



爬虫原理:
什么是爬虫
爬虫:一段自动抓取互联网信息的程序,可以从互联网上抓取对于我们有价值的信息。
python 制作蜘蛛爬虫的一般流程:
①浏览器打开目标网页源代码分析元素节点 ===>Fn+F12
②再用requests打开Url得到网页html文档
③通过Beautiful Soup或则正则表达式提取想要的数据
④存储数据到本地磁盘或数据库(抓取,分析,存储)
爬虫程序基本构筑思路:上网中便签绑定关键字与超链接 我们可以通过点击超链接访问下一级网页,或者再一个网站内可通过翻页的来访问下一级页面
而对于关键字搜索,我们只需要获得所有相应标签,即可实现全引用,在此之后我们便可以让关键字来实现精准引索
实现手段:正则表达式
存入xsl表格实现保存
作业途中遇见问题:无法保存运行结果到xsl‘表格中
爬虫功能:对小游戏网站实现全标签检索,搜索用户想要网站 并且实现查询所有相关网站
import requests
import re
import xlwt
from bs4 import BeautifulSoup
# 设置请求头
hd = {
'User-Agent': 'Mozilla/4.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/95.0.4638.69 Safari/537.36'
}
def fetch_page(url):
"""获取网页内容"""
response = requests.get(url, headers=hd)
response.raise_for_status()
response.encoding = response.apparent_encoding
return response.text
def save_excel(worksheet, count, tag, keyword, count_value, link):
"""保存数据到Excel"""
worksheet.write(count, 0, tag)
worksheet.write(count, 1, keyword)
worksheet.write(count, 2, count_value)
worksheet.write(count, 3, link)
def search_and_count_tags(html, tag, keyword):
"""搜索并计数特定标签中的关键字,并返回关键字所在标签的超链接"""
soup = BeautifulSoup(html, "html.parser")
tags = soup.find_all(tag)
counts = {keyword: 0}
links = []
for t in tags:
if re.search(keyword, t.text, re.IGNORECASE):
counts[keyword] += 1
# 提取超链接
href = t.get('href')
if href:
links.append(href)
return counts, links
def main(start_url, keywords, tag, pages):
workbook = xlwt.Workbook(encoding="utf-8")
worksheet = workbook.add_sheet('sheet1')
count = 0
# 写入表头
worksheet.write(count, 0, "Tag")
worksheet.write(count, 1, "Keyword")
worksheet.write(count, 2, "Count")
worksheet.write(count, 3, "Link")
count += 1
for page in range(1, pages + 1):
url = f"{start_url}/index_{page}.shtml" if page > 1 else start_url
print(f"Visiting: {url}")
try:
html = fetch_page(url)
soup = BeautifulSoup(html, "html.parser")
# 搜索并计数特定标签中的关键字
for keyword in keywords:
tag_counts, links = search_and_count_tags(html, tag, keyword)
print(f"Tag counts on {url} for '{keyword}': {tag_counts}")
# 保存到Excel
if tag_counts[keyword] > 0:
for link in links:
save_excel(worksheet, count, tag, keyword, tag_counts[keyword], link)
count += 1
# 解析游戏信息
ret = soup.find_all("div", class_="game-item")
for x in ret:
info = []
game_name = x.find("a").get_text(strip=True)
game_link = "https://www.4399.com" + x.find("a").get("href")
info.append(game_name)
info.append(game_link)
if info: # 确保info列表不为空
print(count, info)
save_excel(worksheet, count, "Game", game_name, 1, game_link)
count += 1
print("=" * 100)
except requests.RequestException as e:
print(f"Failed to fetch {url}: {e}")
workbook.save("games1111.xls")
print(f"Total games: {count}")
if __name__ == "__main__":
start_url = "https://www.4399.com"
keywords = ["爆枪突击", "造梦西游", "洛克王国", "大富翁", "赛尔号"] # 替换为你需要搜索的关键字
tag = "a" # 替换为你需要搜索的标签
pages = 10 # 替换为你需要爬取的页数
main(start_url, keywords, tag, pages)
代码运行结果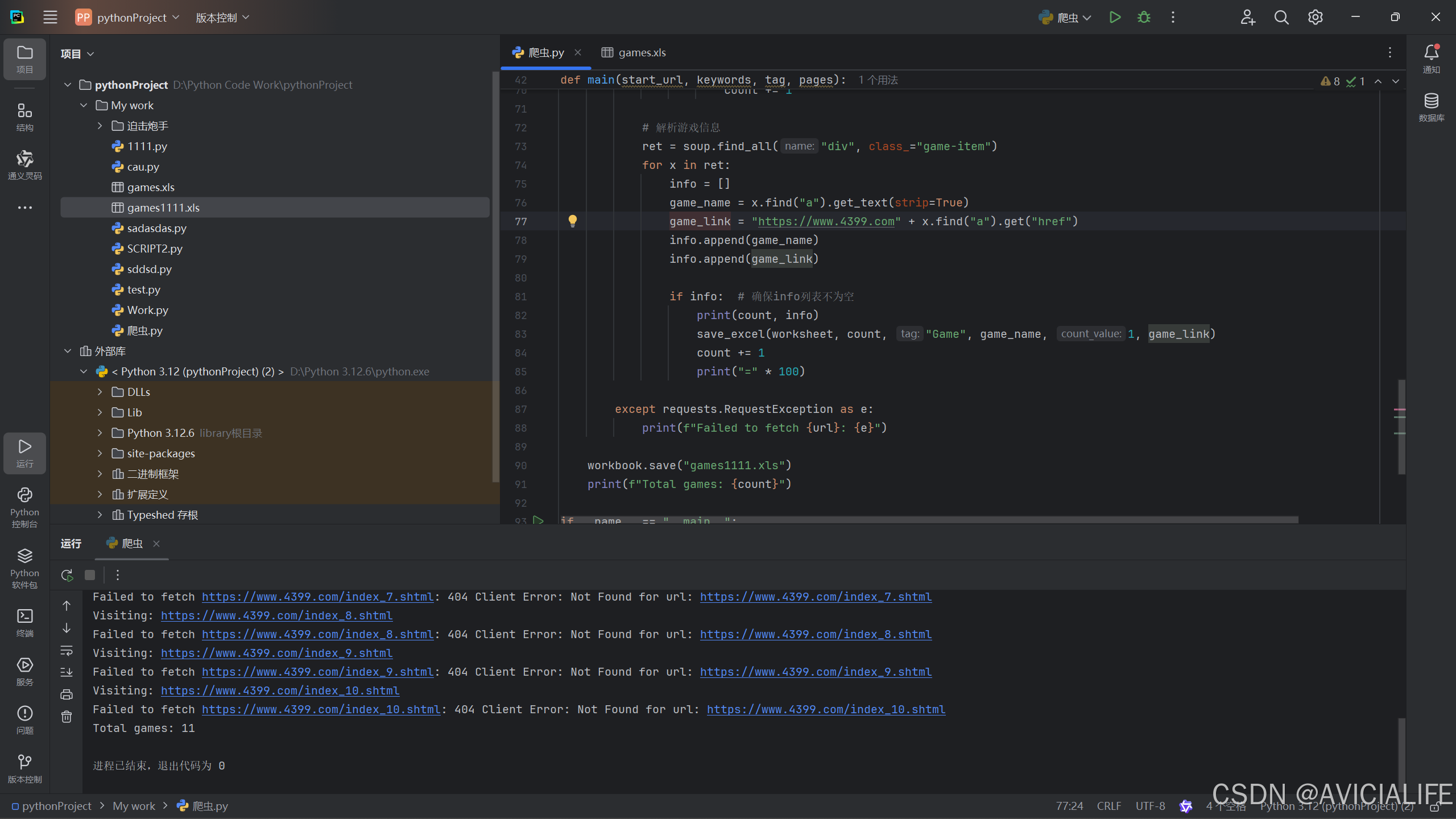 如图
如图
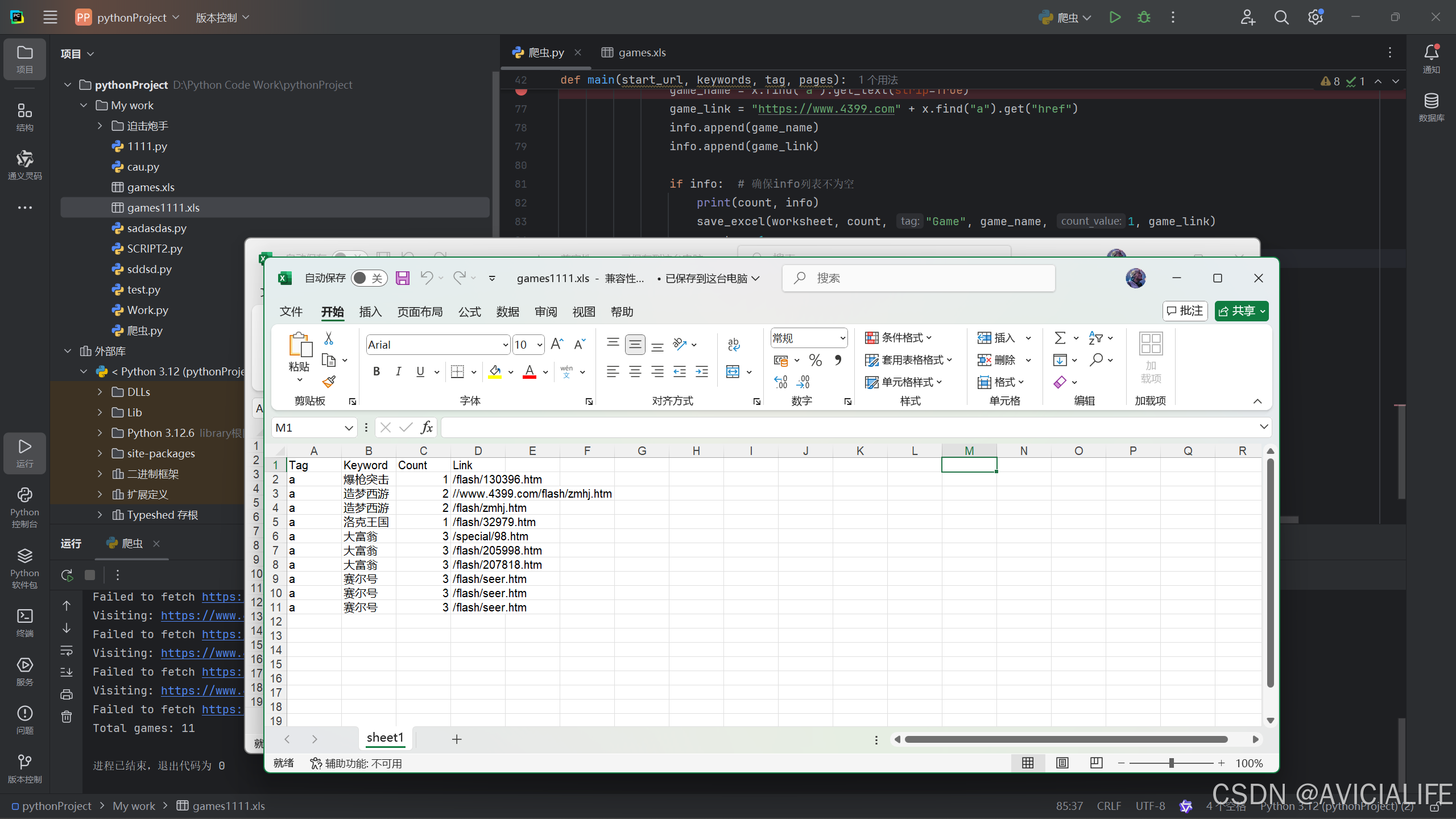

















 5519
5519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









