




选题背景意义
随着智能交通系统的快速发展,无人驾驶技术已成为汽车行业的重要发展方向。据统计,截至2025年,全球无人驾驶汽车市场规模预计将达到700亿美元,年复合增长率超过40%。无人驾驶技术的核心在于环境感知,而道路车辆检测与分类是环境感知系统的关键组成部分。准确、高效的车辆检测与分类能力直接影响无人驾驶汽车的行驶安全和决策准确性。

传统的车辆检测方法主要依赖于人工设计的特征提取算法,如HOG、SIFT等,这些方法在复杂路况下表现不佳,难以应对光照变化、车辆遮挡和恶劣天气等情况。深度学习技术的出现为车辆检测与分类带来了革命性的变化,特别是卷积神经网络(CNN)在图像识别领域取得了突破性进展。Faster R-CNN作为一种基于区域推荐的两阶段目标检测算法,具有较高的检测精度,但在处理小目标和实时性方面仍有改进空间。
本研究计划基于改进的Faster R-CNN算法,构建一个高效的无人驾驶道路车辆检测与分类系统。研究内容包括:车辆图像预处理算法研究及数据集建立,针对无人驾驶道路车辆图像特点、光照及遮挡问题,提出改进的图像预处理算法;基于改进的Faster R-CNN的道路车辆检测与分类,通过引入特征金字塔网络(FPN)和组合剪枝算法,提高模型对小目标的检测能力和实时性能;网络模型性能评估,验证改进算法的有效性和优越性。
数据集构建
数据获取
为了构建高质量的无人驾驶道路车辆数据集,需要从多种渠道获取车辆图像数据。主要数据来源包括:1)公开数据集,如KITTI、COCO、PASCAL VOC等,这些数据集包含大量标注好的车辆图像,可以作为基础数据;2)实地采集,通过在道路上安装摄像头,采集不同路况、不同天气条件下的车辆图像;3)网络爬取,从汽车网站、交通监控视频等来源爬取车辆图像;4)模拟数据,利用无人驾驶模拟器生成车辆图像数据。在数据获取过程中,需要考虑数据的多样性和代表性。应包含不同车型(如轿车、SUV、卡车、公交车等)、不同路况(如城市道路、高速公路、乡村道路等)、不同天气条件(如晴天、雨天、雾天等)、不同光照条件(如白天、夜晚、逆光等)以及不同遮挡情况(如部分遮挡、完全遮挡等)的图像数据。这样可以确保训练出的模型具有较强的泛化能力。

数据获取后,需要对数据进行初步筛选,去除模糊、重复或质量较差的图像。同时,要确保数据的合法性和隐私保护,避免使用未经授权的图像数据。
数据格式与类别
构建的数据集应包含10类不同的车型,具体类别根据实际需求确定,如轿车、SUV、小型货车、中型货车、大型货车、公交车、出租车、摩托车、三轮车和自行车等。每类车型应包含足够数量的样本,以保证模型训练的充分性。
数据格式采用标准的图像格式,如JPEG、PNG等,图像分辨率统一调整为合适的尺寸,如800×600像素。同时,为了方便模型训练,需要将数据集划分为训练集、验证集和测试集,比例一般为7:2:1。训练集用于模型参数学习,验证集用于调整模型超参数和监控训练过程,测试集用于评估模型的最终性能。
此外,还需要为每个图像样本创建对应的标注文件,标注文件应包含车辆的位置信息(边界框坐标)和类别信息。标注文件格式可以采用XML、JSON等标准格式,方便模型读取和解析。
数据标注
数据标注是构建高质量数据集的关键步骤,直接影响模型的训练效果。标注工作主要包括车辆目标的定位和分类。定位是指在图像中画出包围车辆的边界框,分类是指确定车辆所属的类别。
为了提高标注效率和准确性,可以采用半自动化标注工具,如LabelImg、VGG Image Annotator(VIA)等。这些工具提供了友好的界面,可以快速完成图像标注工作。对于大量的图像数据,可以考虑采用众包标注的方式,借助第三方标注平台完成标注任务。
标注过程中需要遵循严格的标注规范,确保标注的一致性和准确性。例如,边界框应尽可能紧密地包围车辆目标,避免包含过多的背景信息;对于遮挡的车辆,应标注可见部分的边界框;对于多辆重叠的车辆,应分别标注每个车辆的边界框。标注完成后,需要进行质量检查,去除错误或不准确的标注。
数据处理
为了提高模型的泛化能力和鲁棒性,需要对标注好的数据进行预处理和数据增强。预处理步骤包括:
1. 图像去噪:采用改进的中值滤波算法对图像进行去噪处理,在保持图像细节的同时,有效去除椒盐噪声和高斯噪声。改进的中值滤波算法结合了几何平均数计算,提高了对高斯噪声的抑制能力。
2. 图像增强:采用直方图均衡化算法对图像进行增强处理,提高图像的对比度和细节表达能力。直方图均衡化可以将图像灰度级密集的范围放大至整个灰度范围,使图像灰度级分布更加均匀,有利于目标物体的特征提取。
3. 图像归一化:将图像像素值归一化到一定范围(如[0,1]或[-1,1]),加速模型训练过程中的收敛速度。
数据增强步骤包括:
1. 几何变换:对图像进行旋转、缩放、平移、翻转等几何变换,增加数据的多样性。
2. 颜色变换:对图像进行亮度、对比度、饱和度等颜色属性的调整,模拟不同光照条件下的图像。
3. 加噪处理:向图像中添加适量的高斯噪声、椒盐噪声等,提高模型对噪声的鲁棒性。
4. 遮挡处理:使用mask掩模算法对部分图像进行遮挡处理,模拟车辆被遮挡的情况,提高模型对遮挡车辆的检测能力。
通过这些数据处理步骤,可以大大提高数据集的质量和多样性,为模型训练提供良好的基础。
功能模块介绍
图像预处理模块
图像预处理模块是无人驾驶道路车辆检测与分类系统的重要组成部分,负责对输入的车辆图像进行去噪、增强等处理,提高图像质量和特征表达能力。该模块的主要功能包括:接收原始车辆图像,进行改进的中值滤波去噪处理,采用直方图均衡化进行图像增强,输出预处理后的高质量图像。
在设计图像预处理模块时,需要考虑不同路况和天气条件下的图像特点。例如,在雨天和雾天,图像会出现模糊和低对比度的情况;在夜晚,图像会出现亮度不足和噪声较多的情况。因此,预处理算法需要具有较强的适应性,能够处理各种复杂情况。改进的中值滤波算法结合了几何平均数计算,在保持图像细节的同时,有效去除了不同类型的噪声;直方图均衡化算法能够提高图像的对比度,增强目标物体的特征表达。
图像预处理模块的实现可以采用Python编程语言,结合OpenCV等图像处理库。该模块可以设计为一个独立的函数或类,接收图像路径或图像数据作为输入,返回预处理后的图像数据。模块的性能直接影响后续检测和分类的准确性,因此需要进行充分的测试和优化,确保处理速度和效果的平衡。
车辆检测模块
车辆检测模块是系统的核心组成部分,负责在预处理后的图像中检测出车辆目标的位置。该模块基于改进的Faster R-CNN算法实现,主要功能包括:特征提取、区域推荐、目标分类和边界框回归。
Faster R-CNN算法采用两阶段检测策略,首先通过区域推荐网络(RPN)生成候选区域,然后对候选区域进行分类和边界框回归。为了提高对小目标的检测能力,本研究计划在Faster R-CNN中引入特征金字塔网络(FPN)。FPN可以融合不同层次的特征信息,高层特征具有较强的语义信息,低层特征具有较高的空间分辨率,融合后的特征能够同时兼顾语义信息和空间信息,提高对小目标的检测精度。
车辆检测模块的实现可以基于深度学习框架,如TensorFlow或PyTorch。需要构建完整的网络结构,包括特征提取网络(如ResNet、VGG等)、RPN网络和FPN网络。训练过程中,需要使用标注好的数据集,通过反向传播算法更新网络参数。为了提高模型的实时性能,可以采用GPU加速和模型优化技术。
车辆分类模块
车辆分类模块负责对检测出的车辆目标进行分类,确定其所属的车型类别。该模块基于卷积神经网络实现,主要功能包括:特征提取、特征分类和结果输出。
车辆分类模块可以与检测模块共享部分网络结构,提高系统的效率。例如,可以使用检测模块中的特征提取网络作为分类模块的基础网络,然后添加几个全连接层和分类层,实现车辆类别的预测。为了提高分类准确性,需要针对不同车型的特点,提取有效的特征信息。
在训练分类模块时,需要使用大量标注好的车辆图像数据,并采用合适的损失函数和优化算法。常用的损失函数包括交叉熵损失函数,优化算法包括随机梯度下降(SGD)、Adam等。训练过程中,需要监控分类准确率和损失值的变化,及时调整网络参数和超参数。
模型优化模块
模型优化模块负责对训练好的检测和分类模型进行优化,提高模型的实时性能和部署效率。该模块基于组合剪枝算法实现,主要功能包括:模型分析、卷积核剪枝、权重剪枝和模型微调。
深度卷积神经网络通常包含大量的参数和计算量,这给模型的实时部署带来了挑战。剪枝算法可以通过去除冗余的卷积核和权重,减少模型的参数数量和计算量,提高模型的运行速度。本研究计划采用组合剪枝算法,结合卷积核剪枝和权重剪枝的优点,在保证模型精度的同时,最大程度地减少模型大小和计算量。
模型优化模块的实现需要对网络结构和参数有深入的理解。首先,需要分析网络中各层的重要性,确定可以剪枝的卷积核和权重;然后,采用合适的剪枝策略进行剪枝操作;最后,对剪枝后的模型进行微调,恢复模型的性能。优化后的模型可以部署到嵌入式设备或车载系统中,实现实时的车辆检测与分类。
算法理论
卷积神经网络(CNN)
卷积神经网络是一类包含卷积计算且具有深度结构的前馈神经网络,是深度学习的核心算法之一。CNN主要由卷积层、池化层和全连接层构成,具有局部连接、权值共享和池化采样的特点,可以直接处理原始图像数据。
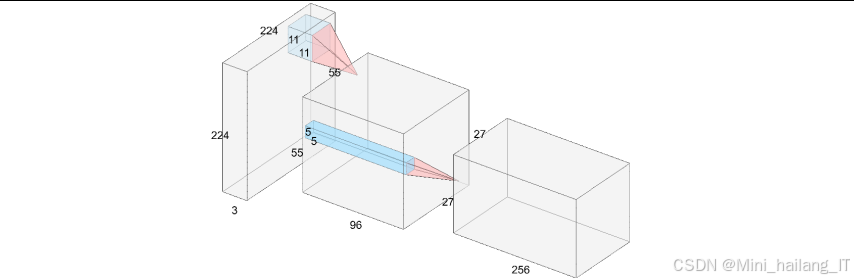
卷积层是CNN的核心组成部分,负责提取图像的特征信息。卷积运算通过卷积核在图像上滑动,计算卷积核与图像局部区域的内积,生成特征图。权值共享机制使得卷积核可以在整个图像上重复使用,大大减少了网络参数的数量。不同的卷积核可以提取不同的特征,如边缘、纹理、形状等。
池化层位于卷积层之后,负责对特征图进行下采样,减少特征图的尺寸和计算量。常用的池化操作包括最大池化和平均池化,最大池化可以提取特征图中的最大值,保留最显著的特征信息;平均池化可以提取特征图中的平均值,具有平滑效果。池化层可以提高网络的鲁棒性,减少过拟合现象的发生。
全连接层位于网络的最后,负责将前面提取的特征进行整合,并输出分类结果。全连接层中的每个神经元与前一层的所有神经元相连,将特征映射到样本标记空间。全连接层通常使用激活函数(如ReLU、Softmax等)进行非线性变换,提高网络的表达能力。

CNN在图像识别领域取得了巨大成功,主要得益于其强大的特征提取能力和参数共享机制。在无人驾驶道路车辆检测与分类任务中,CNN可以自动学习车辆的特征信息,无需人工设计特征提取算法,提高了检测和分类的准确性和鲁棒性。
Faster R-CNN算法
Faster R-CNN是一种基于区域推荐的两阶段目标检测算法,由Ren等人于2015年提出。该算法将特征提取、区域推荐、目标分类和边界框回归整合到一个统一的网络框架中,具有较高的检测精度和效率。Faster R-CNN的网络结构主要包括四个部分:1)特征提取网络,用于提取图像的特征信息;2)区域推荐网络(RPN),用于生成候选区域;3)感兴趣区域池化层(RoI Pooling),用于将不同尺寸的候选区域映射到固定尺寸的特征图;4)分类和回归网络,用于对候选区域进行分类和边界框回归。

区域推荐网络(RPN)是Faster R-CNN的核心创新点,它可以在特征图上直接生成候选区域,避免了传统方法中使用选择性搜索(Selective Search)生成候选区域的计算开销。RPN通过在特征图上滑动一个小网络,生成大量的候选区域,并预测每个候选区域的类别(前景或背景)和边界框偏移量。
感兴趣区域池化层(RoI Pooling)可以将不同尺寸的候选区域映射到固定尺寸的特征图,解决了候选区域尺寸不一致的问题。RoI Pooling将候选区域划分为固定数量的子区域,对每个子区域进行最大池化操作,生成固定尺寸的特征向量。
分类和回归网络接收RoI Pooling输出的固定尺寸特征向量,通过全连接层和激活函数,预测每个候选区域的类别和边界框偏移量。损失函数采用多任务损失函数,包括分类损失和回归损失,同时优化分类和回归任务。
Faster R-CNN算法具有较高的检测精度,但在处理小目标和实时性方面仍有改进空间。本研究计划在Faster R-CNN的基础上,引入特征金字塔网络(FPN)和组合剪枝算法,提高模型对小目标的检测能力和实时性能。
特征金字塔网络(FPN)
特征金字塔网络(FPN)是一种用于目标检测的特征提取架构,由Lin等人于2017年提出。FPN可以融合不同层次的特征信息,解决了传统卷积神经网络中高层特征语义信息强但空间分辨率低、低层特征空间分辨率高但语义信息弱的问题。FPN的网络结构主要包括自下而上的路径、自上而下的路径和横向连接三部分。自下而上的路径是传统的卷积神经网络,如ResNet,用于提取图像的特征信息。在自下而上的路径中,每经过一个阶段,特征图的尺寸减半,特征的语义信息增强。

自上而下的路径用于生成高层特征的高分辨率版本。通过上采样操作(如最近邻插值或反卷积),将高层特征图的尺寸放大到与低层特征图相同,然后与低层特征图进行融合。横向连接用于将自下而上路径中的低层特征图与自上而下路径中的高层特征图进行融合,融合后的特征图同时具有高层特征的语义信息和低层特征的空间分辨率。
FPN可以在多个尺度上进行目标检测,每个尺度的特征图负责检测不同大小的目标。小目标可以在高分辨率的低层特征图上检测,大目标可以在低分辨率的高层特征图上检测。这种多尺度检测策略可以提高对不同大小目标的检测精度,特别是对小目标的检测效果有明显提升。
在无人驾驶道路车辆检测任务中,车辆的大小变化较大,从小型摩托车到大型卡车都需要检测。引入FPN可以有效提高对不同大小车辆的检测能力,特别是在处理远处的小目标车辆时,效果更加明显。
组合剪枝算法
组合剪枝算法是一种用于压缩深度卷积神经网络的方法,结合了卷积核剪枝和权重剪枝的优点。卷积核剪枝通过去除冗余的卷积核,减少卷积层的计算量;权重剪枝通过去除冗余的权重连接,减少模型的参数数量。组合剪枝算法可以在保证模型精度的同时,最大程度地减少模型大小和计算量。
卷积核剪枝的核心思想是根据卷积核的重要性对其进行排序,去除重要性较低的卷积核。卷积核的重要性可以通过多种方式衡量,如卷积核的L1范数、L2范数、激活值等。常用的卷积核剪枝方法包括基于幅度的剪枝和基于梯度的剪枝。权重剪枝的核心思想是根据权重的大小对其进行排序,去除绝对值较小的权重。权重剪枝可以分为结构化剪枝和非结构化剪枝。结构化剪枝去除整个卷积核或通道,保持网络结构的规整性,便于硬件加速;非结构化剪枝可以去除任意位置的权重,剪枝率较高,但会破坏网络结构的规整性,不便于硬件加速。组合剪枝算法通常包括以下步骤:1)模型预训练,训练一个性能较好的原始模型;2)模型分析,分析网络中各层的重要性和冗余度;3)卷积核剪枝,去除冗余的卷积核;4)权重剪枝,去除冗余的权重连接;5)模型微调,恢复模型的性能。
相关代码介绍
图像预处理代码
图像预处理是车辆检测与分类系统的第一步,主要包括图像去噪和增强处理。本研究采用改进的中值滤波算法进行去噪,结合直方图均衡化算法进行图像增强。以下是图像预处理的核心代码:
import cv2
import numpy as np
def improved_median_filter(image, kernel_size=3):
"""
改进的中值滤波算法
:param image: 输入图像
:param kernel_size: 滤波核大小
:return: 去噪后的图像
"""
# 将图像转换为灰度图
if len(image.shape) == 3:
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
else:
gray = image
# 边界填充
pad_size = kernel_size // 2
padded = cv2.copyMakeBorder(gray, pad_size, pad_size, pad_size, pad_size, cv2.BORDER_REFLECT)
# 初始化输出图像
output = np.zeros_like(gray)
# 遍历图像
for i in range(gray.shape[0]):
for j in range(gray.shape[1]):
# 获取窗口区域
window = padded[i:i+kernel_size, j:j+kernel_size]
# 计算窗口内的最小值、最大值和中值
min_val = np.min(window)
max_val = np.max(window)
median_val = np.median(window)
# 计算窗口内的算术平均值
mean_val = np.mean(window)
# 计算几何平均数作为中心像素值
if min_val > 0:
geo_mean = np.exp(np.mean(np.log(window + 1e-10)))
else:
geo_mean = median_val
# 确定中心像素值
if min_val < median_val < max_val:
output[i, j] = geo_mean
else:
output[i, j] = median_val
return output
def histogram_equalization(image):
"""
直方图均衡化算法
:param image: 输入图像
:return: 增强后的图像
"""
# 将图像转换为灰度图
if len(image.shape) == 3:
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
else:
gray = image
# 直方图均衡化
equalized = cv2.equalizeHist(gray)
# 如果输入是彩色图像,将均衡化后的灰度图转换回彩色图像
if len(image.shape) == 3:
equalized = cv2.cvtColor(equalized, cv2.COLOR_GRAY2BGR)
return equalized
def preprocess_image(image_path):
"""
图像预处理主函数
:param image_path: 图像路径
:return: 预处理后的图像
"""
# 读取图像
image = cv2.imread(image_path)
# 改进的中值滤波去噪
denoised = improved_median_filter(image)
# 直方图均衡化增强
enhanced = histogram_equalization(denoised)
return enhanced
这段代码实现了改进的中值滤波算法和直方图均衡化算法。改进的中值滤波算法在传统中值滤波的基础上,结合了几何平均数计算,提高了对高斯噪声的抑制能力。直方图均衡化算法可以提高图像的对比度,增强目标物体的特征表达。图像预处理主函数将这两个算法结合起来,先对图像进行去噪处理,再进行增强处理,输出高质量的预处理图像。
在实际应用中,可以根据具体需求调整滤波核大小、均衡化参数等。同时,为了提高处理效率,可以考虑使用GPU加速或并行计算技术。预处理后的图像将作为车辆检测模块的输入,直接影响后续检测和分类的准确性。
Faster R-CNN模型构建代码
Faster R-CNN是本研究的核心算法,用于实现车辆检测与分类功能。以下是基于TensorFlow框架构建Faster R-CNN模型的核心代码:
import tensorflow as tf
from tensorflow.keras import layers, models
class FasterRCNN(models.Model):
def __init__(self, num_classes=10):
super(FasterRCNN, self).__init__()
self.num_classes = num_classes
# 特征提取网络(使用ResNet50作为基础网络)
self.feature_extractor = tf.keras.applications.ResNet50(include_top=False, weights='imagenet', input_shape=(800, 600, 3))
# 特征金字塔网络(FPN)
self.fpn = FPN()
# 区域推荐网络(RPN)
self.rpn = RPN()
# ROI池化层
self.roi_pooling = ROIPooling()
# 分类和回归网络
self.classifier = Classifier(num_classes)
def call(self, inputs, training=False):
# 特征提取
features = self.feature_extractor(inputs)
# 特征金字塔融合
fpn_features = self.fpn(features)
# 区域推荐
proposals, rpn_loss = self.rpn(fpn_features, training=training)
# ROI池化
roi_features = self.roi_pooling(fpn_features, proposals)
# 分类和回归
classifications, regressions, cls_loss = self.classifier(roi_features, training=training)
if training:
return proposals, classifications, regressions, rpn_loss, cls_loss
else:
return proposals, classifications, regressions
class FPN(models.Model):
def __init__(self):
super(FPN, self).__init__()
# FPN网络结构定义
self.lateral_conv1 = layers.Conv2D(256, (1, 1), padding='same', activation='relu')
self.lateral_conv2 = layers.Conv2D(256, (1, 1), padding='same', activation='relu')
self.lateral_conv3 = layers.Conv2D(256, (1, 1), padding='same', activation='relu')
self.lateral_conv4 = layers.Conv2D(256, (1, 1), padding='same', activation='relu')
self.smooth_conv1 = layers.Conv2D(256, (3, 3), padding='same', activation='relu')
self.smooth_conv2 = layers.Conv2D(256, (3, 3), padding='same', activation='relu')
self.smooth_conv3 = layers.Conv2D(256, (3, 3), padding='same', activation='relu')
def call(self, features):
# FPN前向传播
# ...(代码省略)
return fpn_features
class RPN(models.Model):
def __init__(self):
super(RPN, self).__init__()
# RPN网络结构定义
self.conv = layers.Conv2D(256, (3, 3), padding='same', activation='relu')
self.classification = layers.Conv2D(2, (1, 1), activation='softmax')
self.regression = layers.Conv2D(4, (1, 1))
def call(self, features, training=False):
# RPN前向传播
# ...(代码省略)
return proposals, rpn_loss
class ROIPooling(layers.Layer):
def __init__(self, pool_size=(7, 7)):
super(ROIPooling, self).__init__()
self.pool_size = pool_size
def call(self, features, proposals):
# ROI池化操作
# ...(代码省略)
return roi_features
class Classifier(models.Model):
def __init__(self, num_classes):
super(Classifier, self).__init__()
self.num_classes = num_classes
# 分类网络结构定义
self.flatten = layers.Flatten()
self.fc1 = layers.Dense(1024, activation='relu')
self.dropout1 = layers.Dropout(0.5)
self.fc2 = layers.Dense(1024, activation='relu')
self.dropout2 = layers.Dropout(0.5)
self.classification = layers.Dense(num_classes, activation='softmax')
self.regression = layers.Dense(num_classes * 4)
def call(self, features, training=False):
# 分类和回归网络前向传播
# ...(代码省略)
return classifications, regressions, cls_loss
这段代码实现了基于TensorFlow框架的Faster R-CNN模型,包括特征提取网络、特征金字塔网络(FPN)、区域推荐网络(RPN)、ROI池化层和分类回归网络。特征提取网络使用预训练的ResNet50模型,能够提取高质量的图像特征;FPN网络可以融合不同层次的特征信息,提高对小目标的检测能力;RPN网络可以生成候选区域,避免了传统方法中使用选择性搜索生成候选区域的计算开销;ROI池化层可以将不同尺寸的候选区域映射到固定尺寸的特征图;分类和回归网络负责对候选区域进行分类和边界框回归。
在实际应用中,需要根据具体需求调整网络结构和参数。例如,可以选择不同的基础网络(如VGG、Inception等),调整FPN的层数和通道数,修改RPN的锚点设置等。同时,需要使用标注好的数据集对模型进行训练,通过反向传播算法更新网络参数。训练过程中,需要监控损失值和评价指标的变化,及时调整学习率和其他超参数。
组合剪枝算法代码
组合剪枝算法用于压缩训练好的Faster R-CNN模型,提高模型的实时性能。以下是组合剪枝算法的核心代码:
import tensorflow as tf
from tensorflow.keras import layers, models
import numpy as np
def convolution_kernel_pruning(model, pruning_rate=0.3):
"""
卷积核剪枝
:param model: 原始模型
:param pruning_rate: 剪枝率
:return: 剪枝后的模型
"""
# 创建剪枝后的模型
pruned_model = tf.keras.models.clone_model(model)
pruned_model.set_weights(model.get_weights())
# 遍历模型中的所有卷积层
for layer in pruned_model.layers:
if isinstance(layer, layers.Conv2D):
# 获取卷积层的权重
weights = layer.get_weights()[0]
biases = layer.get_weights()[1]
# 计算每个卷积核的L2范数
kernel_norms = np.linalg.norm(weights, axis=(0, 1, 2))
# 对卷积核进行排序,选择要保留的卷积核
num_kernels = weights.shape[-1]
num_pruned = int(num_kernels * pruning_rate)
sorted_indices = np.argsort(kernel_norms)
pruned_indices = sorted_indices[:num_pruned]
kept_indices = sorted_indices[num_pruned:]
# 剪枝卷积核
pruned_weights = weights[:, :, :, kept_indices]
pruned_biases = biases[kept_indices]
# 更新卷积层的权重
layer.set_weights([pruned_weights, pruned_biases])
# 更新下一层的输入通道数(如果下一层是卷积层或全连接层)
next_layer = get_next_layer(pruned_model, layer)
if next_layer is not None and (isinstance(next_layer, layers.Conv2D) or isinstance(next_layer, layers.Dense)):
next_weights = next_layer.get_weights()[0]
if isinstance(next_layer, layers.Conv2D):
# 下一层是卷积层,调整输入通道数
next_pruned_weights = next_weights[:, :, kept_indices, :]
else:
# 下一层是全连接层,调整输入神经元数
# 需要将权重重塑为适合调整的形状
# ...(代码省略)
pass
if len(next_layer.get_weights()) > 1:
next_biases = next_layer.get_weights()[1]
next_layer.set_weights([next_pruned_weights, next_biases])
else:
next_layer.set_weights([next_pruned_weights])
return pruned_model
def weight_pruning(model, pruning_rate=0.5):
"""
权重剪枝
:param model: 原始模型
:param pruning_rate: 剪枝率
:return: 剪枝后的模型
"""
# 创建剪枝后的模型
pruned_model = tf.keras.models.clone_model(model)
pruned_model.set_weights(model.get_weights())
# 遍历模型中的所有可训练层
for layer in pruned_model.layers:
if hasattr(layer, 'get_weights') and len(layer.get_weights()) > 0:
weights = layer.get_weights()[0]
# 计算权重的绝对值
weight_abs = np.abs(weights)
# 计算剪枝阈值
threshold = np.percentile(weight_abs, pruning_rate * 100)
# 剪枝权重
pruned_weights = weights * (weight_abs > threshold)
# 更新层的权重
if len(layer.get_weights()) > 1:
biases = layer.get_weights()[1]
layer.set_weights([pruned_weights, biases])
else:
layer.set_weights([pruned_weights])
return pruned_model
def combined_pruning(model, kernel_pruning_rate=0.3, weight_pruning_rate=0.5):
"""
组合剪枝算法
:param model: 原始模型
:param kernel_pruning_rate: 卷积核剪枝率
:param weight_pruning_rate: 权重剪枝率
:return: 剪枝后的模型
"""
# 第一步:卷积核剪枝
model_after_kernel_pruning = convolution_kernel_pruning(model, kernel_pruning_rate)
# 第二步:权重剪枝
model_after_combined_pruning = weight_pruning(model_after_kernel_pruning, weight_pruning_rate)
return model_after_combined_pruning
def get_next_layer(model, current_layer):
"""
获取当前层的下一层
:param model: 模型
:param current_layer: 当前层
:return: 下一层
"""
# 获取当前层的输出节点
current_output = current_layer.output
# 遍历模型中的所有层
for layer in model.layers:
# 如果当前层的输入是前一层的输出,则返回当前层
if hasattr(layer, 'input') and layer.input is current_output:
return layer
return None
这段代码实现了组合剪枝算法,包括卷积核剪枝和权重剪枝。卷积核剪枝通过去除重要性较低的卷积核,减少卷积层的计算量;权重剪枝通过去除绝对值较小的权重,减少模型的参数数量。组合剪枝算法可以在保证模型精度的同时,最大程度地减少模型大小和计算量。
在实际应用中,需要根据具体需求调整剪枝率和剪枝策略。例如,可以对不同的卷积层设置不同的剪枝率,对重要性较高的层设置较低的剪枝率,对重要性较低的层设置较高的剪枝率。同时,剪枝后的模型需要进行微调,恢复模型的性能。微调过程中,可以使用较小的学习率,对剪枝后的模型进行少量迭代的训练。
重难点和创新点
本研究的重难点主要包括以下几个方面:
1. 复杂路况下的车辆检测与分类:无人驾驶场景下,车辆检测与分类面临着多种挑战,如光照变化、车辆遮挡、恶劣天气和复杂背景等。如何提高模型在复杂路况下的检测精度和鲁棒性是本研究的重点之一。
2. 小目标车辆的检测:在无人驾驶场景下,远处的车辆通常呈现为小目标,传统的检测算法在处理小目标时表现不佳。如何提高模型对小目标车辆的检测能力是本研究的难点之一。
3. 模型的实时性能:无人驾驶系统对实时性要求较高,需要在短时间内完成车辆检测与分类任务。如何在保证检测精度的同时,提高模型的实时性能是本研究的重点之一。
4. 数据集的构建:高质量的数据集是训练好模型的基础,如何构建包含不同车型、不同路况、不同天气条件和不同遮挡情况的数据集是本研究的难点之一。
本研究的创新点主要包括以下几个方面:
1. 改进的图像预处理算法:提出了一种改进的中值滤波算法,结合了几何平均数计算,在保持图像细节的同时,有效去除了椒盐噪声和高斯噪声。该算法可以提高图像质量,为后续的检测和分类任务提供良好的基础。
2. 基于FPN的Faster R-CNN改进:在Faster R-CNN中引入特征金字塔网络(FPN),融合不同层次的特征信息,提高了对小目标车辆的检测能力。FPN可以同时兼顾高层特征的语义信息和低层特征的空间信息,解决了传统卷积神经网络中高层特征语义信息强但空间分辨率低、低层特征空间分辨率高但语义信息弱的问题。
3. 组合剪枝算法:提出了一种组合剪枝算法,结合了卷积核剪枝和权重剪枝的优点。该算法可以在保证模型精度的同时,最大程度地减少模型大小和计算量,提高模型的实时性能。剪枝后的模型更容易部署到嵌入式设备或车载系统中,降低了硬件成本和功耗。
4. 遮挡处理策略:使用mask掩模算法对训练数据集部分图像进行遮挡处理,提高了网络模型对遮挡图像的敏感度。这种处理策略可以模拟车辆被遮挡的情况,增强模型对遮挡车辆的检测能力。
总结
本研究计划基于深度学习技术,构建一个高效的无人驾驶道路车辆检测与分类系统。主要研究内容包括车辆图像预处理算法研究及数据集建立、基于改进的Faster R-CNN的道路车辆检测与分类、网络模型性能评估等。
在图像预处理方面,提出了一种改进的中值滤波算法,结合了几何平均数计算,在保持图像细节的同时,有效去除了椒盐噪声和高斯噪声;采用直方图均衡化算法对图像进行增强,提高了图像的对比度和细节表达能力。
在车辆检测与分类方面,基于改进的Faster R-CNN算法,引入了特征金字塔网络(FPN)和组合剪枝算法。FPN可以融合不同层次的特征信息,提高对小目标车辆的检测能力;组合剪枝算法可以在保证模型精度的同时,最大程度地减少模型大小和计算量,提高模型的实时性能。
在数据集构建方面,计划从多种渠道获取车辆图像数据,包括公开数据集、实地采集、网络爬取和模拟数据等。数据集将包含不同车型、不同路况、不同天气条件和不同遮挡情况的图像数据,以确保训练出的模型具有较强的泛化能力。
本研究的创新点在于改进的图像预处理算法、基于FPN的Faster R-CNN改进、组合剪枝算法和遮挡处理策略。这些创新点可以提高模型的检测精度、鲁棒性和实时性能,为无人驾驶道路车辆检测与分类提供有效的解决方案。
本研究的成果可以应用于无人驾驶汽车、智能交通系统、交通监控等领域,具有重要的理论意义和实际应用价值。同时,本研究也为深度学习在计算机视觉领域的应用提供了新的思路和方法。
相关文献
[1] Girshick R, Donahue J, Darrell T, et al. Rich feature hierarchies for accurate object detection and semantic segmentation[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2014: 580-587.
[2] Girshick R. Fast R-CNN[C]//Proceedings of the IEEE international conference on computer vision. 2015: 1440-1448.
[3] Ren S, He K, Girshick R, et al. Faster R-CNN: towards real-time object detection with region proposal networks[J]. Advances in neural information processing systems, 2015, 28.
[4] Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2017: 2117-2125.
[5] He K, Zhang X, Ren S, et al. Deep residual learning for image recognition[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 770-778.
[6] Liu W, Anguelov D, Erhan D, et al. SSD: single shot multibox detector[C]//European conference on computer vision. Springer, Cham, 2016: 21-37.
[7] Redmon J, Divvala S, Girshick R, et al. You only look once: unified, real-time object detection[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2016: 779-788.
[8] Han S, Pool J, Tran J, et al. Learning both weights and connections for efficient neural network[C]//Advances in neural information processing systems. 2015: 1135-1143.
[9] Li H, Kadav A, Durdanovic I, et al. Pruning filters for efficient convnets[J]. arXiv preprint arXiv:1608.08710, 2016.
[10] Molchanov P, Tyree S, Karras T, et al. Pruning convolutional neural networks for resource efficient inference[J]. arXiv preprint arXiv:1611.06440, 2016.

















 1912
1912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









