




一、线性查找
概念:
线性查找又称顺序查找,是一种最简单的查找方法,它的基本思想是从第一个记录开始,逐个比较记录的关键字,直到和给定的K值相等,则查找成功;若比较结果与文件中n个记录的关键字都不等,则查找失败。
工作原理
例如r[i].key表示数据元素i中的关键字项。在流程图中的循环回路上要进行两次比较,即对数据元素的关键字项比较和对循环次数的判断。为了提高运算速度,可以作如下的改进:
在原表长n的基础上增加一个元素n+1,将K值送入此元素的关键字项中,这样在循环回路上只要进行一次比较,我们把第n+1个记录称为“监视哨”。这样当n很大时几乎可以节省一半时间。
在顺序查找中,在找到第i个记录时,给定值K和记录中的关键字进行了i次比较。
由于平均查找长度与表长度n成线性关系,因此当n较大时,顺序查找的效率较低。但顺序查找算法比较简单,且对顺序表的存储结构没有限制,既可以用向量作存储结构也可以用链表作存储结构。
public class LinearSearch {
public static void main(String[] args) {
int [] arr={1,51,6,75,33,2,9,11,66};
int index = linearSearch(arr, 66);
if (index==-1){
System.out.println("没有找到");
}else {
System.out.println("找到下标="+index+"对应的数值");
}
}
public static int linearSearch(int arr[],int value){
// 线性查找是逐一比对,发现有相同值,就返回下标
for (int i=0;i<arr.length;i++){
if (arr[i]==value){
return i;
}
}
return -1;
}
}
二、折半查找
概念
折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
工作原理
首先,假设表中元素是按升序排列,将表中间位置记录的关键字与查找关键字比较,如果两者相等,则查找成功;否则利用中间位置记录将表分成前、后两个子表,如果中间位置记录的关键字大于查找关键字,则进一步查找前一子表,否则进一步查找后一子表。重复以上过程,直到找到满足条件的记录,使查找成功,或直到子表不存在为止,此时查找不成功。
算法要求
1.必须采用顺序存储结构。
2.必须按关键字大小有序排列。
非递归(代码如下)
public class BinarySearch {
public static void main(String[] args) {
int [] arr={1,3,6,13,35,66,88,99}; // 注意:折半查找必须是顺序表
int index = binarySearch(arr, 66);
if (index==-1){
System.out.println("查找失败");
}else {
System.out.println("查找到"+arr[index]);
}
}
// 不使用递归
public static int binarySearch(int arr[],int vaule){
int low=0;
int high=arr.length-1;
int mid;
while (low<=high){
mid=(low+high)/2;
if (arr[mid]==vaule){
return mid; // 查找成功则返回所在位置
}else if (arr[mid]>vaule){
high=mid-1; // 从前半部分继续查找
}else {
low=mid+1; // 从后半部分继续查找
}
}
return -1; // 查找失败
}
}
递归(代码如下)
public class BinarySearch {
public static void main(String[] args) {
int [] arr={1,3,6,13,35,66,88,99}; // 注意:折半查找必须是顺序表
int index = binarysEARCH(arr, 0, arr.length - 1, 66);
if (index==-1){
System.out.println("查找失败");
}else {
System.out.println("查找到"+arr[index]);
}
}
public static int binarysEARCH(int arr[],int low,int high,int vaule){
int mid=(low+high)/2;
if (vaule==arr[mid]) {
return mid;
} else if (vaule<arr[mid]){ // 向前半部分递归
return binarysEARCH(arr,low,mid-1,vaule);
}else { // 向后半部分递归
return binarysEARCH(arr,mid+1,high,vaule);
}
}
}
当出现要输出数组中所有对应是value元素的索引
思路分析
* 1、在找到mid索引值时,不要马上返回
* 2、向mid索引值的左边扫描,将所有满足的value的元素下标,加入到集合ArrayList
* 3、向mid索引值的右边扫描,将所有满足的value的元素下标,加入到集合ArrayList
* 4、将ArrayList返回
public static ArrayList binarysEARCH2(int arr[], int low, int high, int vaule){
int mid=(low+high)/2;
if (vaule==arr[mid]) {
ArrayList<Integer> resIndexList = new ArrayList<>();
//向mid索引值的左边扫描,将所有满足的value的元素下标,加入到集合ArrayList
int temp=mid-1;
while (true){
if(temp<0 || arr[temp]!=vaule){ // 退出
break;
}
// 否则,就把temp放到resIndexList集合中
resIndexList.add(temp);
temp--; // temp向左移
}
resIndexList.add(mid); // 放入中间部分
temp=mid+1;
while (true){
if(temp>arr.length-1 || arr[temp]!=vaule){ // 退出
break;
}
// 否则,就把temp放到resIndexList集合中
resIndexList.add(temp);
temp++; // temp向右移
}
return resIndexList;
} else if (vaule<arr[mid]){ // 向前半部分递归
return binarysEARCH2(arr,low,mid-1,vaule);
}else { // 向后半部分递归
return binarysEARCH2(arr,mid+1,high,vaule);
}
}
三、插值查找
概念
有序表的一种查找方式。插值查找是根据查找关键字与查找表中最大最小记录关键字比较后的查找方法。插值查找基于二分查找,将查找点的选择改进为自适应选择,提高查找效率。
优势:对于数据量较大,关键字分布比较均匀的查找表来说,采用插值查找,速度较快。
工作原理
1)插值查找算法类似于二分查找,不同的是插值查找每次从自适应mid处开始查找。
2)将折半查找中的mid索引公式key是要查找的值

3)int mid =low+(high-low)*(key-arr[low]) / (arr[high] - arr[low]);—要插入的索引
public class InterpolationSearch {
public static void main(String[] args) {
// 生成一个有序的从0-100的数组
int[] arr = new int[100];
for (int i=0;i<100;i++){
arr[i]=i+1;
}
int valueIndex=InterValueSearch(arr,0,arr.length-1,6);
System.out.println("查找到value对应的下标"+valueIndex);
}
// 使用递归 编写插值查找
public static int InterValueSearch(int arr[],int low,int high,int vaule){
/*
* 如果找到返回对应下标,如果没有找到,就返回-1
* vaule<arr[0] ||vaule>arr[arr.length-1]必须要有,否则mid可能越界
*
* */
if (low>high || vaule<arr[0] ||vaule>arr[arr.length-1]){
return -1; // 优化,减少查找时间
}
// 插值查找的自适应 mid
int mid=low+(low+high)*(vaule-arr[low])/(arr[high]-arr[low]);
if (vaule==arr[mid]) {
return mid;
} else if (vaule<arr[mid]){ // 向前半部分递归
return InterValueSearch(arr,low,mid-1,vaule);
}else { // 向后半部分递归
return InterValueSearch(arr,mid+1,high,vaule);
}
}
}
四、斐波那契(黄金分割法)查找
斐波那契(黄金分割法)原理:(有序是前提)
斐波那契查找原理,仅仅改变了中间节点(mid)的位置
即 mid=low+F(k-1)-1 —F代表斐波那契数列
对F(k-1)-1的理解:
1)斐波那契数列F[k]=F[k-1]+F[k-2]的性质,可以得到 (F[k]-1)=(F[k-1]-1)+(F[k-2]-1)+1。该式说明,只要顺序表的长度为F[k]-1,则可以将表分成长度为F[k-1]-1和F[k-2]-1两段,即如图所示
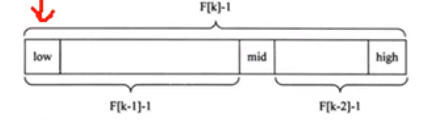
从而中间位置为mid=low+F(k-1)-1
2)类似的,每一个字段也可以用相同的方式分割
3)但顺序表长度n不一定刚好等于F[k]-1,所以需要将原来的顺序表长度n增加至F[k]-1。这里的k值只要能使得F[k]-1恰好大于或等于n即可,有以下代码可得,顺序表长度增加后,新增的位置(从n+1到F[k]-1位置),都赋为n位置的值即可。
while(n>fib(k)-1){
k++;
}
public class FibonacciSearch {
public static int maxSize=20;
public static void main(String[] args) {
int [] arr={1,8,10,89,1000,1234};
System.out.println(FibSearch(arr,1000)); // 返回下标4
}
// 因为后面mid=low+F[k-1]-1,需要使用到斐波那契数列,故要获取一个此数列
// 非递归方法获取一个斐波那契数列
public static int[] fib(){
int[] Fib = new int[maxSize];
Fib[0]=1;
Fib[1]=1;
for (int i=2;i<maxSize;i++){
Fib[i]=Fib[i-1]+Fib[i-2];
}
return Fib;
}
// 编写斐波那契查找算法 使用非递归方法编写
// arr被查询的数组、value被查询的值,return返回对应下标,没有则返回-1
public static int FibSearch(int[] arr,int value){
int low=0;
int high=arr.length-1;
int k=0; // 表示斐波那契分割数值的下标
int mid=0;
int [] Fib=fib(); // 调用斐波那契方法获取斐波那契数列
// 获取到斐波那契数列的下标
while (arr.length>Fib[k]-1){
k++;
}
// 因为Fib[k]值可能大于arr的长度,
// 因此需要适用Array类,构造一个新的数组,并指向arr[],
// 不足的部分会使用0填充
int[] temp= Arrays.copyOf(arr,Fib[k]);
// temp={1,8,10,89,1000,1234,0,0,0} 就不是有序的了
// 实际上需要使用arr数组最后的数值填充temp
// temp={1,8,10,89,1000,1234,1234,1234,1234}
for (int i=high+1;i<temp.length;i++){
temp[i]=arr[high];
}
//使用while循环来处理,找到value
while (low<=high){
mid=low+Fib[k-1]-1;
// (F[k]-1)=(F[k-1]-1)+(F[k-2]-1)+1
if (value<temp[mid]){ // 向数组左半部分查找
high=mid-1;
k--; // 左半部分再拆分的前提,k--,
// 让F[k-1]-1做F[k]-1,故k要-1
}else if (value>temp[mid]){ // 向数组右半部分查找
low=mid+1;
k-=2; // 右半部分再拆分的前提,k-2,
// 让F[k-2]-1做F[k]-1,故k要-2
}else { // 找到
// 需要确定返回的是哪个下标 返回小的
if (mid<=high){
return mid;
}else {
return high;
}
}
}
return -1; // 没找到 返回-1
}
}

















 760
760

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









