






 本文介绍了如何在Flink 1.11中使用StreamingFileSink以ORC格式高效写入流式数据,涉及OrcBulkWriterFactory的构造方法、向量化操作及实际应用实例,帮助读者理解如何配置和利用这种列式存储格式进行数据处理。
本文介绍了如何在Flink 1.11中使用StreamingFileSink以ORC格式高效写入流式数据,涉及OrcBulkWriterFactory的构造方法、向量化操作及实际应用实例,帮助读者理解如何配置和利用这种列式存储格式进行数据处理。
Flink教程-flink 1.11 流式数据ORC格式写入file
在flink中,StreamingFileSink是一个很重要的把流式数据写入文件系统的sink,可以支持写入行格式(json, csv等)的数据,以及列格式(orc、parquet)的数据。
hive作为一个广泛的数据存储,而ORC作为hive经过特殊优化的列式存储格式,在hive的存储格式中占有很重要的地位。今天我们主要讲一下使用StreamingFileSink将流式数据以ORC的格式写入文件系统,这个功能是flink 1.11版本开始支持的。
StreamingFileSink简介
StreamingFileSink提供了两个静态方法来构造相应的sink,forRowFormat用来构造写入行格式数据的sink,forBulkFormat方法用来构造写入列格式数据的sink,
我们看一下方法forBulkFormat。
/**
* Creates the builder for a {@link StreamingFileSink} with bulk-encoding format.
*
* @param basePath the base path where all the buckets are going to be created as
* sub-directories.
* @param writerFactory the {@link BulkWriter.Factory} to be used when writing elements in the
* buckets.
* @param <IN> the type of incoming elements
* @return The builder where the remaining of the configuration parameters for the sink can be
* configured. In order to instantiate the sink, call {@link BulkFormatBuilder#build()}
* after specifying the desired parameters.
*/
public static <IN> StreamingFileSink.DefaultBulkFormatBuilder<IN> forBulkFormat(
final Path basePath, final BulkWriter.Factory<IN> writerFactory) {
return new StreamingFileSink.DefaultBulkFormatBuilder<>(
basePath, writerFactory, new DateTimeBucketAssigner<>());
}
forBulkFormat两个参数,第一个是一个写入的路径,第二个是一个用于创建writer的实现BulkWriter.Factory接口的工厂类。
写入orc工厂类
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-orc_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
flink为我们提供了写入orc格式的工厂类OrcBulkWriterFactory,我们简单看下这个工厂类的一些变量。
@PublicEvolving
public class OrcBulkWriterFactory<T> implements BulkWriter.Factory<T> {
private static final Path FIXED_PATH = new Path(".");
private final Vectorizer<T> vectorizer;
private final Properties writerProperties;
private final Map<String, String> confMap;
private OrcFile.WriterOptions writerOptions;
public OrcBulkWriterFactory(Vectorizer<T> vectorizer) {
this(vectorizer, new Configuration());
}
public OrcBulkWriterFactory(Vectorizer<T> vectorizer, Configuration configuration) {
this(vectorizer, null, configuration);
}
public OrcBulkWriterFactory(Vectorizer<T> vectorizer, Properties writerProperties, Configuration configuration) {
...................
}
.............
}
向量化操作
flink使用了hive的VectorizedRowBatch来写入ORC格式的数据,所以需要把输入数据组织成VectorizedRowBatch对象,而这个转换的功能就是由OrcBulkWriterFactory中的变量—也就是抽象类Vectorizer类完成的,主要实现的方法就是org.apache.flink.orc.vector.Vectorizer#vectorize方法。
在flink中,提供了一个支持RowData输入格式的RowDataVectorizer,在方法vectorize中,根据不同的类型,将输入的RowData格式的数据转成VectorizedRowBatch类型。
@Override
public void vectorize(RowData row, VectorizedRowBatch batch) {
int rowId = batch.size++;
for (int i = 0; i < row.getArity(); ++i) {
setColumn(rowId, batch.cols[i], fieldTypes[i], row, i);
}
}
构造OrcBulkWriterFactory
工厂类一共提供了三个构造方法,我们看到最全的一个构造方法一共接受三个参数,第一个就是我们上面讲到的Vectorizer对象,第二个是一个写入orc格式的配置属性,第三个是hadoop的配置文件.
写入的配置来自https://orc.apache.org/docs/hive-config.html,具体可以是以下的值.
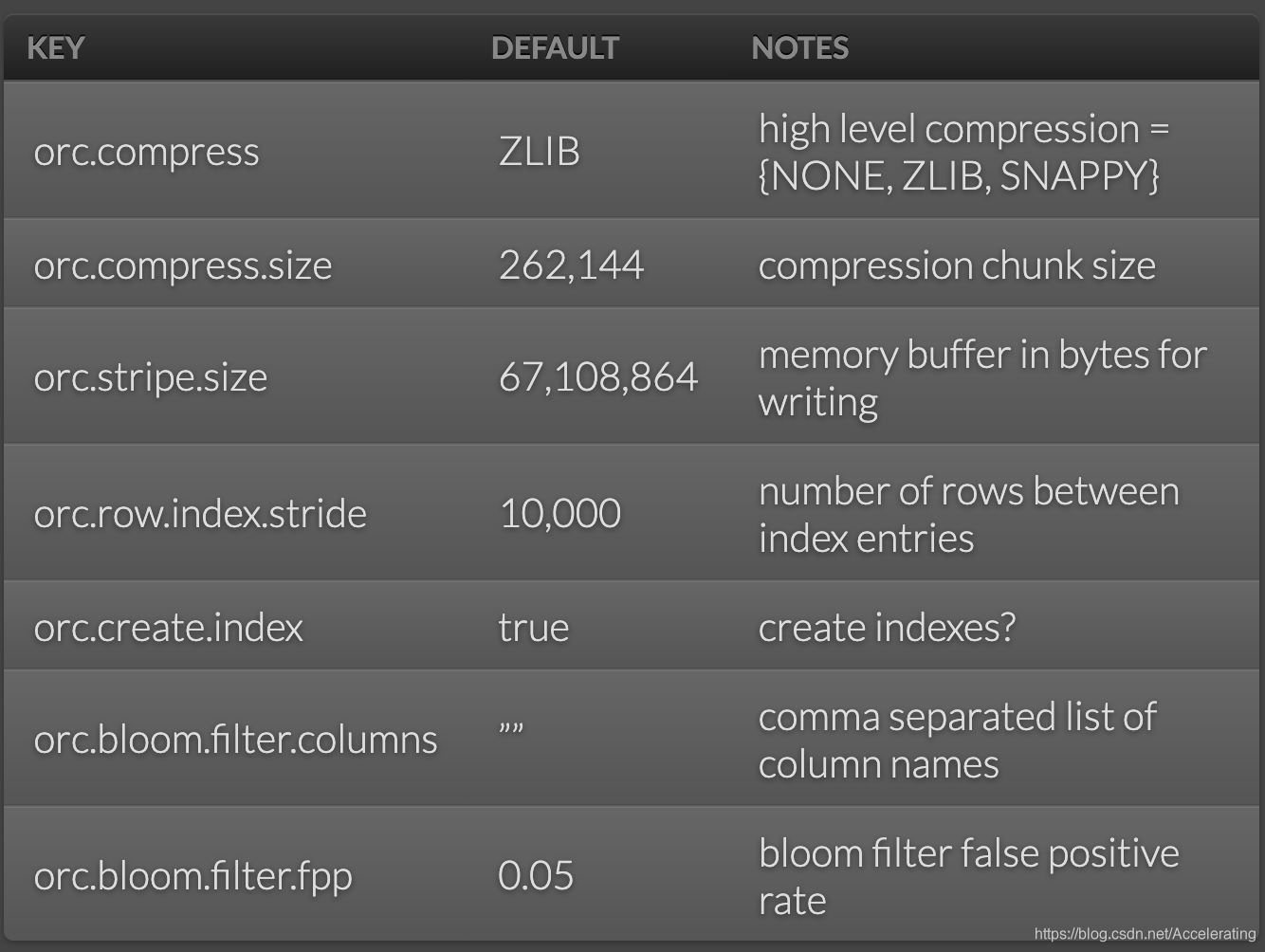
实例讲解
构造source
首先我们自定义一个source,模拟生成RowData数据,我们这个也比较简单,主要是生成了一个int和double类型的随机数.
public static class MySource implements SourceFunction<RowData>{
@Override
public void run(SourceContext<RowData> sourceContext) throws Exception{
while (true){
GenericRowData rowData = new GenericRowData(2);
rowData.setField(0, (int) (Math.random() * 100));
rowData.setField(1, Math.random() * 100);
sourceContext.collect(rowData);
Thread.sleep(10);
}
}
@Override
public void cancel(){
}
}
构造OrcBulkWriterFactory
接下来定义构造OrcBulkWriterFactory需要的参数。
//写入orc格式的属性
final Properties writerProps = new Properties();
writerProps.setProperty("orc.compress", "LZ4");
//定义类型和字段名
LogicalType[] orcTypes = new LogicalType[]{new IntType(), new DoubleType()};
String[] fields = new String[]{"a1", "b2"};
TypeDescription typeDescription = OrcSplitReaderUtil.logicalTypeToOrcType(RowType.of(
orcTypes,
fields));
//构造工厂类OrcBulkWriterFactory
final OrcBulkWriterFactory<RowData> factory = new OrcBulkWriterFactory<>(
new RowDataVectorizer(typeDescription.toString(), orcTypes),
writerProps,
new Configuration());
构造StreamingFileSink
StreamingFileSink orcSink = StreamingFileSink
.forBulkFormat(new Path("file:///tmp/aaaa"), factory)
.build();

















 1262
1262

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









