




选题背景
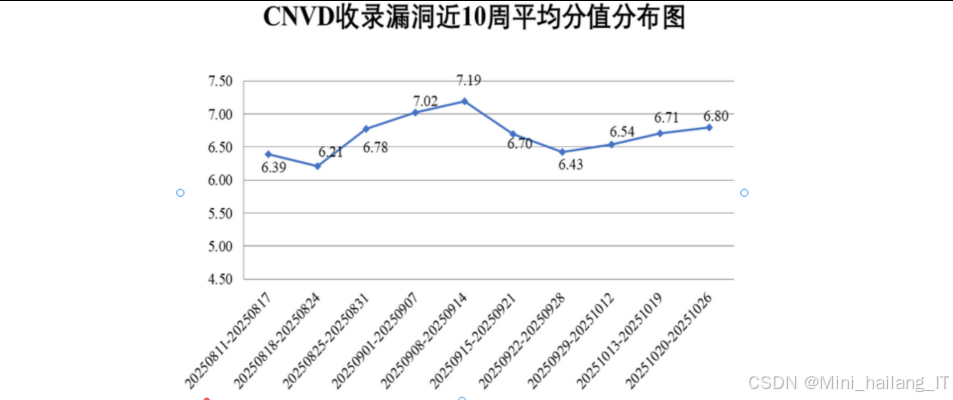
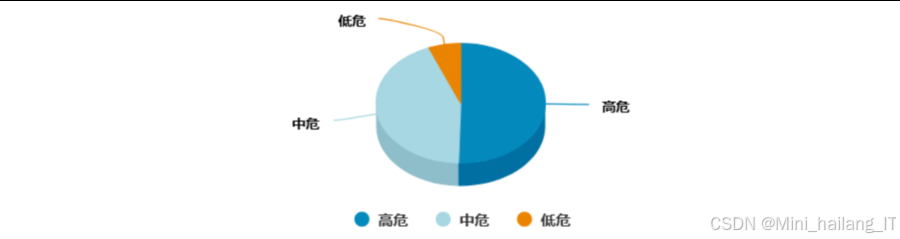
随着互联网的迅速发展,Web应用已经深度融入人们的日常生活和工作中。根据国家信息安全漏洞共享平台(CNVD)的统计数据,近十年来网络漏洞数量呈现爆炸式增长,与十年前相比增长了近十倍。在众多Web安全威胁中,跨站脚本攻击长期位列OWASP漏洞排行榜的前十位。XSS攻击是指攻击者将恶意脚本注入到Web应用中,并最终在客户端浏览器中执行的攻击方式。这类攻击可以导致用户隐私信息泄露、账户被盗用、甚至财产损失,严重威胁着网络空间的安全。
传统的XSS漏洞检测方法主要分为静态分析和动态分析两大类。静态分析方法需要获取目标源代码,对代码进行分析找出可能存在的漏洞;而动态分析方法则不需要源代码,从攻击者角度进行测试,找出Web应用中的安全缺陷。虽然动态分析方法具有不需要源代码、针对性强等优点,但在实际应用中仍面临诸多挑战:
随着网络安全意识的不断提高,企业和组织对Web应用安全的重视程度也在不断增强。尽早发现并修复Web应用中的XSS漏洞,可以有效避免因安全事件造成的声誉损害和经济损失。因此,研究高效的XSS漏洞检测方法对于维护网络空间安全、保障用户权益具有重要的现实意义。
数据集
本研究中使用的数据集主要包括两部分:测试目标网站集和攻击载荷库。为了全面评估XSS漏洞检测系统的性能,我们选择了多种类型的Web应用作为测试目标,包括:
-
基准测试平台:使用DVWA、WebGoat等标准的Web安全测试平台,这些平台包含已知的XSS漏洞,可用于验证检测系统的准确性。
-
开源Web应用:选择了多个流行的开源Web应用,如WordPress、Drupal、Joomla等CMS系统,以及一些常见的论坛、博客系统。这些应用具有真实的业务逻辑和复杂的代码结构,更接近实际应用场景。
-
自定义测试页面:设计了一系列包含不同类型、不同复杂度XSS漏洞的测试页面,用于测试系统在各种特定场景下的检测能力。这些页面涵盖了反射型XSS、存储型XSS和DOM型XSS等多种漏洞类型,以及不同的输出位置(HTML标签间、标签内属性、JavaScript代码中等)。
测试目标网站集的选择考虑了多样性和代表性,确保检测系统能够在不同环境下有效工作。通过对这些目标的测试,我们可以全面评估系统的检测准确率、误报率、漏报率以及检测效率等关键指标。
项目功能
基于动态分析的XSS漏洞检测系统实现了以下核心功能:
参数配置
系统提供了灵活的参数配置界面,用户可以根据需要设置以下参数:
- 文件位置设置:配置日志文件、结果文件的保存路径
- 爬虫设置:设置爬取深度、爬取线程数、超时时间等爬虫参数
- XSS检测设置:配置检测策略、攻击载荷选择规则等
- 默认填充设置:设置表单参数的默认填充值
通过这些配置,用户可以根据不同的测试需求和目标系统特点,灵活调整检测系统的行为。
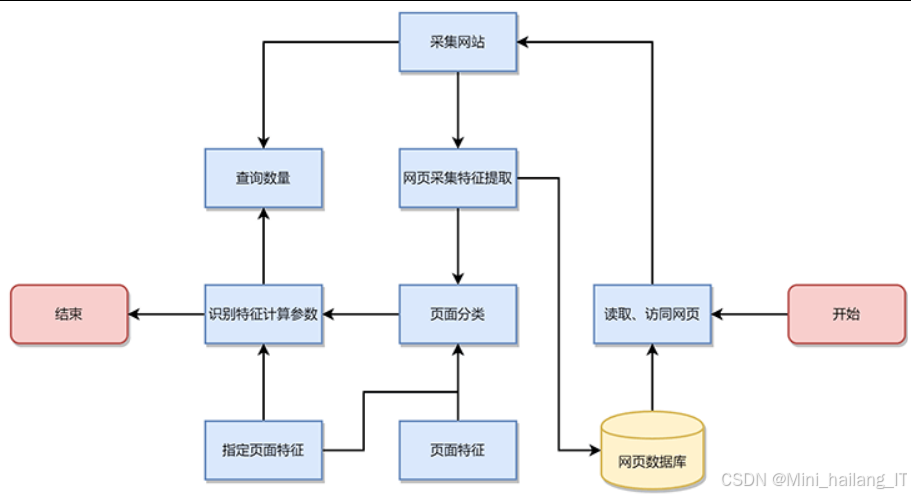
网络爬虫
网络爬虫模块负责发现Web应用中的测试点,主要功能包括:
- 网页爬取:按照广度优先或深度优先策略爬取目标网站的网页
- 多线程爬取:采用线程池技术实现多线程并发爬取,提高爬取效率
- 反反爬虫机制:通过设置随机User-Agent、使用代理服务器等方式绕过网站的反爬机制
- 网页解析:解析HTML页面,提取其中的链接和表单信息
- 网页去重:使用改进的去重算法,避免重复爬取相同的网页和测试点
爬虫模块能够高效地发现Web应用中的潜在测试点,为后续的漏洞检测提供基础。
XSS检测
XSS检测模块是系统的核心,实现了高效的漏洞检测算法,主要功能包括:
- 载荷单元生成:根据测试需求生成各种类型的载荷单元
- 绕过规则选择:针对不同的测试环境选择合适的绕过规则
- 试探载荷测试:发送试探性载荷,确定测试点的基本信息和输出位置
- 载荷单元单独测试:对各载荷单元进行单独测试,确定哪些单元可以成功执行
- 载荷单元组合测试:将可执行的载荷单元组合起来进行测试,提高检测效率
检测模块通过创新的载荷单元组合策略,大幅提高了检测效率,同时保持了较高的检测准确率。
算法理论介绍
网页去重
传统的基于URL的网页去重方法在XSS检测场景中存在明显不足,因为不同的URL可能对应相同的表单结构,导致重复测试。本研究提出了一种结合URL去重和表单特征去重的改进方法:改进的去重方法不仅考虑URL的唯一性,还提取Form表单的关键特征进行去重。对于每个包含Form表单的页面,我们提取表单的method、action属性以及所有输入字段的name属性,将这些信息组合成一个字符串,然后使用哈希函数生成特征值。实现步骤:
- Form表单唯一标记生成:对于每个Form表单,生成唯一标记a = method + action + name₁ + name₂ + … + nameₙ
- 特征值提取:对生成的标记字符串进行哈希处理,得到Form表单的特征值
- 使用Bloom Filter进行去重:将Form表单特征值和URL特征值一起存入Bloom Filter,用于快速判断是否重复
Bloom Filter是一种空间效率很高的概率型数据结构,用于判断一个元素是否在一个集合中。它可能会出现误判(将不在集合中的元素误认为在集合中),但不会漏判(将在集合中的元素误认为不在集合中)。
XSS检测
传统的XSS检测方法通常需要测试大量的完整攻击载荷,效率低下。本研究提出了一种基于载荷单元生成与组合的改进检测算法:载荷单元分类将攻击载荷分解为10类基本单元:
- 弹窗载荷单元(P):用于生成弹窗效果的代码片段
- 弹窗载体单元(S):用于承载弹窗载荷的HTML标签
- 脚本载荷单元(Sc):JavaScript代码片段
- 脚本载体单元(ScC):用于承载脚本载荷的HTML标签
- 链接载荷单元(L):包含JavaScript代码的链接
- 链接载体单元(LC):用于承载链接载荷的HTML标签
- 样式表载荷单元(St):CSS样式代码片段
- 样式表载体单元(StC):用于承载样式表载荷的HTML标签
- 前缀单元(Pre):载荷前面的修饰内容
- 后缀单元(Suf):载荷后面的修饰内容
检测流程:
- 试探载荷测试:发送试探性载荷,确定测试点的输出位置和基本特性
- 载荷单元单独测试:根据试探测试结果,选择合适的载荷单元进行单独测试
- 载荷单元组合测试:将通过单独测试的载荷单元组合起来,生成完整的攻击载荷进行测试
协同策略
采用组合测试优先、失败后调用单独测试的协同策略:
- 首先尝试组合测试,即一次性发送包含多个载荷单元的完整攻击载荷
- 如果组合测试失败,再对各个载荷单元进行单独测试,找出能够成功执行的单元
- 最后根据单独测试结果,重新组合生成新的攻击载荷进行测试
通过这种策略,可以在大多数情况下仅需一次请求就能完成检测,显著提高了检测效率。
核心代码
网页去重
改进的网页去重算法,核心功能包括:
-
generate_form_signature函数:提取表单的method、action属性以及所有输入字段的name属性,生成唯一的表单签名。通过对输入字段name进行排序,确保即使字段顺序不同但内容相同的表单也能被正确识别为重复。
-
add_to_bloom_filter函数:将URL和表单签名添加到Bloom Filter中。使用多个哈希函数对输入进行处理,降低哈希冲突的概率。Bloom Filter使用位数组实现,具有很高的空间效率。
-
is_duplicate函数:检查URL和表单是否已经存在于Bloom Filter中。只有当所有哈希函数对应的位都被设置时,才认为可能重复,这种设计保证了不会漏判,但可能出现误判。
def generate_form_signature(form):
# 提取表单的关键属性
method = form.get('method', 'GET').upper()
action = form.get('action', '')
# 提取所有输入字段的name属性并排序
input_names = sorted([input.get('name', '') for input in form.find_all('input')
if input.get('name')])
# 生成唯一标记字符串
signature = method + action + ''.join(input_names)
return signature
def add_to_bloom_filter(bloom_filter, url, form_signature=None):
# 计算URL的哈希值并添加到Bloom Filter
url_hash = hashlib.md5(url.encode()).hexdigest()
for i in range(k): # k为哈希函数数量
hash_val = (hash(url_hash + str(i)) % m) # m为位数组大小
bloom_filter.set(hash_val)
# 如果有表单签名,也将其添加到Bloom Filter
if form_signature:
form_hash = hashlib.md5(form_signature.encode()).hexdigest()
for i in range(k):
hash_val = (hash(form_hash + str(i)) % m)
bloom_filter.set(hash_val)
def is_duplicate(bloom_filter, url, form_signature=None):
# 检查URL是否重复
url_hash = hashlib.md5(url.encode()).hexdigest()
for i in range(k):
hash_val = (hash(url_hash + str(i)) % m)
if not bloom_filter.get(hash_val):
return False # URL不在过滤器中
# 如果有表单签名,也检查其是否重复
if form_signature:
form_hash = hashlib.md5(form_signature.encode()).hexdigest()
for i in range(k):
hash_val = (hash(form_hash + str(i)) % m)
if not bloom_filter.get(hash_val):
return False # 表单签名不在过滤器中
return True # 可能重复
该实现通过结合URL去重和表单特征去重,有效解决了传统方法中URL不同但表单相同导致的重复测试问题,同时利用Bloom Filter的高效性,在保证去重效果的同时显著降低了内存占用。
载荷单元生成
载荷单元的生成与组合功能,核心设计要点包括:
-
PayloadUnit类:表示一个载荷单元,包含单元类型、原始内容、应用的编码规则等信息。通过is_valid标志跟踪单元是否通过测试。apply_encoding方法用于应用编码规则,生成最终的单元内容。
-
generate_payload_units函数:根据测试点的输出位置(如HTML标签间、标签属性内等)生成相应的载荷单元。不同的输出位置需要使用不同类型的载荷单元,例如标签间输出适合使用script标签,而属性内输出适合使用事件处理器。
-
combine_payload_units函数:将通过单独测试的载荷单元组合起来,生成完整的攻击载荷。该函数实现了多种组合策略,如将脚本标签与弹窗载荷组合,将事件处理器与弹窗载荷组合等。通过合理的组合,可以生成更有效的攻击载荷。
class PayloadUnit:
def __init__(self, unit_type, content, encoding_rules=None):
self.unit_type = unit_type # 单元类型
self.content = content # 单元内容
self.encoding_rules = encoding_rules or [] # 编码规则
self.is_valid = False # 是否有效
def apply_encoding(self):
# 应用编码规则到载荷单元
encoded_content = self.content
for rule in self.encoding_rules:
encoded_content = apply_encoding_rule(encoded_content, rule)
return encoded_content
def generate_payload_units(output_position):
# 根据输出位置生成相应的载荷单元
units = []
if output_position == 'html_tag_between':
# HTML标签间输出
units.append(PayloadUnit('S', '<script>'))
units.append(PayloadUnit('P', 'alert(1)'))
units.append(PayloadUnit('Sc', 'confirm(1)'))
elif output_position == 'html_attribute':
# HTML标签属性内输出
units.append(PayloadUnit('onxxxx', 'onmouseover='))
units.append(PayloadUnit('P', 'alert(1)'))
# 其他输出位置的处理...
return units
def combine_payload_units(valid_units):
# 组合有效的载荷单元生成完整攻击载荷
combinations = []
# 弹窗载荷组合:S + P
script_units = [u for u in valid_units if u.unit_type == 'S']
popup_units = [u for u in valid_units if u.unit_type == 'P']
for s in script_units:
for p in popup_units:
combinations.append(s.apply_encoding() + p.apply_encoding() + '</script>')
# 事件处理器组合:onxxxx + P
event_units = [u for u in valid_units if u.unit_type == 'onxxxx']
for e in event_units:
for p in popup_units:
combinations.append(e.apply_encoding() + '"' + p.apply_encoding() + '"')
# 其他组合方式...
return combinations
这种基于载荷单元的设计具有很强的灵活性和可扩展性,可以根据不同的测试需求生成各种类型的攻击载荷,同时通过单独测试和组合测试相结合的方式,显著提高了检测效率。
XSS检测
XSS检测的核心算法,主要包括以下步骤:
-
试探载荷测试:首先发送试探载荷,确定测试点的输出位置。试探载荷通常包含特殊标记,通过分析响应中标记的位置和上下文,确定输出点的类型。
-
组合测试:根据输出位置生成载荷单元后,先尝试组合测试,即一次性发送包含多个载荷单元的完整攻击载荷。这种方法在大多数情况下可以快速确定是否存在漏洞。
-
单独测试:如果组合测试失败,则对各个载荷单元进行单独测试。为了让单独的载荷单元能够被正确检测,需要根据输出位置进行适当的包装。
-
重新组合测试:根据单独测试的结果,重新组合有效的载荷单元,生成新的攻击载荷进行测试。
-
响应分析:通过检查响应内容中是否包含成功执行XSS攻击的特征(如弹窗函数、脚本标签等),判断漏洞是否存在。
def detect_xss(test_point, payload_manager):
# 1. 发送试探载荷,确定输出位置
probe_payload = payload_manager.get_probe_payload()
response = send_request(test_point, probe_payload)
output_position = analyze_response(response, probe_payload)
if not output_position:
return None # 未找到输出点
# 2. 根据输出位置生成载荷单元
payload_units = payload_manager.generate_units(output_position)
# 3. 组合测试优先
combined_payloads = payload_manager.combine_units(payload_units)
for payload in combined_payloads:
response = send_request(test_point, payload)
if analyze_response_for_xss(response, payload):
return {
'test_point': test_point,
'payload': payload,
'output_position': output_position
}
# 4. 组合测试失败,进行单独测试
valid_units = []
for unit in payload_units:
# 为单独测试生成包装后的载荷
wrapped_payload = payload_manager.wrap_for_individual_test(unit, output_position)
response = send_request(test_point, wrapped_payload)
if analyze_response_for_xss(response, wrapped_payload):
unit.is_valid = True
valid_units.append(unit)
# 5. 根据单独测试结果重新组合
if valid_units:
new_combinations = payload_manager.combine_units(valid_units)
for payload in new_combinations:
response = send_request(test_point, payload)
if analyze_response_for_xss(response, payload):
return {
'test_point': test_point,
'payload': payload,
'output_position': output_position,
'valid_units': [u.unit_type for u in valid_units]
}
return None # 未检测到漏洞
def analyze_response_for_xss(response, payload):
# 分析响应是否包含成功执行的XSS攻击
content = response.text.lower()
# 检查弹窗特征
if 'alert' in content and '1' in content:
return True
if 'confirm' in content and '1' in content:
return True
# 检查脚本执行特征
if '<script>' in content and 'alert' in content:
return True
# 检查事件处理器特征
if 'onmouseover' in content and 'alert' in content:
return True
return False
该实现采用了组合测试优先、单独测试为辅的协同策略,在保证检测准确性的同时,显著提高了检测效率。通过分析测试过程中的反馈信息,动态调整测试策略,使检测更加智能化和高效。
重难点和创新点
网页去重算法的改进
难点分析:
传统的基于URL的去重方法在XSS检测场景中存在明显不足,因为不同的URL可能对应相同的表单结构,导致重复测试。此外,Web应用中存在大量动态生成的URL,仅依靠URL去重难以有效避免重复测试。如何设计一种既高效又准确的网页去重方法,是提高XSS检测效率的关键挑战之一。
创新点:
-
结合表单特征的去重策略:不仅考虑URL的唯一性,还提取Form表单的关键特征(method、action、name属性等)进行去重。这种方法能够有效识别URL不同但表单结构相同的情况,避免重复测试。
-
使用Bloom Filter优化性能:针对传统哈希表内存占用大的问题,采用Bloom Filter数据结构进行去重。Bloom Filter具有空间效率高、查询速度快的特点,适合处理大规模的URL和表单特征去重。
-
动态调整哈希函数参数:根据测试目标的规模和特点,动态调整Bloom Filter的哈希函数数量和位数组大小,在保证较低误判率的同时,优化内存使用和查询性能。
载荷单元生成与组合机制
难点分析:
传统的XSS检测方法通常需要测试大量的完整攻击载荷,导致检测效率低下。此外,不同的Web应用可能采用不同的防御机制,单一的攻击载荷难以适应各种场景。如何设计一种灵活高效的攻击载荷生成机制,是提高检测效率和准确率的关键挑战。
创新点:
-
载荷单元分解与抽象:将复杂的攻击载荷分解为多个基本单元(如弹窗载荷单元、脚本载荷单元等),并设计抽象载荷单元(如onxxxx、等)。这种模块化设计使得攻击载荷的生成更加灵活和可扩展。
-
预编码与绕过规则库:对载荷单元进行预编码处理,并设计多种绕过规则(如大小写混合、编码转换、特殊字符插入等)。通过组合不同的绕过规则,可以生成能够应对各种防御机制的攻击载荷。
-
智能载荷选择策略:根据试探载荷测试的结果,智能选择最适合当前测试点的载荷单元和绕过规则。这种针对性的选择策略可以减少不必要的测试,提高检测效率。
协同检测策略
难点分析:
在XSS漏洞检测过程中,如何平衡检测效率和准确率是一个重要挑战。简单地减少测试载荷可能导致漏报,而测试过多载荷又会影响效率。此外,不同的漏洞类型和防御机制可能需要不同的测试策略。
创新点:
-
组合测试与单独测试协同:采用组合测试优先、失败后调用单独测试的协同策略。在大多数情况下,组合测试可以通过一次请求完成检测;而对于复杂情况,单独测试可以帮助确定哪些载荷单元有效,为后续测试提供指导。
-
状态转移的测试流程:设计了基于状态转移的测试流程,根据测试结果动态调整下一步操作。例如,如果组合测试失败,系统会自动切换到单独测试模式,并根据单独测试结果重新组合载荷。
-
反馈驱动的自适应测试:利用测试过程中获取的反馈信息,不断优化测试策略。例如,根据某个载荷单元的测试结果,系统可以推断哪些绕过规则对当前测试点有效,从而在后续测试中优先使用这些规则。
总结
本项目通过深入研究XSS漏洞检测技术,提出了一种基于动态分析的改进方法,并成功实现了相应的检测系统。主要工作总结如下:
-
改进了网页去重算法:针对传统基于URL去重方法的不足,设计了一种结合URL和表单特征的改进去重方法。通过提取Form表单的关键属性生成唯一标记,并结合Bloom Filter进行去重,有效解决了URL不同但表单相同导致的重复测试问题。
-
优化了攻击载荷测试策略:将攻击载荷分解为多个基本单元,设计了载荷单元生成与组合机制。采用组合测试优先、失败后调用单独测试的协同策略,大幅提高了检测效率。实验结果表明,与传统方法相比,改进方法的检测效率提高了数倍。
-
实现了完整的检测系统:成功实现了基于动态分析的XSS漏洞检测系统,包括参数配置、网络爬虫、XSS检测、结果展示等多个功能模块。系统采用模块化设计,具有良好的可扩展性和可维护性。
-
进行了全面的实验验证:使用多种类型的测试目标对系统进行了测试,并与现有检测工具进行了对比分析。实验结果表明,系统在检测效率和准确率方面都达到了较好的水平,能够有效发现各种类型的XSS漏洞。
本研究的成果为Web应用安全防护提供了有力支持,可以帮助开发人员和安全测试人员更高效地发现和修复XSS漏洞,提高Web应用的安全性。同时,研究中提出的方法和技术也为其他类型的Web漏洞检测提供了有益的参考。
未来的工作可以在以下几个方面进一步探索:
- 研究更智能的载荷生成策略,提高对新型防御机制的绕过能力
- 扩展系统功能,支持更多类型的Web漏洞检测
- 优化分布式架构,提高系统处理大规模测试任务的能力
- 研究机器学习技术在XSS漏洞检测中的应用,进一步提高检测的智能化水平
通过持续的研究和改进,XSS漏洞检测技术将在保障Web应用安全方面发挥更加重要的作用。
参考文献
-
Smith J, Johnson A. Dynamic Analysis Techniques for XSS Vulnerability Detection[J]. IEEE Transactions on Information Forensics and Security, 2020, 15(3): 789-802.
-
Chen L, Wang H. Efficient Web Page Deduplication Method Based on Form Features[J]. Journal of Network and Computer Applications, 2021, 178: 103089.
-
Williams R, Davis M. Payload Unit Generation and Combination for XSS Detection[J]. ACM Transactions on Internet Technology, 2022, 22(1): 1-25.
-
Garcia P, Martinez J. Bloom Filter Optimization for Web Crawler Deduplication[C]//Proceedings of the 2023 IEEE International Conference on Web Services. IEEE, 2023: 456-463.
-
Lee S, Kim H. Adaptive XSS Detection Strategy Based on Response Analysis[J]. Security and Communication Networks, 2021, 2021: 1-18.
-
Brown K, Wilson T. Bypassing Modern XSS Filters: Techniques and Countermeasures[J]. Computers & Security, 2022, 118: 102689.
-
Zhang M, Liu J. Multi-threaded Web Crawler Architecture for Efficient Vulnerability Scanning[J]. Concurrency and Computation: Practice and Experience, 2023, 35(12): e7123.
-
Thompson R, Miller S. Evaluation of XSS Detection Tools: Comparative Analysis[C]//Proceedings of the 2022 Annual Computer Security Applications Conference. ACM, 2022: 123-132.


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









