




中等
编写一个高效的算法来搜索 *m* x *n* 矩阵 matrix 中的一个目标值 target 。该矩阵具有以下特性:
-
每行的元素从左到右升序排列。
-
每列的元素从上到下升序排列。
示例 1:
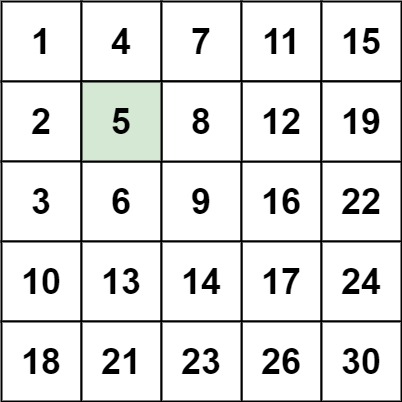
输入:matrix = [[1,4,7,11,15],[2,5,8,12,19],[3,6,9,16,22],[10,13,14,17,24],[18,21,23,26,30]], target = 5 输出:true
提示:
-
m == matrix.length -
n == matrix[i].length -
1 <= n, m <= 300 -
-109 <= matrix[i][j] <= 109 -
每行的所有元素从左到右升序排列
-
每列的所有元素从上到下升序排列
-
-109 <= target <= 109
思路:
二分查找,题目强调有序数据,天然的符合二分条件,常规的二分就是取中间点, 然后观察这个点的值与目标值比较是大了还是小了。不断更新左右端点,中间点自然跟着变化。这样就使得中间点不断向目标值靠近。而这里二维二分,基本思路一样,初始取整个数组的中间坐标,根据得到的点不断更新 x,y 即可。
class Solution {
public boolean searchMatrix(int[][] matrix, int target) {
int n = matrix.length;
int m = matrix[0].length;
int left = 0;
int buttom = n - 1;
while(left < m && buttom >= 0){
// 如果比目标值大 则往上靠
if(matrix[buttom][left] > target) buttom --;
// 比目标值小 往右靠
else if(matrix[buttom][left] < target) left ++;
else return true;
}
return false;
}
}

















 1364
1364

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









