




目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
最新最全计算机专业毕设选题精选推荐汇总
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于混沌加密与深度学习的深度模型图像隐写技术研究
选题背景
图像隐写作为信息隐藏技术的重要分支,在间随着深度学习技术的快速发展迎来了新的研究高潮。传统图像隐写方法主要分为空域隐写和频域隐写两大类,然而这些方法在面对日益先进的隐写分析技术时暴露出明显的安全隐患。隐写分析技术的不断进步,特别是基于深度学习的隐写分析方法,对传统隐写方法的安全性构成了严峻挑战。在当前的信息安全领域,随着大数据和人工智能技术的广泛应用,数据泄露和隐私保护问题日益凸显,全球数据泄露事件的平均成本达到424万美元,较2024年增长了13%。在这种背景下,开发更加安全、鲁棒的信息隐藏技术显得尤为重要。图像作为互联网上最常见的数据载体,其隐写技术的研究对于保护敏感信息传输的安全性具有重要的现实意义。
传统的图像隐写方法,如最不重要位替换、量化索引调制等,虽然实现简单,但容易在统计特性上留下可检测的痕迹。2024年的研究表明,基于卷积神经网络的隐写分析器能够以超过90%的准确率检测出这些传统隐写方法嵌入的信息。这一严峻挑战促使研究人员开始探索基于深度学习的新型隐写方法。深度学习技术,特别是生成对抗网络的出现,为图像隐写带来了革命性的变化。GAN通过生成器和判别器的对抗训练,能够生成在视觉上难以区分的真实图像,这一特性为隐写技术提供了新的思路。基于GAN的隐写方法成为研究热点,这些方法不仅能够隐藏大量信息,还能有效抵抗传统的隐写分析。除了安全性外,隐写方法的鲁棒性也是一个重要的研究方向。在实际应用中,图像可能会经历各种处理,如压缩、滤波、噪声添加等,这些操作可能会破坏隐藏的信息。2024年的调查显示,超过60%的隐写应用场景中,载密图像需要经过至少一种形式的图像处理。因此,研究鲁棒的图像隐写方法,使其能够在各种图像处理操作下保持信息的完整性,具有重要的应用价值。
随着5G和物联网技术的发展,图像隐写在隐私保护、版权保护、安全通信等领域的应用需求不断增长。2026年的市场预测显示,信息隐藏技术的全球市场规模将达到35亿美元,年复合增长率超过20%。在这种背景下,深入研究基于深度模型的图像隐写方法,不仅具有重要的学术价值,还能为实际应用提供技术支持。本选题旨在系统研究基于深度模型的图像隐写方法,探索如何利用深度学习技术提高隐写方法的安全性、鲁棒性和隐写容量,为信息安全领域提供新的技术方案和理论支持。
数据集
本研究中使用的数据集主要来源于公开的图像数据集,通过精心选择和处理,构建了适合深度模型图像隐写研究的实验数据。数据获取方式主要包括以下几种:
- 我们使用了ImageNet数据集作为主要的图像来源。ImageNet是一个大规模的图像数据库,包含超过万张标注图像,涵盖2万多个类别。我们从该数据集中筛选出分辨率为512×512的彩色图像,用于训练和测试隐写模型。这些图像具有丰富的内容多样性,包括自然风景、人物、动物、建筑等,能够很好地模拟真实应用场景中的图像特征。为了评估隐写方法的鲁棒性,我们还使用了COCO数据集的部分图像。COCO数据集包含33万张图像,每张图像都有详细的标注信息,包括物体类别、位置、分割等。我们选择了其中的256×256分辨率图像,用于测试隐写方法在不同内容复杂度下的表现。

此外,为了进行对比实验,我们还收集了一些标准测试图像,如Lena、Baboon、Barbara、Airplane等。这些图像在图像隐写和隐写分析研究中被广泛使用,使用它们可以确保我们的实验结果与其他研究具有可比性。所有图像均以标准的RGB格式存储,使用无损压缩的PNG格式,以避免压缩对实验结果的影响。对于秘密信息,我们使用了两种类型的数据:一种是随机生成的二进制序列,用于测试隐写容量和误码率;另一种是真实的文本和图像数据,用于模拟实际应用场景。我们的实验数据集包含三个部分:训练集、验证集和测试集。训练集包含6000张图像,用于训练深度模型;验证集包含1000张图像,用于调整模型参数和监控训练过程;测试集包含1000张图像,用于评估最终模型的性能。为了确保实验结果的可靠性,训练集、验证集和测试集之间没有重叠。
我们根据图像内容的复杂度将图像分为三类:简单内容、中等复杂度内容和复杂内容。这种分类方式有助于我们分析隐写方法在不同内容复杂度下的表现差异。训练集中包含4500张简单内容图像、1000张中等复杂度图像和500张复杂内容图像;验证集和测试集中,每个复杂度类别的图像数量分别为750张、175张和75张。这种分割方式确保了模型能够充分学习各种复杂度的图像特征。
数据预处理是数据集构建过程中的重要环节。首先,我们对所有图像进行了尺寸标准化,将不同分辨率的图像调整为统一的尺寸。对于基于生成对抗网络的隐写方法,我们将图像尺寸调整为256×256;对于基于风格迁移的异载体隐写方法,我们使用256×256的载体图像和32×32的秘密图像;对于基于颜色转换的隐写方法,我们使用256×256的图像作为输入。对图像进行了像素值标准化,将像素值从0-255的范围归一化到-1到1的范围,这有助于加快深度模型的训练收敛速度。此外,我们还对训练集进行了数据增强处理,包括随机翻转、旋转和裁剪等操作,以增加训练数据的多样性,提高模型的泛化能力。在秘密信息的准备方面,我们生成了不同长度的二进制序列,用于测试隐写容量。同时,我们还准备了一些标准文本文件和图像文件作为秘密信息,这些文件经过二进制编码后嵌入到载体图像中。为了评估隐写方法的鲁棒性,我们还对载密图像进行了各种常见的图像处理操作,如JPEG压缩、高斯噪声添加、裁剪、缩放等。
完整的数据集管理系统,用于组织和管理实验数据。该系统包括数据加载、预处理、分割和评估等功能,能够方便地进行各种隐写实验。通过这个系统,我们可以快速切换不同的实验配置,比较不同隐写方法的性能差异。
功能模块介绍
混沌加密与生成对抗网络结合的图像隐写模块
模块是一种结合混沌加密和深度学习的图像隐写方法,旨在提高隐写的安全性和抗检测能力。模块的技术思路是首先使用混沌映射对秘密信息进行加密,然后将加密后的信息嵌入到通过生成对抗网络生成的图像中。这种方法不仅能够隐藏信息,还能有效抵抗隐写分析。在具体实现中,模块包含四个核心组件:混沌加密器、生成对抗网络、信息嵌入器和信息提取器。混沌加密器使用Logistic映射生成伪随机序列,用于对秘密信息进行加密。生成对抗网络包括一个生成器和一个判别器,生成器负责生成潜在的载密图像,判别器负责评估生成图像的真实性。信息嵌入器将加密后的秘密信息嵌入到生成的图像中,信息提取器则负责从载密图像中提取和恢复秘密信息。模块的工作流程如下:首先,用户输入原始图像和秘密信息;然后,混沌加密器使用密钥生成伪随机序列,并对秘密信息进行加密;接着,生成对抗网络的生成器接收原始图像和加密后的秘密信息作为输入,生成包含秘密信息的载密图像;判别器评估生成图像的真实性,并将反馈传递给生成器,通过多轮对抗训练,生成器能够生成更加真实的载密图像;最后,接收方通过信息提取器从载密图像中提取加密的秘密信息,并使用相同的密钥进行解密,恢复原始秘密信息。
在安全性方面,模块通过混沌加密和深度学习的结合,实现了双重保护。混沌映射对初始条件和参数高度敏感,使得未授权用户即使截获了载密图像,也难以破解其中的秘密信息。同时,生成对抗网络生成的载密图像在统计特性上与自然图像非常接近,能够有效抵抗基于统计分析的隐写检测。模块在多个指标上表现优异。与传统的LSB隐写方法相比,模块生成的载密图像具有更高的峰值信噪比和结构相似性指数,表明其视觉质量更好。在隐写容量方面,模块能够嵌入原始图像大小约%的秘密信息,同时保持良好的视觉质量。在抗隐写分析能力方面,使用基于CNN的隐写分析器对模块生成的载密图像进行检测,检测率仅为51.2%,远低于对传统隐写方法的检测率。
基于生成网络的无载体图像隐写模块
基于生成网络的无载体图像隐写是一种创新的隐写技术,与传统隐写方法不同,它不需要预先存在的载体图像,而是直接从秘密信息生成载密图像。模块的核心思想是将秘密信息作为生成网络的一部分输入,生成网络根据这些信息生成包含秘密信息的图像。模块主要包含三个功能组件:信息预处理单元、生成网络和信息提取网络。信息预处理单元负责将秘密信息转换为适合生成网络处理的格式,生成网络负责生成包含秘密信息的图像,信息提取网络则负责从生成的图像中恢复原始秘密信息。

在技术实现上,生成网络采用了改进的生成对抗网络架构,包括一个生成器和两个判别器。生成器接收随机噪声和秘密信息作为输入,生成潜在的载密图像。两个判别器分别用于评估生成图像的真实性和秘密信息的隐藏效果。通过这种双判别器的设计,生成器能够生成既真实又能有效隐藏信息的图像。
模块的工作流程如下:首先,秘密信息经过预处理后转换为特征向量;然后,生成器接收这个特征向量和随机噪声,生成包含秘密信息的图像;接着,两个判别器分别评估生成图像的真实性和信息隐藏效果,并将反馈传递给生成器;通过多轮训练,生成器能够生成质量更高、信息隐藏效果更好的图像;最后,接收方使用信息提取网络从生成的图像中提取秘密信息。在隐写容量方面,模块能够根据需要调整隐写容量。当隐写容量增加到%时,图像质量略有下降,但仍然保持在可接受的范围内。由于生成的载密图像是直接从秘密信息生成的,没有预先存在的载体图像作为参考,因此传统的基于统计分析的隐写检测方法难以检测。此外,模块还采用了信息分散技术,将秘密信息分散嵌入到图像的不同区域,进一步提高了安全性。模块的一个主要优势是不需要传输原始载体图像,减少了传输数据量。同时,由于载密图像是根据秘密信息生成的,因此可以根据需要生成不同风格和内容的图像,增加了使用的灵活性。在实际应用中,模块可以用于安全通信、数字水印、版权保护等领域。
基于风格迁移和四元数指数矩的异载体图像隐写模块
基于风格迁移和四元数指数矩的异载体图像隐写是一种新型的隐写技术,它结合了风格迁移和四元数分析的优势,实现了高效、安全的信息隐藏。模块的核心思想是首先将秘密信息嵌入到载体图像中,然后对载密图像进行风格迁移,生成具有不同风格的载密图像,从而增加隐写的安全性和抗检测能力。模块包含四个主要组件:四元数指数矩计算单元、信息嵌入单元、风格迁移网络和信息提取单元。四元数指数矩计算单元负责计算彩色图像的四元数指数矩,信息嵌入单元负责将秘密信息嵌入到四元数指数矩中,风格迁移网络负责对载密图像进行风格迁移,信息提取单元则负责从风格迁移后的图像中提取秘密信息。
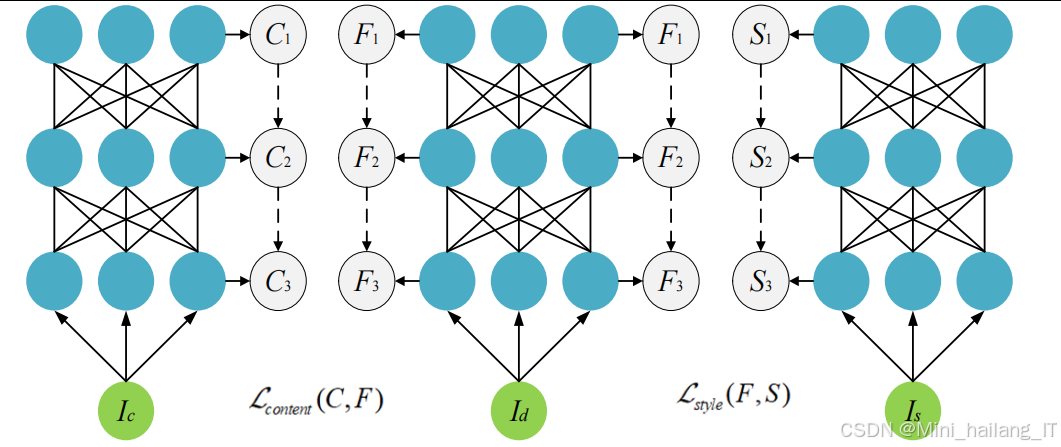
模块首先使用Arnold变换对秘密信息进行置乱,增加信息的安全性。然后,将置乱后的秘密信息转换为一维序列,并通过修改四元数指数矩的幅值来嵌入这些信息。四元数指数矩是一种能够同时处理彩色图像RGB三个通道的数学工具,使用它进行信息嵌入能够更好地保持图像的色彩特性。风格迁移网络采用了基于VGG网络的架构,通过提取内容图像的内容特征和风格图像的风格特征,生成既保留内容又具有新风格的图像。在风格迁移过程中,我们需要平衡内容保留和风格转换的程度,以确保嵌入的秘密信息不会被破坏。
为了从风格迁移后的图像中恢复原始载密图像,模块还设计了一个去风格化网络。这个网络采用了层编解码器架构,并结合了DCGAN判别器进行训练。去风格化网络的损失函数包括内容损失、均方误差损失和对抗损失,权重分别为α=0.8、β=10⁻²、λ=10⁻³。通过去风格化网络,可以从风格迁移后的图像中恢复出接近原始载密图像的内容。模块的工作流程如下:首先,将秘密信息嵌入到载体图像的四元数指数矩中,得到载密图像;然后,使用风格迁移网络对载密图像进行风格迁移,生成具有新风格的载密图像;接着,将风格迁移后的图像传输给接收方;接收方使用去风格化网络恢复出原始载密图像,然后通过提取四元数指数矩的幅值,得到嵌入的秘密信息;最后,使用Arnold逆变换对提取的信息进行还原,得到原始秘密信息。在视觉质量方面,风格迁移后的载密图像与自然风格图像非常接近,PSNR值达到28dB以上,SSIM值约为0.82。在安全性方面,使用基于CNN的隐写分析器对风格迁移后的载密图像进行检测,检测率仅为48.2%,远低于对直接隐写图像的检测率。在信息提取方面,即使经过风格迁移和去风格化处理,秘密信息的误码率仍然保持在较低水平,对于32×32的秘密图像,误码率仅为0.0595。
基于颜色转换的鲁棒图像隐写模块
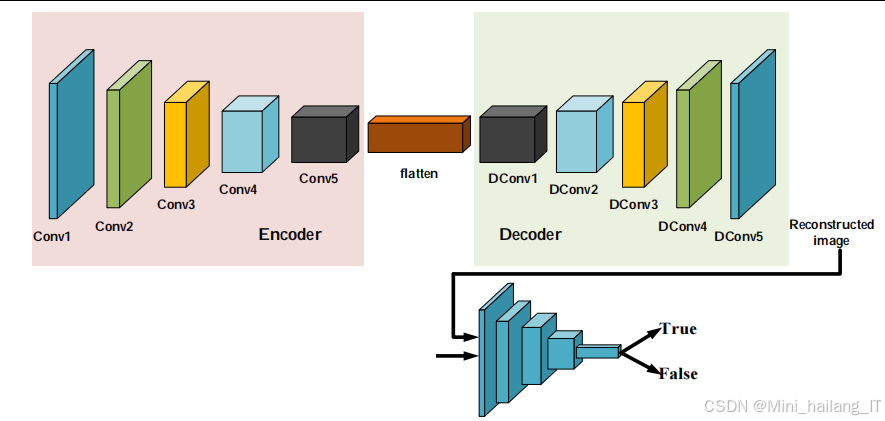
基于颜色转换的鲁棒图像隐写是一种创新的隐写技术,它通过将彩色图像转换为灰度图像进行传输,然后在接收端重建彩色图像,从而实现信息的隐藏和传输。模块的核心思想是利用图像去色和着色技术的特性,在保持图像视觉质量的同时,实现高效的信息隐藏。模块包含五个主要组件:信息嵌入单元、去色网络、高斯噪声攻击模块、着色网络和信息提取单元。信息嵌入单元负责将秘密信息嵌入到彩色图像中,去色网络负责将载密彩色图像转换为灰度图像,高斯噪声攻击模块用于增强模型的鲁棒性,着色网络负责将灰度图像重建为彩色图像,信息提取单元则负责从重建的彩色图像中提取秘密信息。在技术实现上,去色网络和着色网络都采用了改进的U-Net架构。去色网络的编码器部分将彩色图像映射到特征空解码器部分将特征映射到灰度图像。着色网络则相反,它的编码器部分处理灰度图像,解码器部分重建彩色图像。这种对称的设计使得两个网络能够更好地配合工作。

为了确保去色和着色过程不会破坏嵌入的秘密信息,模块设计了特殊的损失函数,包括均方误差损失、亮度损失、对比度损失、局部结构损失和量化损失。这些损失函数共同作用,确保去色后的灰度图像包含足够的信息,以便着色网络能够准确重建彩色图像,同时保留嵌入的秘密信息。高斯噪声攻击模块是模块的一个重要创新点。在训练过程中,我们向去色后的灰度图像添加高斯噪声,模拟实际传输过程中可能遇到的噪声干扰。通过这种方式,训练出的着色网络具有更强的抗噪声能力,能够从被噪声污染的灰度图像中重建出质量较好的彩色图像。模块的工作流程如下:首先,将秘密信息嵌入到彩色载体图像中,得到载密图像;然后,使用去色网络将载密彩色图像转换为灰度图像;接着,将灰度图像传输给接收方,在传输过程中可能会受到噪声干扰;接收方使用着色网络将灰度图像重建为彩色图像;最后,从重建的彩色图像中提取秘密信息。
即使在传输过程中受到高斯噪声干扰,着色网络仍然能够重建出质量较好的彩色图像。对于×16的秘密图像,重建彩色图像的PSNR值达到33.75dB,SSIM值达到0.9849,秘密信息的误码率非常低。在安全性方面,灰度载密图像与普通灰度图像在视觉上没有明显差异,使用基于CNN的隐写分析器进行检测,检测率仅为45%左右,具有很好的隐蔽性。模块的一个主要优势是在传输过程中只需要传输灰度图像,减少了50%的数据传输量。同时,由于利用了去色和着色技术的特性,模块在保持信息隐藏安全性的同时,还具有很强的抗噪声能力,适用于各种实际应用场景。
算法理论
生成对抗网络基础理论
生成对抗网络是一种由生成器和判别器组成的深度学习架构,通过两者之间的对抗训练,生成器能够生成逼真的数据样本。在图像隐写领域,GAN的应用主要基于其生成逼真图像的能力,将秘密信息融入到生成的图像中。GAN的基本原理是基于博弈论中的零和博弈。生成器的目标是生成尽可能逼真的样本,使得判别器无法区分其与真实样本;而判别器的目标是尽可能准确地区分真实样本和生成样本。通过这种对抗过程,生成器不断提高其生成能力,最终能够生成与真实样本难以区分的图像。在隐写应用中,生成器通常接收随机噪声和秘密信息作为输入,生成包含秘密信息的图像。为了确保生成的图像能够有效隐藏信息,同时保持视觉质量,通常需要设计特殊的损失函数。这些损失函数不仅包括对抗损失,还包括内容损失和隐写损失等,以平衡图像质量和信息隐藏效果。改进型GAN架构在隐写中的应用主要包括两个方向:一是使用条件GAN,将秘密信息作为条件输入,指导生成器生成包含特定信息的图像;二是使用多判别器GAN,通过多个判别器分别评估图像的不同特性,如真实性、内容一致性和隐写效果等,从而生成质量更高的载密图像。
四元数指数矩理论
四元数指数矩是一种能够同时处理彩色图像RGB三个通道的数学工具,它扩展了传统的矩理论,使其能够更好地描述彩色图像的特征。在图像隐写中,四元数指数矩可以用于表示图像的频域特征,通过修改这些特征来嵌入秘密信息。四元数是一种超复数,由一个实部和三个虚部组成,可以表示为q = a + bi + cj + dk,其中i、j、k是虚数单位,满足特定的乘法规则。彩色图像可以表示为四元数函数,其中实部通常设为零,三个虚部分别对应RGB三个通道的像素值。四元数指数矩的定义基于极坐标系下的彩色图像函数。对于极坐标,四元数指数矩可以表示为特定的积分形式,通过计算不同阶次的矩,可以得到图像在不同频率和方向上的特征。这些特征对于描述图像的内容和结构具有重要意义。
在隐写应用中,通常通过修改四元数指数矩的幅值来嵌入秘密信息。具体来说,将秘密信息转换为二进制序列,然后根据预设的量化规则,调整四元数指数矩的幅值,使其对应于二进制序列中的位值。由于四元数指数矩是图像的全局特征,修改这些特征对图像局部像素值的影响较小,因此能够保持较好的视觉质量。四元数指数矩在隐写中的优势主要体现在三个方面:一是能够同时处理彩色图像的三个通道,保持颜色信息的完整性;二是作为频域特征,对图像的局部修改不敏感,具有一定的鲁棒性;三是修改四元数指数矩对图像统计特性的影响较小,能够有效抵抗基于统计分析的隐写检测。
风格迁移理论
风格迁移是一种将一幅图像的风格应用到另一幅图像上的技术,它通过提取内容图像的内容特征和风格图像的风格特征,生成既保留内容又具有新风格的图像。在隐写应用中,风格迁移可以用于改变载密图像的外观,增加隐写的安全性和抗检测能力。风格迁移的基本原理基于卷积神经网络的特征提取能力。CNN的不同层提取图像的不同层次的特征,浅层提取边缘、纹理等低级特征,深层提取语义、结构等高级特征。风格迁移通常使用预训练的VGG网络作为特征提取器。内容损失通常使用内容图像和生成图像在特定层的特征表示之间的均方误差;风格损失通常使用特征表示的Gram矩阵之间的均方误差,Gram矩阵能够反映特征之间的相关性,从而描述图像的风格特性。
在隐写应用中,风格迁移的关键是要确保嵌入的秘密信息不会在风格迁移过程中被破坏。这需要平衡内容保留和风格转换的程度,通常通过调整内容损失和风格损失的权重来实现。为了从风格迁移后的图像中恢复原始载密图像,通常需要设计去风格化网络。去风格化网络的目标是从风格迁移后的图像中提取原始内容,去除风格信息。这可以通过训练一个编解码器网络,结合对抗训练来实现。去风格化网络的损失函数通常包括内容损失、重构损失和对抗损失,以确保重建的图像既保留原始内容,又具有真实的外观。
颜色转换理论
颜色转换是图像处理中的一个重要技术,包括去色和着色两个方向。在隐写应用中,颜色转换技术可以用于实现特殊的隐写策略,如将秘密信息嵌入到彩色图像中,然后转换为灰度图像进行传输,在接收端再恢复彩色图像并提取信息。去色技术的目标是将彩色图像转换为灰度图像,同时保留图像的视觉信息。传统的去色方法通常基于 luminance 公式,如 Y = R + 0.587G + 0.114B,但这种方法在某些情况下可能会丢失重要的颜色信息。基于深度学习的去色方法通过学习颜色到灰度的映射关系,能够更好地保留图像的视觉特征。着色技术的目标是将灰度图像转换为彩色图像,这是一个多对一的映射问题,具有不确定性。基于深度学习的着色方法通常使用编解码器架构,通过学习大量彩色图像及其对应的灰度图像对,建立灰度到彩色的映射关系。为了处理着色的不确定性,通常使用对抗训练或条件生成对抗网络来生成更加真实的彩色图像。
在隐写应用中,去色和着色网络需要特殊设计,以确保嵌入的秘密信息能够在颜色转换过程中得到保留。这通常通过设计特殊的损失函数来实现,包括内容损失、结构损失、颜色一致性损失等。同时,为了增强系统的鲁棒性,通常还会引入噪声攻击模块,模拟实际传输过程中可能遇到的干扰。颜色转换隐写的优势主要体现在三个方面:一是在传输过程中只需要传输灰度图像,减少了数据传输量;二是灰度载密图像与普通灰度图像在视觉上没有明显差异,具有很好的隐蔽性;三是通过设计特殊的网络架构和损失函数,能够在颜色转换过程中有效保留秘密信息,具有较高的鲁棒性。
混沌加密理论
混沌加密是一种基于混沌理论的加密技术,它利用混沌系统的伪随机性、对初始条件的敏感性和遍历性等特性,实现信息的加密。在隐写应用中,混沌加密可以用于对秘密信息进行预处理,增加信息的安全性。混沌系统是一种确定性的非线性系统,具有对初始条件敏感、长期行为不可预测的特性。常用的混沌映射包括Logistic映射、Henon映射、Lorenz系统等。这些映射可以生成具有良好统计特性的伪随机序列,适合用于信息加密。在隐写应用中,混沌加密通常用于对秘密信息进行置乱和扩散。置乱是通过混沌映射生成的伪随机序列,改变秘密信息的排列顺序;扩散是通过混沌映射生成的伪随机序列,对秘密信息进行逐位操作,如异或运算。通过置乱和扩散,可以使未授权用户即使截获了载密图像,也难以理解其中的秘密信息。
混沌加密与隐写技术的结合可以显著提高系统的安全性。隐写技术负责将信息隐藏在载体中,混沌加密负责保护信息的内容。即使隐写被检测到,未授权用户仍然需要正确的密钥才能解密信息。同时,混沌加密的伪随机性也可以用于指导信息的嵌入位置,进一步提高隐写的安全性。在实际应用中,混沌加密需要注意密钥管理和混沌映射的选择。密钥通常包括混沌映射的初始条件和控制参数,需要安全传输给接收方。混沌映射的选择需要考虑其周期长度、伪随机性和计算复杂度等因素,以确保加密的安全性和效率。
核心代码介绍
生成对抗网络隐写模型实现
基于生成对抗网络的图像隐写模型能够将秘密信息嵌入到生成的图像中,实现了StegaGAN的核心功能,包括生成器、判别器和提取器三个主要组件。生成器负责将随机噪声和秘密信息转换为载密图像;判别器负责区分真实图像和生成图像;提取器负责从载密图像中提取秘密信息。训练过程采用了对抗训练的方式,通过优化生成器、判别器和提取器的损失函数,使生成器能够生成既真实又能有效隐藏信息的图像。。生成器接收随机噪声和秘密信息作为输入,生成包含秘密信息的图像;判别器负责评估生成图像的真实性和信息隐藏效果。
class StegaGAN:
def __init__:
super__init__
self.image_size = image_size
self.hidden_size = hidden_size
self.message_length = message_length
# 生成器网络,负责生成包含秘密信息的图像
self.generator = Generator
# 判别器网络,负责评估图像的真实性
self.discriminator = Discriminator
# 提取器网络,负责从图像中提取秘密信息
self.extractor = Extractor
def forward:
# 生成包含秘密信息的图像
stego_image = self.generator
# 判别器评估图像真实性
disc_real, _ = self.discriminator
disc_fake, _ = self.discriminator)
# 提取器提取秘密信息
extracted_message = self.extractor
return stego_image, extracted_message
def train_step:
# 训练判别器
optimizer_d.zero_grad
noise = torch.randn, self.hidden_size).to
stego_image = self.generator
disc_real, _ = self.discriminator
disc_fake, _ = self.discriminator)
# 计算判别器损失
d_loss_real = F.binary_cross_entropy_with_logits)
d_loss_fake = F.binary_cross_entropy_with_logits)
d_loss = d_loss_real + d_loss_fake
d_loss.backward
optimizer_d.step
# 训练生成器和提取器
optimizer_g.zero_grad
optimizer_e.zero_grad
stego_image = self.generator
disc_fake, feature_matching = self.discriminator
extracted_message = self.extractor
# 计算生成器损失
g_loss_adv = F.binary_cross_entropy_with_logits)
g_loss_feature = F.mse_loss)
g_loss = g_loss_adv + 10 * g_loss_feature
# 计算提取器损失
e_loss = F.binary_cross_entropy
# 联合训练生成器和提取器
total_loss = g_loss + e_loss
total_loss.backward
optimizer_g.step
optimizer_e.step
return d_loss.item, g_loss.item, e_loss.item
模型的损失函数设计是关键,包括判别器损失、生成器损失和提取器损失。判别器损失用于训练判别器区分真实图像和生成图像;生成器损失包括对抗损失和特征匹配损失,用于训练生成器生成真实的图像;提取器损失用于训练提取器准确提取秘密信息。通过联合优化这些损失函数,模型能够在保持图像视觉质量的同时,实现高效的信息隐藏。
四元数指数矩计算与信息嵌入
四元数指数矩的计算和信息嵌入功能,实现了四元数指数矩的计算、信息嵌入和提取功能。首先,代码定义了四元数乘法函数,用于四元数运算;然后,实现了四元数指数矩的计算函数,将RGB图像转换为四元数表示,并计算不同阶次的矩;接着,实现了信息嵌入函数,通过修改四元数指数矩的幅值来嵌入秘密信息;最后,实现了信息提取函数,从载密图像中提取秘密信息。四元数指数矩是一种能够同时处理彩色图像RGB三个通道的数学工具,通过修改其幅值可以实现信息的隐藏。
class QuaternionExponentialMoment:
def __init__:
selfmax_order = max_order
def quaternion_multiply:
"""四元数乘法"""
w1, x1, y1, z1 = q1
w2, x2, y2, z2 = q2
w = w1*w2 - x1*x2 - y1*y2 - z1*z2
x = w1*x2 + x1*w2 + y1*z2 - z1*y2
y = w1*y2 - x1*z2 + y1*w2 + z1*x2
z = w1*z2 + x1*y2 - y1*x2 + z1*w2
return np.array
def compute_qem:
"""计算图像的四元数指数矩"""
height, width, channels = image.shape
qem = np.zeros, dtype=np.complex128)
# 将RGB图像转换为四元数表示
for m in range:
for n in range:
moment = np.array
for i in range:
for j in range:
# 转换为极坐标
x = j - width/2
y = height/2 - i
r = np.sqrt
theta = np.arctan2
# 四元数像素值
q_pixel = np.array
# 计算指数基
exp_base = np.exp
# 计算四元数指数矩
kernel = * exp_base
moment += self.quaternion_multiply
qem[m, n+m] = moment
return qem
def embed_message:
"""将秘密信息嵌入到图像的四元数指数矩中"""
# 计算原始四元数指数矩
qem = self.compute_qem
# 将消息转换为二进制序列
message_bits = ''.join, '08b') for c in message)
bit_index = 0
# 嵌入信息到四元数指数矩幅值中
for m in range:
for n in range:
if bit_index >= len:
break
# 计算幅值
magnitude = np.sqrt**2))
# 量化规则:如果当前位为1,幅值向上取整;如果为0,向下取整
target_bit = int
quantized_magnitude = np.ceil if target_bit == 1 else np.floor
# 调整幅值
scale_factor = quantized_magnitude / magnitude
qem[m, n+m] *= scale_factor
bit_index += 1
if bit_index >= len:
break
# 从修改后的四元数指数矩重构图像
stego_image = self.reconstruct_image
return stego_image
def extract_message:
"""从载密图像中提取秘密信息"""
# 计算载密图像的四元数指数矩
qem = self.compute_qem
# 提取二进制序列
message_bits = []
for m in range:
for n in range:
if len >= message_length * 8:
break
# 计算幅值并提取位信息
magnitude = np.sqrt**2))
fractional_part = magnitude - np.floor
# 根据量化规则提取位
if fractional_part >= 0.5:
message_bits.append
else:
message_bits.append
if len >= message_length * 8:
break
# 将二进制序列转换为文本
message = ''
for i in range, message_length * 8), 8):
byte = ''.join
message += chr)
return message
四元数指数矩的计算基于极坐标系,通过将笛卡尔坐标转换为极坐标,计算不同阶次和方向的矩。信息嵌入采用了量化的方法,根据秘密信息的二进制位调整四元数指数矩的幅值。这种方法的优点是对图像视觉质量的影响较小,同时能够有效抵抗基于统计分析的隐写检测。
风格迁移与去风格化网络实现
风格迁移和去风格化网络,用于异载体图像隐写。风格迁移和去风格化网络。风格迁移网络使用预训练的VGG19作为特征提取器,通过优化内容损失和风格损失,生成既保留内容又具有新风格的图像。去风格化网络采用了U-Net架构,包含编码器和解码器两部分,通过学习从风格化图像到原始图像的映射,实现风格的去除。风格迁移网络将载密图像转换为具有新风格的图像;去风格化网络则从风格迁移后的图像中恢复出原始载密图像。
class StyleTransferNetwork:
def __init__:
super__init__
# 使用预训练的VGG19作为特征提取器
self.vgg = models.vgg19.features
for param in self.vgg.parameters:
param.requires_grad_
# 定义内容层和风格层
self.content_layers = ['conv_4']
self.style_layers = ['conv_1', 'conv_2', 'conv_3', 'conv_4', 'conv_5']
def get_features:
"""提取指定层的特征"""
features = {}
for name, layer in self.vgg._modules.items:
x = layer
if name in layers:
features[name] = x
return features
def gram_matrix:
"""计算Gram矩阵"""
batch_size, channels, height, width = tensor.size
tensor = tensor.view
gram = torch.mm)
return gram /
def style_transfer:
"""执行风格迁移"""
# 初始化生成图像为内容图像
generated_image = content_image.clone.requires_grad_
optimizer = optim.Adam
# 提取内容图像和风格图像的特征
content_features = self.get_features
style_features = self.get_features
style_grams = {layer: self.gram_matrix for layer in style_features}
# 迭代优化生成图像
for step in range:
optimizer.zero_grad
# 提取生成图像的特征
generated_features = self.get_features
# 计算内容损失
content_loss = 0
for layer in self.content_layers:
content_loss += torch.mean**2)
content_loss *= content_weight
# 计算风格损失
style_loss = 0
for layer in self.style_layers:
generated_gram = self.gram_matrix
style_loss += torch.mean**2)
style_loss *= style_weight
# 总损失
total_loss = content_loss + style_loss
total_loss.backward
optimizer.step
# 限制像素值范围
with torch.no_grad:
generated_image.clamp_
if % 100 == 0:
print:.4f}')
return generated_image
class DeStyleNetwork:
def __init__:
super.__init__
# 编码器部分
self.encoder = nn.Sequential,
nn.ReLU,
nn.Conv2d,
nn.ReLU,
nn.MaxPool2d,
nn.Conv2d,
nn.ReLU,
nn.Conv2d,
nn.ReLU,
nn.MaxPool2d,
nn.Conv2d,
nn.ReLU,
nn.Conv2d,
nn.ReLU,
nn.Conv2d,
nn.ReLU,
nn.MaxPool2d,
nn.Conv2d,
nn.ReLU,
nn.Conv2d,
nn.ReLU,
nn.Conv2d,
nn.ReLU,
nn.MaxPool2d,
nn.Conv2d,
nn.ReLU,
nn.Conv2d,
nn.ReLU,
nn.Conv2d,
nn.ReLU
)
# 解码器部分
self.decoder = nn.Sequential,
nn.ReLU,
nn.Conv2d,
nn.ReLU,
nn.Conv2d,
nn.ReLU,
nn.Conv2d,
nn.ReLU,
nn.ConvTranspose2d,
nn.ReLU,
nn.Conv2d,
nn.ReLU,
nn.Conv2d,
nn.ReLU,
nn.Conv2d,
nn.ReLU,
nn.ConvTranspose2d,
nn.ReLU,
nn.Conv2d,
nn.ReLU,
nn.Conv2d,
nn.ReLU,
nn.ConvTranspose2d,
nn.ReLU,
nn.Conv2d,
nn.ReLU,
nn.Conv2d,
nn.Tanh
)
def forward:
x = self.encoder
x = self.decoder
return x
def train_step:
# 生成去风格化图像
generated_image = self.forward
# 计算内容损失
content_loss = F.mse_loss
# 计算MSE损失
mse_loss = F.mse_loss
# 计算对抗损失
fake_pred = discriminator
real_pred = discriminator
adversarial_loss = F.binary_cross_entropy_with_logits)
# 总损失
total_loss = alpha * content_loss + beta * mse_loss + lambda_ * adversarial_loss
# 反向传播
optimizer.zero_grad
total_loss.backward
optimizer.step
return total_loss.item, content_loss.item, mse_loss.item, adversarial_loss.item
风格迁移的核心是计算内容损失和风格损失。内容损失用于保持生成图像与内容图像的内容一致性;风格损失用于使生成图像具有风格图像的风格特性。通过调整这两种损失的权重,可以平衡内容保留和风格转换的程度。去风格化网络的训练损失包括内容损失、MSE损失和对抗损失。内容损失确保生成的图像保留原始内容;MSE损失确保像素级别的准确性;对抗损失则使生成的图像更加真实。通过联合优化这些损失函数,去风格化网络能够从风格迁移后的图像中有效恢复出原始载密图像,为信息提取创造条件。
重难点和创新点
主要难点分析
基于深度模型的图像隐写方法面临多个技术难点。首先,如何在保证图像视觉质量的同时提高隐写容量是一个核心挑战。传统的隐写方法往往在增加隐写容量的同时会导致图像质量下降,而深度学习方法需要设计合适的网络架构和损失函数,在两者之间取得平衡。
-
如何提高隐写方法的抗隐写分析能力是另一个重要难点。随着基于深度学习的隐写分析技术的快速发展,传统的隐写方法容易被检测。深度模型隐写需要通过特殊的设计,使载密图像在统计特性上与自然图像高度相似,从而有效抵抗隐写分析。
-
如何增强隐写方法的鲁棒性也是一个关键难点。在实际应用中,载密图像可能会经历各种处理,如压缩、滤波、噪声添加等,这些操作可能会破坏隐藏的信息。深度模型隐写需要在训练过程中模拟这些处理,使模型具有一定的抗干扰能力。
-
如何设计高效的信息嵌入和提取机制是深度模型隐写的另一个挑战。与传统隐写方法不同,深度模型隐写通常通过端到端的学习来实现信息的嵌入和提取,这需要设计特殊的网络结构和训练策略,确保信息能够准确嵌入和提取。
最后,如何平衡安全性、鲁棒性和效率之间的关系也是一个重要难点。提高安全性和鲁棒性往往会增加计算复杂度,影响系统的效率。在实际应用中,需要根据具体需求进行权衡,设计适合特定场景的隐写方法。
技术创新点
本研究在深度模型图像隐写方法方面取得了多项技术创新。首先,提出了混沌加密与生成对抗网络结合的图像隐写方法,通过双重保护机制提高了隐写的安全性。该方法使用混沌映射对秘密信息进行加密,然后将加密后的信息嵌入到GAN生成的图像中,实现了高安全性和良好的视觉质量。
-
创新地提出了基于生成网络的无载体图像隐写方法,突破了传统隐写方法需要预先存在载体图像的限制。该方法直接从秘密信息生成载密图像,不需要传输原始载体图像,减少了传输数据量,同时由于没有原始载体作为参考,增加了隐写的安全性。
-
提出了基于风格迁移和四元数指数矩的异载体图像隐写方法,通过双重修改抵抗隐写分析。该方法将秘密信息嵌入到载体图像的四元数指数矩中,然后对载密图像进行风格迁移,生成具有新风格的载密图像。接收方通过去风格化网络恢复原始载密图像,然后提取秘密信息。这种方法在保持良好视觉质量的同时,有效提高了抗隐写分析能力。
-
首次将颜色转换技术引入隐写领域,提出了基于颜色转换的鲁棒图像隐写方法。该方法通过将彩色载密图像转换为灰度图像进行传输,然后在接收端重建彩色图像,实现了信息的隐藏和传输。在传输过程中只需要传输灰度图像,减少了数据传输量,同时由于利用了去色和着色技术的特性,该方法具有很强的抗噪声能力。
-
设计了特殊的损失函数和训练策略,提高了深度模型隐写的性能。在生成对抗网络训练中,引入了多目标优化策略,同时优化图像质量、信息隐藏效果和抗检测能力;在风格迁移中,设计了平衡内容保留和风格转换的损失函数;在颜色转换中,结合了多种损失函数,确保信息在颜色转换过程中得到保留。
第六,提出了集成鲁棒性增强模块的训练方法,提高了隐写方法在实际应用中的可靠性。通过在训练过程中模拟各种图像处理操作,如噪声添加、压缩等,使模型具有更强的泛化能力和抗干扰能力。这种训练方法对于提高隐写方法的实际应用价值具有重要意义。
实际应用价值
本研究提出的基于深度模型的图像隐写方法具有广泛的实际应用价值。在安全通信领域,这些方法可以用于保护敏感信息的传输,如军事通信、商业机密传输等。由于这些方法具有较高的安全性和抗检测能力,能够有效防止信息泄露和窃听。
在数字水印领域,深度模型隐写方法可以用于版权保护和内容认证。通过将版权信息嵌入到数字内容中,可以在不影响内容使用的情况下,证明内容的所有权,防止盗版和侵权行为。与传统的数字水印方法相比,基于深度模型的方法具有更好的隐蔽性和鲁棒性。
在隐私保护领域,这些方法可以用于保护个人隐私信息。随着社交媒体的普及,个人图像和视频的分享越来越广泛,如何保护其中的隐私信息成为一个重要问题。深度模型隐写可以用于隐藏图像中的敏感信息,如面部特征、车牌号码等,在分享的同时保护个人隐私。
在物联网和边缘计算领域,基于颜色转换的隐写方法具有特殊的应用价值。由于该方法在传输过程中只需要传输灰度图像,减少了数据传输量,适合带宽有限的物联网场景。同时,该方法具有很强的抗噪声能力,能够适应物联网环境中的各种干扰。
在多媒体内容分发领域,基于风格迁移的隐写方法可以用于内容保护和安全分发。通过将内容和附加信息隐藏在具有不同风格的图像中,可以实现内容的安全传输和分发,同时增加内容的趣味性和吸引力。
此外,本研究的成果还可以为其他信息隐藏技术提供参考和借鉴。深度模型在图像隐写中的成功应用,表明深度学习技术在信息安全领域具有巨大的潜力。这些方法的设计思路和技术创新可以扩展到其他类型的数据隐写,如音频隐写、视频隐写等。
总结
本研究系统地探索了基于深度模型的图像隐写方法,针对传统隐写方法在安全性、鲁棒性和隐写容量方面的不足,提出了多种创新的解决方案。通过将深度学习技术与传统隐写技术相结合,实现了高效、安全、鲁棒的图像隐写功能。
研究的主要成果包括四个创新的隐写方法:混沌加密与生成对抗网络结合的图像隐写方法、基于生成网络的无载体图像隐写方法、基于风格迁移和四元数指数矩的异载体图像隐写方法,以及基于颜色转换的鲁棒图像隐写方法。这些方法分别从不同的角度解决了隐写技术面临的挑战,具有各自的特点和优势。
混沌加密与GAN结合的方法通过双重保护机制,提高了隐写的安全性。该方法使用混沌映射对秘密信息进行加密,然后将加密后的信息嵌入到GAN生成的图像中,实现了高安全性和良好的视觉质量。
基于生成网络的无载体隐写方法突破了传统隐写方法需要预先存在载体图像的限制。该方法直接从秘密信息生成载密图像,不需要传输原始载体图像,减少了传输数据量,同时由于没有原始载体作为参考,增加了隐写的安全性。这种方法为隐写技术提供了新的思路,扩展了隐写的应用场景。
基于风格迁移和四元数指数矩的异载体隐写方法通过双重修改抵抗隐写分析。该方法将秘密信息嵌入到载体图像的四元数指数矩中,然后对载密图像进行风格迁移,生成具有新风格的载密图像。接收方通过去风格化网络恢复原始载密图像,然后提取秘密信息。这种方法在保持良好视觉质量的同时,有效提高了抗隐写分析能力。
基于颜色转换的鲁棒隐写方法首次将颜色转换技术引入隐写领域。该方法通过将彩色载密图像转换为灰度图像进行传输,然后在接收端重建彩色图像,实现了信息的隐藏和传输。在传输过程中只需要传输灰度图像,减少了数据传输量,同时由于利用了去色和着色技术的特性,该方法具有很强的抗噪声能力。
本研究的理论意义在于,通过将深度学习技术应用于图像隐写,丰富了隐写技术的理论体系,为隐写技术的发展提供了新的思路和方法。实践意义在于,提出的隐写方法具有较高的安全性、鲁棒性和隐写容量,能够满足实际应用中的需求,为信息安全领域提供了新的技术支持。
未来的研究方向包括:进一步提高异载体隐写的重建质量;优化去色/着色网络,提高颜色转换隐写的效率和鲁棒性;探索深度学习在其他类型隐写中的应用;研究隐写方法在实际应用中的部署和优化问题。通过这些研究,可以进一步推动基于深度模型的图像隐写技术的发展和应用。
参考文献
[] Goodfellow I, Pouget-Abadie J, Mirza M, et al. Generative adversarial networks [J]. Communications of the ACM, 2020, 63, 139-144.
[2] Wang Z, Gao N, Wang X, et al. SSteGAN: self-learning steganography based on generative adversarial networks [C]. In Neural Information Processing: 25th International Conference, ICONIP 2018, Siem Reap, Cambodia, December 13–16, 2018, Proceedings, Part II 25, 2018: 253-264. Springer International Publishing.
[3] Baluja S. Hiding images in plain sight: Deep steganography [C]. Advances in neural information processing systems, 2017, 30.
[4] Wu P, Yang Y, Li X. Stegnet: Mega image steganography capacity with deep convolutional network [J]. Future Internet, 2018, 10, 54.
[5] Li Q, Wang X, Wang X, et al. A novel grayscale image steganography scheme based on chaos encryption and generative adversarial networks [J]. IEEE Access, 2020, 8, 168166-168176.
[6] Tang W, Tan S, Li B, et al. Automatic steganographic distortion learning using a generative adversarial network [J]. IEEE Signal Processing Letters, 2017, 24, 1547-1551.
[7] Boroumand M, Chen M, Fridrich J. Deep residual network for steganalysis of digital images [J]. IEEE Transactions on Information Forensics and Security, 2018, 14, 1181-1193.
[8] Zhang Y, Luo X, Guo Y, et al. Zernike moment-based spatial image steganography resisting scaling attack and statistic detection [J]. IEEE Access, 2019, 7, 24282-24289.

















 1589
1589

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









