



 本文详述了使用Azkaban进行大数据批处理任务的自动调度流程,包括Flink Table API离线数据计算、Sqoop数据导出至MySQL,以及Azkaban 2.0版本的流设计与任务调度配置。
本文详述了使用Azkaban进行大数据批处理任务的自动调度流程,包括Flink Table API离线数据计算、Sqoop数据导出至MySQL,以及Azkaban 2.0版本的流设计与任务调度配置。
概述
本篇是用户综合分析系统专栏的最后一篇。到本篇为止,我们此次的项目实施宣告终结。
我们已经完成了大数据 流处理与批处理 的设计编码,已经实现了基本的数据处理任务,但是,因为批处理一般都是定期执行的,而且多数是在非服务器高峰期的半夜执行的,因此,我们需要用到 Azkaban的任务调度,帮我们完成批处理的自动执行。
设计计划
附:完整的计划zip包:
整体思路
批处理的过程是:
①先执行Flink的Table api完成离线数据计算
②再通过Sqoop将①中执行输出的数据写到MySQL
整体调度计划结构
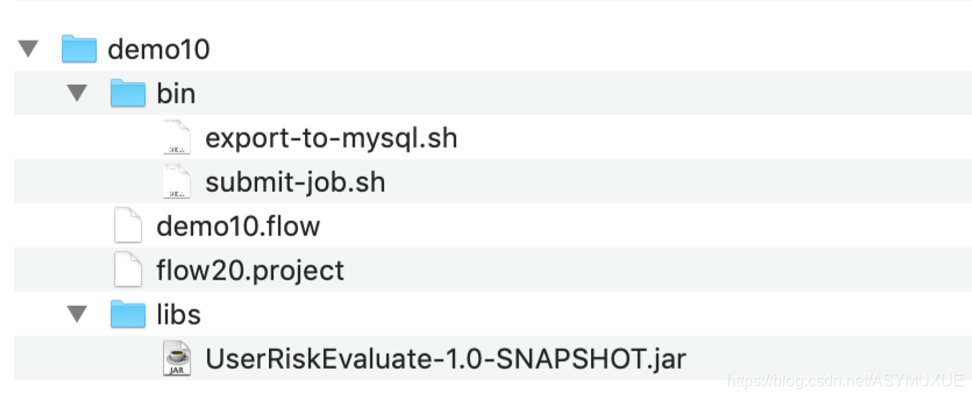
说明: 此次的项目批处理设计中,批处理的
读取文件地址和输出文件地址是作为参数传递的
libs下的代码实现
package com.baizhi.sql
import java.text.SimpleDateFormat
import org.apache.flink.api.scala.ExecutionEnvironment
import org.apache.flink.table.api.scala.BatchTableEnvironment
import org.apache.flink.table.api.scala._
import org.apache.flink.api.scala._
import java.math.{BigDecimal => JBigDecimal}
import org.apache.flink.api.common.typeinfo.TypeInformation
import org.apache.flink.api.java.io.jdbc.JDBCAppendTableSinkBuilder
import org.apache.flink.api.scala.typeutils.Types
object UserRiskErrorRateCount {
def main(args: Array[String]): Unit = {
val fbEnv = ExecutionEnvironment.getExecutionEnvironment
val fbTableEnv = BatchTableEnvironment.create(fbEnv)
//获取传递的参数
var input=args(0)
var output=args(1)
val sdf= new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val dataSet:DataSet[(String,String,String,String,String,Boolean,Boolean,Boolean,Boolean,Boolean,Boolean,Boolean)] = fbEnv.readTextFile(input,
"utf-8")
.map(_.split("\\s+"))
.map(ts => (ts(0),ts(1),sdf.format(ts(3).toLong),ts(4),ts(5),ts(6).toBoolean,
ts(7).toBoolean,ts(8).toBoolean,ts(9).toBoolean,ts(10).toBoolean,ts(11).toBoolean,ts(12).toBoolean))
val table = fbTableEnv.fromDataSet(dataSet,'appName,'userIdentified,'evaluateTime,'cityName,'geoPoint,'area,'device,'inputfeature, 'similarity, 'speed,'timeslot,'total)
//注册视图
fbTableEnv.createTemporaryView("t_report",table)
table.select("appName, userIdentified,evaluateTime,cityName,geoPoint,area,device,inputfeature,similarity, speed,timeslot,total")
.toDataSet[(String,String,String,String,String,Boolean,Boolean,Boolean,Boolean,Boolean,Boolean,Boolean)]
.print()
var tableSink = new JDBCAppendTableSinkBuilder()
.setDBUrl("jdbc:mysql://localhost:3306/test")
.setDrivername("com.mysql.jdbc.Driver")
.setUsername("root")
.setPassword("root")
.setBatchSize(1000)
.setQuery("INSERT INTO error_rate(app_name,area_rate,device_rate,inputfeature_rate,similarity_rate,speed_rate,timeslot_rate,total_rate,total,start,end) values(?,?,?,?,?,?,?,?,?,?,?)")
.setParameterTypes(Types.STRING, Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.INT,Types.STRING, Types.STRING)
.build();
fbTableEnv.registerTableSink("Result",
Array("app_name","area_rate","device_rate","inputfeature_rate","similarity_rate","speed_rate","timeslot_rate","total_rate","total","start","end"),
Array[TypeInformation[_]](Types.STRING, Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.JAVA_BIG_DEC,Types.INT, Types.STRING, Types.STRING),
tableSink)
//获取时间参数
var start=args(2)
var end=args(3)
//计算因子触发率
val sql=
s"""
select appName,
round(sum(case area when true then 1.0 else 0 end)/count(area),2) as area_rate,
round(sum(case device when true then 1.0 else 0 end)/count(device),2) as device_rate,
round(sum(case inputfeature when true then 1.0 else 0 end)/count(inputfeature),2) as inputfeature_rate,
round(sum(case similarity when true then 1.0 else 0 end)/count(similarity),2) as similarity_rate,
round(sum(case speed when true then 1.0 else 0 end)/count(speed),2) as speed_rate,
round(sum(case timeslot when true then 1.0 else 0 end)/count(timeslot),2) as timeslot_rate,
round(sum(case total when true then 1.0 else 0 end)/count(total),2) as total_rate,
count(*) as total
from (select * from t_report where evaluateTime between '${start}' and '${end}')
group by appName
"""
fbTableEnv.sqlQuery(sql)
.addColumns(s"'${start}' as start")
.addColumns(s"'${end}' as end")
.toDataSet[(String,JBigDecimal,JBigDecimal,JBigDecimal,JBigDecimal,JBigDecimal,JBigDecimal,JBigDecimal,Long,String,String)]
.map(t => t._1+","+t._2+","+t._3+","+t._4+","+t._5+","+t._6+","+t._7+","+t._8+","+t._9+","+t._10+","+t._11)
.writeAsText(output,WriteMode.OVERWRITE)
fbEnv.execute("UserRiskErrorRateCount")
}
}
flow20.project
2.0版本的 任务调度
azkaban-flow-version: 2.0
demo10.flow
---
config:
user.to.proxy: root
failure.emails: zyl.m@qq.com
success.emails: zyl.m@qq
notify.emails: zyl.m@qq
nodes:
- name: UserRiskErrorRateCount
type: command
config:
command: sh ./demo10/bin/submit-job.sh ${input} ${output}
- name: ExportToMysQL
type: command
dependsOn:
- UserRiskErrorRateCount
config:
command: sh ./demo10/bin/export-to-mysql.sh ${out}
${}----->表示传参,第二个任务的参数out,由第一个任务的执行计划传递
第一个任务Submit-job.sh
#!/usr/bin/env bash
base_path=$(pwd)
jar_path=$base_path/demo10/libs/UserRiskEvaluate-1.0-SNAPSHOT.jar
start_time=$(date -d -1month '+%Y-%m-%d')
end_time=$(date '+%Y-%m-%d')
input=$1
output=$2
/usr/flink-1.10.0/bin/flink run --class com.baizhi.sql.UserRiskErrorRateCount --parallelism 4 --jobmanager centos:8081 $jar_path $input $output $start_time $end_time
echo '{"out":"'$output'"}' > $JOB_OUTPUT_PROP_FILE
说明:${date -d -1month ‘+%Y-%m-%d’} 表示获取当前时间减去一个月的时间,作为传递到批处理计算的第三个参数,后面的end_time作为第四个参数
第二个任务export-to-mysql.sh
#!/usr/bin/env bash
sqoop export --connect jdbc:mysql://CentOS:3306/test --username root --password root --table error_rate --update-key app_name --update-mode allowinsert --export-dir $1 --input-fields-terminated-by ','
- 将以上文件打成
Zip包,上传到Azkaban的客户端,提交执行即可。
测试
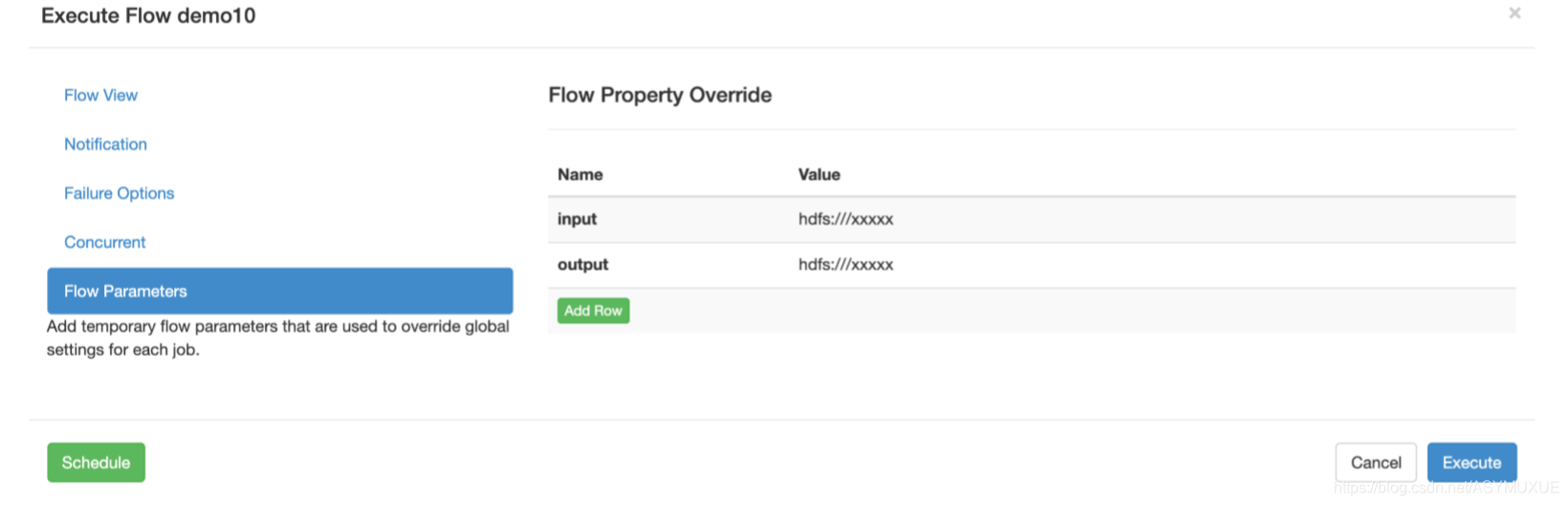
在以上界面中填写参数即可注:参数名一定要与脚本中的名字一致
附
本次项目的完整源码:
https://pan.baidu.com/s/1YLcfiaiYIe0Gnj9IY2wYgQ 获取码:ag8t
2020-04-10 项目结束,有缘再见。-----------------------项目交付就跑路的项目经理。

















 2973
2973

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









