







 文章探讨了在学习Lambda表达式过程中对流的困惑,通过对比传统for循环和使用流的方法来查找长度超过4分钟的歌曲,发现流的方式在耗时上更长,但代码更简洁。尽管如此,文章提出了对于流的使用目的和价值的疑问,尤其是在性能和可读性之间的权衡。
文章探讨了在学习Lambda表达式过程中对流的困惑,通过对比传统for循环和使用流的方法来查找长度超过4分钟的歌曲,发现流的方式在耗时上更长,但代码更简洁。尽管如此,文章提出了对于流的使用目的和价值的疑问,尤其是在性能和可读性之间的权衡。
正在学习Lamda表达式,看到流的时候感觉很迷惑,语法还处于迷惑状态
通过对比和验证,流的耗时更长,不易读,虽然代码量确实少了一点,但也差不多,太复杂 的应该也不会用流吧。
那为什么更推荐使用流呢?
本代码来自下书重构遗留代码章节

以下代码来自书中,仅整理和验证
由for循环代码到流的一个演变过程。
package com.lamdaDemo.demo1;
import lombok.Data;
import org.junit.Test;
import java.util.*;
import java.util.function.BinaryOperator;
import java.util.stream.Collectors;
import java.util.stream.Stream;
import static java.lang.Character.isDigit;
import static java.util.Arrays.asList;
import static java.util.stream.Collectors.toList;
import static java.util.stream.Collectors.toSet;
import static org.junit.Assert.assertEquals;
/**
* test
*/
public class StreamDemo {
public static void main(String[] args) {
StreamDemo streamDemo = new StreamDemo();
List<Album> albums = asList(new Album(asList(
new Track("修炼爱情", 287),
new Track("可惜没如果", 298),
new Track("不为谁而做的歌", 266),
new Track("她说", 321),
new Track("谢幕", 243)
)), new Album(asList(
new Track("别怕我伤心", 295),
new Track("信仰", 322),
new Track("过火", 302),
new Track("宽容", 316)
)), new Album(asList(
new Track("天外之物", 257),
new Track("演员", 261),
new Track("其实", 242),
new Track("野心", 220),
new Track("意外", 297)
)), new Album(asList(
new Track("身骑白马", 335),
new Track("听", 309),
new Track("最美的太阳", 257),
new Track("着魔", 215),
new Track("明天过后", 298)
)));
long start=System.currentTimeMillis();
Set<String> longTracks = streamDemo.findLongTracks(albums);
long end=System.currentTimeMillis();
System.out.println("共计"+longTracks.size()+"首,"+longTracks);
System.out.println("耗时:"+(end-start));
start=System.currentTimeMillis();
longTracks = streamDemo.findLongTracks1(albums);
end=System.currentTimeMillis();
System.out.println("共计"+longTracks.size()+"首,"+longTracks);
System.out.println("耗时:"+(end-start));
start=System.currentTimeMillis();
longTracks = streamDemo.findLongTracks2(albums);
end=System.currentTimeMillis();
System.out.println("共计"+longTracks.size()+"首,"+longTracks);
System.out.println("耗时:"+(end-start));
start=System.currentTimeMillis();
longTracks = streamDemo.findLongTracks3(albums);
end=System.currentTimeMillis();
System.out.println("共计"+longTracks.size()+"首,"+longTracks);
System.out.println("耗时:"+(end-start));
start=System.currentTimeMillis();
longTracks = streamDemo.findLongTracks4(albums);
end=System.currentTimeMillis();
System.out.println("共计"+longTracks.size()+"首,"+longTracks);
System.out.println("耗时:"+(end-start));
}
//遗留代码:找出长度大于 4 分钟的曲目
public Set<String> findLongTracks(List<Album> albums) {
Set<String> trackNames = new HashSet<>();
for (Album album : albums) {
for (Track track : album.getTrackList()) {
if (track.getLength() > 240) {
String name = track.getName();
trackNames.add(name);
}
}
}
return trackNames;
}
//ForEach 重构第一步
public Set<String> findLongTracks1(List<Album> albums) {
Set<String> trackNames = new HashSet<>();
albums.stream()
.forEach(album -> {
album.getTrackList()
.forEach(track -> {
if (track.getLength() > 240) {
String name = track.getName();
trackNames.add(name);
}
});
});
return trackNames;
}
//ForEach 重构第二步
public Set<String> findLongTracks2(List<Album> albums) {
Set<String> trackNames = new HashSet<>();
albums.stream()
.forEach(album -> {
album.getTracks()
.filter(track -> track.getLength() > 240)
.map(track -> track.getName())
.forEach(name -> trackNames.add(name));
});
return trackNames;
}
//ForEach 重构第三步
public Set<String> findLongTracks3(List<Album> albums) {
Set<String> trackNames = new HashSet<>();
albums.stream()
.flatMap(album -> album.getTracks())
.filter(track -> track.getLength() > 240)
.map(track -> track.getName())
.forEach(name -> trackNames.add(name));
return trackNames;
}
//ForEach 重构第四步
public Set<String> findLongTracks4(List<Album> albums) {
return albums.stream()
.flatMap(album -> album.getTracks())
.filter(track -> track.getLength() > 240)
.map(track -> track.getName())
.collect(toSet());
}
}
@Data
class Album {
private String name;//专辑名
private List<Track> trackList;//歌曲加时长
public Album(List<Track> tracks) {
this.trackList = tracks;
}
public Stream<Track> getTracks() { //包含整张专辑中所有的歌曲流
return trackList.stream();
}
}
@Data
class Track {
private String name;//歌曲名
private int length;//时长
public Track(String song, int length) {
this.name = song;
this.length = length;
}
}

打印时间对比
第一种更快,emmm
再对比一下代码量,emmm
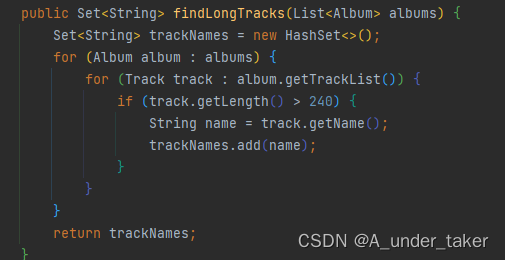
213
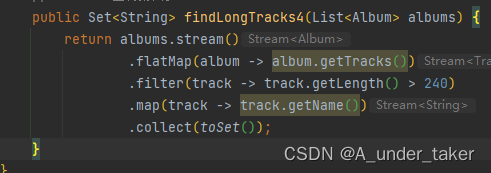
147
代码量差别不是特别大,且流更耗时,而通用版更易读,使用流的目的是什么?时间换空间吗?
等搞懂了再来更新。。。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









