




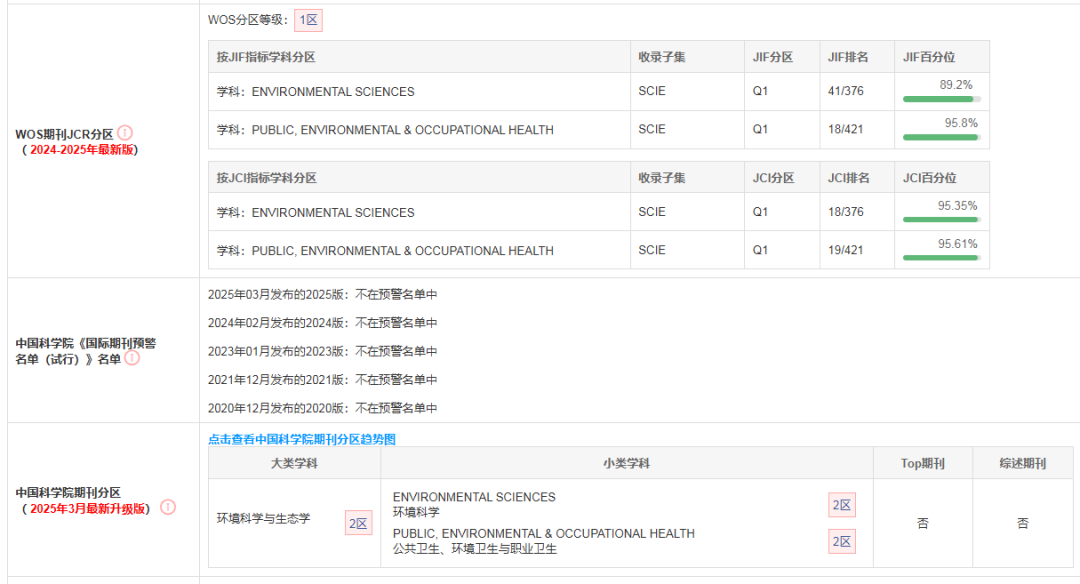
《Environmental Research》由Academic Press Inc.出版,研究方向涉及环境科学-公共卫生、环境卫生与职业卫生,出版于美国,语言为英语。期刊发文量近五年增长约4倍,影响因子稳定在8左右,目前位列JCR Q1区,中科院2区。
影响因子与自引率
最新影响因子为7.7,五年影响因子为7.7,自引率为5.20%,数据表现稳定。
影响因子趋势图
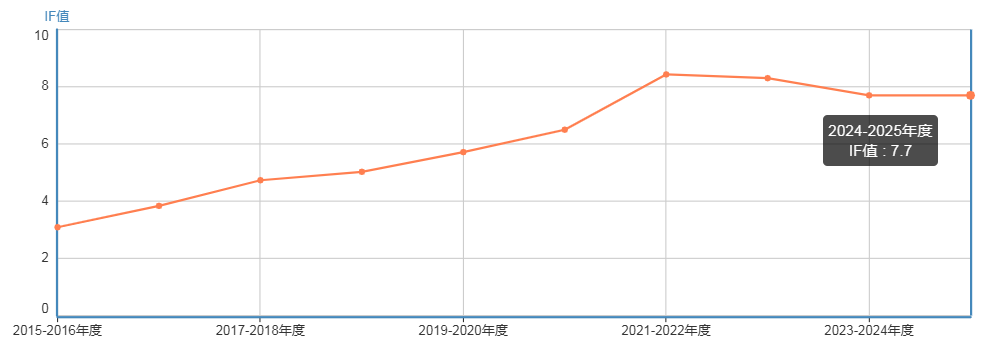
自引率趋势图
收稿方向
主要包括空气、土壤和水污染物与健康、生物监测和人类健康影响、环境流行病学、环境毒理学、全球变暖、纳米材料、风险分析、废物处理等领域。
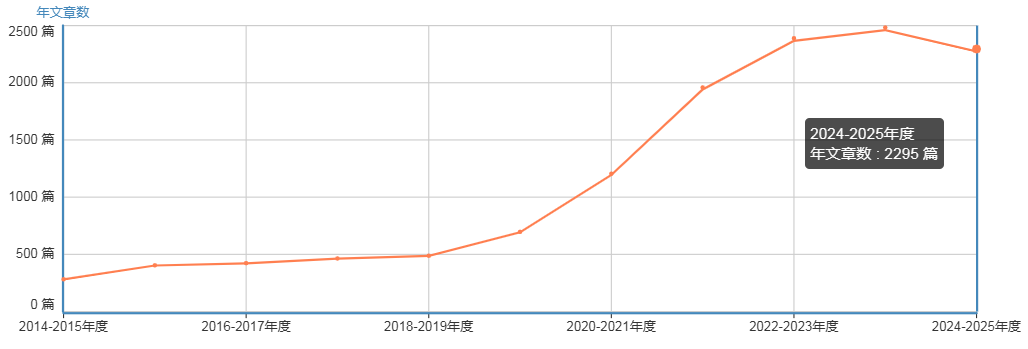
年发文量
2018-2023年发文量持续上涨,期刊发文量近五年增长约4倍,2023-2024年度发文量已达2483篇(峰值)。2024-2025年度发文量虽稍有下降,也发表了2295篇。
总体来看,发文量一直持续上涨中。
审稿周期和费用
初审周期仅5天,从投稿到接受平均82天(约3个月),录用到出版约3天,速度较快。

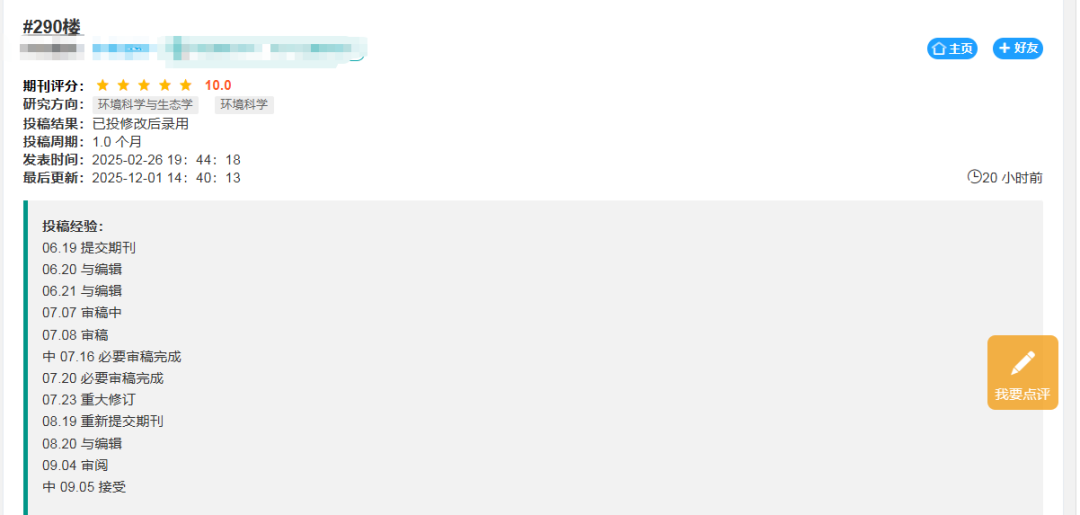
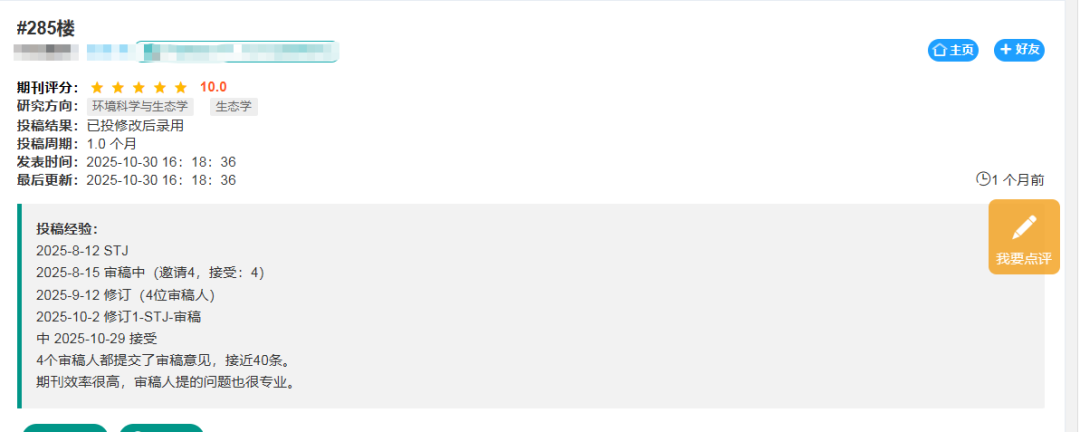
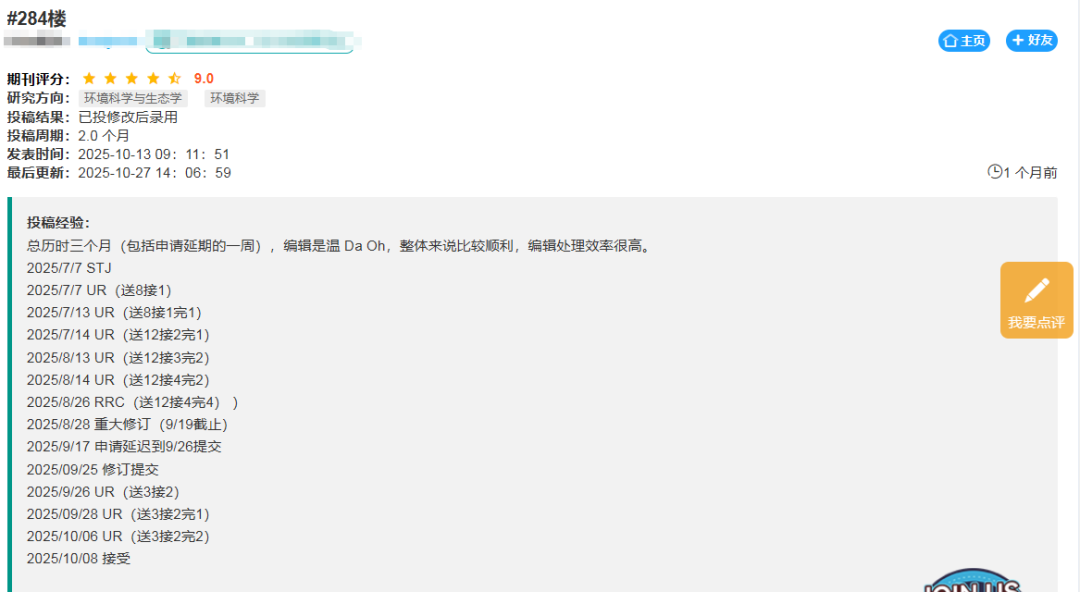
网友近期投稿情况,看出审稿确实很有效率。
出版模式包括订阅和开放获取(OA),OA版面费为3860美元(约合人民币27313元)。

总体评价
《Environmental Research》在环境科学与生态学领域具有影响力,审稿效率高、自引率低,且对国人友好,适合相关研究者投稿。

















 3206
3206

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









