




目录
1. 选题意义背景
随着建筑业的快速发展,我国建筑施工领域安全事故仍时有发生,其中因施工人员不安全行为导致的事故占比高达70%以上。传统的安全监管主要依靠人工巡检,存在效率低下、覆盖面有限、易受主观因素影响等问题。如何实现高效、准确的施工人员不安全行为自动识别,成为建筑安全领域亟待解决的重要课题。
随着计算机视觉技术和深度学习的快速发展,基于视频分析的人体行为识别技术取得了突破性进展。双流卷积神经网络因其能够有效捕捉视频中的空间和时间信息,成为人体行为识别的主流方法之一。通过将深度学习模型部署到边缘设备,可以实现数据的本地化处理,减少传输延迟,提高实时性。但边缘设备通常具有计算资源有限、内存容量小、功耗约束高等特点,这对模型的轻量化提出了严格要求。

在此背景下,研究基于改进双流CNN的施工人员不安全行为识别方法具有重要的理论意义和实际应用价值对当前建筑施工安全监管的实际需求,结合深度学习和边缘计算技术,提出了一种高效、轻量化的施工人员不安全行为识别方法,具有重要的理论研究意义和广阔的应用前景。
2. 数据集
2.1 数据来源与获取方式
本研究使用的数据集主要包括两部分:公共行为识别数据集和自建建筑工地施工人员行为数据集。
公共行为识别数据集:
-
UCF-101数据集:该数据集是行为识别领域广泛使用的公开数据集,视频主要来源于YouTube平台。数据集包含101种行为类别,共计13320条视频片段。每个类别由25个人分别执行,每人执行4至7组动作。视频分辨率为320×240,时长5-10秒左右。该数据集通过UCF官方网站免费获取,为研究提供了丰富的基础行为数据。

-
HMDB-51数据集:由布朗大学于2011年发布,视频来源于电影片段和YouTube平台。包含51种行为类别,每个类别至少101个视频片段,总计6849条视频片段。视频分辨率为320×240,帧率为30fps。该数据集通过HMDB官方网站获取,为模型预训练提供了补充数据。

自建建筑工地施工人员行为数据集:
为了更好地适应建筑工地实际场景,本研究构建了自建数据集。数据采集于某建筑工地,由课题组实拍完成。采集过程中,使用高清摄像头记录施工人员的日常工作行为,包括正常行为和不安全行为。拍摄时确保相机位置固定,以减少视角变化对后续光流提取的影响。采集环境为正常施工环境,人员佩戴安全帽,身穿反光背心,以符合实际工地安全要求。

2.2 数据格式与数据规模
数据格式:
- 视频格式:MP4
- 视频分辨率:公共数据集为320×240,自建数据集为856×480
- 视频帧率:公共数据集为24fps或30fps,自建数据集为30fps
- 视频时长:公共数据集为1-10秒,自建数据集为5-10秒
2.3 类别定义
行为类别的精确定义是构建高质量数据集的关键。本研究对14种行为类别进行了详细定义:
-
正常行走:施工人员以正常步速在工地内移动,无奔跑、跳跃等危险动作。
-
搬运物品:施工人员双手或单手持物或肩扛物品,保持稳定姿态移动。
-
使用推车:施工人员操作手推车运输材料或工具,速度适中,方向可控。
-
驾驶车辆:施工人员在工地内操作工程车辆,严格遵循安全操作规程。
-
搭建脚手架:施工人员按照标准流程搭建脚手架,佩戴安全带等防护装备。
-
清理工地:施工人员使用工具清理工地杂物、垃圾,保持工作环境整洁。
-
施工作业:施工人员进行正常的砌筑、粉刷、安装等专业操作,符合安全规范。
-
攀爬高处:施工人员未经许可攀爬脚手架、围墙等高处设施,未采取安全防护措施。
-
翻越围栏:施工人员翻越工地围栏或防护栏,存在跌落风险。
-
快速奔跑:施工人员在工地内奔跑,可能导致碰撞或跌倒。
-
抛掷物品:施工人员向空中或远处抛掷工具、材料等物品,存在砸伤风险。
-
打闹推搡:施工人员在工地内互相追逐、推搡、嬉戏,分散注意力。
-
意外摔倒:施工人员因地面湿滑、障碍物等原因意外跌倒,需要紧急救援。
-
使用手机:施工人员在操作设备或进行危险作业时使用手机,分散注意力。
2.4 数据分割策略
为了保证模型训练的有效性和评估的公正性,本研究采用以下数据分割策略:
-
预训练阶段:使用UCF-101数据集进行模型预训练。按照数据集官方提供的分割方法,将数据集分为训练集(9537条)、验证集(1332条)和测试集(2451条)。
-
微调阶段:使用自建建筑工地数据集对预训练模型进行微调。将自建数据集按照7:2:1的比例随机分割,其中:
- 训练集:655条视频片段,用于模型参数更新
- 验证集:187条视频片段,用于调整超参数和监控训练过程
- 测试集:93条视频片段,用于评估模型最终性能
-
交叉验证:为了减少数据分割带来的偶然性,采用5折交叉验证方法。将数据集分成5个相等的子集,每次使用4个子集作为训练集,1个子集作为测试集,重复5次,取平均性能作为最终结果。
2.5 数据预处理
数据预处理是提高模型性能的关键步骤。本研究采用以下预处理方法:
-
视频解码与帧提取:使用OpenCV库对视频进行解码,提取连续的视频帧序列。对于高清视频,先进行降采样处理,统一调整为640×360分辨率,以平衡计算效率和图像质量。
-
关键帧采样:采用基于帧间差分法的关键帧采样策略,减少冗余帧的数量。具体步骤包括:
- 对相邻视频帧进行灰度化处理
- 计算帧间像素灰度值差值的绝对值
- 设置差分阈值,进行二值化处理
- 对二值化结果进行平滑和标准化
- 提取差分值较大的帧作为关键帧

-
二次去重:对提取的关键帧进行相似度计算,剔除过于相似的相邻帧。当两帧位置编号小于3且相似度较高时,认为存在冗余,保留其中一帧。
-
光流提取:使用TV-L1稠密光流算法提取视频帧的运动信息。对于每个关键帧,计算其与前一帧之间的光流场,得到水平和垂直方向的光流图像。光流图像能够有效表征视频中的运动信息,为时间流网络提供输入。
-
数据增强:为了提高模型的鲁棒性和泛化能力,对训练数据进行增强处理,包括:
- 随机裁剪:从图像中随机裁剪不同位置的子图像
- 随机翻转:水平或垂直翻转图像
- 亮度调整:随机调整图像亮度
- 对比度增强:随机调整图像对比度
- 旋转:随机旋转图像小角度
-
标准化:对RGB图像进行归一化处理,将像素值从[0, 255]缩放到[-1, 1]范围。对光流图像进行标准化处理,使其均值为0,标准差为1。
-
数据格式转换:将处理后的图像数据转换为模型所需的张量格式,RGB图像和光流图像分别作为空间流和时间流的输入。
通过上述预处理步骤,不仅提高了数据质量,还大幅减少了数据冗余,降低了模型计算复杂度,为后续模型训练和推理奠定了良好基础。
3. 功能模块介绍
3.1 双流特征提取模块
双流特征提取模块是整个识别系统的核心,负责从视频数据中提取空间特征和时间特征。该模块采用改进的双流CNN结构,分别处理RGB图像和光流图像。
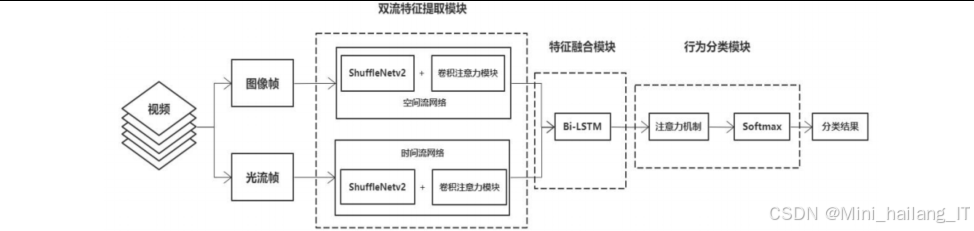
空间流网络以RGB图像帧作为输入,主要提取人体的静态外观特征。为了实现模型轻量化,空间流网络采用ShuffleNetV2作为骨干网络。ShuffleNetV2通过通道混洗操作和分组卷积,在保持较高特征提取能力的同时,大幅降低了计算复杂度。此外,在ShuffleNetV2的基础上,引入了CBAM注意力机制,增强对关键区域的特征提取能力。CBAM包含通道注意力和空间注意力两个子模块,能够自适应地为不同通道和不同空间位置分配权重,有效提高特征表达能力。
时间流特征提取:
时间流网络以堆叠的光流图像作为输入,主要提取人体的动态运动特征。时间流网络与空间流网络采用相同的网络结构,但输入为连续10帧光流图像的堆叠(水平和垂直方向),分辨率为224×224×20。时间流网络的设计思路是通过捕捉相邻帧之间的像素运动,有效表征人体行为的动态信息。
通过双流特征提取模块,系统能够同时获取视频中的静态空间信息和动态时间信息,为后续的行为识别提供丰富的特征表示。
3.2 双流特征融合模块
双流特征融合模块负责将空间流和时间流提取的特征进行有效融合,充分利用两种特征的互补性。考虑到视频行为具有长时序特性,本研究引入Bi-LSTM(双向长短期记忆网络)进行特征融合。
Bi-LSTM由前向LSTM和后向LSTM组成,能够同时考虑过去和未来的信息,有效捕捉视频序列的长距离依赖关系。与传统的最大池化或平均池化融合方法相比,Bi-LSTM能够更好地保留时序信息,提高行为识别的准确率。双流特征融合模块的具体实现流程如下:
- 接收空间流和时间流输出的特征向量
- 将空间特征和时间特征按时间步拼接,形成时空特征序列
- 将时空特征序列输入Bi-LSTM网络
- Bi-LSTM网络的前向和后向单元分别处理特征序列
- 对Bi-LSTM的输出进行拼接,得到融合后的特征向量
通过Bi-LSTM特征融合,系统能够有效建模视频序列中的时序关系,提高对复杂行为的识别能力。
3.3 行为分类模块
行为分类模块负责对融合后的特征进行分类,输出最终的行为识别结果。为了进一步提高识别准确率,本研究在分类模块中引入了注意力机制。注意力机制能够自适应地为不同时间步的特征分配权重,突出对识别结果贡献较大的关键帧特征。具体来说,注意力机制根据Bi-LSTM输出的特征向量,计算每个时间步的注意力权重,然后对特征进行加权求和,得到最终的分类特征向量。行为分类模块的具体实现流程如下:
- 接收Bi-LSTM输出的特征序列
- 通过全连接层将特征映射到注意力空间
- 应用tanh激活函数进行非线性变换
- 通过另一个全连接层计算注意力权重
- 使用Softmax函数对权重进行归一化
- 根据注意力权重对特征序列进行加权求和
- 最后通过分类器(全连接层+Softmax)输出行为类别概率分布
通过引入注意力机制,系统能够更加关注对行为识别起关键作用的帧,提高识别准确率,同时增强模型的可解释性。
4. 算法理论
4.1 双流卷积神经网络原理
双流卷积神经网络是一种经典的视频行为识别框架,通过分别处理视频的空间信息和时间信息,有效提升了行为识别的准确率。双流CNN由空间流和时间流两个分支组成。空间流以单帧RGB图像为输入,主要提取人体的外观特征;时间流以光流场为输入,主要提取人体的运动特征。两个分支分别独立训练,最终通过特征融合或分数融合得到识别结果。
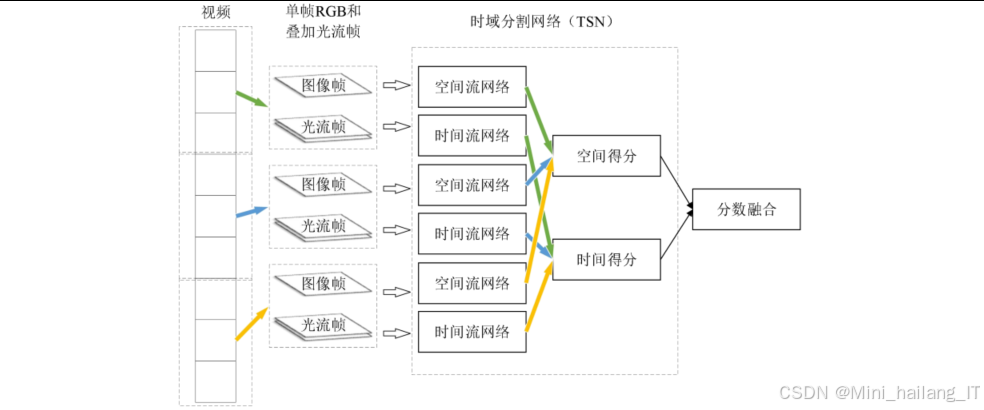
传统双流CNN通常使用VGG或ResNet作为骨干网络,参数量大,计算复杂度高。本研究采用ShuffleNetV2作为骨干网络,并引入CBAM注意力机制,在保证识别性能的同时大幅降低了计算复杂度。
4.2 ShuffleNetV2轻量化网络
ShuffleNetV2是一种专为移动设备设计的高效CNN架构,通过创新实现了计算效率和模型精度的良好平衡ShuffleNetV2基于四条核心设计原则:
- 等通道宽度原则:卷积层的输入通道数和输出通道数应尽可能接近,以减少内存访问成本。
- 分组数适中原则:分组卷积虽然可以减少计算量,但会增加分组操作的开销,分组数应适中。
- 网络碎片化适度原则:过多的网络分支会降低并行度,增加内存访问成本。
- 元素级操作简化原则:元素级操作(如Add、ReLU)虽然计算量小,但内存访问成本高,应尽量减少。
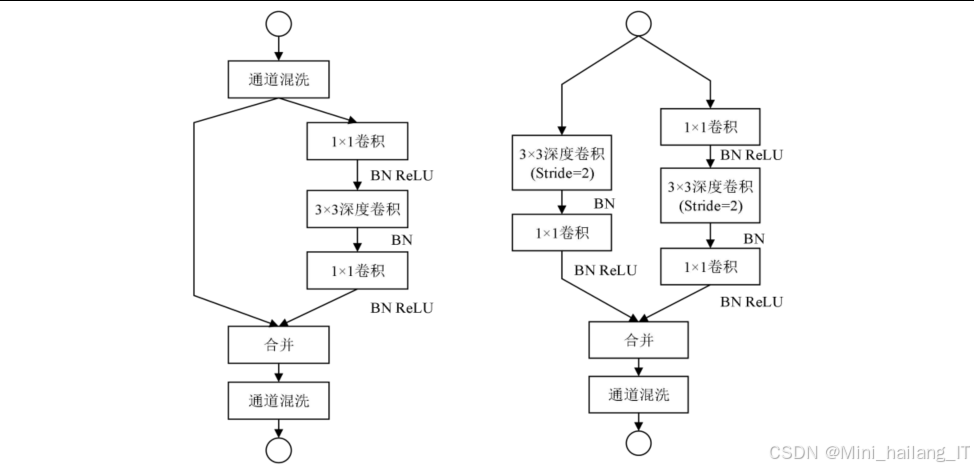
核心组件:
-
通道混洗:通过对分组卷积后的特征图进行通道混洗,实现不同组之间的信息交互,解决分组卷积导致的信息隔离问题。
-
ShuffleNetV2单元:包含两种基本结构:
- 步长为1的单元:包含两个分支,主分支直接通过,另一个分支包含1×1卷积(分组)、通道混洗、3×3深度可分离卷积和1×1卷积(分组),最后通过Add操作合并。
- 步长为2的单元:用于降采样,包含两个分支,主分支通过3×3深度可分离卷积和步长为2的操作降采样,另一个分支包含1×1卷积(分组)、通道混洗、3×3深度可分离卷积(步长2)和1×1卷积(分组),最后通过Concat操作合并。
4.3 CBAM注意力机制
CBAM是一种轻量级的注意力机制,能够有效提升卷积神经网络的特征表达能力。CBAM包含通道注意力模块和空间注意力模块两个子模块,分别从通道维度和空间维度对特征进行加权。CBAM注意力机制具有以下优势:
- 计算开销小,可以轻松集成到现有网络中
- 能够自适应地关注重要的通道和空间位置
- 有效提升模型的特征表达能力和识别准确率
4.4 Bi-LSTM特征融合
Bi-LSTM(双向长短期记忆网络)是LSTM的扩展版本,通过同时考虑序列的前向和后向信息,能够更好地建模长序列数据的时序关系。LSTM通过门控机制解决了传统RNN的梯度消失问题,能够有效捕捉长距离依赖关系。LSTM单元包含三个门:遗忘门、输入门和输出门,分别控制信息的遗忘、更新和输出。
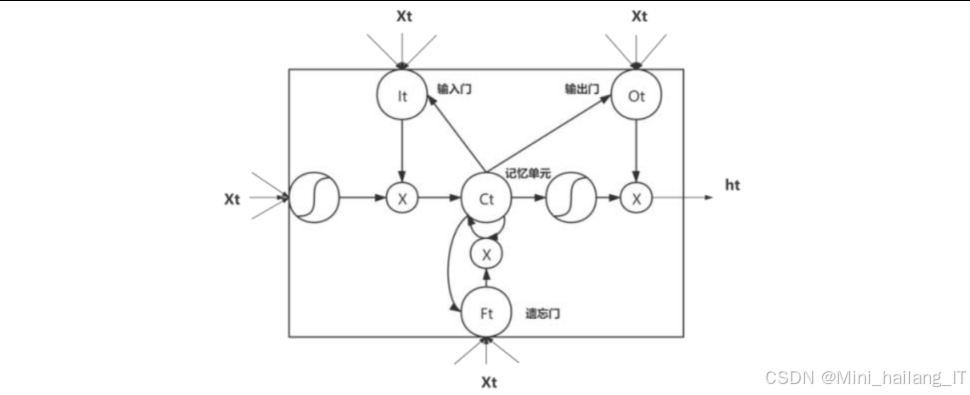
4.5 注意力机制分类
在行为分类模块中引入注意力机制,能够自适应地为不同时间步的特征分配权重,提高分类准确率,注意力机制的核心思想是根据任务需求,动态地为输入序列中的不同元素分配不同的权重。在本研究中,注意力机制用于为Bi-LSTM输出的特征序列中的每个时间步分配权重,突出对行为识别贡献较大的关键帧特征。
5. 核心代码介绍
5.1 ShuffleNetV2特征提取网络实现
ShuffleNetV2是本研究的骨干网络,负责高效提取视频帧的特征。下面是ShuffleNetV2单元的核心实现代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class ShuffleV2Block(nn.Module):
def __init__(self, inp, oup, mid_channels, ksize, stride):
super(ShuffleV2Block, self).__init__()
self.stride = stride
assert stride in [1, 2]
self.mid_channels = mid_channels
self.ksize = ksize
pad = ksize // 2
# 判断是否需要通道分割
self.inp = inp
self.oup = oup
if stride == 2:
self.branch_main_1 = nn.Sequential(
# 1×1卷积,分组数为2
nn.Conv2d(inp, inp, 1, 1, 0, groups=2, bias=False),
nn.BatchNorm2d(inp),
nn.ReLU(inplace=True),
# 3×3深度可分离卷积,步长为2
nn.Conv2d(inp, inp, ksize, stride, pad, groups=inp, bias=False),
nn.BatchNorm2d(inp),
)
self.branch_main_2 = nn.Sequential(
# 1×1卷积,分组数为2
nn.Conv2d(inp, oup - inp, 1, 1, 0, groups=2, bias=False),
nn.BatchNorm2d(oup - inp),
nn.ReLU(inplace=True),
)
elif stride == 1:
self.branch_main_1 = nn.Sequential(
# 1×1卷积,分组数为2
nn.Conv2d(inp - inp//2, mid_channels, 1, 1, 0, groups=2, bias=False),
nn.BatchNorm2d(mid_channels),
nn.ReLU(inplace=True),
# 3×3深度可分离卷积,步长为1
nn.Conv2d(mid_channels, mid_channels, ksize, stride, pad, groups=mid_channels, bias=False),
nn.BatchNorm2d(mid_channels),
# 1×1卷积,分组数为2
nn.Conv2d(mid_channels, oup - inp//2, 1, 1, 0, groups=2, bias=False),
nn.BatchNorm2d(oup - inp//2),
nn.ReLU(inplace=True),
)
def forward(self, x):
if self.stride == 1:
# 通道分割
x1, x2 = x.chunk(2, dim=1)
out = torch.cat((x1, self.branch_main_1(x2)), dim=1)
elif self.stride == 2:
# 步长为2时,直接连接两个分支
out = torch.cat((self.branch_main_1(x), self.branch_main_2(x)), dim=1)
# 通道混洗操作
out = self.channel_shuffle(out, 2)
return out
def channel_shuffle(self, x, groups):
# 通道混洗函数实现
batchsize, num_channels, height, width = x.data.size()
channels_per_group = num_channels // groups
# 重塑张量以进行通道混洗
x = x.view(batchsize, groups, channels_per_group, height, width)
# 转置并重塑回原始形状
x = torch.transpose(x, 1, 2).contiguous()
x = x.view(batchsize, -1, height, width)
return x
这段代码实现了ShuffleNetV2的基本构建单元,包括步长为1(用于特征提取)和步长为2(用于降采样)两种情况。核心创新点包括:
-
通道分割:在步长为1的情况下,将输入特征通道分为两部分,一部分直接通过,另一部分经过卷积操作,减少计算量。
-
分组卷积:使用分组卷积降低计算复杂度,1×1卷积的分组数设置为2,平衡计算效率和特征提取能力。
-
深度可分离卷积:3×3卷积采用深度可分离卷积,将标准卷积分解为深度卷积和逐点卷积,大幅减少计算量。
-
通道混洗:通过通道混洗操作实现不同组之间的信息交互,解决分组卷积导致的信息隔离问题。
该模块是ShuffleNetV2网络的核心,通过这些设计,在保持较高特征提取能力的同时,显著降低了计算复杂度和参数量。
5.2 CBAM注意力机制实现
CBAM注意力机制用于增强特征图中关键区域的表示,下面是其核心实现代码:
import torch
import torch.nn as nn
import torch.nn.functional as F
class ChannelAttention(nn.Module):
def __init__(self, in_channels, reduction_ratio=16):
super(ChannelAttention, self).__init__()
# 全局平均池化
self.avg_pool = nn.AdaptiveAvgPool2d(1)
# 全局最大池化
self.max_pool = nn.AdaptiveMaxPool2d(1)
# 共享的多层感知机
self.mlp = nn.Sequential(
nn.Linear(in_channels, in_channels // reduction_ratio, bias=False),
nn.ReLU(inplace=True),
nn.Linear(in_channels // reduction_ratio, in_channels, bias=False)
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 计算平均池化特征
avg_out = self.mlp(self.avg_pool(x).view(x.size(0), -1))
# 计算最大池化特征
max_out = self.mlp(self.max_pool(x).view(x.size(0), -1))
# 特征相加并应用Sigmoid
out = avg_out + max_out
out = self.sigmoid(out).view(x.size(0), x.size(1), 1, 1)
# 与原始特征图相乘
return x * out
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super(SpatialAttention, self).__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
# 7×7卷积层
self.conv = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
# 在通道维度上计算平均池化
avg_out = torch.mean(x, dim=1, keepdim=True)
# 在通道维度上计算最大池化
max_out, _ = torch.max(x, dim=1, keepdim=True)
# 拼接两个池化结果
out = torch.cat([avg_out, max_out], dim=1)
# 通过卷积层
out = self.conv(out)
# 应用Sigmoid
out = self.sigmoid(out)
# 与原始特征图相乘
return x * out
class CBAM(nn.Module):
def __init__(self, in_channels, reduction_ratio=16, kernel_size=7):
super(CBAM, self).__init__()
# 通道注意力模块
self.channel_attention = ChannelAttention(in_channels, reduction_ratio)
# 空间注意力模块
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
# 先应用通道注意力,再应用空间注意力
x = self.channel_attention(x)
x = self.spatial_attention(x)
return x
这段代码实现了CBAM注意力机制的两个核心组件:通道注意力模块和空间注意力模块。主要特点包括:
-
通道注意力模块:通过全局平均池化和全局最大池化获取通道特征,然后通过共享的MLP学习通道间的依赖关系,生成通道注意力权重。
-
空间注意力模块:通过在通道维度上的平均池化和最大池化获取空间特征,然后通过7×7卷积学习空间位置间的依赖关系,生成空间注意力权重。
-
串联结构:CBAM采用通道注意力在前、空间注意力在后的串联结构,先关注重要的通道,再在这些通道上关注重要的空间位置。
-
轻量化设计:通过降维MLP和深度卷积等技术,保持模块的轻量级特性,计算开销小。
CBAM注意力机制能够自适应地为不同通道和不同空间位置分配权重,有效提高特征表达能力,同时计算开销小,可以轻松集成到现有网络中。
5.3 Bi-LSTM特征融合网络实现
Bi-LSTM用于融合双流CNN提取的时空特征,下面是其核心实现代码:
import torch
import torch.nn as nn
class BiLSTMFeatureFusion(nn.Module):
def __init__(self, input_size, hidden_size, num_layers=1, dropout=0.5):
super(BiLSTMFeatureFusion, self).__init__()
# 双向LSTM层
self.bilstm = nn.LSTM(
input_size=input_size,
hidden_size=hidden_size,
num_layers=num_layers,
bidirectional=True,
batch_first=True,
dropout=dropout if num_layers > 1 else 0
)
# Dropout层用于防止过拟合
self.dropout = nn.Dropout(dropout)
# 输出特征维度是hidden_size*2(双向)
self.out_feature_dim = hidden_size * 2
def forward(self, x):
# x的形状: [batch_size, seq_len, input_size]
batch_size = x.size(0)
# 初始化隐藏状态和细胞状态
h0 = torch.zeros(2 * self.bilstm.num_layers, batch_size, self.bilstm.hidden_size).to(x.device)
c0 = torch.zeros(2 * self.bilstm.num_layers, batch_size, self.bilstm.hidden_size).to(x.device)
# 前向传播
# out的形状: [batch_size, seq_len, hidden_size*2]
# hn的形状: [2*num_layers, batch_size, hidden_size]
out, (hn, cn) = self.bilstm(x, (h0, c0))
# 应用Dropout
out = self.dropout(out)
return out
class AttentionMechanism(nn.Module):
def __init__(self, hidden_size):
super(AttentionMechanism, self).__init__()
# 注意力计算层
self.attention = nn.Linear(hidden_size, 1)
def forward(self, lstm_output):
# lstm_output的形状: [batch_size, seq_len, hidden_size]
# 计算注意力分数
# scores的形状: [batch_size, seq_len, 1]
scores = self.attention(torch.tanh(lstm_output))
# 应用Softmax获取注意力权重
# weights的形状: [batch_size, seq_len, 1]
weights = F.softmax(scores, dim=1)
# 加权求和,得到上下文向量
# context的形状: [batch_size, hidden_size]
context = torch.sum(weights * lstm_output, dim=1)
return context, weights
class BiLSTMWithAttention(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(BiLSTMWithAttention, self).__init__()
# Bi-LSTM特征融合
self.bilstm = BiLSTMFeatureFusion(input_size, hidden_size)
# 注意力机制
self.attention = AttentionMechanism(hidden_size * 2)
# 分类器
self.classifier = nn.Linear(hidden_size * 2, num_classes)
def forward(self, spatial_features, temporal_features):
# 将空间特征和时间特征按时间步拼接
# input_features的形状: [batch_size, seq_len, input_size]
input_features = torch.cat((spatial_features, temporal_features), dim=2)
# Bi-LSTM特征融合
lstm_output = self.bilstm(input_features)
# 应用注意力机制
context_vector, attention_weights = self.attention(lstm_output)
# 分类
output = self.classifier(context_vector)
return output, attention_weights
这段代码实现了Bi-LSTM特征融合网络和注意力机制,主要功能包括:
-
Bi-LSTM特征融合:通过双向LSTM网络同时处理序列的前向和后向信息,有效捕捉视频序列的长距离依赖关系。
-
注意力机制:为Bi-LSTM输出的每个时间步分配不同的权重,突出对行为识别贡献较大的关键帧特征。
-
特征拼接:将空间流和时间流提取的特征按时间步拼接,作为Bi-LSTM的输入。
-
端到端训练:整个网络可以端到端训练,注意力权重的计算过程可微分。
该模块能够有效融合双流CNN提取的时空特征,同时通过注意力机制自适应地关注重要的时间步,提高行为识别的准确率。
5.4 模型部署与推理代码
下面是模型在边缘设备上的部署与推理代码,包括模型加载、视频处理和推理过程:
import cv2
import numpy as np
import torch
from rknn.api import RKNN
class BehaviorRecognitionSystem:
def __init__(self, model_path, num_classes=14):
self.model_path = model_path
self.num_classes = num_classes
self.rknn = RKNN()
self.class_names = [
'正常行走', '搬运物品', '使用推车', '驾驶车辆',
'搭建脚手架', '清理工地', '施工作业', '攀爬高处',
'翻越围栏', '快速奔跑', '抛掷物品', '打闹推搡',
'意外摔倒', '使用手机'
]
# 初始化模型
self._init_model()
def _init_model(self):
# 加载RKNN模型
print('Loading RKNN model...')
ret = self.rknn.load_rknn(self.model_path)
if ret != 0:
print('Load RKNN model failed!')
exit(-1)
# 初始化RKNN运行环境
print('Initializing RKNN runtime environment...')
ret = self.rknn.init_runtime()
if ret != 0:
print('Init RKNN runtime environment failed!')
exit(-1)
print('Model initialized successfully!')
def preprocess_frame(self, frame, size=(224, 224)):
# 调整图像大小
resized = cv2.resize(frame, size)
# 转换为RGB格式
rgb = cv2.cvtColor(resized, cv2.COLOR_BGR2RGB)
# 归一化到[-1, 1]
normalized = rgb.astype(np.float32) / 127.5 - 1.0
# 调整维度顺序为[1, 2, 0](HWC->CHW)
transposed = np.transpose(normalized, (2, 0, 1))
# 添加批次维度
batch = np.expand_dims(transposed, axis=0)
return batch
def extract_optical_flow(self, prev_frame, curr_frame, size=(224, 224)):
# 调整图像大小
prev_gray = cv2.cvtColor(cv2.resize(prev_frame, size), cv2.COLOR_BGR2GRAY)
curr_gray = cv2.cvtColor(cv2.resize(curr_frame, size), cv2.COLOR_BGR2GRAY)
# 使用TV-L1光流算法
flow = cv2.optflow.DualTVL1OpticalFlow_create().calc(prev_gray, curr_gray, None)
# 标准化光流
flow_normalized = np.zeros_like(flow)
for i in range(2):
min_val = flow[..., i].min()
max_val = flow[..., i].max()
if max_val - min_val > 0:
flow_normalized[..., i] = 255 * (flow[..., i] - min_val) / (max_val - min_val)
# 调整维度顺序
flow_transposed = np.transpose(flow_normalized, (2, 0, 1))
# 添加批次维度
batch = np.expand_dims(flow_transposed, axis=0)
return batch
def keyframe_extraction(self, frames, threshold=10):
# 基于帧间差分法提取关键帧
keyframes = [frames[0]]
prev_gray = cv2.cvtColor(frames[0], cv2.COLOR_BGR2GRAY)
for i in range(1, len(frames)):
curr_gray = cv2.cvtColor(frames[i], cv2.COLOR_BGR2GRAY)
# 计算帧间差分
diff = cv2.absdiff(prev_gray, curr_gray)
# 计算差分绝对值的平均值
mean_diff = np.mean(diff)
if mean_diff > threshold:
keyframes.append(frames[i])
prev_gray = curr_gray
return keyframes
def predict(self, rgb_input, flow_input):
# 模型推理
outputs = self.rknn.inference(inputs=[rgb_input, flow_input])
# 获取预测结果
pred = np.argmax(outputs[0])
confidence = np.max(outputs[0])
return pred, confidence
def process_video(self, video_path):
# 打开视频文件
cap = cv2.VideoCapture(video_path)
frames = []
# 读取视频帧
while True:
ret, frame = cap.read()
if not ret:
break
frames.append(frame.copy())
cap.release()
# 提取关键帧
keyframes = self.keyframe_extraction(frames)
results = []
for i in range(1, len(keyframes)):
# 预处理RGB帧
rgb_input = self.preprocess_frame(keyframes[i])
# 提取光流
flow_input = self.extract_optical_flow(keyframes[i-1], keyframes[i])
# 模型推理
pred, confidence = self.predict(rgb_input, flow_input)
results.append({
'frame_index': i,
'class': self.class_names[pred],
'confidence': float(confidence),
'is_unsafe': pred >= 7 # 不安全行为类别索引从7开始
})
return results
def release(self):
# 释放RKNN资源
self.rknn.release()
# 使用示例
def main():
# 初始化识别系统
model_path = 'behavior_recognition.rknn'
system = BehaviorRecognitionSystem(model_path)
# 处理视频
video_path = 'test_video.mp4'
results = system.process_video(video_path)
# 输出结果
for result in results:
print(f"Frame {result['frame_index']}: {result['class']} (confidence: {result['confidence']:.4f})")
if result['is_unsafe']:
print(f" WARNING: Unsafe behavior detected!")
# 释放资源
system.release()
if __name__ == '__main__':
main()
这段代码实现了模型在边缘设备上的部署与推理功能,主要包括:
-
模型加载与初始化:使用RKNN API加载和初始化模型,准备推理环境。
-
图像预处理:包括调整大小、颜色空间转换、归一化等操作,将输入图像转换为模型所需格式。
-
光流提取:使用OpenCV的TV-L1光流算法提取视频帧之间的运动信息。
-
关键帧提取:基于帧间差分法提取视频中的关键帧,减少冗余计算。
-
模型推理:调用RKNN的推理接口进行预测,获取行为类别和置信度。
-
结果处理:输出识别结果,并标记不安全行为。
该代码充分考虑了边缘设备的资源限制,通过关键帧提取、优化的预处理算法等技术,提高了推理效率,实现了施工人员不安全行为的实时识别。
6. 重难点和创新点
本研究在实现过程中面临多个技术难点,主要包括:
-
模型轻量化与识别精度的平衡:
传统双流CNN模型虽然识别准确率高,但计算复杂度和参数量大,难以在边缘设备上实时运行。如何在保证识别准确率的前提下,大幅降低模型计算复杂度和参数量,是本研究的首要难点。解决方法:通过深入分析ShuffleNetV2、MobileNet等轻量级网络的设计原理,选择ShuffleNetV2作为骨干网络,并引入CBAM注意力机制补偿轻量化带来的性能损失。同时,通过模型量化技术进一步减小模型体积,最终实现了模型大小从41.8MB减小到20.9MB,计算复杂度从传统双流CNN的12.41G降低到7.73G,同时保持94.3%的高识别准确率。
-
视频行为长时序特征提取:
施工人员行为具有明显的时序特性,传统的双流CNN方法在处理长时序视频时存在信息丢失问题,难以有效建模行为的时间依赖性。解决方法:引入Bi-LSTM网络进行特征融合,Bi-LSTM能够同时考虑视频序列的前向和后向信息,有效捕捉长距离依赖关系。通过将双流CNN提取的时空特征序列输入Bi-LSTM,显著提高了模型对复杂行为的识别能力。实验结果表明,引入Bi-LSTM后,模型识别准确率从93.5%提升到94.1%。
-
关键帧高效提取:
直接处理视频的所有帧会导致计算量过大,降低识别效率。如何高效提取能够准确表征行为信息的关键帧,是实现实时识别的关键。解决方法:提出了基于帧间差分法的关键帧采样策略,并结合二次去重机制。通过计算相邻帧的灰度差值,提取变化较大的帧作为关键帧,然后对关键帧进行相似度分析,剔除冗余帧。该方法在保证行为信息完整性的同时,显著减少了处理的帧数,提高了识别效率。
-
边缘设备模型部署与优化:
边缘设备资源有限,如何将训练好的模型高效部署到边缘设备,并充分利用NPU进行加速,是实现实时识别的技术难点。解决方法:使用RKNN-Toolkit将PyTorch模型转换为RKNN格式,并进行16位整型量化。通过分析量化后的精度损失,对模型进行微调,最终在边缘设备上实现了91.1%的识别准确率。同时,优化了视频处理流程,采用多线程技术并行处理视频采集和模型推理,进一步提高了系统响应速度。
7. 总结
本研究针对建筑工地施工人员不安全行为识别的实际需求,提出了一种基于改进双流CNN的轻量级识别方法,并成功实现了边缘端部署。通过系统的理论分析、算法设计和实验验证,取得了以下主要成果:
-
理论研究方面:深入研究了双流CNN、轻量级网络、注意力机制、Bi-LSTM等相关理论和技术,为构建高效的行为识别模型提供了理论基础。通过分析不同轻量级网络的性能特点,选择ShuffleNetV2作为骨干网络,并结合CBAM注意力机制,有效平衡了模型性能和计算效率。
-
算法设计方面:提出了一种融合ShuffleNetV2、CBAM、Bi-LSTM和注意力机制的改进双流CNN模型。该模型通过双流结构分别提取空间和时间特征,使用Bi-LSTM进行特征融合,最后通过注意力机制进行行为分类。实验结果表明,该模型在UCF-101数据集上的识别准确率达到94.3%,计算复杂度为7.73G,模型参数量为5.38M,综合性能优于传统双流CNN方法。
-
数据处理方面:构建了包含14类行为的建筑工地施工人员行为数据集,并提出了基于TV-L1的稠密光流提取和基于帧间差分的关键帧采样方法。这些方法有效提高了数据质量,减少了数据冗余,为模型训练和推理提供了良好基础。
8. 参考文献
[1] Wang X, Gupta A. Videos as space-time region graphs[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 399-417.
[2] Li W, Nie W, et al. Human action recognition based on selected spatio-temporal features via bidirectional LSTM[J]. IEEE Access, 2018, 6(1): 44211-44220.
[3] Zhang Z, Luo H, Wang C, et al. Automatic modulation classification using CNN-LSTM based dual-stream structure[J]. IEEE Transactions on Vehicular Technology, 2020, 69(11): 13521-13531.
[4] Zhao Y, Xiong Y, Lin D. Trajectory convolution for action recognition[J]. Advances in Neural Information Processing Systems, 2018, 31(1): 243-251.
[5] Woo S, Park J, Lee J Y, et al. CBAM: Convolutional block attention module[C]//Proceedings of the European Conference on Computer Vision. 2018: 3-19.
[6] Zhang X, Zhou X, Lin M, et al. ShuffleNet: An extremely efficient convolutional neural network for mobile devices[C]//Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2018: 6848-6856.
[7] Ma N, Zhang X, Zheng H T, et al. ShuffleNet v2: Practical guidelines for efficient CNN architecture design[C]//Proceedings of the European Conference on Computer Vision. 2018: 116-131.
[8] Sandler M, Howard A, Zhu M, et al. MobileNetV2: Inverted residuals and linear bottlenecks[C]//Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2018: 4510-4520.


















 356
356

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









