








------------25.3.28更新内容如下:
已在GitHub开源与本博客同步的MobileNetv2_RK3588_Classification项目,地址:https://github.com/A7bert777/MobileNetv2_RK3588_Classification
详细使用教程,可参考README.md或参考本博客第五章 模型部署
文章目录
一、模型选择介绍
近期需要做一个针对分类图像的模型,并部署到RK3588公版的开发板上,可选择的有YOLOv8、ResNet、MobileNet…
而瑞芯微的部署demo:rknn_model_zoo中可以看到,并没有yolov8的图像分类demo,只有ResNet和MobileNet的demo。因此为了省事,就按照瑞芯微的方法来,看了下其官网ONNX模型示例的大小,ResNet比MobileNet大了一个数量级,根据经验,肯定模型越小运行速度越快,因此选择MobileNet进行分类任务。
注:rknn_model_zoo中只有ResNet50v2和MobileNetv2这两个版本,其余的分类模型版本并未公布,所以大家如果为了省事,最好就直接选择MobileNetv2版本吧,这样在部署时,和官方demo一致,非常方便。
另外,本篇文章参考了博主@nice-wyh,原文链接。
下面进入正题,先开始模型训练的必要准备。
二、文件及环境配置
由于MobileNetv2结构较为简单,且图像分类也没有目标检测的复杂后处理流程,因此训练MobileNetv2所需要的文件很少,不同于以前训练YOLO系列模型的繁琐流程。
1.所需文件

在这里,我们所需的文件都是py类型的,只有四个。
其中model_v2.py是MobileNetv2的定义文件
train.py和predict.py是模型训练和预测用文件
pt2onnx.py是训练得到的pt模型转onnx的文件
各文件详细内容如下,可直接复制粘贴
1.model_v2.py:
from torch import nn
import torch
# 将channel调整为离8最近的整数倍,这样的处理对硬件更加的友好,也有一定训练速度的提升
def _make_divisible(ch, divisor=8, min_ch=None):
"""
This function is taken from the original tf repo.
It ensures that all layers have a channel number that is divisible by 8
It can be seen here:
https://github.com/tensorflow/models/blob/master/research/slim/nets/mobilenet/mobilenet.py
"""
if min_ch is None:
min_ch = divisor
new_ch = max(min_ch, int(ch + divisor / 2) // divisor * divisor)
# Make sure that round down does not go down by more than 10%.
if new_ch < 0.9 * ch:
new_ch += divisor
return new_ch
class ConvBNReLU(nn.Sequential):
def __init__(self, in_channel, out_channel, kernel_size=3, stride=1, groups=1):
padding = (kernel_size - 1) // 2
super(ConvBNReLU, self).__init__(
# 这里如果group=1,则为普通卷积;group=输入特征矩阵的深度时,则为DW卷积
nn.Conv2d(in_channel, out_channel, kernel_size, stride, padding, groups=groups, bias=False),
nn.BatchNorm2d(out_channel),
nn.ReLU6(inplace=True)
)
class InvertedResidual(nn.Module):
def __init__(self, in_channel, out_channel, stride, expand_ratio):
super(InvertedResidual, self).__init__()
hidden_channel = in_channel * expand_ratio
# 当步长为1,且输入输出维度相同时,使用捷径分支
self.use_shortcut = stride == 1 and in_channel == out_channel
layers = []
if expand_ratio != 1:
# 1x1 pointwise conv
layers.append(ConvBNReLU(in_channel, hidden_channel, kernel_size=1))
layers.extend([
# 3x3 depthwise conv
ConvBNReLU(hidden_channel, hidden_channel, stride=stride, groups=hidden_channel),
# 1x1 pointwise conv(linear)
nn.Conv2d(hidden_channel, out_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channel),
])
self.conv = nn.Sequential(*layers)
def forward(self, x):
if self.use_shortcut:
return x + self.conv(x)
else:
return self.conv(x)
class MobileNetV2(nn.Module):
def __init__(self, num_classes=1000, alpha=1.0, round_nearest=8):
super(MobileNetV2, self).__init__()
block = InvertedResidual
input_channel = _make_divisible(32 * alpha, round_nearest)
last_channel = _make_divisible(1280 * alpha, round_nearest)
inverted_residual_setting = [
# t, c, n, s
# t:将输入特征矩阵深度调整t倍
# c:输入channel
# n:bottle(倒残差结构重复的次数)
# s:每个block中,第一个bottleneck的步长
[1, 16, 1, 1],
[6, 24, 2, 2],
[6, 32, 3, 2],
[6, 64, 4, 2],
[6, 96, 3, 1],
[6, 160, 3, 2],
[6, 320, 1, 1],
]
features = []
# conv1 layer
features.append(ConvBNReLU(3, input_channel, stride=2))
# building inverted residual residual blockes
for t, c, n, s in inverted_residual_setting:
output_channel = _make_divisible(c * alpha, round_nearest)
for i in range(n):
stride = s if i == 0 else 1
features.append(block(input_channel, output_channel, stride, expand_ratio=t))
input_channel = output_channel
# building last several layers
features.append(ConvBNReLU(input_channel, last_channel, 1))
# combine feature layers
self.features = nn.Sequential(*features)
# building classifier
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.classifier = nn.Sequential(
nn.Dropout(0.2),
nn.Linear(last_channel, num_classes)
)
# weight initialization
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out')
if m.bias is not None:
nn.init.zeros_(m.bias)
elif isinstance(m, nn.BatchNorm2d):
nn.init.ones_(m.weight)
nn.init.zeros_(m.bias)
elif isinstance(m, nn.Linear):
nn.init.normal_(m.weight, 0, 0.01)
nn.init.zeros_(m.bias)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
if __name__ == "__main__":
net = MobileNetV2(num_classes=10)
in_data = torch.randn(1, 3, 224, 224)
out = net(in_data)
print(out)
2. train.py:
import os
import sys
import json
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import transforms, datasets
from tqdm import tqdm
from model_v2 import MobileNetV2
def main():
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"using {device} device.")
data_transform = {
"train": transforms.Compose([transforms.RandomResizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])]),
"val": transforms.Compose([transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])}
# 获取数据集路径
image_path = os.path.join(os.getcwd(), "data_set", "raw_data") # flower data set path
assert os.path.exists(image_path), "{} path does not exist.".format(image_path)
# 加载数据集,准备读取
train_dataset = datasets.ImageFolder(root=os.path.join(image_path, "train"), transform=data_transform["train"])
validate_dataset = datasets.ImageFolder(root=os.path.join(image_path, "val"), transform=data_transform["val"])
nw = min([os.cpu_count(), 16 if 16 > 1 else 0, 8]) # number of workers
print('Using {} dataloader workers every process'.format(nw))
# 加载数据集
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=16, shuffle=True, num_workers=nw)
validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=16, shuffle=False, num_workers=nw)
train_num = len(train_dataset)
val_num = len(validate_dataset)
print(f"using {train_num} images for training, {val_num} images for validation.")
# {'cane':0, 'carpet':1, 'cavallo':2, 'elefante':3, 'farfalla':4, 'gallina':5, 'gatto':6, 'mucca':7, 'pecora':8, 'ragno':9, 'scoiattolo':10}
flower_list = train_dataset.class_to_idx
cla_dict = dict((val, key) for key, val in flower_list.items())
# write dict into json file
json_str = json.dumps(cla_dict, indent=4)
with open('class_indices.json', 'w') as json_file:
json_file.write(json_str)
# load pretrain weights
# download url: https://download.pytorch.org/models/mobilenet_v2-b0353104.pth
net = MobileNetV2(num_classes=11)
model_weight_path = "./mobilenet_v2.pth"
assert os.path.exists(model_weight_path), f"file {model_weight_path} dose not exist."
pre_weights = torch.load(model_weight_path, map_location='cpu')
# delete classifier weights,因为预训练参数是基于ImageNet数据集训练的,类别为1000,所以需要删掉最后一层参数,只保留其他部分
pre_dict = {k: v for k, v in pre_weights.items() if net.state_dict()[k].numel() == v.numel()}
missing_keys, unexpected_keys = net.load_state_dict(pre_dict, strict=False)
# freeze features weights
# 预训练模型中,我们只希望微调最后几层,因此冻结前面的权重和偏置参数
for param in net.features.parameters():
param.requires_grad = False
net.to(device)
# define loss function
loss_function = nn.CrossEntropyLoss()
# construct an optimizer
params = [p for p in net.parameters() if p.requires_grad]
optimizer = optim.Adam(params, lr=0.0001)
epochs = 5
best_acc = 0.0
train_steps = len(train_loader)
for epoch in range(epochs):
# train
net.train()
running_loss = 0.0
train_bar = tqdm(train_loader, file=sys.stdout)
for step, data in enumerate(train_bar):
images, labels = data
optimizer.zero_grad()
logits = net(images.to(device))
loss = loss_function(logits, labels.to(device))
loss.backward()
optimizer.step()
# print statistics
running_loss += loss.item()
train_bar.desc = f"train epoch[{epoch + 1}/{epochs}] loss:{loss:.3f}"
# validate
net.eval()
acc = 0.0 # accumulate accurate number / epoch
with torch.no_grad():
val_bar = tqdm(validate_loader, file=sys.stdout)
for val_data in val_bar:
val_images, val_labels = val_data
outputs = net(val_images.to(device))
# loss = loss_function(outputs, test_labels)
predict_y = torch.max(outputs, dim=1)[1]
acc += torch.eq(predict_y, val_labels.to(device)).sum().item()
val_bar.desc = f"valid epoch[{epoch + 1}/{epochs}]"
val_accurate = acc / val_num
print('[epoch %d] train_loss: %.3f val_accuracy: %.3f' %
(epoch + 1, running_loss / train_steps, val_accurate))
if val_accurate > best_acc:
best_acc = val_accurate
torch.save(net, "./MobileNetV2.pth")
print('Finished Training')
if __name__ == '__main__':
main()
3. predict.py:
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model_v2 import MobileNetV2
def main():
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
data_transform = transforms.Compose(
[transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])])
# load image
img_path = "./ea34b0062bf4063ed1584d05fb1d4e9fe777ead218ac104497f5c978a6ebb3bf_640.jpg"
img = Image.open(img_path)
plt.imshow(img)
# [N, C, H, W]
img = data_transform(img)
# expand batch dimension
img = torch.unsqueeze(img, dim=0)
# read class_indict
json_path = './class_indices.json'
assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)
with open(json_path, "r") as f:
class_indict = json.load(f)
# create model
model = MobileNetV2(num_classes=10).to(device)
# load model weights
model = torch.load("./MobileNetV2.pth")
model.eval()
with torch.no_grad():
# predict class
output = torch.squeeze(model(img.to(device))).cpu()
predict = torch.softmax(output, dim=0)
predict_cla = torch.argmax(predict).numpy()
print_res = f"class: {class_indict[str(predict_cla)]} prob: {predict[predict_cla].numpy():.3}"
plt.title(print_res)
for i in range(len(predict)):
print(f"class: {class_indict[str(i)]:10} prob: {predict[i].numpy():.3}")
plt.show()
if __name__ == '__main__':
main()
4. pt2onnx.py:
import torch
import torchvision
from model_v2 import MobileNetV2
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = MobileNetV2(num_classes=10).to(device)
model=torch.load("/home/lm/MobileNet/MobileNetV2.pth")
model.eval()
example = torch.ones(1, 3, 244, 244)
example = example.to(device)
torch.onnx.export(model, example, "MobileNetV2.onnx", verbose=True, opset_version=12)
注意这里的“opset_version=12”,最好选择12版本的op指令集,因为瑞芯微示例的onnx模型的操作集版本为12。
5. 预训练模型:
mobilenetv2.pth预训练模型可以去官网下载:
https://download.pytorch.org/models/mobilenet_v2-b0353104.pth,下不了的科学上网试试,另外优快云应该也有下载链接。
6. 所需数据集:
我这边共有11个类别,需要注意,图像分类和目标检测的数据集格式不同,目标检测数据集需要txt、xml、json等标注数据格式…
但是图像分类是不用标注数据集的,而你的类别名,就是通过所在的子文件夹名来定义的。具体格式如下:

还是分为train和val两个文件夹,两个文件夹下各有11个类别的子文件夹,子文件夹名即其中所有图片代表的类别名,打开其中子文件夹内容如下:

就是正常图片格式,无图片命名要求。
2. 环境配置
这里我用的环境就是Yolov8训练时的环境,因为根据train.py所需导入的文件,几乎没啥要求,直接安装torch、torchvision和tqdm…就行了。
三、模型训练
将train.py中的模型路径、数据集路径、epoch次数设置好后,执行train.py,终端结果如下:

四、模型转换
1. PTH转换ONNX
将训练得到的pth模型,修改pt2onnx.py中的pth模型路径,执行pt2onnx.py,终端结果如下:


终端显示如上后即可得到ONNX模型,用netron打开后看到模型结构如下:

2. ONNX转换RKNN
打开PC虚拟机,激活自己的转化RKNN的环境:rknn210,至于这个环境是啥以及怎么来的,可以参考我的这篇文章,其中有详细的该转换环境的介绍:【YOLOv8n部署至RK3588】模型训练→转换rknn→部署全流程
一、mobilenet.py文件修改
打开rknn_model_zoo/examples/mobilenet目录如下:

修改其中的python/mobilenet.py文件,修改内容如下:



注意,这里一定要改成input.1,因为netron打开onnx模型可以看到模型的输入名就是input.1(可看上述onnx模型图),这样确保与模型输入名一致,执行后不会报错。
二、激活环境,执行mobilenet.py:

三、终端显示如下,得到RKNN模型:

四、RKNN模型结构:
打开netron,查看rknn模型结构如下,输出的 “11” 是指有11个类别:

五、模型部署
如果前面流程都已实现,模型的结构也没问题的话,则可以进行最后一步:模型端侧部署。
我已经帮大家做好了所有的环境适配工作,科学上网后访问博主GitHub仓库:MobileNetv2_RK3588_Classification ,进行简单的路径修改就即可编译运行。
统一声明:
1、这个仓库的项目只能做图片的批量检测,不支持视频流检测,没时间做这个,有需要的自己修改代码。
2、从GitHub的README.md中加QQ后直接说问题和小星星截图,对于常见的相同问题,很多都已在优快云博客中提到了(RKNN转换流程是统一的,可去博主所有的RKNN相关博客下去翻评论),已在评论中详细解释过的问题,不予回复。
重点:请大家举手之劳,帮我的仓库点个小星星
点了小星星的同学可以免费帮你解决转模型与部署过程中遇到的问题。
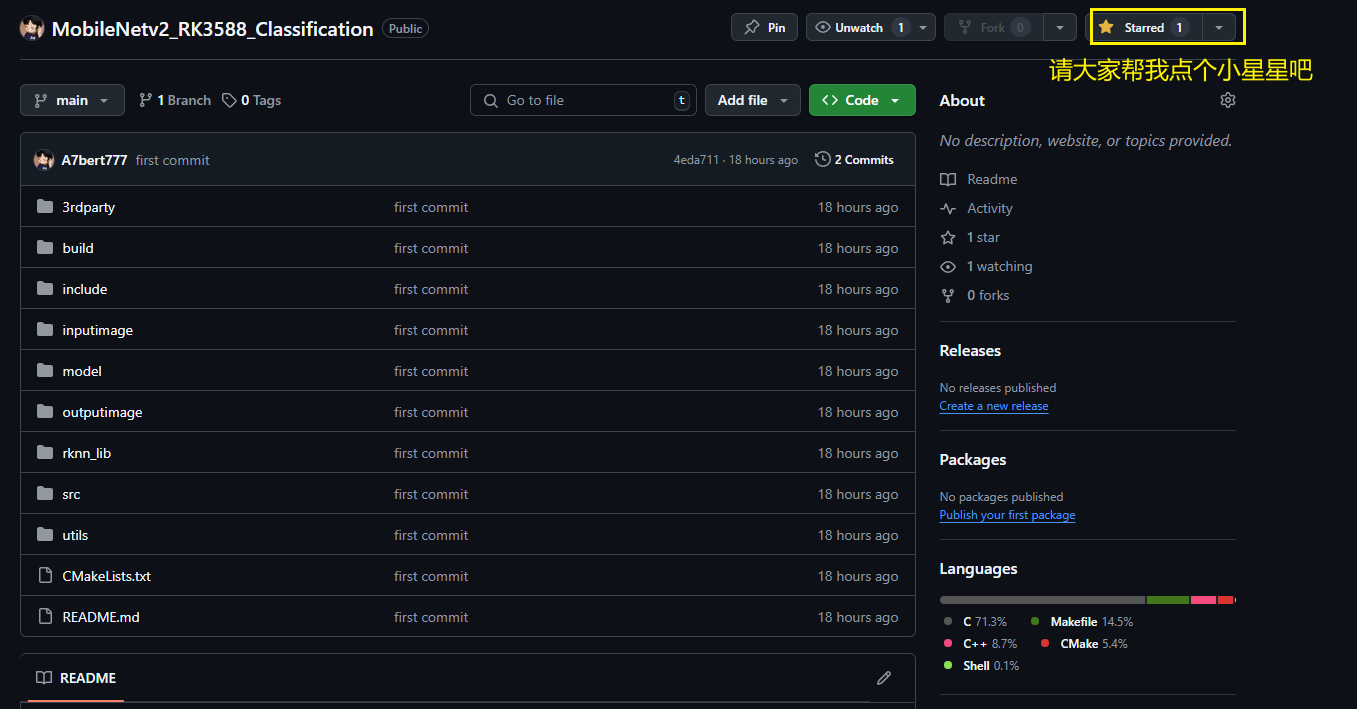
git clone后把项目复制到开发板上,按如下流程操作:
①:cd build,删除所有build文件夹下的内容
②:cd src 修改main.cc,修改main函数中的如下四个内容:
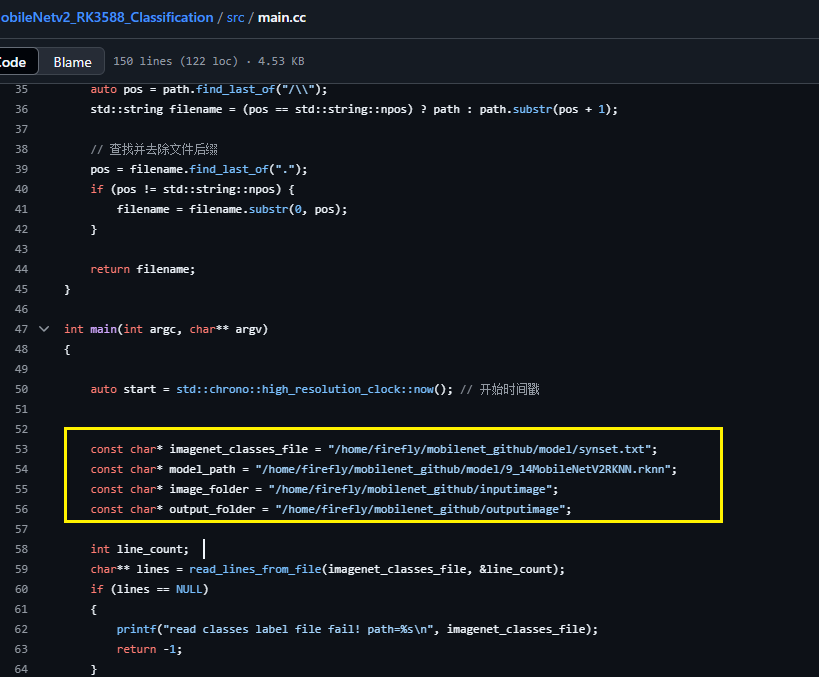
将这四个参数改成自己的绝对路径
③:解释一下,imagenet_classes_file 这个标签路径中的内容如下所示:
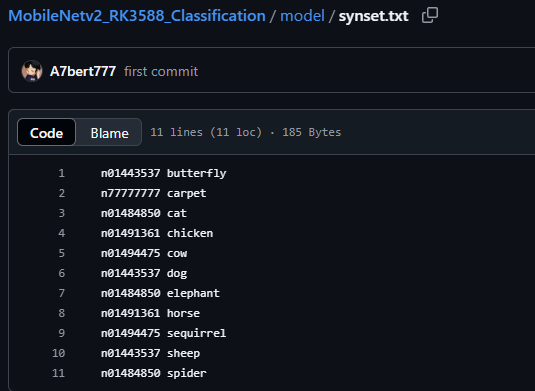
其实就是你在训练MobileNetv2分类模型时在yaml配置文件中的那几个类别名(即文件夹名)
④:把你之前训练好并已转成RKNN格式的模型放到MobileNetv2_RK3588_Classification/model文件夹下,然后把你要检测的所有图片都放到MobileNetv2_RK3588_Classification/inputimage下。
在运行程序后,生成的结果图片在MobileNetv2_RK3588_Classification/outputimage下
⑤:进入build文件夹进行编译
cd build
cmake ..
make
在build下生成可执行文件文件:rknn_yolov8_demo
在build路径下输入
./rknn_mobilenet_demo
运行结果如下所示:
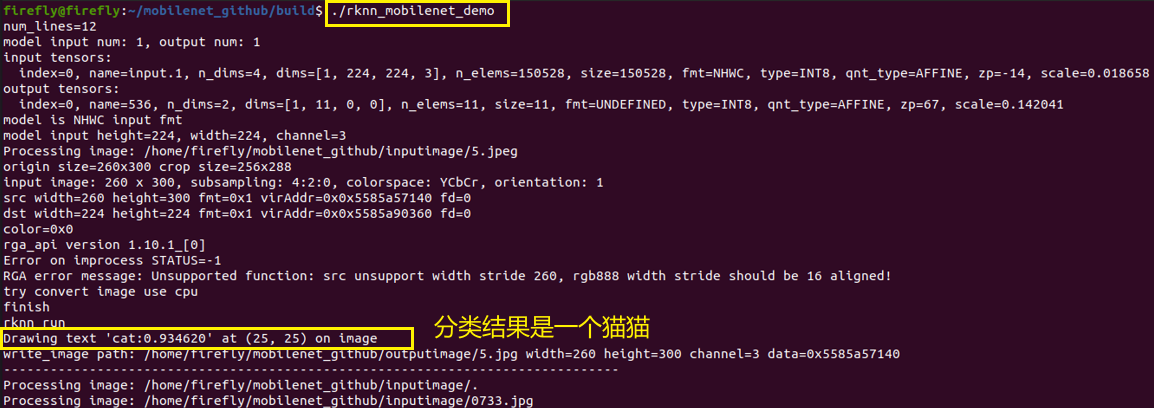
原inputimage文件夹下的图片:

在执行完./rknn_mobilenet_demo后在outputimage下的输出结果图片:

可以看到,与终端显示的分类结果一致。
六、推理结果
取其它场景下的图片进行推理,结果如下:
原图1:

结果1:

原图2:

结果2:

原图3:

结果3:

总体来说,推理得分还是很高的,MobileNetv2在各项任务上足以胜任,效果不比ResNet50v2差,而且推理速度理论上要快很多。
以上即为MobileNetv2图像分类任务部署至RK3588的全流程。


















 1482
1482

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









