




在数字图像爆炸式增长的时代,如何从海量图像库中快速准确地找到所需图片,基于内容的图像检索技术提供了一种强大的解决方案。
在传统图像检索中,我们通常通过关键词或标签来搜索图片,但这种方式需要人工对图像进行标注,效率低下且带有主观性。基于内容的图像检索(Content-based Image Retrieval, CBIR)技术则颠覆了这一模式。
它根据图像内容特征及其组合,从图像库中直接找到含有特定内容的图像。无论是颜色分布、纹理模式还是物体形状,都可以成为CBIR系统检索的依据。
1. 什么是基于内容的图像检索?
CBIR是一种根据图像视觉内容进行检索的技术,其核心思想是利用图像本身包含的视觉特征,而非外部标注的文本信息,来实现图像的相似性匹配和检索。
当用户提交一张查询图像时,CBIR系统会提取该图像的视觉特征,然后与图像库中存储的特征进行相似度比较,最后返回视觉内容最相似的图像。
与传统的基于文本的图像检索相比,CBIR具有多项显著优势:
- 无需人工标注:自动提取特征,节省大量人力成本
- 客观一致:避免因主观判断导致的标注差异
- 发现隐藏模式:能够根据视觉相似性发现人类难以察觉的图像模式
- 多维度检索:可以同时结合颜色、纹理、形状等多种特征进行检索
2. CBIR的基本原理与技术架构
一个典型的CBIR系统包括两个核心步骤:特征提取和相似性匹配。
2.1 特征提取
特征提取是基于内容的图像检索的基础,决定了系统能够捕捉的图像信息类型和粒度。CBIR系统使用的图像特征主要分为以下几种类型:
颜色特征:是最直观的视觉特征,包括颜色直方图、颜色矩和颜色聚合向量等。颜色特征对图像旋转、平移和尺度变化不敏感,计算简单,但无法捕捉图像的空间结构信息。
纹理特征:反映图像中同质现象的视觉模式,如平滑度、粗糙度和规律性。常用的纹理特征提取方法包括局部二值模式(LBP)、方向梯度直方图(HOG)等。纹理特征在医学影像分析等领域尤为重要。

形状特征:描述图像中物体的轮廓和区域特性。形状特征可以分为基于边界的特征(如傅里叶描述子)和基于区域的特征(如矩不变量)。形状特征对遮挡和变形较为敏感。

深度特征:随着深度学习的发展,利用卷积神经网络(CNN)提取的图像特征已成为主流。深度特征能够捕捉图像的语义信息,显著缩小了底层特征与高层语义之间的"语义鸿沟"。
2.2 相似性匹配与检索
在提取图像特征后,系统需要一种方法来度量图像之间的相似性。常用的相似性度量方法包括:
- 欧氏距离:衡量特征空间中的直线距离
- 余弦相似度:关注特征向量的方向而非大小
- 汉明距离:用于比较二进制哈希码的差异
为了提高大规模图像检索的效率,哈希算法被广泛使用。它将高维图像特征量化为低维二进制编码,在减少存储和计算成本的同时,保持特征的判别能力。
3. CBIR的查询方式
CBIR系统提供多种查询方式,以适应不同的应用场景和用户需求:
- 示例查询:最常用的查询方式,用户提供一张示例图像,系统查找与之视觉内容相似的图像。这种方式直观友好,但可能受限于用户对示例图像与系统理解之间的差异。
- 草图查询:用户绘制草图,系统从草图中提取特征并进行检索。这种方式为用户提供了更大的创作空间,但兼容性较差,可能增加用户负担。
- 类别浏览:当用户没有明确查询目标时,可以按照系统分类体系浏览图像库,发现感兴趣图像后再进行示例查询。
4. CBIR的发展历程
图像检索技术经历了从手工特征到深度特征的演进过程,主要可以分为三个阶段:
4.1 全局特征阶段
在CBIR的早期,研究主要集中在全局特征的提取上。研究人员使用颜色直方图、纹理统计和形状描述符等特征,这些特征简单直观,易于计算,但在复杂图像上的检索效果有限。
4.2 局部特征阶段
进入21世纪,局部特征的提取成为研究热点。SIFT(尺度不变特征变换)和SURF(加速鲁棒特征,SIFT的改进版)等技术应运而生,它们通过关注图像的特定区域或兴趣点,提高了检索的准确性和稳定性。

SIFT特征对图像的尺度、旋转、光照变化具有很强的鲁棒性,如上图中右侧书籍与左图中的摆放角度有很大的变化,仍然能够被捕捉到很多相似的特征。
同时,特征聚合技术如BoVW(视觉词袋模型)、VLAD(局部聚合描述符向量)和FV(Fisher向量)被开发出来,将局部特征汇总为全局图像表示。
以BoVW模型为例,其精髓在于,它通过聚类将高维、稀疏且数量不定的局部特征(如SIFT矢量是128维,一幅图可能有几百到几千个SIFT特征,在进行下游机器学习计算时,这个计算量非常大,效率很低),转换成了一个低维、稠密的固定长度直方图向量。这种表示方式极大地简化了后续的图像分类或检索任务。BoVW模型最核心的局限性在于将图像视为“单词”的无序集合,无法表征物体各部分之间的空间关系。例如,一张人脸图片和一张将人眼、鼻子、嘴巴打乱分布的图片,用基础BoVW表示可能是一样的。
4.3 深度特征阶段
近十年来,随着深度学习特别是卷积神经网络(CNN) 的发展,CBIR进入了深度特征阶段。
深度特征能够捕捉图像的语义信息,显著提高了检索精度。常用的CNN模型包括VGG16、ResNet和DarkNet53等。研究表明,在ImageNet等大规模数据集上预训练的CNN模型,即使不经微调,也能提取出具有高度判别性的图像特征。
训练一个高性能的CNN模型需要大量的标注数据和计算资源。为了解决这个问题,迁移学习(Transfer Learning) 被广泛应用。研究者们通常使用在大型图像数据集(如ImageNet)上预训练好的模型(如VGG, ResNet, Inception等),然后将这些模型作为特征提取器,直接应用于新的CBIR任务。这些预训练模型已经学习到了丰富的通用视觉知识,因此即使在新的数据集上只有少量标注数据,也能取得很好的效果。例如,VGG-19和ResNet-152是两个在CBIR中常用的预训练模型。在一个[包含500张图像、25个类别的测试数据库](pochih/CBIR: 🏞 A content-based image retrieval (CBIR) system)中,使用ResNet-152提取的特征进行检索,其平均精度均值(Mean Average Precision, MAP)达到了0.944,远超基于颜色、纹理、形状的传统特征。这充分证明了深度特征在图像表示上的优越性。
| 特征提取方法 | 类型 | 平均精度均值 (MAP) @ K=10 |
|---|---|---|
| ResNet-152 | 深度学习 | 0.944 |
| VGG-19 | 深度学习 | 0.914 |
| RGB 直方图 | 颜色 | 0.614 |
| HOG | 形状 | 0.450 |
| Daisy | 形状 | 0.468 |
| Gabor | 纹理 | 0.346 |
| 边缘直方图 | 形状 | 0.301 |
数据来源: [GitHub CBIR项目](pochih/CBIR: 🏞 A content-based image retrieval (CBIR) system)
4.3.1 神经哈希(Neural Hashing)与向量压缩技术
尽管深度特征性能优越,但其高维度(通常为数百到数千维)给大规模图像检索带来了挑战。为了在保持高精度的同时提高检索效率,研究者们提出了多种向量压缩技术,其中神经哈希(Neural Hashing) 是近年来的研究热点。神经哈希通过设计特殊的神经网络结构,将高维的浮点特征向量映射为低维的二进制哈希码。这种哈希码不仅大大减少了存储空间和计算量,还能通过汉明距离等高效方式进行相似度计算。例如,一些研究通过在网络中加入量化层或利用特定的损失函数来约束网络输出,使其逼近二进制编码。此外,为了应对高维向量检索的效率问题,近似最近邻(Approximate Nearest Neighbor, ANN) 搜索算法和专门的向量数据库(如Milvus, Faiss)也被广泛应用于CBIR系统中,它们能够在牺牲少量精度的情况下,实现百万甚至十亿级别图像的快速检索。
5. CBIR系统核心架构与实现
一个完整的CBIR系统不仅仅是特征提取算法的堆砌,它需要一个清晰、高效的架构来支撑从图像输入到结果输出的整个流程。这个架构通常包括图像预处理、特征提取与索引构建、相似度计算与排序等核心模块。对于大规模图像检索场景,还需要引入向量数据库和近似最近邻(ANN)搜索等关键技术来保证系统的实时响应能力。此外,一个优秀的CBIR系统还应具备用户反馈机制,通过用户的交互来不断优化检索结果,提升用户体验。本章节将详细解析CBIR系统的核心架构,并提供基于Python和OpenCV的实现示例,帮助读者从理论走向实践。
5.1 系统基本流程:从图像输入到结果输出
CBIR系统的基本工作流程可以概括为“离线建库,在线检索”。在离线阶段,系统需要对数据库中的所有图像进行预处理,提取其视觉特征,并将这些特征向量化后存储在索引文件中。在线检索阶段,系统接收用户输入的查询图像,同样提取其特征向量,然后与索引库中的特征向量进行相似度计算,最后将最相似的图像按序返回给用户。这个流程看似简单,但每个环节都涉及到关键的技术选择和优化,直接影响着系统的最终性能和用户体验。
5.1.1 图像预处理与归一化
图像预处理是CBIR流程的第一步,其目的是消除图像中无关的信息,增强有用信息,并将图像转换为适合后续特征提取的标准格式。常见的预处理操作包括尺寸归一化、颜色空间转换和噪声滤除。尺寸归一化是指将所有输入图像调整为统一的尺寸,这对于需要固定长度输入向量的模型(如全连接神经网络)至关重要。例如,在使用ResNet50进行特征提取时,通常会将图像调整为224x224或440x440像素。颜色空间转换,如从RGB转换到HSV或灰度空间,可以简化计算或突出特定的视觉特征。例如,在基于颜色的检索中,转换到HSV空间能更好地模拟人眼对颜色的感知。噪声滤除,如使用高斯滤波或中值滤波,可以平滑图像,减少噪声对特征提取的干扰。这些预处理步骤虽然简单,但对于保证特征提取的稳定性和一致性,以及提高整个系统的鲁棒性都起着不可或缺的作用。
5.1.2 特征提取与向量化表示
特征提取是CBIR系统的核心环节,其目标是将图像转换为一个能够表征其视觉内容的数值向量,即特征向量。如前所述,这可以通过传统方法(如颜色直方图、SIFT)或深度学习方法(如CNN)来实现。无论采用何种方法,最终输出的特征向量都应该是固定长度的,以便于后续的存储和比较。例如,一个基于颜色直方图的系统可能会生成一个由多个局部直方图串联而成的特征向量。而一个基于SIFT的系统,由于每张图像提取出的关键点数量不固定,通常会采用视觉词袋模型(Bag of Visual Words, BoVW)或其变种(如VLAD, Fisher Vector)将这些局部特征聚合成一个固定长度的全局特征向量。对于基于CNN的系统,通常会从预训练模型的特定层(如ResNet的pool5层)直接获取固定维度的特征向量。一旦特征向量被提取出来,它们就需要被持久化存储,这个过程称为“索引化”或“建库”。通常会创建一个索引文件,其中每一行对应数据库中的一张图像,包含图像ID和其对应的特征向量,以CSV或其他格式存储。
5.1.3 相似度计算与排序(欧氏距离、余弦相似度)
当系统接收到查询图像并提取出其特征向量后,下一步就是计算该查询向量与索引库中所有特征向量之间的相似度。相似度的计算是CBIR检索的关键,它决定了哪些图像会被认为是“相似”的。常用的相似度(或距离)度量方法包括欧氏距离(Euclidean Distance) 、余弦相似度(Cosine Similarity) 和卡方距离(Chi-Squared Distance) 等。欧氏距离是最直观的距离度量,它计算两个向量在多维空间中的直线距离,距离越小表示越相似。余弦相似度则衡量两个向量方向上的夹角,夹角越小(余弦值越接近1),表示两个向量的方向越一致,即内容越相似,它对向量的长度不敏感,适用于特征值大小差异较大的情况。卡方距离常用于比较直方图,它对小的频率变化不敏感,能够更好地衡量两个分布之间的差异。在计算出所有相似度后,系统会根据相似度得分对结果进行排序,并将得分最高(或距离最小)的前N张图像作为检索结果返回给用户。
5.2 大规模图像检索的关键技术
当图像数据库的规模达到百万甚至数十亿级别时,传统的线性扫描(即逐一计算查询向量与库中所有向量的距离)方法将变得非常低效,无法满足实时检索的需求。因此,需要引入更高效的技术来加速检索过程。
5.2.1 向量数据库(如Milvus)在CBIR中的作用
向量数据库是专门为存储和检索高维向量而设计的数据库系统。与传统的关系型数据库不同,向量数据库的核心功能是高效地执行相似度搜索。Milvus是一个开源的、高性能的向量数据库,它在CBIR系统中扮演着至关重要的角色。在一个典型的应用中,如BestPay的照片欺诈检测系统“Zhentu”,首先使用深度学习模型将海量的营业执照照片转化为高维特征向量,然后将这些向量插入到Milvus数据库中。当需要进行欺诈检测时,系统将待查询照片的特征向量在Milvus中进行相似度搜索,Milvus能够在毫秒级的时间内从数千万张图片中高效地检索出最相似的照片。这极大地提升了系统的实时处理能力,使得大规模图像检索成为可能。
5.2.2 近似最近邻(ANN)搜索算法优化
为了在庞大的向量空间中进行快速搜索,向量数据库通常采用近似最近邻(Approximate Nearest Neighbor, ANN) 搜索算法。与精确搜索(Exact Search)不同,ANN算法通过牺牲一定的精度来换取巨大的性能提升。常见的ANN算法包括基于树的算法(如KD-Tree、Annoy)、基于哈希的算法(如LSH)和基于图的算法(如HNSW)。这些算法通过构建高效的索引结构,将搜索空间限制在一个很小的范围内,从而避免了全局扫描。例如,HNSW(Hierarchical Navigable Small World) 算法通过构建一个多层的、可导航的小世界图,能够在高维空间中实现亚线性的搜索复杂度,是目前性能最优秀的ANN算法之一。
5.2.3 用户反馈机制与检索结果优化
为了进一步提升检索的准确性,许多CBIR系统引入了用户反馈机制,即相关性反馈(Relevance Feedback) 。该机制的核心思想是“Human-in-the-Loop”,通过用户的交互来优化检索结果。具体流程是:系统首先返回一个初始的检索结果列表,然后让用户标记出哪些结果是相关的,哪些是不相关的。系统根据用户的反馈信息,自动调整查询特征向量(例如,将查询向量向相关结果的特征中心移动,远离不相关结果的特征中心),然后使用更新后的查询向量进行新一轮的检索。这个过程可以迭代多次,直到用户满意为止。相关性反馈机制能够有效地捕捉用户的真实意图,从而显著提高检索的精准度。
5.3 系统实现示例代码
为了帮助读者更好地理解CBIR系统的实现细节,本节将提供两个基于Python和OpenCV的示例代码。第一个示例将展示如何结合颜色直方图和SIFT特征进行图像检索,体现了传统特征融合的思路。第二个示例则演示如何利用强大的预训练ResNet模型进行深度特征提取和检索,代表了当前的主流技术方向。这些代码示例旨在提供一个可运行的基础框架,读者可以根据自己的需求进行修改和扩展。
5.3.1 基于颜色直方图与SIFT特征融合的Python实现
这个示例将展示如何构建一个简单的CBIR系统,该系统结合了颜色直方图和SIFT特征。颜色直方图用于捕捉图像的全局颜色分布,而SIFT特征则用于描述图像的局部结构和关键点信息。通过融合这两种特征,系统可以在一定程度上兼顾全局和局部信息,提高检索的准确性。
import cv2
import numpy as np
import os
from scipy.spatial import distance
class ImageFeatureExtractor:
def __init__(self, hist_bins=25, sift=True):
self.hist_bins = hist_bins
self.sift = sift
if sift:
self.sift_extractor = cv2.SIFT_create()
def describe(self, image_path):
# 读取图像
image = cv2.imread(image_path)
if image is None:
return None
# 提取RGB直方图
hist = self._compute_color_histogram(image)
# 提取SIFT特征
if self.sift:
kp, des = self._compute_sift_features(image)
else:
des = None
return (hist, des)
def _compute_color_histogram(self, image):
# 计算RGB直方图
hist = cv2.calcHist([image], [0, 1, 2], None, [self.hist_bins]*3, [0, 256]*3)
# 归一化
cv2.normalize(hist, hist)
return hist.flatten()
def _compute_sift_features(self, image):
# 转换为灰度
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 检测关键点和描述符
kp, des = self.sift_extractor.detectAndCompute(gray, None)
return kp, des
def compare_images(query_features, image_path, feature_extractor):
# 提取目标图像的特征
target_features = feature_extractor.describe(image_path)
if target_features is None:
return float('inf')
# 比较直方图
hist_dist = cv2.compareHist(query_features[0], target_features[0], cv2.HISTCMP_BHATTACHARYYA)
# 比较SIFT特征
if feature_extractor.sift:
if target_features[1] is None or query_features[1] is None:
sift_dist = float('inf')
else:
# 使用BFMatcher匹配SIFT描述符
matcher = cv2.BFMatcher()
matches = matcher.knnMatch(query_features[1], target_features[1], k=2)
# 应用ratio test
good_matches = []
for m, n in matches:
if m.distance < 0.7 * n.distance:
good_matches.append(m)
sift_dist = len(good_matches)
else:
sift_dist = 0
# 综合距离
if feature_extractor.sift:
return hist_dist * 0.5 + (1 - sift_dist / len(query_features[1])) * 0.5
else:
return hist_dist
def retrieve_images(query_image_path, image_dir, feature_extractor):
query_features = feature_extractor.describe(query_image_path)
if query_features is None:
return []
# 遍历图像数据库
image_files = [os.path.join(image_dir, f) for f in os.listdir(image_dir) if f.lower().endswith(('.jpg', '.jpeg', '.png'))]
# 计算相似度
scores = []
for img_path in image_files:
score = compare_images(query_features, img_path, feature_extractor)
scores.append((img_path, score))
# 排序
scores.sort(key=lambda x: x[1])
return scores
# 使用示例
if __name__ == '__main__':
image_dir = 'path/to/image/directory'
query_path = 'path/to/query/image.jpg'
extractor = ImageFeatureExtractor(hist_bins=25, sift=True)
results = retrieve_images(query_path, image_dir, extractor)
# 添加调试信息
print(f"总共找到 {len(results)} 张图片")
# 清除可能的重复项
unique_results = []
seen_paths = set()
for item in results:
if item[0] not in seen_paths:
unique_results.append(item)
seen_paths.add(item[0])
# 打印结果
print("去重后的检索结果:")
for rank, (img_path, score) in enumerate(unique_results):
print(f"Rank {rank+1}: {img_path}, Score: {score}")
本地执行结果如下图
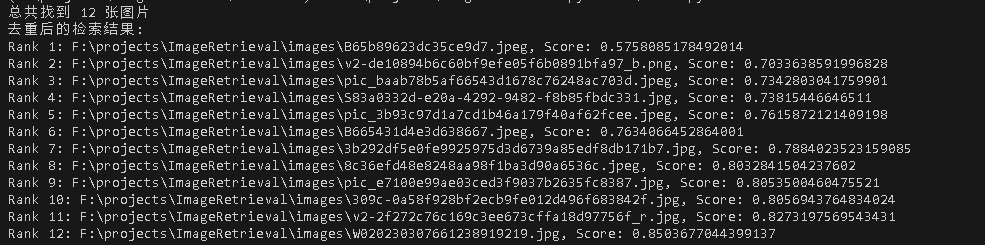
这段代码首先定义了一个ImageFeatureExtractor类,其describe方法负责读取图像并调用内部方法分别计算RGB颜色直方图和SIFT特征。颜色直方图通过cv2.calcHist计算,并进行归一化处理。SIFT特征则通过OpenCV的cv2.SIFT_create()检测器和描述符提取器获得。在compare_images函数中,系统分别计算查询图像和目标图像在颜色直方图上的巴氏距离(Bhattacharyya distance),以及SIFT特征的匹配程度。对于SIFT特征,使用了BFMatcher进行暴力匹配,并应用了Lowe’s ratio test来筛选出高质量的匹配点。最后,通过一个加权求和的方式将两种特征的相似度得分融合起来,得到最终的图像间距离。retrieve_images函数则负责遍历整个图像数据库,计算查询图像与每张图像的相似度得分,并按得分升序排列,返回最相似的图像列表。这个融合系统能够有效地结合颜色和形状信息,在金融领域的票据识别、钞票真伪验证等场景中具有广泛的应用前景。
5.3.2 基于预训练ResNet模型的特征提取与检索
在构建一个基于深度学习的CBIR系统时,利用预训练的卷积神经网络(CNN)模型进行特征提取是一种高效且常用的方法。这种方法的核心思想是利用在大规模数据集(如ImageNet)上训练好的模型,这些模型已经学习到了丰富的图像特征,可以作为通用的特征提取器。在本示例中,我们选择了ResNet50模型,它是一个深度残差网络,通过引入残差连接有效地解决了深度网络训练中的梯度消失问题,能够提取出更具表达力的图像特征。具体的实现步骤如下:首先,加载预训练的ResNet50模型,并移除其顶层的分类层,只保留卷积基部分。然后,在卷积基的末尾添加一个全局平均池化层,将多维的特征图转换为一个固定长度的特征向量。这个特征向量就可以作为图像的最终表示,用于后续的相似度计算和检索。
在代码实现中,我们首先定义了一个extract_features函数,该函数接收一个图像路径和一个预训练模型作为输入,对图像进行预处理(如调整大小、归一化等),然后将其输入到模型中,提取出特征向量。接着,我们定义了一个build_features_db函数,该函数遍历指定目录下的所有图像,调用extract_features函数提取每张图像的特征,并将所有特征向量存储在一个NumPy数组中,同时将对应的文件名保存到一个文本文件中,从而构建一个图像特征数据库。最后,我们定义了一个search_similar_images函数,该函数接收一个查询图像的路径、特征数据库和文件名列表作为输入,首先提取查询图像的特征向量,然后计算该特征向量与数据库中所有特征向量的欧氏距离,并根据距离从小到大进行排序,返回最相似的前K张图像的文件名。通过这种方式,我们可以实现一个简单而有效的基于深度学习的CBIR系统。然而,需要注意的是,由于预训练模型是在通用数据集上训练的,其提取的特征可能并不完全适用于特定的应用场景。因此,在实际应用中,通常会采用微调(fine-tuning) 的策略,即在预训练模型的基础上,使用特定领域的数据集进行进一步的训练,以使模型学习到更具针对性的特征,从而提高检索的准确率。
import torch
import torch.nn as nn
import torchvision.models as models
import torchvision.transforms as transforms
from PIL import Image
import numpy as np
import os
from sklearn.metrics.pairwise import euclidean_distances
class DeepFeatureExtractor:
def __init__(self):
# 加载预训练的ResNet50模型
self.model = models.resnet50(pretrained=True)
# 移除顶层的分类层,只保留卷积基部分
self.model = nn.Sequential(*list(self.model.children())[:-1])
self.model.eval() # 设置为评估模式
# 定义图像预处理步骤
self.preprocess = transforms.Compose([
transforms.Resize((224, 224)), # ResNet要求输入224x224大小
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # ImageNet标准化参数
])
def extract_features(self, image_path):
"""
提取单张图像的特征向量
"""
try:
# 读取图像
image = Image.open(image_path).convert('RGB')
# 预处理图像
input_tensor = self.preprocess(image)
input_batch = input_tensor.unsqueeze(0) # 添加批次维度
# 提取特征
with torch.no_grad():
features = self.model(input_batch)
# 使用全局平均池化将特征图转换为特征向量
features = torch.flatten(features, 1)
# 转换为numpy数组
features = features.numpy().flatten()
return features
except Exception as e:
print(f"处理图像 {image_path} 时出错: {e}")
return None
def build_features_db(image_dir, feature_extractor):
"""
构建图像特征数据库
"""
# 获取所有图像文件路径
image_files = [os.path.join(image_dir, f) for f in os.listdir(image_dir)
if f.lower().endswith(('.jpg', '.jpeg', '.png'))]
features_list = []
valid_files = []
# 提取每张图像的特征
for img_path in image_files:
features = feature_extractor.extract_features(img_path)
if features is not None:
features_list.append(features)
valid_files.append(img_path)
# 将特征存储为NumPy数组
features_db = np.array(features_list)
return features_db, valid_files
def search_similar_images(query_image_path, features_db, file_list, feature_extractor, top_k=10):
"""
搜索相似图像
"""
# 提取查询图像的特征
query_features = feature_extractor.extract_features(query_image_path)
if query_features is None:
return []
query_features = query_features.reshape(1, -1)
# 计算欧氏距离
distances = euclidean_distances(query_features, features_db)[0]
# 根据距离排序
sorted_indices = np.argsort(distances)
# 返回最相似的前K张图像
results = []
for i in range(min(top_k, len(sorted_indices))):
idx = sorted_indices[i]
results.append((file_list[idx], distances[idx]))
return results
# 使用示例
if __name__ == '__main__':
# 设置路径
image_dir = 'F:\\projects\\ImageRetrieval\\images'
query_path = 'F:\\projects\\ImageRetrieval\\images_to_query\\query_image.jpg'
# 创建特征提取器
extractor = DeepFeatureExtractor()
# 构建特征数据库
print("正在构建特征数据库...")
features_db, file_list = build_features_db(image_dir, extractor)
print(f"特征数据库构建完成,共处理 {len(file_list)} 张图像")
# 搜索相似图像
print("正在搜索相似图像...")
results = search_similar_images(query_path, features_db, file_list, extractor, top_k=10)
# 打印结果
print("检索结果:")
for rank, (img_path, distance) in enumerate(results):
print(f"Rank {rank+1}: {img_path}, Distance: {distance}")
本地执行结果如下图
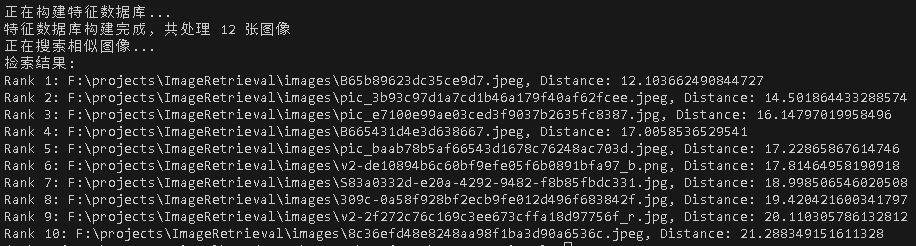
6. CBIR在金融行业的深度应用
金融行业是数据密集型行业,每天产生海量的图像数据,如票据、证件、合同、理赔照片等。如何高效、准确地管理和利用这些图像数据,对于提升业务效率、加强风险控制至关重要。CBIR技术以其强大的图像分析和检索能力,在金融领域的多个场景中展现出巨大的应用价值。
6.1 金融风控与欺诈检测
金融欺诈是金融机构面临的重大挑战之一,而图像欺诈是其中一种常见的手段。欺诈者可能通过伪造、篡改或重复使用图像来骗取保险金、盗用账户或进行虚假交易。CBIR技术,特别是基于深度学习的图像相似性检测,为识别此类欺诈行为提供了有效的解决方案。
6.1.1 保险理赔中的图像欺诈识别(重复、PS、翻拍)
在保险理赔流程中,客户需要提交事故现场的损失照片。传统的审核方式主要依赖人工,不仅耗时耗力,而且容易出错。欺诈者常常利用这一点,通过提交重复的照片、经过Photoshop等软件篡改的照片,或者翻拍电脑屏幕上的旧照片来骗取赔款。CBIR系统可以有效地应对这些欺诈手段。系统首先会建立一个历史理赔图像数据库。当收到新的理赔申请时,系统会提取新图像的深度特征,并与数据库中的所有图像进行相似性比对。如果系统发现新图像与数据库中某张图像的相似度超过预设阈值,就会发出警报,提示审核人员进行人工复核。用PS的照片申请理赔,保险公司能过吗?-腾讯云开发者社区-腾讯云中就提到了保险行业进行二次理赔时的CBIR应用。
6.1.2 支付机构的照片欺诈检测系统(如BestPay的“Zhentu”)
支付机构在开户、实名认证等环节也需要用户上传身份证件、银行卡等照片。这些环节同样面临照片欺诈的风险,例如使用伪造证件或他人证件进行开户。一些领先的支付机构已经开始应用CBIR技术来构建智能风控系统。例如,中国电信旗下的支付公司翼支付(BestPay)就推出了名为“Zhentu”(侦图)的图像反欺诈系统。该系统利用深度学习模型对用户上传的证件照片进行多维度的分析,包括证件真伪识别、人像比对、翻拍检测等。通过将用户上传的照片与权威数据库中的照片进行比对,系统可以有效防止身份冒用。同时,系统还能检测出照片是否为屏幕翻拍或打印件翻拍,从而拦截使用伪造证件的攻击。这种基于CBIR的实时图像风控能力,极大地提升了支付账户的安全性。
6.1.3 商业银行反欺诈智能风控系统中的图像分析
商业银行的业务范围广泛,从信贷审批到日常交易,都可能涉及图像数据。例如,在信用卡申请中,申请人需要提交收入证明、工作证明等材料,这些材料可能是扫描件或照片。欺诈者可能会伪造这些文件。CBIR系统可以通过分析文档的版式、字体、印章等视觉特征,与真实样本库进行比对,从而识别出伪造文件。此外,在交易监控中,如果一笔交易关联了地理位置信息(如IP地址对应的街景图像),CBIR系统可以分析该交易地点的图像与用户历史交易地点的图像是否一致,从而辅助判断交易是否存在异常。比如小雨点火眼系统 基于CBIR在经营场所图片识别方面进行欺诈预警。虽然机器学习在金融欺诈检测中的应用更广泛地集中在结构化数据分析上,如使用逻辑回归、支持向量机(SVM)、随机森林等算法分析交易流水,但将CBIR技术融入其中,可以构建一个更全面、更多维度的反欺诈智能风控体系,实现对文本、图像等多模态数据的综合分析。
6.2 金融票据与凭证处理
金融机构每天都要处理大量的纸质票据和凭证,如支票、发票、合同等。传统的人工处理方式效率低下、成本高昂且容易出错。CBIR技术结合光学字符识别(OCR)和图像处理技术,可以实现票据处理的自动化和智能化。
6.2.1 支票、发票等票据的自动识别与检索
以银行支票处理为例,美国每年处理的支票数量高达680亿张,人工读取金额字段成本巨大。一个自动化的支票处理系统可以利用CBIR技术实现。系统首先对扫描的支票图像进行预处理,如去噪、二值化、倾斜校正等。然后,系统利用图像分割技术定位到关键信息区域,如金额栏、日期栏、签名栏等。对于金额字段,系统可以采用基于神经网络的方法进行字符分割和识别。更进一步,CBIR技术可以用于票据的检索和管理。例如,银行可以建立一个电子票据影像库。当需要查询某张特定支票或发票时,用户不再需要输入繁琐的编号,而是可以直接上传一张票据的图像,CBIR系统会自动检索出影像库中相同或相似的票据,极大地提高了查询效率。这种技术同样适用于发票管理、合同归档等场景,帮助企业实现无纸化办公和高效的文档管理。
6.2.2 客户身份认证与证件信息录入(身份证、银行卡识别)
在远程开户、移动支付等场景中,客户身份认证是关键环节。CBIR技术结合OCR,可以实现证件信息的自动录入和真伪核验。用户通过手机摄像头拍摄身份证、银行卡等证件,系统首先利用图像处理技术对证件图像进行校正和裁剪,然后利用OCR技术提取出姓名、身份证号、银行卡号等文本信息,并自动填入表单。同时,CBIR系统会将证件照片与公安、银联等权威机构的图像数据库进行比对,验证证件的真实性。此外,系统还可以进行人脸识别,将证件上的照片与用户现场拍摄的自拍照片进行比对,完成“人证合一”的验证。整个过程自动化完成,极大地简化了用户操作,提升了用户体验,同时也增强了业务的安全性。
7. CBIR在商业领域的创新实践
商业世界充满了视觉信息,从电商平台的商品图片到零售店的货架陈列,再到社交媒体的营销素材。CBIR技术通过赋予机器“看懂”这些视觉信息的能力,正在深刻地改变着商业的运作模式。它不仅优化了消费者的购物体验,也为企业提供了强大的商业智能工具,驱动着营销、运营和决策的智能化升级。
7.1 电商与零售行业的“以图搜物”
“以图搜物”是CBIR技术在商业领域最成功、最广泛的应用。它允许用户通过上传一张图片来搜索相似的商品,打破了传统基于关键词搜索的局限性,极大地提升了购物的便捷性和转化率。
7.1.1 电商平台(淘宝、京东、亚马逊)的拍照购物功能
当消费者在现实生活中看到一件心仪的商品,但不知道其名称或品牌时,“以图搜物”功能就派上了用场。用户只需用手机拍下商品的照片,上传到淘宝、京东、亚马逊等主流电商平台的App中,系统就能在数秒内从数以亿计的商品库中检索出同款或相似的商品。其背后的核心技术就是CBIR。系统首先对用户上传的图像进行特征提取,生成一个高维的特征向量。然后,系统利用高效的近似最近邻(ANN)搜索算法,在预先构建好的商品图像特征向量数据库中,快速找到与查询向量最相似的一批商品。这些商品会按照相似度得分进行排序,并展示给用户。这种直观的搜索方式,不仅降低了用户的搜索门槛,也为平台带来了显著的流量和销售额增长。例如,阿里巴巴、亚马逊和eBay等电商巨头都提供了强大的商品图像搜索功能,这已成为现代电商平台的标配。
7.1.2 跨境电商中的视觉搜索与商品匹配
在跨境电商中,语言障碍是消费者面临的一大难题。消费者可能很难用外语准确地描述自己想要购买的商品。CBIR技术为此提供了完美的解决方案。通过视觉搜索,消费者可以绕过语言障碍,直接用图片来寻找全球各地的商品。此外,对于跨境电商平台而言,商品信息的本地化翻译成本高昂且难以保证准确性。利用CBIR技术,平台可以建立一个全球统一的商品图像特征库,当用户在不同国家/地区的站点进行视觉搜索时,系统可以直接在统一的特征库中进行检索,并将结果返回给用户,而无需依赖复杂的文本翻译。这不仅提升了用户体验,也极大地降低了平台的运营成本。
7.1.3 时尚零售(如影儿时尚集团)的同款与相似商品推荐
在时尚零售领域,潮流变化迅速,消费者对款式和搭配的需求非常个性化。CBIR技术可以帮助时尚零售商(如影儿时尚集团等)更好地满足这些需求。当顾客在门店或线上浏览某件商品时,系统可以利用CBIR技术,实时地从库存中找出与当前商品在款式、颜色、图案上相似的其他商品,并向顾客推荐。这种“搭配购”或“相似款推荐”功能,可以有效提升客单价和连带率。例如,一个顾客正在看一件条纹衬衫,系统可以推荐一条与之搭配的纯色裤子,或者推荐几款不同品牌的相似条纹衬衫供其比较。这种基于视觉相似性的推荐,比传统的基于协同过滤的推荐更直观、更符合时尚行业的特点。
7.2 商业智能与营销优化
除了优化前端购物体验,CBIR技术在后端的商业智能和营销优化方面也展现出巨大的潜力。通过对海量商业图像进行分析,企业可以获得前所未有的洞察力,从而做出更明智的决策。
7.2.1 货架排面管理与商品识别
对于实体零售商(尤其是大型连锁超市),货架管理是一项复杂而重要的工作。货架上商品的陈列情况,如排面数量、位置、是否缺货等,直接影响着销售业绩。传统的管理方式依赖人工巡店,效率低且数据不准确。基于CBIR的图像识别技术可以实现货架管理的自动化。业务员或巡检机器人可以用手机或专用设备拍摄货架照片,上传到云端系统。系统利用CBIR和物体检测技术,可以自动识别出照片中的每一个商品(SKU),并计算出排面占比、缺货率等关键指标,帮助品牌方优化供应链和营销策略。
7.2.2 品牌保护与版权监测
在电商平台上,假冒伪劣产品和盗用品牌图片的现象屡禁不止,严重损害了品牌声誉和消费者权益。CBIR技术可以帮助品牌方进行有效的版权监测和品牌保护。品牌方可以将其官方产品图片和认证商家图片录入数据库。系统会持续监控电商平台上的所有商品图片,通过图像相似度比对,自动发现使用品牌官方图片的非授权商家,或者销售与正品高度相似(疑似假货)的商品。亚马逊的Brand Registry项目就利用了类似的技术,帮助品牌方主动识别和举报侵权行为,从而维护一个健康的商业生态。
8. 总结与未来展望
基于内容的图像检索(CBIR)技术,从最初依赖手工设计特征到如今由深度学习驱动,已经取得了长足的进步,并在金融、商业、医疗、安防等众多领域展现出巨大的应用价值。它成功地缩小了“语义鸿沟”,让机器能够更好地理解和检索视觉信息。然而,随着应用场景的不断深化和数据规模的持续爆炸,CBIR技术依然面临着诸多挑战,同时也孕育着新的发展机遇。
8.1 CBIR技术面临的挑战
尽管CBIR技术已经相当成熟,但在迈向更智能、更普适的应用过程中,仍需克服以下关键挑战:
8.1.1 跨模态检索(图文结合)的复杂性
传统的CBIR系统主要处理单一的图像模态。然而,在现实世界中,信息往往是以多种模态存在的,例如一张图片伴随着一段描述性的文字。如何有效地融合图像和文本这两种异构信息,实现跨模态检索(Cross-Modal Retrieval),是当前研究的热点和难点。用户可能希望用一段文字来搜索一张图片,或者用一张图片来查找相关的文章。这要求系统不仅要理解图像的视觉内容,还要理解文本的语义,并在一个统一的语义空间中对齐这两种模态的特征。虽然近年来出现了一些基于Transformer的预训练模型(如CLIP)在这一领域取得了突破,但如何进一步提升其在细粒度、复杂场景下的检索精度,仍然是一个开放性问题。
8.1.2 大规模数据下的检索效率与精度平衡
随着图像数据量从百万级增长到十亿甚至百亿级,如何在保证检索精度的同时,实现毫秒级的响应速度,是CBIR系统面临的巨大挑战。这需要在检索效率和检索精度之间做出精妙的权衡。虽然近似最近邻(ANN)搜索算法和向量数据库的出现极大地提升了检索效率,但它们本质上是一种有损压缩,不可避免地会牺牲一定的精度。如何设计更高效的索引结构和更精准的ANN算法,以在超大规模数据集上实现“又快又准”的检索,是工业界和学术界共同追求的目标。
8.1.3 数据隐私与安全问题
在CBIR系统中,用户上传的查询图像和数据库中的图像数据可能包含大量的敏感信息,如个人照片、证件、商业机密等。如何在利用这些数据进行检索的同时,保障用户的数据隐私和信息安全,是一个至关重要的问题。尤其是在金融、医疗等对数据安全要求极高的领域,需要采用联邦学习、同态加密、差分隐私等技术,确保数据在存储、传输和计算过程中的安全性,防止数据泄露和滥用。
8.2 未来发展趋势
展望未来,CBIR技术将朝着更智能、更高效、更个性化的方向发展,并与人工智能的其他前沿领域深度融合,催生出更多创新的应用。
8.2.1 多模态融合与大模型在CBIR中的应用
未来的CBIR系统将不再是单一模态的检索,而是多模态融合的检索。以GPT-4V、CLIP等为代表的大模型(Large Models) ,具备强大的跨模态理解和生成能力,能够将文本、图像、音频、视频等多种信息映射到一个统一的语义空间中。将这些大模型应用于CBIR,可以实现更自然、更智能的交互方式。例如,用户可以输入“帮我找一件和这件上衣风格相似但更便宜的外套”,系统能够理解这个复杂的、带有情感和比较意图的查询,并返回精准的结果。大模型的引入,将使CBIR系统从“以图搜图”升级为“以意搜图”,真正实现对人类复杂意图的理解和满足。
8.2.2 边缘计算与实时图像检索
随着物联网(IoT)和移动设备的普及,越来越多的图像数据在终端设备上产生。将海量的图像数据全部上传到云端进行处理,不仅会带来巨大的网络带宽压力,还可能引发隐私泄露的风险。边缘计算(Edge Computing) 为此提供了解决方案。通过在智能手机、摄像头、无人机等终端设备上部署轻量化的CBIR模型,可以实现本地的、实时的图像检索和分析。例如,在智能安防领域,边缘设备可以实时检索可疑人员的图像;在智能制造领域,生产线上的摄像头可以实时检测产品缺陷。边缘计算与CBIR的结合,将推动图像检索技术向更实时、更分布式的方向发展。
8.2.3 更智能的用户交互与个性化检索体验
未来的CBIR系统将提供更加智能和个性化的用户体验。系统将不再是一个被动的工具,而是一个能够主动学习和适应用户偏好的智能助手。通过引入强化学习和持续学习机制,系统可以根据用户的点击、收藏、购买等反馈行为,动态地调整检索模型,为每个用户打造独一无二的个性化检索体验。此外,交互方式也将更加多样化,除了上传图片,用户还可以通过语音、手势、甚至眼动等方式与系统进行交互,实现更自然、更高效的信息获取。


















 5253
5253

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











