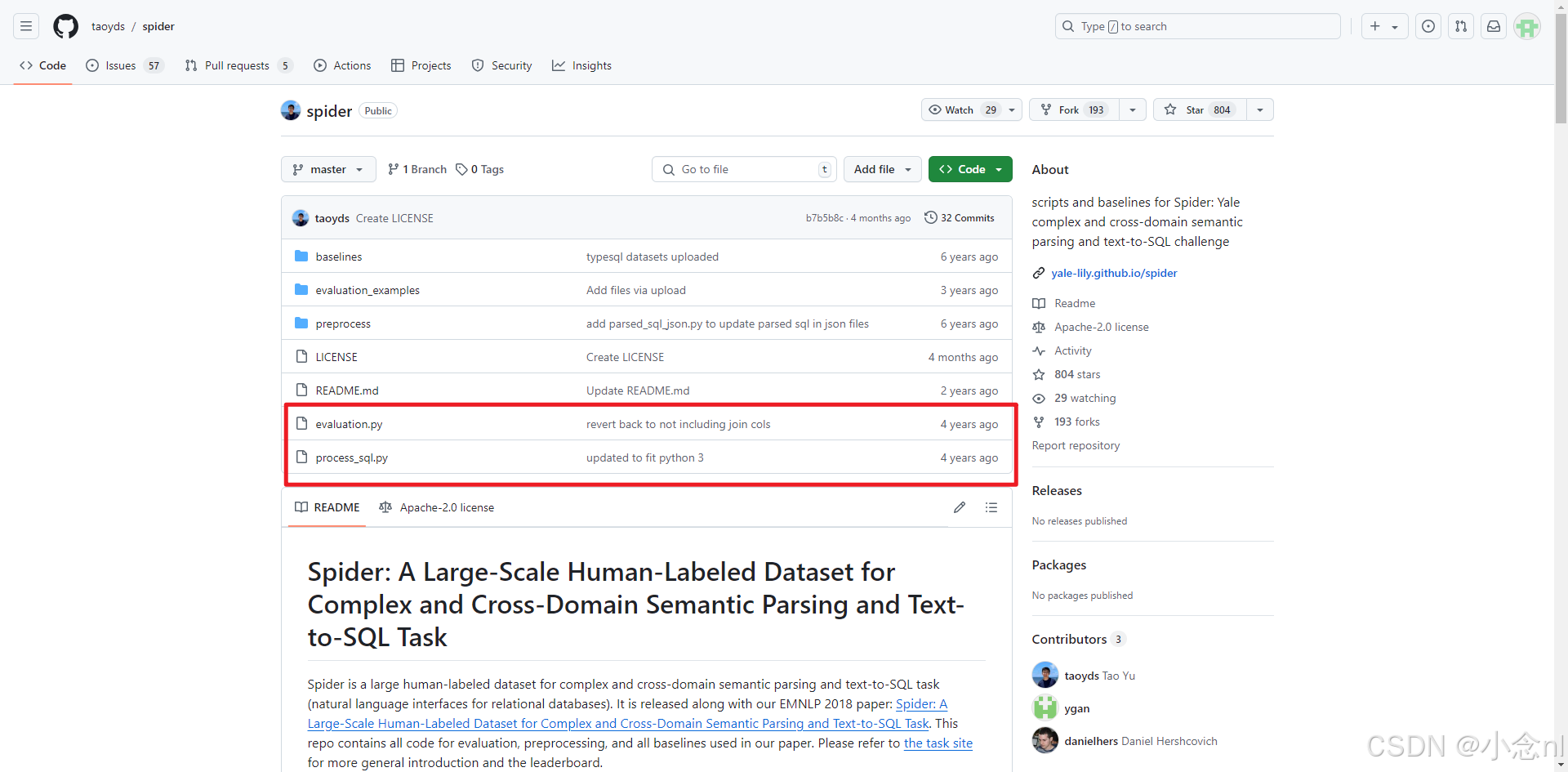
评估链接:https://github.com/taoyds/spider
进入后如下图,下载下面红框中圈出的两个.py文件,放在DAIL-SQL项目根目录,具体目录结构如上面展示sql文件的图片所示:
然后往下滑找到下图红框圈出的python命令,我是把python3改为python能成功运行。
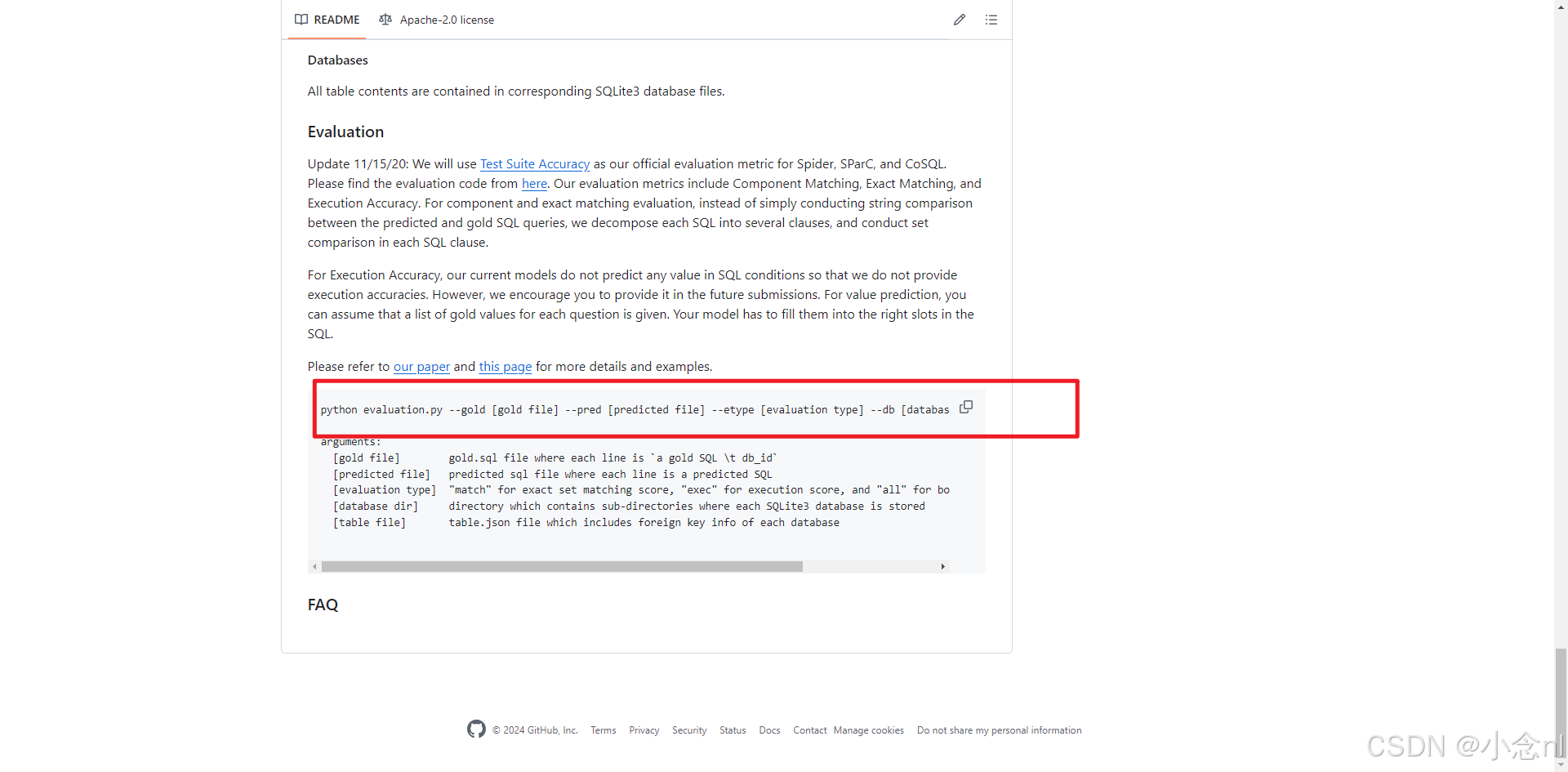
命令:
python evaluation.py --gold [gold file] --pred [predicted file] --etype [evaluation type] --db [database dir] --table [table file]其中--gold:dataset/spider/dev_gold.sql
--pred:dataset/process/SPIDER-TEST_SQL_9-SHOT_EUCDISQUESTIONMASK_QA-EXAMPLE_CTX-200_ANS-4096/RESULTS_MODEL-gpt-4.txt
--etype:all
--db:dataset/spider/database
--table:dataset/spider/tables.json
具体路径根据自己项目来。
然后运行即可成功。
到这里恭喜你完成了DAIL-SQL的整体代码运行的复现。


















 4078
4078

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









